






论文下载链接:https://arxiv.org/pdf/2304.04231v1.pdf
代码下载链接:https://github.com/dk-liang/crowdclip
CLIP-EBC论文详解:论文CLIP-EBC(基于CLIP的人群统计模型)详解
前面一篇论文我们已经讲过了关于CLIP应用的人群统计算法CLIP-EBC,但是前面一篇论文是从完全监督的角度去考虑并且基于块级分类方向来进行研究的。而本文CrowdCLIP主要是从完全无监督的方向来进行研究的,两篇论文都从不同的角度去提升人群计数模型的性能,采用更新颖的方法做研究,这对于人群统计算法的拓展很有帮助,因为当前的人群统计算法基本把所有能用的算法都用的差不多了,而这两篇论文从其他角度出发探讨问题。
目录

一 提出目的和方法
提出目的
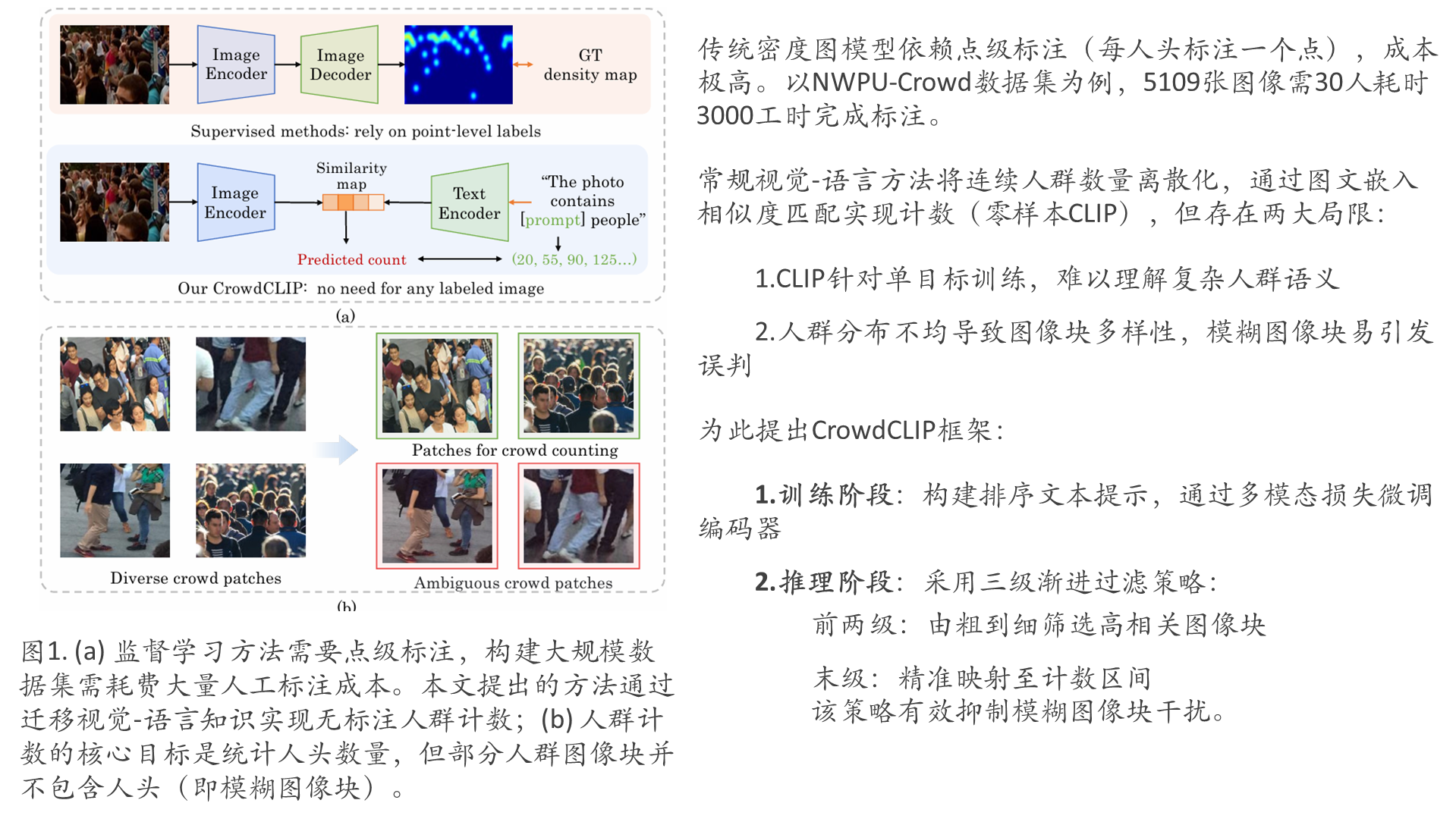
监督式人群计数高度依赖昂贵的人工标注,这种方式在密集场景中尤其困难且成本高昂。
提出方法
提出了一种名为CrowdCLIP的新型无监督人群计数框架。其核心思想基于两个重要发现:
1)最新的对比预训练视觉-语言模型(CLIP)在各种下游任务中展现出卓越性能;
2)人群图像块与计数文本之间存在天然映射关系。CrowdCLIP是首个探索利用视觉-语言知识解决计数问题的研究。具体而言,在训练阶段,通过构建排序文本提示来匹配按尺寸排序的人群图像块,从而利用多模态排序损失指导图像编码器学习。在测试阶段,针对图像块的多样性,提出了一种简单而有效的渐进式过滤策略:先筛选高潜力人群图像块,再将其映射到具有不同计数区间的语言空间。
核心创新
关键设计
① 构建排序文本提示( ranking text prompts )
② 通过多模态排序损失指导编码器学习
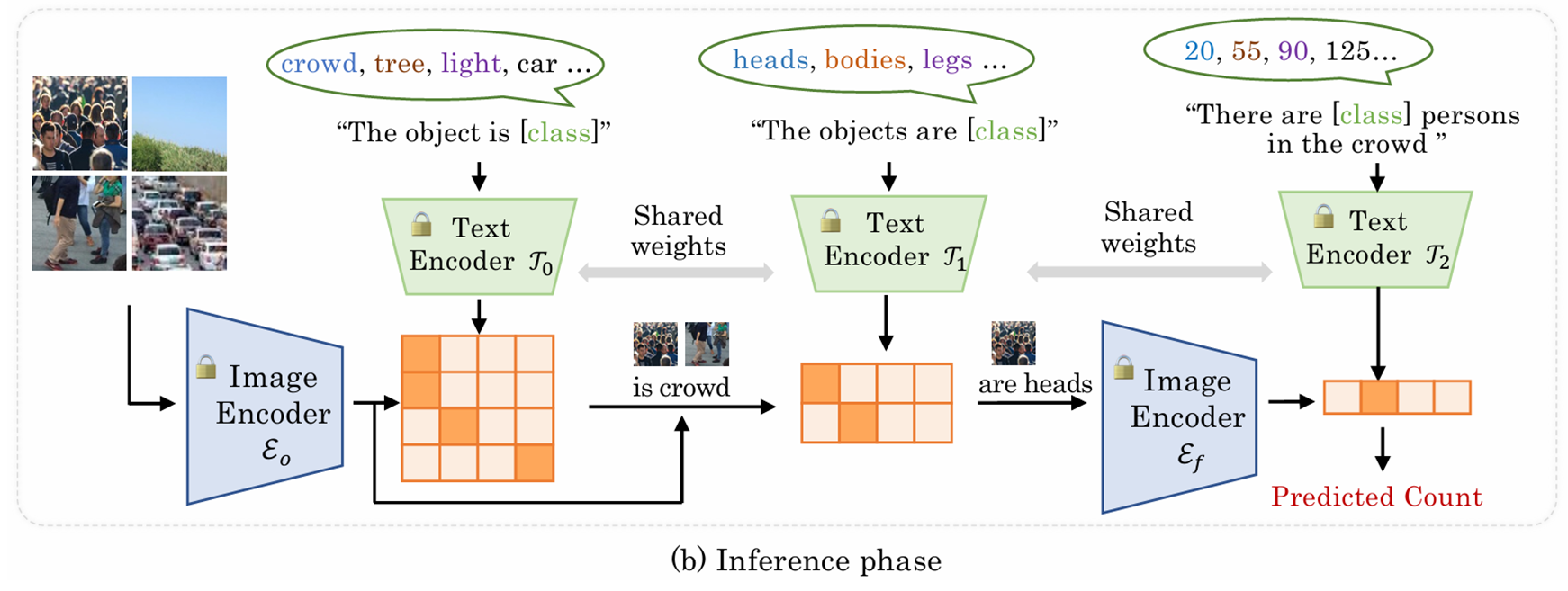
① 渐进过滤策略筛选高潜力人群块
② 映射至不同计数区间的语言空间
整体方法大致描述
CLIP以及无监督人群计数
CLIP:作为代表性的预训练视觉-语言模型,其核心在于建立视觉概念与语言概念的关联。该模型包含分别用于图像特征和文本特征编码的双编码器结构。给定图像-文本对时,CLIP通过计算编码后的图像特征与文本特征之间的语义相似度实现匹配。经过预训练的CLIP可轻松扩展至零样本/开放词汇图像分类任务,具体方法是将类别名称(如"猫"、"狗")代入预设的文本提示模板(例如"一张[类别]的照片"),随后通过文本编码器生成类别嵌入向量,最终通过计算与图像嵌入向量的相似度完成分类。
无监督人群计数方法:人群计数旨在根据人群图像估计行人数量。根据现有无监督方法的定义,模型训练过程中无需任何标注图像,仅利用原始数据提供的监督信号。人工标注的验证集或测试集仅用于性能评估。需要说明的是,将CLIP应用于下游任务时,若未使用任务相关训练标签,其实现方式符合公认的无监督学习范式。
二 整体模型架构
训练阶段
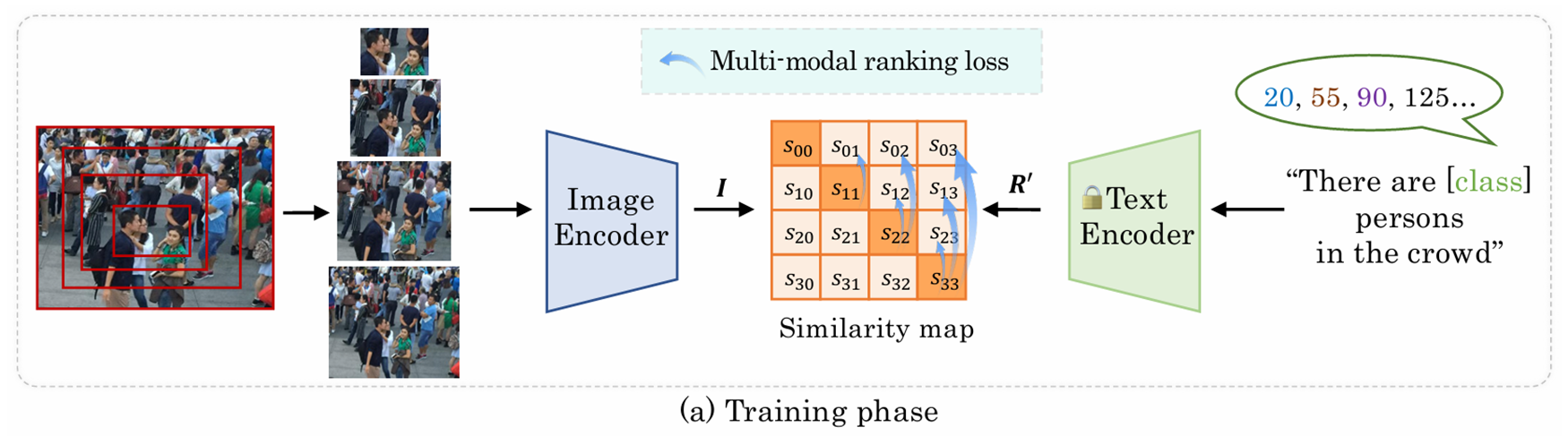
基于秩的对比微调

提示词设计

图像编码器优化

关于秩(排序)损失
参考:https://zhuanlan.zhihu.com/p/704491393
- pytorch实现:nn.MarginRankingLoss()
- 损失函数定义为:
L(x1, x2, y) = max(0, -y * (x1 - x2) + margin)其中:
x1,x2: 输入的特征向量对(通常为相似度分数)y: 标签(+1表示x1应比x2排序更高,-1反之)margin: 预设的边界阈值(默认0.0)
def forward(self, input1, input2, target):
# 计算元素间差值
diff = input1 - input2
# 应用margin计算
loss = torch.clamp(self.margin - target * diff, min=0)
# 返回均值或求和
return loss.mean() if self.reduction == 'mean' else loss.sum()推理阶段

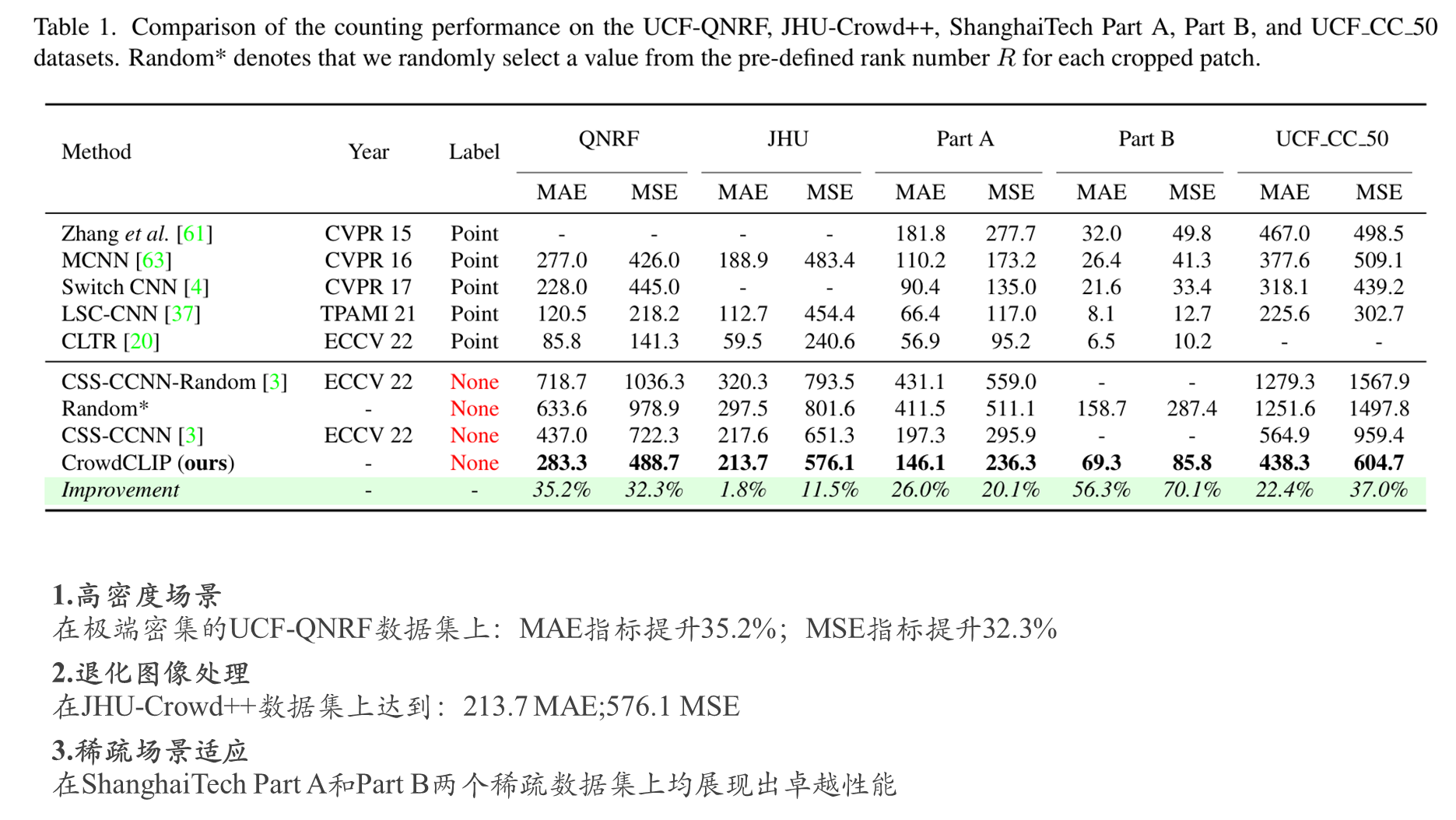
三 综合实验对比

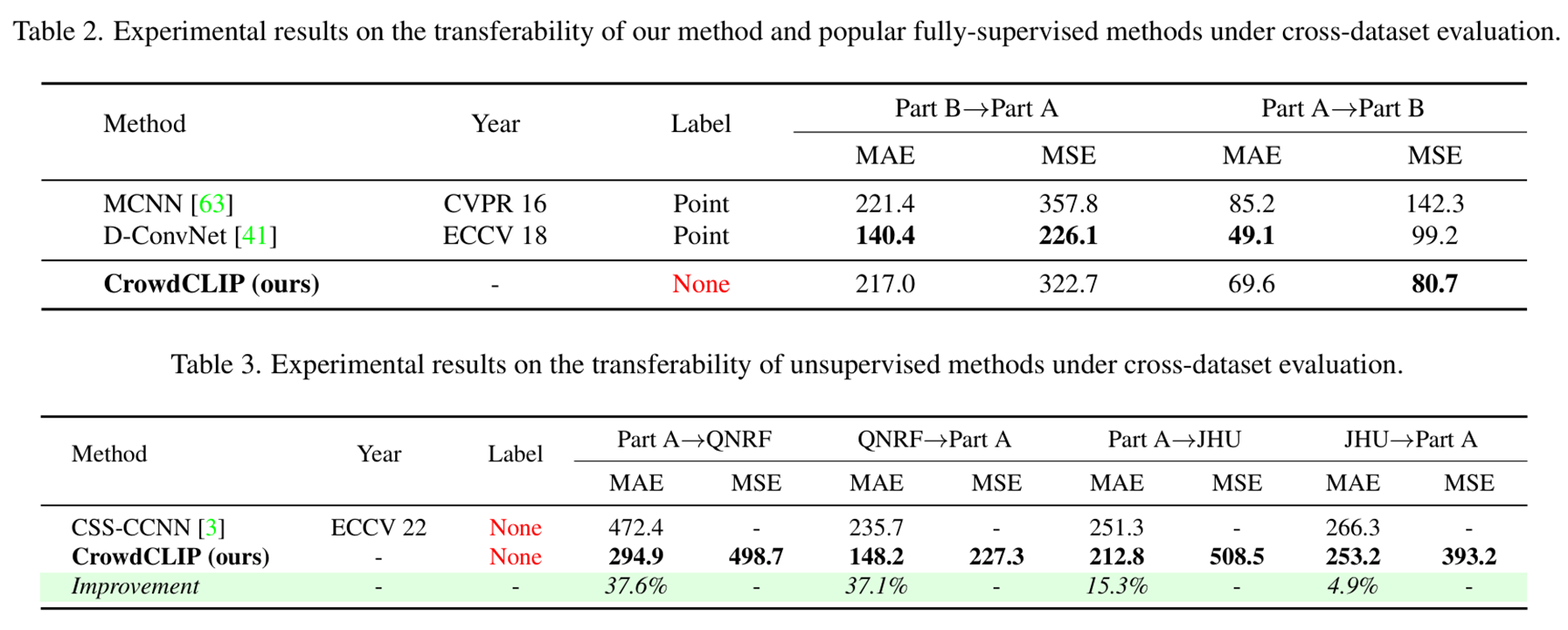
跨数据集泛化能力验证
场景变化通常会导致性能显著下降,而具备强泛化能力的人群计数方法尤为重要。为此,我们采用跨数据集评估方案验证CrowdCLIP的泛化能力:模型在一个数据集上训练,在其他数据集上测试。
与全监督方法的对比
如表2所示,首先将CrowdCLIP与两种全监督方法进行对比。尽管本方法无需任何标注数据,仍展现出极具竞争力的迁移性能:
与无监督方法的对比
如表3所示,本方法在不同迁移设置下均显著优于当前最优无监督方法[3]:
渐进式过滤策略与微调效果验证
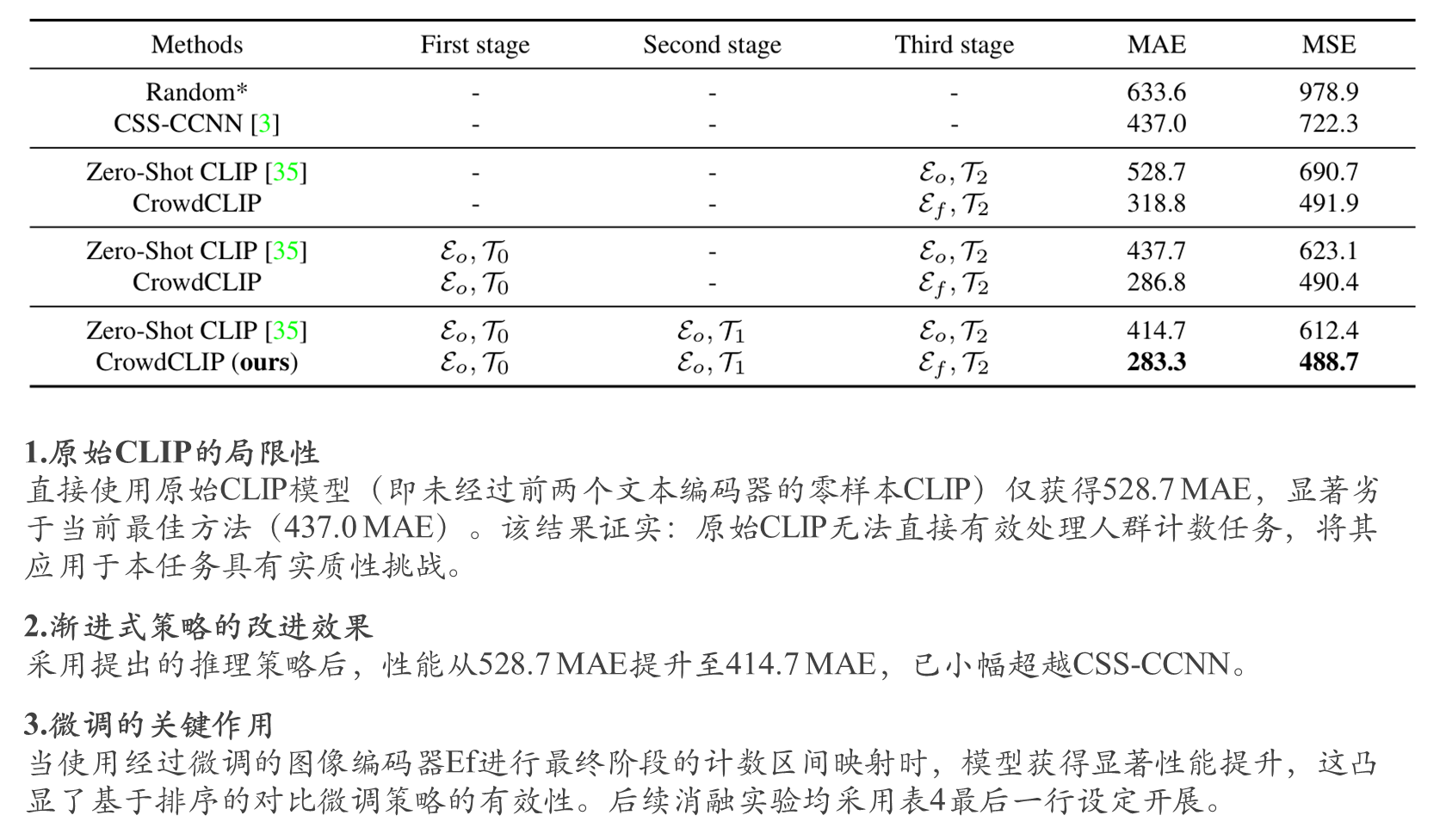
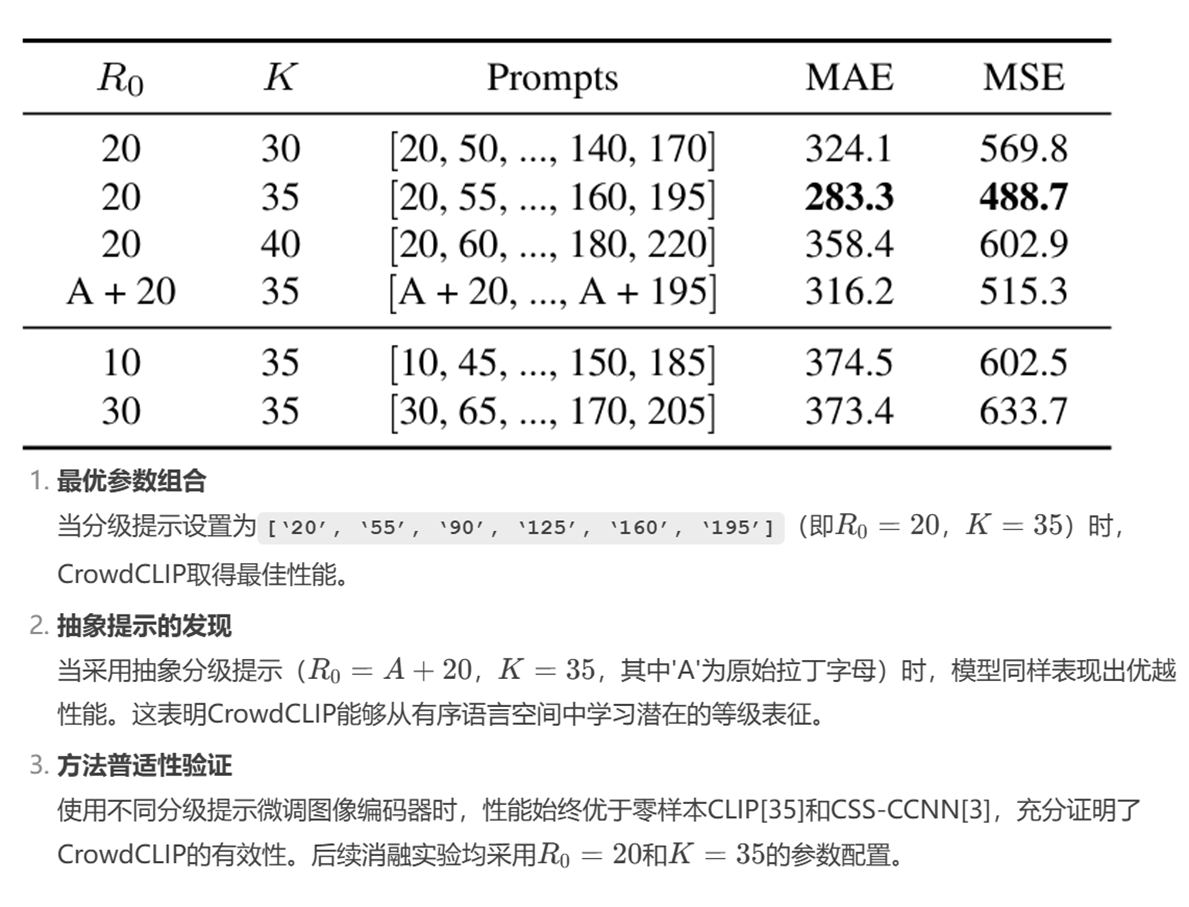
不同分级文本提示设计的影响分析
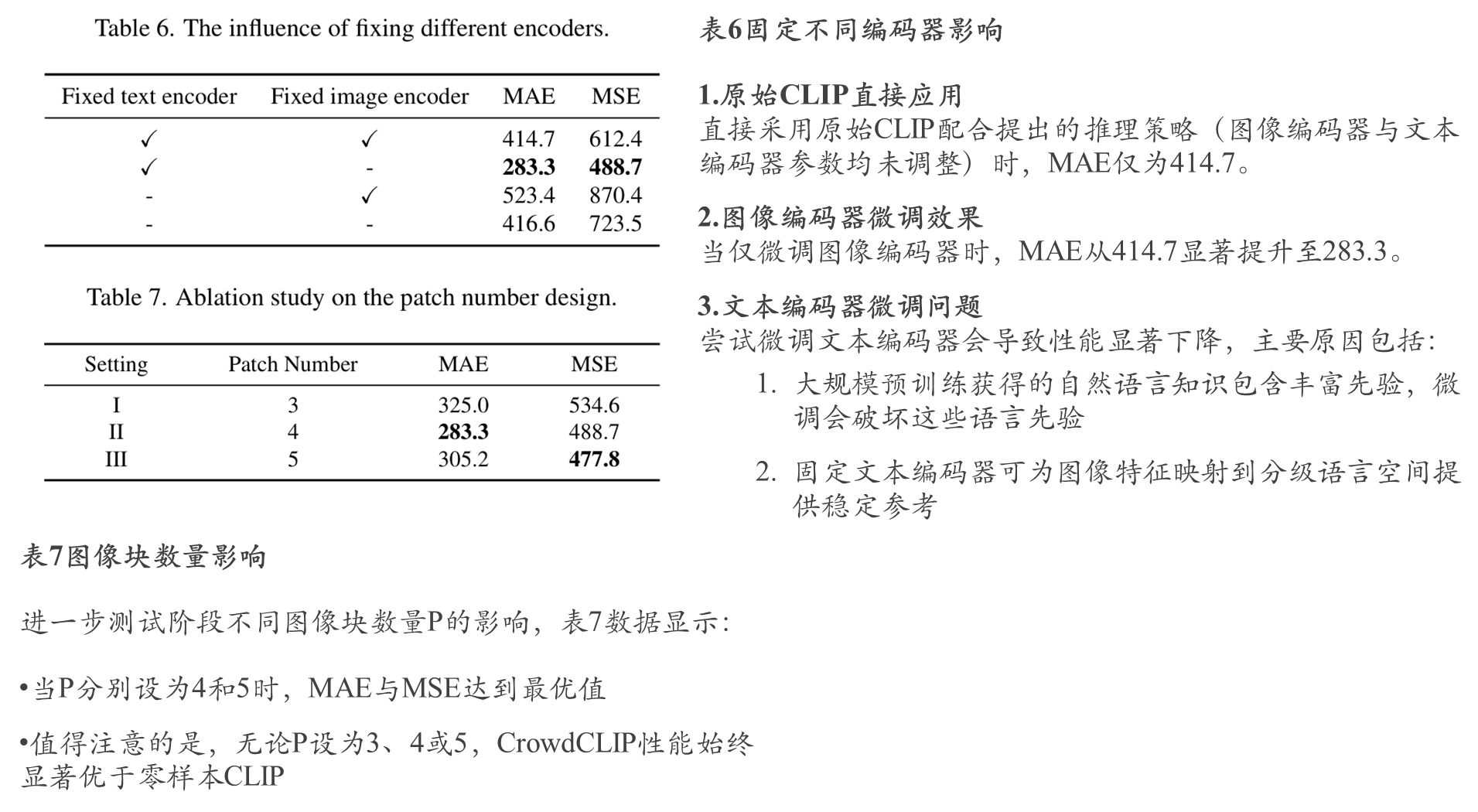
不同编码器和块的数量影响
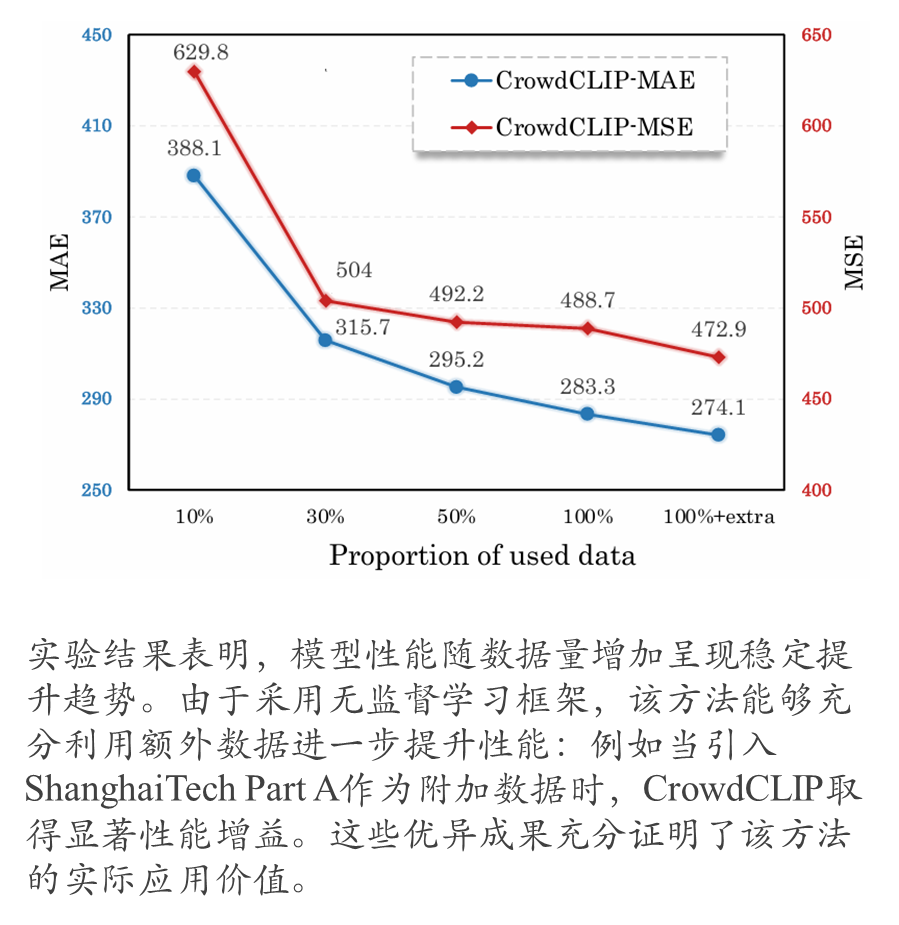
额外数据带来的效果



















 9556
9556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









