







Large Language Models for Disease Diagnosis: A Scoping Review
https://arxiv.org/abs/2409.00097
- 问题
- 现有基于大语言模型(LLMs)的疾病诊断研究中,对于 LLMs 应用的疾病类型、临床数据、技术及评估方法等关键方面缺乏全面清晰的阐述。例如,哪些疾病和医疗数据已被用于 LLM - 诊断任务(Q1)?应用了哪些 LLM 技术以及如何选择合适的技术(Q2)?采用何种评估方法评估性能(Q3)?
- 挑战
- 信息收集与整合挑战
- 多数研究在诊断中未充分整合多模态数据,与实际临床场景中患者信息多模态性不符,易导致误诊。
- 多数研究假设患者信息完备,但实际初始诊疗或复杂疾病诊断中常因信息不足导致误诊。
- 多数研究未充分考虑临床指南,对实验室检测结果的整合与解释不足。
- 决策过程挑战:在诊断决策过程中,许多研究忽视了模型可解释性、患者隐私、安全和公平性等人本视角。
- 技术层面挑战
- 多模态数据集成面临数据噪声、异构数据融合及高效学习等技术难题。
- 领域特定 LLMs 参数规模较小,限制其性能,可能因训练数据和资源不足导致。
- LLMs 存在幻觉问题,影响诊断可靠性,包括数据相关和训练相关的幻觉。
- 诊断系统开发受限于公共数据可用性低和标注数据稀缺,且缺乏标准化评估指南。
- 实际部署挑战:LLMs 在诊断应用中稳定性不足,难以提供稳定预测,在移动设备部署和早期诊断应用方面存在困难。
- 信息收集与整合挑战
- 创新点
- 对 LLMs 在疾病诊断中的应用进行了全面系统的综述,涵盖疾病类型、临床专业、数据、技术和评估方法等多个方面,此前未有研究如此全面地聚焦于此领域。
- 深入分析了主流 LLM 技术和评估方法的优缺点,为根据不同用户需求开发诊断系统提供了针对性建议,填补了此前研究在这方面的不足。
- 从多个角度剖析了当前研究现状,包括对现有研究现象的解读、背后原因的挖掘,以及对未来研究方向的全面展望,为该领域研究提供了新的思路和方向。
- 贡献
- 知识总结:系统总结了 LLMs 用于疾病诊断领域的疾病类型、临床专业、数据、技术和评估方法等关键信息。
- 方法比较与建议:详细比较主流 LLM 技术和评估方法的优缺点,为诊断系统开发提供基于用户需求的建议。
- 现象剖析与展望:深入剖析当前研究现象,明确未来研究方向,为该领域研究提供全面指导。
- 提出的方法
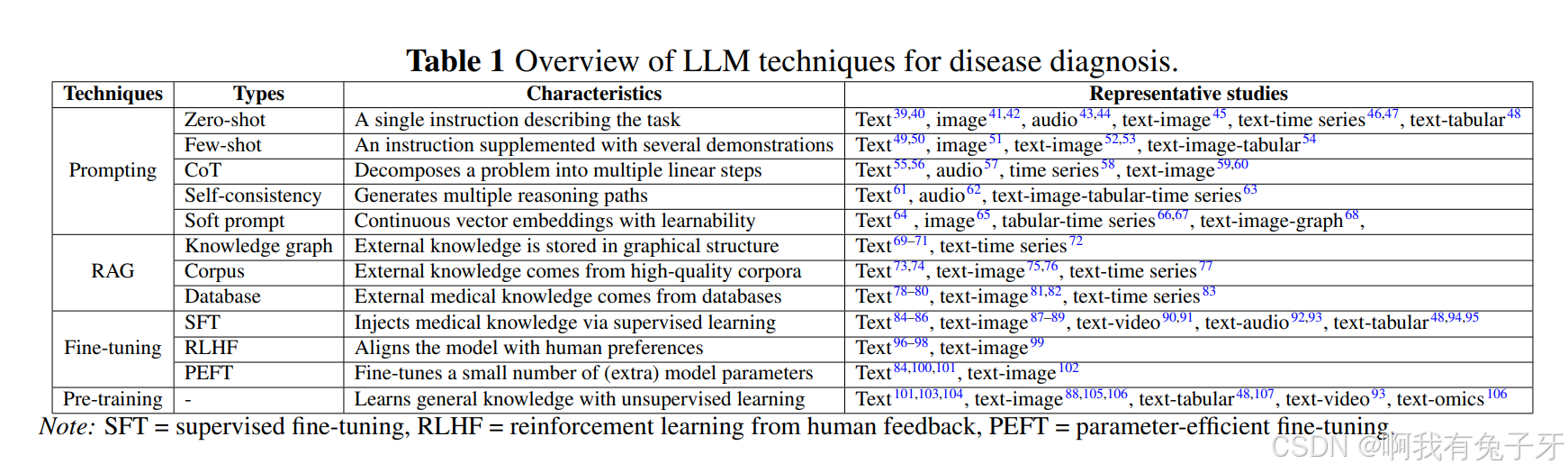
- LLM 技术分类方法:将用于疾病诊断的 LLM 技术分为 prompt(包括零样本、少样本、思维链、自一致性等)、RAG(基于文本、文本 - 图像、时间序列等不同数据模态)、fine - tuning(包含监督微调 SFT 和强化学习人类反馈 RLHF)和 pre - training 等类别,并详细阐述了各类别的特点和操作流程。
- 评估策略分类方法:把诊断任务的评估策略分为自动评估(使用分类 - 、多标签 - 和风险预测 - 相关指标)、人工评估(依靠领域专家判断)和 LLM 评估(利用 LLMs 替代人类专家),分析了各自的优缺点。
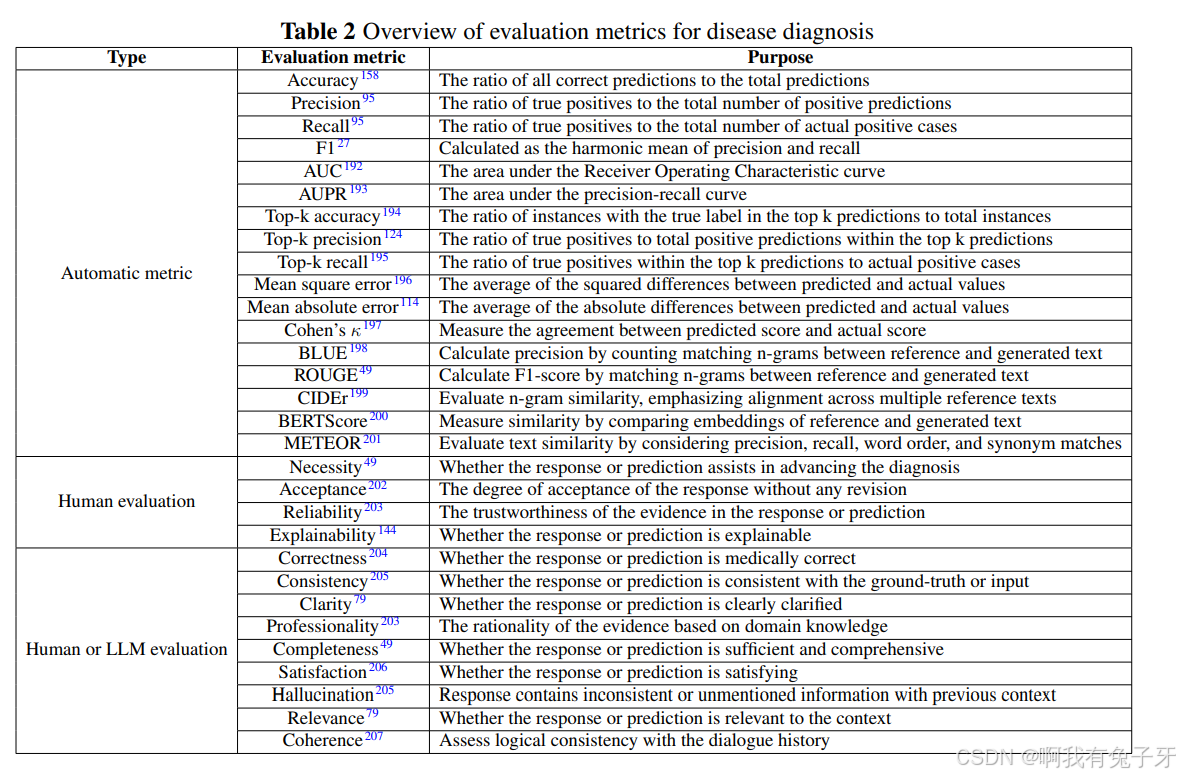
- 指标
- 自动评估指标:如准确率、精确率、召回率、F1 值、AUC、AUPR、Top - k 准确率、Top - k 精确率、均方误差、平均绝对误差、Cohen's kappa、BLUE、ROUGE、CIDEr、BERTScore、METEOR 等,用于衡量模型预测的准确性、可靠性和一致性等。
- 人工评估指标:包括必要性、可接受性、可靠性、可解释性等,从人类专家角度评估模型预测的质量和实用性。
- LLM 评估指标:如正确性、一致性、清晰度、专业性、完整性、满意度、幻觉、相关性、连贯性等,综合评估模型性能。
- 模型结构:论文未提及具体的单一模型结构,而是对不同类型的 LLM 技术及其在疾病诊断中的应用方式进行了阐述,如 prompt 技术中指令、上下文、输入数据和输出指标的构成,RAG 中外部知识的来源和融入方式,fine - tuning 的两个阶段及操作,pre - training 的过程及对模型知识获取的作用等。
- 结论
- 总结了 LLMs 在疾病诊断领域的研究现状,包括应用范围、技术应用情况和评估方法等。
- 分析了当前研究的局限性,如在信息收集与整合、决策过程、技术层面和实际部署等方面面临的挑战。
- 基于现状和局限性,对未来研究方向提出了建议,如改进数据收集与处理、加强模型性能提升、完善评估体系和推动实际应用等。
- 剩余挑战和未来工作
- 数据相关挑战与工作:强调多模态数据收集与融合,提高数据质量,增强对真实临床场景的模拟;开发应对信息不完整的方法,将信息不完整性意识融入诊断模型或开发自动诊断查询方法。
- 【这里可以使用患者相似性来补充一些可能性】
- 人机交互挑战与工作:加强人机交互研究,探索如何使诊断系统更好地辅助临床工作,提高临床意义;开发用户友好的交互界面,促进医生与诊断系统的有效沟通。
- 技术提升挑战与工作:探索新的模型架构和训练策略,解决多模态数据集成、参数规模限制和幻觉问题;扩大训练数据规模和多样性,提高模型性能和泛化能力;研究知识编辑或外部知识检索方法,减少数据相关幻觉;构建和发布标注基准数据集,制定标准化评估指南,提高评估的准确性和可比性。
- 部署应用挑战与工作:提高 LLMs 诊断的稳定性,确保在临床应用中能提供可靠预测;探索在移动设备上的部署,实现连续自动数据收集和风险预警;加强早期诊断研究,克服早期疾病症状不明显的难题,提高早期诊断的准确性和有效性。
- 数据集:论文未明确提及特定的数据集,主要强调了数据的类型(如临床笔记、X 射线、病理图像、ECG、超声、遗传数据、实验室测试结果、MRI、语音等)、模态(文本、图像、视频、音频、时间序列、多模态等)以及数据的来源(包括数据的隐私状态,如私有数据和公共数据)等信息,同时指出了数据在不同临床专业和疾病诊断中的应用情况。
原文
抽象。
自动疾病诊断在临床实践中变得越来越有价值。大型语言模型 (LLM) 的出现催化了人工智能的范式转变,越来越多的证据支持 LLM 在诊断任务中的有效性。尽管该领域受到越来越多的关注,但仍然缺乏整体观点。许多关键方面仍不清楚,例如应用 LLM 的疾病和临床数据、采用的 LLM 技术以及使用的评估方法。在本文中,我们对基于 LLM 的疾病诊断方法进行了全面回顾。我们的综述从各个维度检查了现有文献,包括疾病类型和相关的临床专业、临床数据、LLM 技术和评估方法。此外,我们还为在诊断任务中应用和评估 LLM 提供了建议。此外,我们评估了当前研究的局限性并讨论了未来的方向。据我们所知,这是第一篇关于基于 LLM 的疾病诊断的全面综述。
介绍
自动疾病诊断是临床场景中的一项关键任务,它以临床数据为输入,分析模式,并在最少或无需人工干预的情况下生成潜在的诊断 1。其医疗保健的重要性是多方面的。首先,它提高了诊断准确性,支持医生进行临床决策,并通过提供更高质量的诊断服务来解决医疗保健可及性方面的差异 2。二、自动诊断提升健康效率护理专业人员 3,4,这对于管理大型 PA 面板的临床医生特别有价值
年龄增加和多种发病率 5。例如,DXplain6 是一个诊断系统,它利用患者的体征、症状和实验室数据来生成潜在诊断列表,以及为什么应该考虑每种情况的理由。此外在线服务进一步促进了某些疾病的早期诊断或大规模筛查 4,7,例如作为心理健康障碍,通过在早期阶段提高认识并帮助预防潜在风险。例如,几项研究调查了使用社交媒体帖子进行大规模抑郁症识别 8 和自杀风险预测 9。
人工智能 (AI) 的最新进展推动了自动化的发展诊断系统分为两个阶段 10-13。最初,支持向量机和决策树等机器学习技术被用于疾病分类 14,15,这通常涉及数据处理、特征提取、模型优化和疾病预测四个步骤。凭借更大的数据集和足够的计算能力,深度学习方法后来成为 domi开发了诊断任务 2,16。这些方法利用了深度神经网络 (DNN),包括卷积神经网络 1,17、递归神经网络 18 和生成式神经网络Adversarial Networks19 的 Alpha S Networks,支持端到端特征提取和模型训练。例如,具有 34 层的卷积 DNN 在心律失常诊断方面达到了心脏病专家级别的性能 20。但是,这些模型通常需要大量的标记数据进行监督学习和通常是特定于任务的 1,20,限制了它们对其他任务或新需求的适应性 17。
近年来,AI 的范式已经从传统的深度学习转变为新兴大型语言模型 (LLM) 的与监督学习不同,LLM(例如生成式预训练转换器 (GPT)21 和 LLaMA22)是通过自我监督学习在大量未标记数据上进行预训练的生成模型。这些模型通常由数十亿个参数组成,在语言处理方面表现出色,并适应各种任务。迄今为止,LLM 已在临床场景 23 中表现出卓越的性能,包括问答 (QA)24、信息
mation 检索 25 和临床报告生成 26,27。最近,越来越多的研究验证了 LLM 对诊断任务的有效性。例如,PathChat28 是一个视觉语言通才 LLM,经过数十万条指令的微调,在人类病理学方面取得了最先进的性能。Med-MLLM27 是一种多模式法学硕士,根据广泛的医疗数据(包括胸部 X 光片、CT 扫描和临床记录)进行了预先训练和微调,在 COVID-19 诊断中表现出显着的准确性。此外,Kim 等人 29 使用具有快速工程的 GPT-4,发现它在识别强迫症方面超过了心理健康专业人员,这强调了 LLM 在心理健康诊断方面的潜力。
尽管这一研究领域引起了广泛关注,但许多关键问题仍未得到充分探索。例如,在基于 LLM 的诊断任务 (Q1) 中研究了哪些疾病和医疗数据?哪些 LLM 技术已应用于疾病诊断以及如何选择合适的技术 (Q2)?哪些评估方法适合评估绩效 (Q3)?尽管有许多综述论文调查了将 LLM 应用于医学领域 30-37,这些努力通常提供了各种临床应用的广泛概述不强调疾病诊断。例如Pressman 等人 38 提供了 LLM 潜在临床应用的全面总结,包括会诊前、治疗、术后管理、出院和患者教育。此外,这些综述论文都没有解决将 LLM 应用于疾病诊断的细微差别和挑战,也没有回答上述问题凸显了一个关键的研究差距
本综述的主要目的是提供利用 LLM 进行疾病诊断的研究概述。该综述介绍了各种疾病类型、疾病相关临床专业、临床数据、LLM 技术和现有工作的评价方法。此外,我们还为数据准备、选择合适的 LLM 技术以及为诊断任务采用合适的评估策略提供了建议。此外,我们的综述描述了当前研究的局限性,并深入了解了该领域的挑战和未来方向。据我们所知,这是第一篇关注 LLM 疾病诊断的综述,并提供了该领域的全面概述。总之,本综述概述了基于 LLM 的疾病诊断的蓝图,并有助于启发和简化未来的研究工作。
表 1 用于疾病诊断的 LLM 技术概述。【可以看到,还是有两个技术用知识图谱检索的】
结果
范围概述
本节介绍了我们综述的范围。图 2 不仅说明了疾病类型、相关的临床专业、临床数据类型和数据模态 (Q1),还介绍了应用的 LLM 技术 (Q2) 和评估方法 (Q3),回答了上述问题。具体来说,我们调查了 19 个临床专业和超过 15 种疾病诊断的临床数据。临床数据涵盖各种数据模态,包括文本、图像、视频、音频、时间序列和多模态病例。此外,我们根据应用的 LLM 技术对现有的疾病诊断工作进行分类,例如提示 (zero-shot)、检索增强生成 (RAG) 和预训练。表 1 总结了主流 LLM 技术的分类法。图 4 展示了所纳入论文的临床专业、数据模式和 LLM 技术的关联。以上数字全面揭示了基于 LLM 的疾病诊断的现状。此外,图 3 显示了我们综述的元信息分析,涉及不同地区的发布趋势,广泛使用的用于训练和推理的 LLM 摘要,以及数据源、评估方法和数据隐私状况的统计数据。
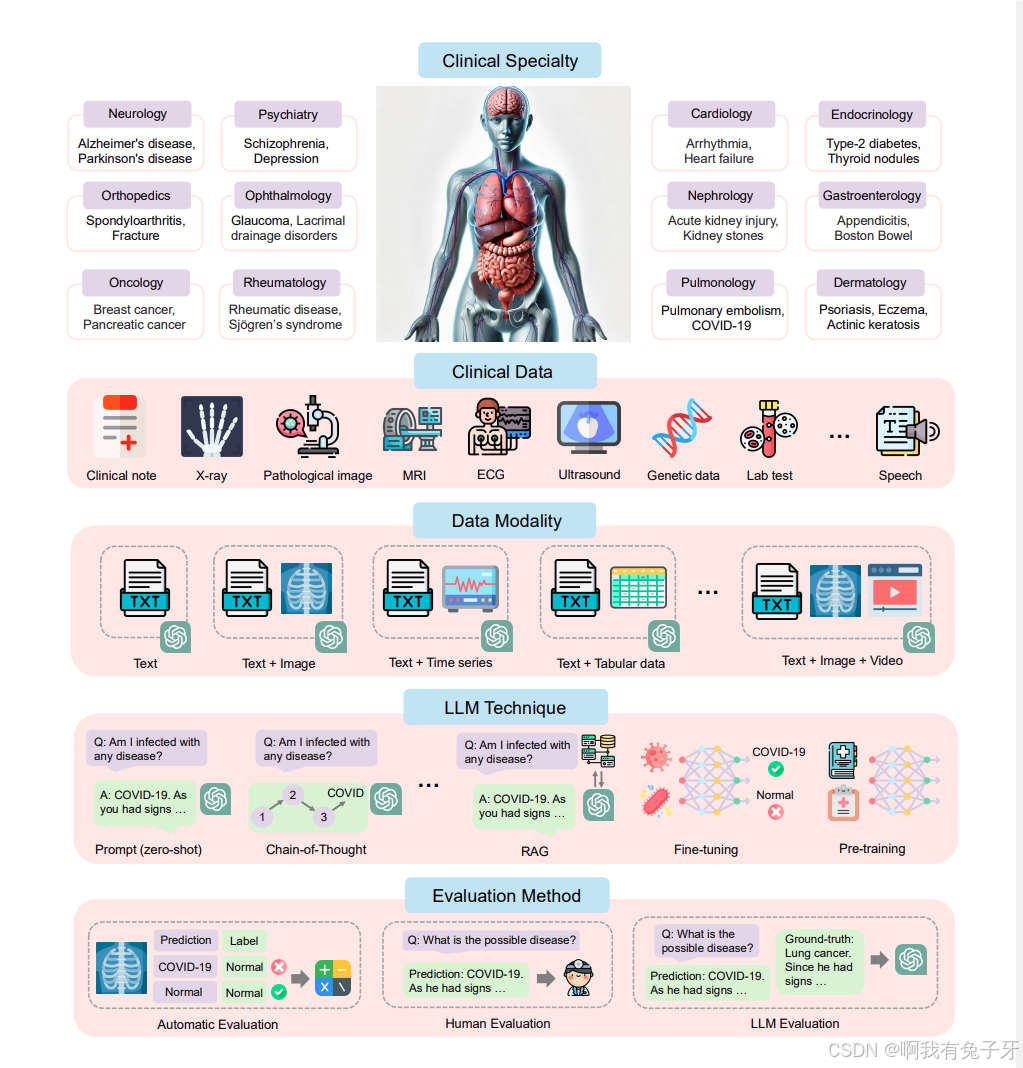
图 2 调查范围概述。它说明了疾病类型和相关的临床专业、临床数据类型、所用数据的方式、应用的 LLM 技术和评估方法。我们只介绍了部分临床专科和一些代表性疾病。

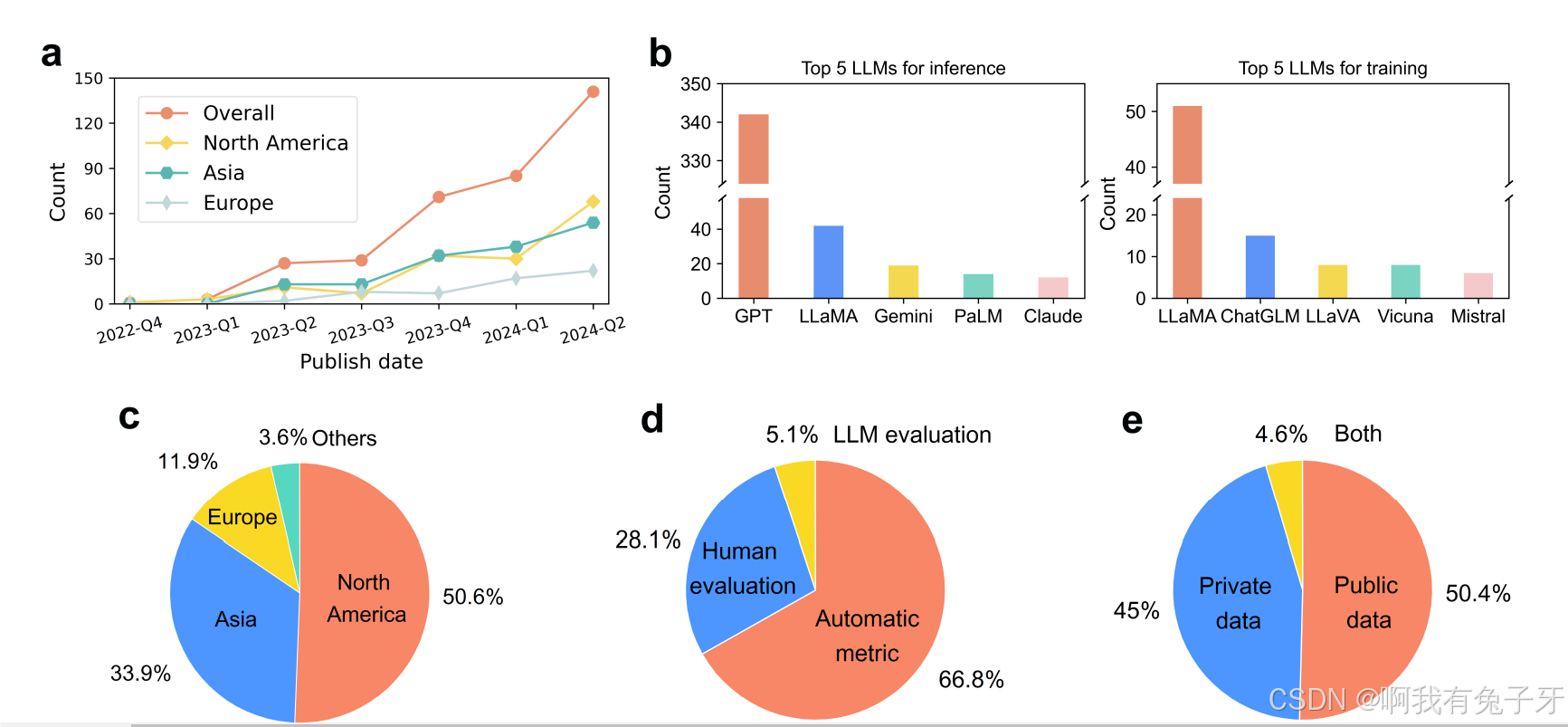
图 3 范围审查中基于 LLM 的诊断研究的信息元数据。a 基于 LLM 的诊断研究的季度细分。由于 2024 年第三季度的信息不完整,我们的统计数据仅涵盖 2024 年第二季度。b 用于推理和训练的前 5 个广泛使用的 LLM。c 按区域划分的数据源。d 评价方法的分类(注意一些论文使用了多种评价方法)。e 按隐私状态划分的已使用数据集的细分。
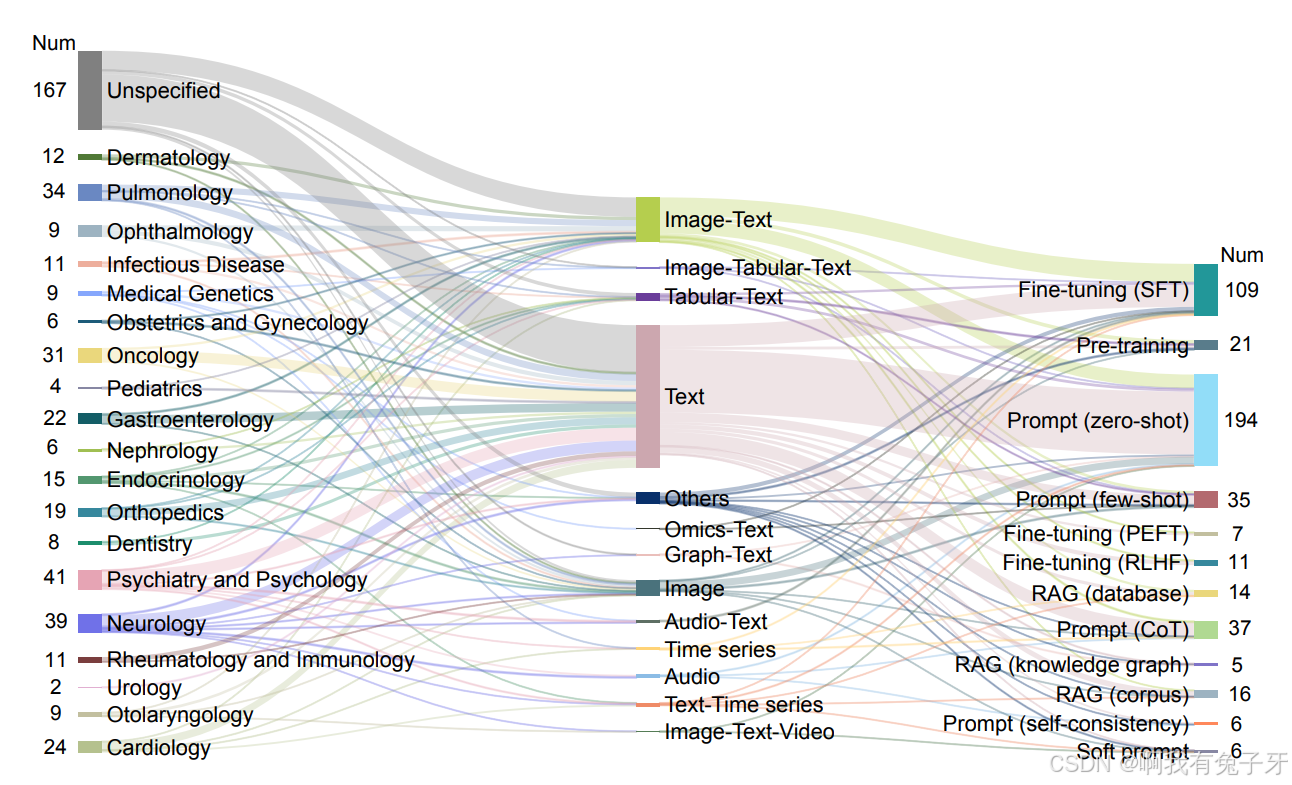
图 4 收录论文中临床专业(左)、数据模态(中)和 LLM 技术(右)之间的关联总结。
基于提示的疾病诊断
自定义提示通常包括四个部分 108:指令(指定任务)、上下文(定义场景或域)、输入数据(标识要处理的数据)和输出指示符(将模型引导到所需的样式或角色)。超过 60% 的 的纳入研究是基于提示的方法。我们确定了五种不同的技术,它们分为两大类:硬提示和软提示。硬提示包括零发、少发、思维链 (CoT) 和自洽提示等方法。这些提示是静态的且可解释的,以自然语言编写,这使得它们在输入和输出结构定义明确时特别有效 109。另一方面,软提示是由小型可训练模型生成的连续向量嵌入,然后馈送到 LLM 中。这种技术称为提示调整,将输入数据编码为特定于任务的嵌入,使 LLM 能够更有效地适应任务 110。
在基于提示的研究中,零样本提示(由没有标记示例的单个指令组成)是最普遍的 。基于 CoT 的方法 的特点是将复杂问题分解为更小、可管理的部分,使模型能够分多个步骤依次解决这些问题 111,112。例如,在鉴别诊断中,LLM使用 CoT 推理可以遵循临床指南按顺序解释医学图像、放射学报告和症状描述,在提供到随后的分析中 55,59,60。这种循序渐进的方法允许模型集成上下文在整个推理过程中,最终实现整体的最终诊断。基于少发提示的方法 扩展了零发提示,并提供了一些标记的示例来提高任务性能。基于自洽性提示 self-consistency prompting 的研究以生成多个推理路径以增强 LLMs63,113 的可靠性和稳健性。例如Kim 等人 63 采用自洽提示来预测抑郁评分 (PHQ-4),方法是综合来自人口统计学、健康领域文献、自我报告症状和可穿戴传感器数据的不同信息,以在多个推理路径中选择最一致的响应。基于软提示的研究 涉及在将连续向量嵌入馈送到 LLM 之前对其进行训练,这使它们能够根据特定任务调整 LLM 的行为。它主要用于编码多模式电子健康记录 (EHR),包括医学图像、临床记录和实验室结果。软提示的一个关键优势是它能够将外部领域知识(如医学概念嵌入)与上下文信息(如个人临床概况)集成。这允许模型生成细微的疾病诊断详细的解释,使其非常适合复杂的临床场景 65,66。
基于提示的研究大多涉及单峰数据探索 ,其中大多数仅关注文本数据的研究 。主要使用临床记录 14.115、医学影像报告 56,116,117 和临床病例报告 45,118 等临床文本数据。这些研究通常输入临床记录或病例报告,并向 LLM 询问建议的疾病诊断诺西斯 19-12。一些研究 将提示工程应用于医学图像数据。常用研究的医学图像包括 CT 扫描 51,123、X 射线 68,124、磁共振成像 (MRI) 51,125 和病理图像 126,127。主要用途是检测医学图像上的异常并为鉴别诊断提供支持证据 41,75,126,128。
随着多模态 LLM 的快速发展,越来越多的研究探索使用这些模型进行疾病诊断和快速工程 。该领域的一个关键进步是视觉语言模型 (VLM)(例如 GPT-4V、LLava 和 Flamingo),它使图像 - 文本对成为多模态 LLM 最普遍的输入组合 。与单峰 LLM 不同,VLM 被赋予了更全面的临床概况,即医学图像和互补的文本描述,并且能够证明诊断的合理性,具有更多详细信息的决定 129-131。例如,Upadhyaya 等人 75 证明 incorporat将眼科医生的反馈和上下文信息(例如,图像位置、目的)与眼动图像相结合,显著提高了 GPT-4V 对弱视的诊断准确性。
更先进的多模态 LLM,例如 GPT-4o 和 Gemini-1.5 Pro,使基于提示的研究超越了文本和图像,并包括用于疾病诊断的多种数据模式。具体来说,许多工作利用音频和视频数据来促进神经系统的诊断和神经退行性疾病,如自闭症 43,132 和痴呆症 44,68。一些研究调查了使用组学数据检测罕见遗传病 133 和阿尔茨海默病 134。此外,广泛的风险预测任务倾向于在早期结合多模态数据
警告,包括时间序列数据,例如心电图信号 46,47,135 和可穿戴传感器数据 58,63; 表格数据,例如用户人口统计 134,136 和实验室测试结果 66,137。这些应用包括抑郁和焦虑筛查 63、紧急分诊 138 和心律失常检测 46,135,139。其他研究进一步将多模态 LLM 与用于神经系统疾病诊断的医学概念图相结合 68。
用于诊断的检索增强 LLM
为了提高诊断的准确性和可信度,缓解幻觉问题等,确定 LLM 无需重新培训即可储存的医学知识,最近的研究 69,70,79,140-142将外部医学知识纳入诊断任务。外部知识Marily 来自包含的论文中的语料库 73,74,74–77,140,141,143–148,数据库 61,78–83,123,135,142,149–153 和知识图谱 69–72,154。根据数据模态,这些基于 RAG 的研究可以是大致分为基于文本、基于文本图像和基于时间序列的增强。
在基于文本的 RAG 中,大多数研究 74,78,79,140,142,143,145,148,149,151–153 都采用了 ba
SiC 检索策略。在这种方法中,外部知识使用句子转换器(例如 OpenAI 的 text-embedding-ada-002)编码为向量表示,这些句子转换器用作检索源。查询采用类似的编码,允许系统通过计算查询向量和源向量之间的相似性来识别和获取最相关的知识。然后使用专门设计的提示将这些组合信息输入到 LLM 中,以生成诊断结果。然而,两篇论文使用 LLM 从给定内容 144,146。Zhenzhu et al. 144 设计了基于指南的 GPT 代理来总结和检索创伤性脑损伤康复相关问题的内容。McInerney et al. 146 利用 LLM 从以前的笔记中提取证据片段,以评估癌症、肺炎和肺水肿的危险因素。四项研究从知识中检索到相关内容边缘图 69-71,147,154。一项研究利用正则表达式来匹配有用的知识
肺动脉高压诊断 141。与以前仅使用一个 LLM 进行诊断的研究不同,Wang et al. 80 聘请了几个 LLM,每个 LLM 都配备了特定的医学知识,进行联合诊断。
在文本图像数据处理中,一种常见的方法 75,81,82,123,151 涉及从输入图像提取特征,将这些功能转换为文本描述,然后应用基于文本的增强技术。例如,Ferber 等人 151 采用 GPT-4V 等高级模型从图像中提取关键信息,以促进检索肿瘤学诊断中的相关文件。同样,Ranjit 等人 73 采用多模态模型直接计算图像和文本特征之间的相似性,以便进行文档检索。值得注意的是,两项研究进行了微调
LLM 使用检索到的文档来提高诊断准确性 76,150。对于时间序列 RAG,大多数研究都集中在心电图 (ECG) 分析上 77,83,135。例如,Yu et al. 77 通过利用检索到的相关信息将基本的心电图条件转换为改进的文本描述。Yu et al. 135 构建了一个具有特定领域知识的本地数据库,用于诊断心律失常和睡眠呼吸暂停。Chen 等人 83 使用公共 ECG-Report 数据集预训练了一个模型,并微调了用于高血压和心肌梗死诊断的模型。一项研究使用 RAG 方法基于多模态 EHR72 进行再入院预测。
微调 LLM 以进行诊断
微调 LLM 通常包括两个关键阶段:监督微调 (SFT) 和来自人类反馈的强化学习 (RLHF)。在 SFT 阶段,该模型在特定于任务的指令 - 响应对上进行训练,使其能够解释指令并跨不同模态生成响应。此阶段对于建立对模型的基本理解至关重要,有助于处理输入以产生所需的输出。随后,RLHF 阶段通过使其行为与人类偏好保持一致来进一步完善模型。利用强化学习,该模型经过优化,以生成更有用、更真实且符合人类价值观的响应 155,从而确保符合社会对合乎道德和有效 AI 的期望。
医学 SFT 增强了 LLM 的上下文学习、推理、规划和角色扮演能力,从而提高了诊断性能。在此过程中,来自各种数据模态的输入被集成到 LLM 的词嵌入空间中。按照 LLaVA156 中概述的方法,首先使用图像编码器和投影仪将视觉信息转换为视觉标记嵌入。这些嵌入与 lan 的维数匹配
然后将 guage token 嵌入馈送到 LLM 中进行端到端训练。在这篇综述中,许多研究侧重于对医学文本进行 SFT 以进行诊断目的 ( . 梅迪CAL 文本可以是临床笔记 84,95,157、临床 QA 对 84,104,158-160、医学对话 100,161-164 或医疗报告 90,102,165-167。许多研究结合了医学文本和图像来增强疾病诊断 ,例如 X 射线图像 0.16.18170 RI 图像 102.17.121 或病理图像 92,106,172。一些研究还探讨了从医学视频中检测疾病 90,91,
其中,对视频帧进行采样并转换为视觉标记嵌入。为了有效地执行 SFT,收集对特定于任务的指令的高质量响应至关重要。这些说明应定义明确且多样化,涵盖广泛的场景,以确保全面的培训。
RLHF 方法可以分为两类:在线和离线。在线 RLHF 是 ChatGPT173 成功的关键过程,它首先将奖励模型拟合到提示和人类对响应的偏好数据集,然后使用 PPO 等强化学习算法来更新 LLM 以最大化学习到的奖励模型。一些探索显示了在线 RLHF可有效提高医学 LLMs 的诊断能力 97-99。例如,Zhang et al. 98他们的模型与医生的特点保持一致,并在广泛的医疗 QA 任务中取得了稳健的性能,包括病情诊断和病因分析。然而,在线 RLHF 的整体表现在很大程度上依赖于奖励模型的质量,期望对 LLM 响应给予准确的奖励,一些工作表明,奖励模型可能会出现过度优化 175 和初始数据分布偏移 176 等问题。同时,强化学习的训练过程通常以不稳定和控制挑战为特征 177。DPO178 等离线 RLHF 方法将 RLHF 转换为优化简单的分类损失,无需奖励模型。这些方法是也更稳定且计算更轻量级,并已被证明在医疗 LLM 中很有用ment96,101,179。Yang 等人 101 发现,如果去除离线 RLHF 相,他们的模型会显示医生在儿科基准上的评估性能显著下降。为了进行 RLHF,具有人类偏好的高质量提示和响应数据集对于为在线 RLHF 训练一个校准良好的奖励模型 180 或确保 DPO 更好地融合(如离线 RLHF 算法 181)至关重要,无论是来自人类专家 173 还是强大的人工智能模型 182。
随着 LLM 规模的增加,它们的功能也相应增强。因此,通常首选较大的模型,以确保适应下游任务的强大基础能力。然而,扩大模型大小会使全面训练变得越来越不切实际,因为它需要大量的 GPU 资源。参数高效微调 (PEFT) 通过最大限度地减少需要微调的参数数量,为这一挑战提供了解决方案。最流行的 PEFT 方法是低秩适应 (LoRA)183,它将可训练的秩分解矩阵引入每一层,而无需修改模型的架构。LoRA 特别受到青睐,因为它具有不增加推理延迟的优势。在本综述中,所有基于 PEFT 的研究(N=7) 使用 LoRA 来降低训练成本 84,100–102,184–186。
用于诊断的预训练 LLM
LLM 最初在广泛的文本语料库上进行预训练,以执行下一个标记预测。在这个阶段,模型学习语言的结构并获得大量关于世界的知识。当对医学文本进行预训练时,LLM 获得了基本的医学知识,这在使他们适应各种下游医疗任务(包括医学诊断)时被证明是有价值的。在这篇综述中,五项研究对 LLM 进行了纯文本预训练不同的来源 103,104,187-189,例如临床笔记、医学 QA 文本、对话和维基百科。
此外,8 项研究通过预训练将医学视觉知识注入多模态 LLMING88,105–107,189–191。例如,Chen 等人 105 和 Wang 等人 189 在视觉问答 (VQA) 数据。具体来说,Chen 等人 105 采用现成的多模态 LLM 将 PubMed 中的图像 - 文本对重新格式化为 VQA 数据点,以训练他们的模型。为了提高图像编码器的质量,常见的选择是预训练任务,例如在平铺级别或幻灯片级别重建图像 106,以及对齐相似的图像或图像 - 文本对 88。
评估策略
由于评估诊断性能至关重要,我们进一步总结和分析了诊断任务的评估策略。一般来说,现有的评估方法分为三类:自动评估、人工评估和 LLM 评估(如表 2 所示)。图 5 概述了评估策略的优点和局限性。
大多数研究使用自动指标评估诊断有效性,自动指标大致可分为三种类型。第一种类型主要使用基于分类的指标,例如准确率、精确率和召回率,这些指标适用于单一疾病预测。例如,Liu 等人 27 采用 AUC 、准确性和 F1 评分来评估 COVID-19 诊断的有效性。第二种类型通常用于多标签场景,其中预测涉及多种潜在诊断,包括 top-k 准确率和 top-k 精确率。例如,Tu et al. 194 利用 top-k 准确性来衡量出现在诊断列表前 k 位置的正确诊断的百分比。第三种类型适用于风险预测任务,其中平均绝对误差 (MAE) 或均方误差 (MSE) 衡量预测值与实际值之间的偏差
14,196 个。总之,自动指标具有时间和成本效率、易用性等优势的实施情况,以及对大规模数据的适用性。但是,它们需要真实答案,而这在许多情况下通常不可用。此外,这些指标通常缺乏以人为本的观点,例如评估预测的可靠性或整体有用性。此外,它们在评估复杂情况方面通常达不到要求,例如确定诊断推理过程在医学上是否正确 208。
许多研究通过人工努力评估诊断性能 24,209。这种方法重新依靠领域专家根据他们的医学知识评估模型预测的质量。一个优点在于它通常不需要真实答案。此外,它适应以人为本的观点,并且可以处理需要大量人类智能或领域知识的复杂任务。然而,人类评估存在一些局限性,包括大量的时间和成本需求,以及容易出现人为错误。因此,这种策略通常用于小规模数据评估。
此外,一些研究利用 LLM 来取代人类专家进行诊断评估
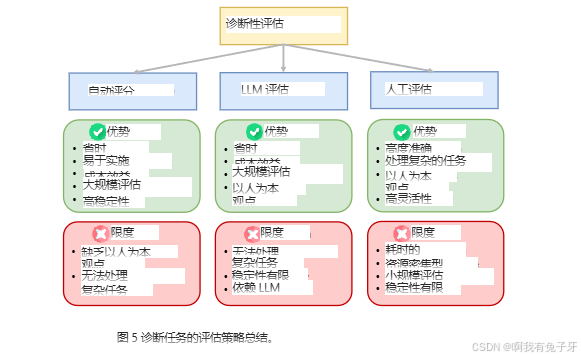
图 5 诊断任务的评估策略总结。
tion210–212。LLM 评估将以人为本的评估的优势与自动化指标的效率相结合。尽管这种方法并不严格要求真实值 205,212,但其纳入进一步提高了 LLM 评估的可靠性 209。用于此目的的常用 LLM 包括 GPT-3.5、GPT-4 和 LLaMA-3。然而,这种方法受到所采用的 LLM 性能的限制,这些 LLM 容易受到幻觉问题的影响 205。此外,基于 LLM 的评估可能难以处理复杂的临床情况 213。
综上所述,上述评价策略各有其优点和局限性。准确评估和成本效益之间的平衡因具体情况而异。我们的分析如图 5 所示,为选择合适的评估策略提供了便利,以满足各种应用的要求。
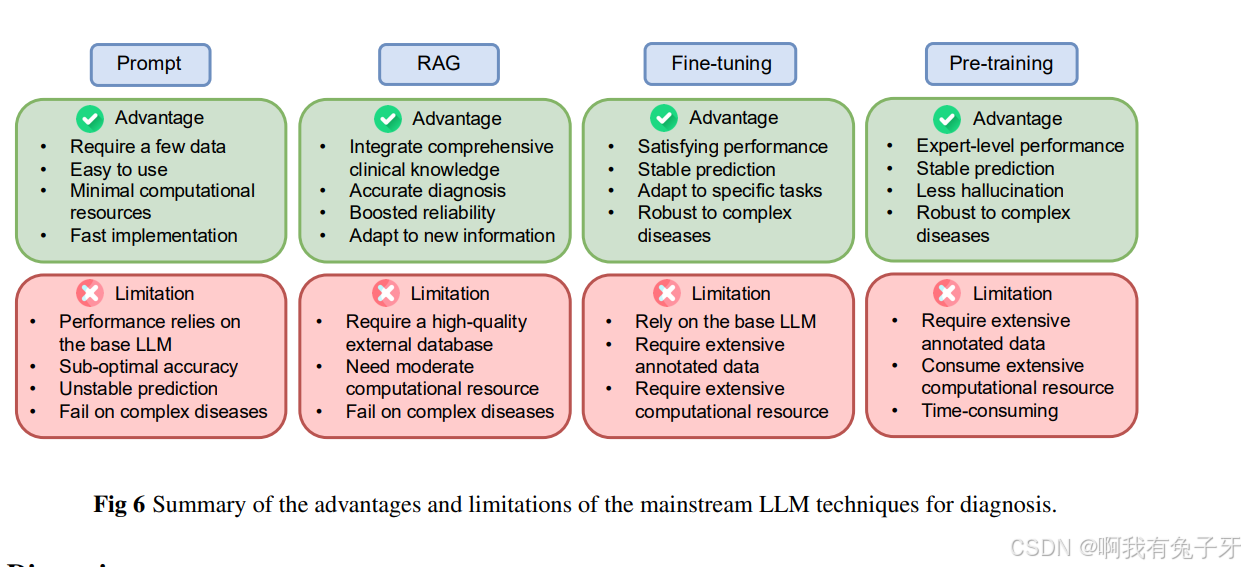
讨论
本节介绍了纳入研究的显着发现,讨论了主流 LLM 技术的数据准备,并强调了关键挑战和潜在的未来研究方向。我们的综述显示,大多数研究通过快速学习使用 LLM 进行疾病诊断。这种现象可以解释如下。首先,它需要最少的数据。例如,零样本和少数样本提示使诊断系统的发展成为可能
TEMS 只有几十个例子 39,214。其次,基于提示的方法对用户友好且需要最少的设置,使机器学习专业知识有限的研究人员能够访问它们。此外,它还显著降低了计算开销,使在普通硬件上实现成为可能。此外,如果使用得当,像 GPT-4 或 GPT-3.5 这样拥有广泛医学知识的大规模 LLM 在各种诊断任务 24,214。
我们在图 6 中总结了纳入论文的主流 LLM 技术的优势和局限性,并讨论了以下数据准备。通常,用于开发诊断系统的 LLM 技术的选择取决于可用数据的数量和质量。
具体来说,当注释数据有限时,提示工程是高度灵活和有效的。一般来说,设计一个适当的指令并辅以几个例子作为示范就足以提示 24。零样本提示甚至允许模型在没有注释示例的情况下执行诊断,同时仍能实现公平的性能 214。为了有效地将 RAG 应用于诊断,全面、高质量的外部知识库是必不可少的。此知识库可以是数据库 79、语料库 78,143 或知识图谱 70,LLM 可以在推理过程中从中检索准确的信息。有效的微调需要一个注释良好的、特定于领域的数据集,其中包括反映目标诊断任务的标记示例,例如带注释的临床记录或医学图像,以及大量样本 27。预训练需要广泛而多样的数据集,其中包含广泛的医学知识,包括非结构化文本(例如,临床笔记、医学文献)或结构化数据(例如,实验室测试结果)54,94。预训练数据集的质量和多样性对于建立该模型的基础知识及其在各种医学环境中泛化的能力。
虽然预训练和微调将实现有希望的性能和可靠性 27,190,但它们要大量资源,例如高级显卡和数百万个医疗数据,而这些资源通常很难获得。相比之下,并非所有场景都需要专家级的性能才能显示易于诊断,例如大规模筛查 8,215、移动设备的健康风险警报 58 或公共卫生教育 30,32。在准确性和成本效益之间进行权衡的平衡因场景。总之,图 6 中所示的分析指导用户根据可用资源选择合适的 LLM 技术进行疾病诊断。
尽管基于 LLM 的疾病诊断方法取得了进展,但本范围界定审查确定了阻碍其临床应用的几个障碍(图 7)。在信息收集过程中,一个显著的局限性是,只有一小部分研究整合了全面的用于诊断的 TiModal 数据 216,例如文本、图像、时间序列和其他模态。例如,邓等人 217 开发了一种多模态 LLM,其中包含文本、图像、视频和语音,用于自闭症谱系障碍筛查。这种差异与现实世界的诊断场景形成鲜明对比,在现实世界的诊断场景中,全面的患者信息跨越多种数据模式 160,特别是对于影响多个器官的复杂疾病。因此,未来的研究应强调从不同模式收集和融合信息以模拟现实世界的场景。
另一个局限性是,大多数研究隐含地假设收集的患者信息足以用于疾病诊断。然而,这种假设通常几乎不成立,尤其是在初次咨询或患有复杂疾病时,使用不完整的数据可能会导致误诊 218,219。在实践中,临床信息收集是一个迭代过程,从通过收集初始患者数据(例如,主观症状),缩小潜在诊断范围,然后进行医学检查以进一步收集数据和疾病筛查 220。此过程通常需要经验丰富的临床医生提供广泛的领域专业知识。为了减轻对专业人士的依赖,越来越多的研究正在探索诊断通过多轮对话收集相关患者信息的 Nostic 对话 221,222。
例如,AIME 使用 LLM 进行临床病史采集和诊断对话 194,而 MEDIQ 则提出后续问题以收集临床推理所需的基本信息 213。顺应这一趋势,未来的研究可以将对不完整信息的意识整合到诊断模型或开发用于自动诊断查询的高级方法 223,224。
信息集成过程中存在一些障碍。尽管在医疗场景中遵守临床指南至关重要,但只有少数研究考虑了这一因素。例如,Kresevic 等人 143 旨在通过准确解释慢性丙型肝炎病毒感染管理的医学指南来改善临床决策支持系统。未来的工作可以整合开发诊断系统的临床指南。此外,实验室测试结果的整合和解释在医疗保健中具有重要价值。例如,He et al. 225 利用 LLM 生成与实验室测试相关的响应来回答患者的疑问,从而获得患者的信任。未来的方向是利用 LLM 为专业人士和患者解释实验室测试结果。
探索临床医生、患者和诊断系统之间的互动是一个前景研究大道 221,222,226。在医疗环境中,诊断系统可以起到提供补充信息以提高 Clini 的准确性或效率的 SISTANTScians51,157,227,228。此外,这些系统应结合医学专家的反馈,方便不断完善和适应。此外,人机交互需要一个用户友好的界面。例如,医生直接与诊断系统对话,输入患者信息并进行讨论。简而言之,未来的研究可以探索诊断算法的有效应用如何进一步提高临床意义 229。
另一个障碍在于决策步骤。虽然许多研究强调诊断的准确性,但它们通常忽略了以人为本的观点,例如模型可解释性、患者隐私、安全和公平 30,230,231。具体来说,在临床情况下,仅提供诊断预测是不够的,因为 LLM 的黑盒性质通常会破坏信任 205,208。协议总的来说,为诊断提供解释性见解是必不可少的 208。例如,Dual-Inf 是一个基于提示的框架,它不仅提供潜在的诊断,还解释了它们背后的基本原理 209。在隐私方面,必须遵守《健康保险流通与责任法案》(HIPAA) 和《通用数据保护条例》(GDPR) 等法规TIAL,例如敏感信息的去标识化 25,232。迄今为止,只有少数作品调查了这个问题 80,233。例如,SkinGPT-4 是一个皮肤病学诊断系统,旨在用于本地部署以保护用户隐私 233。公平是另一个问题,确保患者不因性别、年龄或种族而受到歧视 230。解决公平性问题的研究在 LLM 中,基于 LLM 的诊断仍然有限 234,235。简而言之,未来的研究应该整合这些以人为本的诊断系统,以解决这些关键问题。
在技术方面,整合多模态数据进行疾病诊断越来越受到关注 12。然而,仍然存在一些挑战,包括消除数据噪声 236、融合来自各种模态的异构数据 237 以及执行高效学习。此外,与通用域相比,许多特定于域的 LLM 受到较小参数尺度的限制法学硕士 203,238。这可能是由于缺乏大量的语料库和计算资源。用于训练大规模医学模型的 Essary194。然而,对庞大的医学数据集进行预训练可以将更多的医学知识嵌入到 LLM 中,从而提高他们的推理能力和提高罕见病和复杂病例的性能 239,240。未来的工作也可以调查采用多个专业模型来提高诊断准确性,因为它模拟了跨学科
涉及多个临床专业的复杂疾病病例的临床讨论 80,241,242。艾迪
从本质上讲,幻觉是 LLM 中一个长期存在的问题,这严重危害了诊断系统的可靠性 243。为了减轻与数据相关的幻觉,这种幻觉植根于误mation 或来自训练数据的知识差距,未来的研究可以调查知识编辑 244 或检索外部知识 79,143 进行诊断。对于与训练相关的幻觉,即由 LLMs245 中的架构或训练策略的内在限制提出,未来的工作可以探索新颖的模型架构或预训练策略 239,246。
另一个关键领域是诊断系统的开发。许多研究使用私人数据集,由于隐私问题,通常无法访问这些数据集 143,247。然而,进步的诊断系统需要更多的公共数据可用性。另一个问题是,注释数据的稀缺性对该领域的发展构成了重大挑战。这是原因注释良好的数据集可以利用自动指标进行评估,从而减少性能评估中对大量人力的需求 209。因此,构建和发布带注释的基准数据集将为研究界做出重大贡献。此外,还应强调绩效评估。目前,没有标准化的指导方针用于评估诊断性能,特别是关于以人为本的指标 49,207,248。一个通用原则是从有效性、稳健性、可靠性和可解释性等不同方面考虑指标,从而提供全面的评估。
在实践中,诊断系统的部署仍然是一个相当大的挑战。多研究报告称,LLM 难以提供稳定的响应或预测 231,249。例如Hager 等人 231 发现,指令的变化可能导致诊断准确性的巨大明显变化。然而,在临床情况下,稳定且可重复的临床决策至关重要。因此,未来的工作可以探索确保 LLM 在诊断任务中的稳定性。另一个方向是在移动设备上部署诊断算法,这些算法可以连续自动地从人体收集基本体征和信息,例如脑电图节律和心电图节律。这使移动设备能够发送与健康相关的风险警报以进行早期预警。此外,早期诊断引起了广泛关注,并产生了重大影响值 16,237。例如,肺腺癌的早期诊断可以将 5 年生存率提高到 52%250。然而,只有少数研究为此目的利用了 LLM75,121。难点在于许多疾病在早期通常缺乏明显的症状,难以识别。未来的方向可以进一步探索如何部署诊断系统进行早期诊断。
总之,我们的研究对基于 LLM 的疾病诊断方法进行了全面回顾。我们的贡献是多方面的。首先,我们总结了疾病类型、相关的临床专业、临床数据、采用的 LLM 技术和评价方法在这个研究领域内。其次,我们比较了主流 LLM 技术和评估方法的优势和局限性,根据不同的用户需求为开发诊断系统提供了建议。第三,我们从当前的研究中确定了有趣的现象,并提供了对其根本原因的见解。最后,我们分析了当前的挑战并概述了该研究领域的未来方向。总之,我们的综述对基于 LLM 的疾病诊断进行了深入分析,概述了其蓝图,激发了未来的研究,并帮助简化了诊断系统的开发工作。
方法
检索策略和选择标准
该范围综述是根据系统评价和荟萃分析的首选报告项目 (PRISMA) 指南报告的,如图 1 所示。我们从各种资源中进行了文献检索,以查找 2019 年 1 月 1 日至 2024 年 7 月 18 日期间发表的相关文章。我们检索了七个电子数据库,包括 PubMed、CINAHL、Scopus、Web of Science、Google Scholar、ACM Digital Library 和 IEEE Xplore。检索词是根据共识专家意见选择的,并用于每个数据库(参见补充数据 1)。
我们进行了两阶段筛选过程,重点关注用于人类疾病诊断的 LLM。第一阶段涉及使用标题和摘要进行论文排除。标准如下:(a) 文章没有用英文发表;(b) 与 LLM 或基础模型无关的文章;以及 (c) 与健康领域无关的文章。第二阶段是全文筛选,强调使用语言模型完成与诊断相关的任务。我们排除了综述论文、社论和未明确用于疾病诊断的论文。值得注意的是,本综述中 “疾病诊断” 的范围并不局限于直接产生诊断的任务,例如医学
图像分类;它还包括与诊断相关的任务,例如抑郁症识别 8 和自杀风险预测 9。有关范围的详细信息,请参阅 补充数据 2 。我们还排除了关于未纳入文本模态的基础模型的研究,包括视觉基础模型。至少两名审查员独立评估了从初步筛选中保留的研究全文的最终合格性。任何分歧都通过共识或第三方成员解决。
数据提取
从文章中获得的信息包括四类。(1) 基本信息,包括标题、发布地点、发布时间(年月)、通信区域。(2) 数据相关信息,包括数据源(大洲)、数据集类型、模态(例如文本、图像、视频或文本图像)、临床专业、疾病名称、数据可用性(即私人或公共数据)和数据大小。(3) 模型相关信息,包括基础 LLM 类型、参数大小和技术类型。(4) 评估,包括评估架构(例如,自动或人工评估)和评估指标(例如,准确性和精度)。有关数据提取表的详细信息,请参阅补充表 1。
数据合成
我们综合了数据提取中的见解,以突出基于 LLM 的疾病诊断的主要主题。首先,我们介绍了我们的综述范围,涵盖与疾病相关的临床专业、临床数据、数据模式和 LLM 技术。我们还计算了元信息的统计数据,包括发展趋势、使用最广泛的 LLM 和数据源的分布。然后,我们总结了各种基于 LLM 的技术和评估
ATION 策略,分析其优缺点,并提供有针对性的建议。深入研究技术方面,我们将建模方法详细分为四类(基于提示的方法、RAG、微调和预训练)和细粒度的子类型。我们还研究了当前研究面临的挑战,并概述了潜在的未来方向。总之,我们的综合涵盖了广泛的观点,评估了数据、LLM 技术、绩效评估和应用场景的研究,这些研究符合既定的报告标准。
数据可用性
分析的数据包含在本文中。本研究中分析的汇总数据将在本文被接受后发布。

















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









