



一、项目概述
这是一个完整的金融数据分析Web应用系统,使用Python的Streamlit框架构建,实现从数据获取、处理到可视化展示的全流程分析。系统专注于申万家用电器行业和沪深300指数的深度分析,共包含10个核心步骤。
二、系统架构设计
2.1 技术栈
-
前端框架: Streamlit
-
数据处理: pandas
-
可视化: matplotlib + matplotlib.dates
-
核心语言: Python
2.2 适用领域
金融分析、数据可视化、Web应用开发
2.3 数据集准备
数据来源:Tushare数据


三、核心功能逻辑
3.1 主程序架构
Steps是从行业筛选 → 财务分析 → 数据处理 → 主成分分析 → 交易分析 → 指数构建 → 基准对比 → 技术分析,这实际上是一个从宏观到微观、从基本面到技术面的完整分析链。
# 1. 导入模块和库
import streamlit as st
import step1, step2, step3, step4, step5, step6, step7, step8, step9, step10
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# 2. 页面配置
st.set_page_config(
page_title="多步骤金融分析系统",
layout='wide',
)
# 3. 步骤定义
STEPS = [
'1.申万家用电器行业股票代码获取',
'2.申万家用电器行业股票财务指标数据获取',
'3.申万家用电器行业股票财务指标数据处理',
'4.主成分累计贡献率在95%',
'5.家电行业2017年的股票交易数据',
'6.家用电器行业交易指数',
'7.沪深300指数年度涨跌幅',
'8.沪深300指数2016年指数的关键转折点',
'9.沪深300指数2016年平均收盘',
'10.沪深300指数2016年收盘指数的现价指标'
]3.2 数据预加载机制
# 读取.py文件内容
def read_py_file(file_path):
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
# 预加载所有代码内容
CODE_CONTENTS = {}
for i in range(1, 11):
CODE_CONTENTS[i] = read_py_file(f"step{i}.py")
# 预加载原始数据文件
ORIGINAL_DATA = {
1: pd.read_excel('申万行业分类.xlsx'),
2: pd.read_excel('上市公司财务与指标数据2013-2017.xlsx'),
5: pd.read_excel('股票交易数据_2017.xlsx'),
}
# 加载沪深300数据(多个步骤共用)
hs300_data = pd.read_excel('沪深300指数交易数据表.xlsx')
for i in [7, 8, 9, 10]:
ORIGINAL_DATA[i] = hs300_data3.3 模块化步骤处理
# 获取步骤编号
def get_step_number(step_name):
return int(step_name.split('.')[0])
# 显示原始数据
def show_original_data(step_num):
st.subheader('原始数据(取前100条) ')
if step_num in ORIGINAL_DATA:
data = ORIGINAL_DATA[step_num]
if step_num == 3:
data = step2.return_values()
elif step_num == 4:
data = pd.DataFrame(step3.return_values()[0])
elif step_num == 6:
data = step5.return_values()
st.dataframe(data.head(100), use_container_width=True)
# 显示代码
def show_code(step_num):
st.subheader('代码 ')
st.code(CODE_CONTENTS[step_num], language='python')3.4 各步骤功能模块
每个步骤的处理逻辑完全独立,不会互相干扰。
Step1.py: 申万家用电器行业股票代码获取
# -*- coding: utf-8 -*-
#1.读取“申万行业分类.xlsx”表,字段如下所示:
# 行业名称 股票代码 股票名称
# 获得“家用电器”行业的所有上市公司股票代码和股票简称
# 结果用序列Fs来表示,其中index为股票代码、值为股票简称
def return_values():
import pandas as pd
A=pd.read_excel('申万行业分类.xlsx')
F = A[A['行业名称']=='家用电器']
Fs = pd.Series(F['股票名称'].values,index=F['股票代码'])
return FsStep2.py: 申万家用电器行业股票财务指标数据获取
# -*- coding: utf-8 -*-
'''
基于上一关的结果,读取“上市公司财务与指标数据2013-2017.xlsx”数据,其中字段依次为:
Stkcd、Accper、B001101000 、B001300000、B001000000、B002000000、A001000000、
A001212000、F050501B、F091301A、F091001A、F090101B
中文名称依次为股票代码、会计期间、财务与指标(教材第8章中总体规模与投资效率指标)
任务为:筛选出家用电器行业股票代码2016年的财务与指标数据,字段同原数据表,记为data
'''
def return_values():
import pandas as pd
import step1
r=step1.return_values()
stkcd=list(r.index)
A=pd.read_excel('上市公司财务与指标数据2013-2017.xlsx')
A=A.iloc[A.iloc[:,1].values=='2016-12-31',:]
data = A[A['Stkcd'].isin(stkcd)]
return dataStep3.py: 申万家用电器行业股票财务指标数据处理
# -*- coding: utf-8 -*-
'''
在上一关基础上,对筛选出的家用电器行业股票代码2016年的财务与指标数据,
去掉空缺值、作均值-方差标准化处理,返回结果x(数组)和股票代码code(列表)
'''
def return_values():
import step2
data=step2.return_values() #上一关的结果,家用电器行业股票代码2016年的财务与指标数据
data = data.dropna() #删除缺失值
code = data['Stkcd'].tolist() #转化为列表.tolist()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() #创建对象
# 提取所有数值列
num = data.select_dtypes(include=['number'])
x = num.values # 直接获取数值数组
scaler.fit(x) #调用fit()拟合方法
x = scaler.transform(x)
return (x,code)Step4.py: 主成分累计贡献率在95%
# -*- coding: utf-8 -*-
'''
在上一关基础上,对去掉缺失值和标准化后的x,进行主成分分析,
并提取主成分,要求累计贡献率在95%
'''
def return_values():
import step3
from sklearn.decomposition import PCA
r = step3.return_values()
x = r[0]
#导入主成分分析模块PCA
#创建分析对象y
y = PCA(n_components=0.95) #贡献率为0.95
y.fit(x) #对待分析的数据进行拟合训练
Y = y.transform(x) #返回提取的主成分
return YStep5.py: 家电行业2017年的股票交易数据
# -*- coding: utf-8 -*-
"""
在第一关的基础上,读取"股票交易数据_2017.xlsx"表,字段如下:
Stkcd、Trddt、Clsprc、Dnshrtrd、Dnvaltrd、Opnprc、Hiprc、Loprc,
中文名称依次为:股票代码、交易日期、收盘价、成交量、成交额、开盘价、最高价、最低价。
任务为:筛选出家电行业2017年的股票交易数据,字段同原表,记为data
"""
def return_values():
import pandas as pd
import step1
r=step1.return_values()
stkcd=list(r.index)
A=pd.read_excel('股票交易数据_2017.xlsx')
data = A[A['Stkcd'].isin(stkcd)]
return dataStep6.py: 家用电器行业交易指数
# -*- coding: utf-8 -*-
'''
在上一关基础上,构造家用电器行业交易指数,其中指数计算公式为:
当日指数=当日总交易额/基准日总交易额*100
其中当日总交易额=当日所有股票交易额之和,基准日为2017年首个交易日,
返回index_val
'''
def return_values():
import step5
data=step5.return_values()
data_total = data.groupby('Trddt')['Dnvaltrd'].sum()
# 获取基准日
d = data_total.index.min()
#交易额
d_amount = data_total[d]
# 指数=当日总交易额/基准日总交易额*100
index_val = (data_total / d_amount * 100)
return index_valStep7.py: 沪深300指数年度涨跌幅
# -*- coding: utf-8 -*-
'''
"读取沪深300指数交易数据表.xlsx",字段依次为:
Indexcd、Idxtrd01、Idxtrd05
中文名称依次为:指数代码、交易日期、收盘指数
分别计算2014-2017年的年度涨跌幅,
其中年度涨跌幅=(年末收盘指数-年初收盘指数)/年初收盘指数
依次返回年度涨跌幅(r1,r2,r3,r4)
'''
def rdata(date1,date2,A):
#定义一个计算年度涨跌幅的函数
#输入:年初日期date1、年末日期date2、交易数据A
#返回:涨跌幅r
#获取年初的收盘指数
start_data = A[A['Idxtrd01'] >= date1].iloc[0]
start_price = start_data['Idxtrd05']
#获取年末的收盘指数
end_data = A[A['Idxtrd01'] <= date2].iloc[-1]
end_price = end_data['Idxtrd05']
#年度涨跌幅=(年末收盘指数-年初收盘指数)/年初收盘指数
r = (end_price - start_price) / start_price
return r
def return_values():
import pandas as pd
A=pd.read_excel('沪深300指数交易数据表.xlsx')
r1=rdata('2014-01-01','2014-12-31',A)
r2=rdata('2015-01-01','2015-12-31',A)
r3=rdata('2016-01-01','2016-12-31',A)
r4=rdata('2017-01-01','2017-12-31',A)
return (r1,r2,r3,r4)Step8.py: 沪深300指数2016年指数的关键转折点
# -*- coding: utf-8 -*-
'''
序列x1,x2,x3,如果|x2-(x1+x2)/2|越大,x2成为关键转折点的可能性就越大。
"读取沪深300指数交易数据表.xlsx",字段依次为:
Indexcd、Idxtrd01、Idxtrd05
中文名称依次为:指数代码、交易日期、收盘指数
请计算获得2016年指数的关键转折点20个,包括年初和年末的两个点。
并输出结果,用一个序列Fs来表示,其中index为序号,值为收盘指数。
注意:序号按年度实际交易日期从0开始编号
'''
def return_values():
import pandas as pd
import numpy as np
A=pd.read_excel('沪深300指数交易数据表.xlsx')
I1=A.iloc[:,1].values>='2016-01-01'
I2=A.iloc[:,1].values<='2016-12-31'
data=A.iloc[I1&I2,:].sort_values(['Idxtrd01'])
turn_points = []
p = data['Idxtrd05'].values #价格
for i in range(1, len(p) - 1):
#转折点 |x2-(x1 + x3)/2|
a = abs(p[i] - (p[i-1] + p[i+1]) / 2)
turn_points.append((i,a,p[i]))
#转折18个点,加上首尾就20个
turn_points.sort(key=lambda x: x[1], reverse=True)
sel_points = turn_points[:18]
# 提取索引
sel_i = []
for point in sel_points:
sel_i.append(point[0])
#提取价格
sel_p = []
for point in sel_points:
sel_p.append(point[2])
#添加首尾两个点
sel_i = [0] + sel_i + [len(p)-1]
sel_p = [p[0]] + sel_p + [p[-1]]
#创建keydata序列
keydata = pd.Series(sel_p, index=sel_i)
return keydataStep9.py: 沪深300指数2016年平均收盘
# -*- coding: utf-8 -*-
'''
"读取沪深300指数交易数据表.xlsx",字段依次为:
Indexcd、Idxtrd01、Idxtrd05
中文名称依次为:指数代码、交易日期、收盘指数
请计算获得2016年收盘指数的10、20、30、60日移动平均收盘指数,
返回结果为(x10,x20,x30,x60),其中xi为序列,index按年度实际交易天数从0开始编号
'''
def return_values():
import pandas as pd
A=pd.read_excel('沪深300指数交易数据表.xlsx')
I1=A.iloc[:,1].values>='2016-01-01'
I2=A.iloc[:,1].values<='2016-12-31'
rdata=A.iloc[I1&I2,:].sort_values(['Idxtrd01'])
#计算移动平均
x10 = rdata['Idxtrd05'].rolling(window=10).mean()
x20 = rdata['Idxtrd05'].rolling(window=20).mean()
x30 = rdata['Idxtrd05'].rolling(window=30).mean()
x60 = rdata['Idxtrd05'].rolling(window=60).mean()
#索引从0开始
x10 = x10.reset_index(drop=True)
x20 = x20.reset_index(drop=True)
x30 = x30.reset_index(drop=True)
x60 = x60.reset_index(drop=True)
return (x10,x20,x30,x60)Step10.py: 沪深300指数2016年收盘指数的现价指标
# -*- coding: utf-8 -*-
'''
"读取沪深300指数交易数据表.xlsx",字段依次为:
Indexcd、Idxtrd01、Idxtrd05
中文名称依次为:指数代码、交易日期、收盘指数
请计算获得2016年收盘指数的现价指标,其公式为:
现价=当日收盘指数 / 过去 10 个交易日的移动平均收盘指数
返回结果为p10,为序列,index按年度实际交易天数从0开始编号
'''
def return_values():
import pandas as pd
A=pd.read_excel('沪深300指数交易数据表.xlsx')
I1=A.iloc[:,1].values>='2016-01-01'
I2=A.iloc[:,1].values<='2016-12-31'
rdata=A.iloc[I1&I2,:].sort_values(['Idxtrd01'])
#10日移动平均收盘指数
ma10 = rdata['Idxtrd05'].rolling(window=10).mean()
#现价=当日收盘指数 / 过去 10 个交易日的移动平均收盘指数
p10 = rdata['Idxtrd05'] / ma10
#重置索引,drop=True——去掉原先索引
p10 = p10.reset_index(drop=True) #reset_index()——重置索引
return p103.5 步骤管理系统
从步骤名称中提取编号,例如"1.申万家用电器行业股票代码获取" → 提取数字"1"。
# 获取步骤编号
def get_step_number(step_name):
return int(step_name.split('.')[0])3.6 智能数据展示系统
根据步骤号动态选择数据源;只显示前100条数据,避免页面卡顿。
def show_original_data(step_num):
st.subheader('原始数据(取前100条) ')
if step_num in ORIGINAL_DATA:
data = ORIGINAL_DATA[step_num]
# 特殊步骤的数据处理
if step_num == 3:
data = step2.return_values() # 使用前一步的结果
elif step_num == 4:
data = pd.DataFrame(step3.return_values()[0]) # 多维数据转换
elif step_num == 6:
data = step5.return_values() # 引用其他模块结果
st.dataframe(data.head(100), use_container_width=True) #自适应布局:use_container_width=True让表格适应容器宽度3.7 代码透明度设计
每个step步骤对应的Python代码都显示在网页上,支持语法高亮,便于阅读和学习。
def show_code(step_num):
st.subheader('代码 ')
st.code(CODE_CONTENTS[step_num], language='python')3.8 导航与界面布局
# 侧边栏 - 导航控制中心
with st.sidebar:
st.subheader('请选择实验')
selected_step = st.selectbox(" ", STEPS) # selectbox(" ", STEPS)的空格占位使界面更简洁
# 主内容区域 - 动态显示标题
step_num = get_step_number(selected_step)
st.subheader(f'//{selected_step}//')3.9 模块化步骤执行系统
# 步骤1:股票代码获取
if step_num == 1:
r = step1.return_values()
stock_codes = [str(code).zfill(6) for code in r.index]
result_df = pd.DataFrame({'股票代码': stock_codes, '股票简称': r.values})
st.dataframe(result_df)
# 步骤2:财务数据获取(直接展示)
elif step_num == 2:
r = step2.return_values()
st.dataframe(r)
# 步骤3:财务数据处理(组合展示)
elif step_num == 3:
x, code = step3.return_values()
df = pd.DataFrame(x)
df['Stkcd'] = code # 添加股票代码列
st.dataframe(df)
# 步骤4
elif step_num == 4:
r = step4.return_values()
df = pd.DataFrame(r)
st.dataframe(df)
# 步骤7
elif step_num == 7:
r = step7.return_values()
df = pd.DataFrame(r)
st.dataframe(df)
# 步骤10
elif step_num == 10:
r = step10.return_values()
df = pd.DataFrame(r)
st.dataframe(df)3.10 高级可视化子系统
step5:股票走势可视化
多只股票对比,采用多线图,每条线代表一只股票,数据自动选取前5只股票,避免图表过于拥挤;使用groupby按股票代码分组绘制。
elif step_num == 5:
# 数据处理
df['Trddt'] = pd.to_datetime(df['Trddt'], format='%Y-%m-%d')
# 可视化配置
plt.rcParams['font.sans-serif'] = 'SimHei'
st.subheader('可视化走势图 ')
top5_stocks = df['Stkcd'].unique()[:5] # 只显示前5只股票
plot_data = df[df['Stkcd'].isin(top5_stocks)]
# 多线图绘制
plt.figure(figsize=(10, 5))
for code, group in plot_data.groupby('Stkcd'):
plt.plot(group['Trddt'], group['Clsprc'], markersize=3, label=str(code))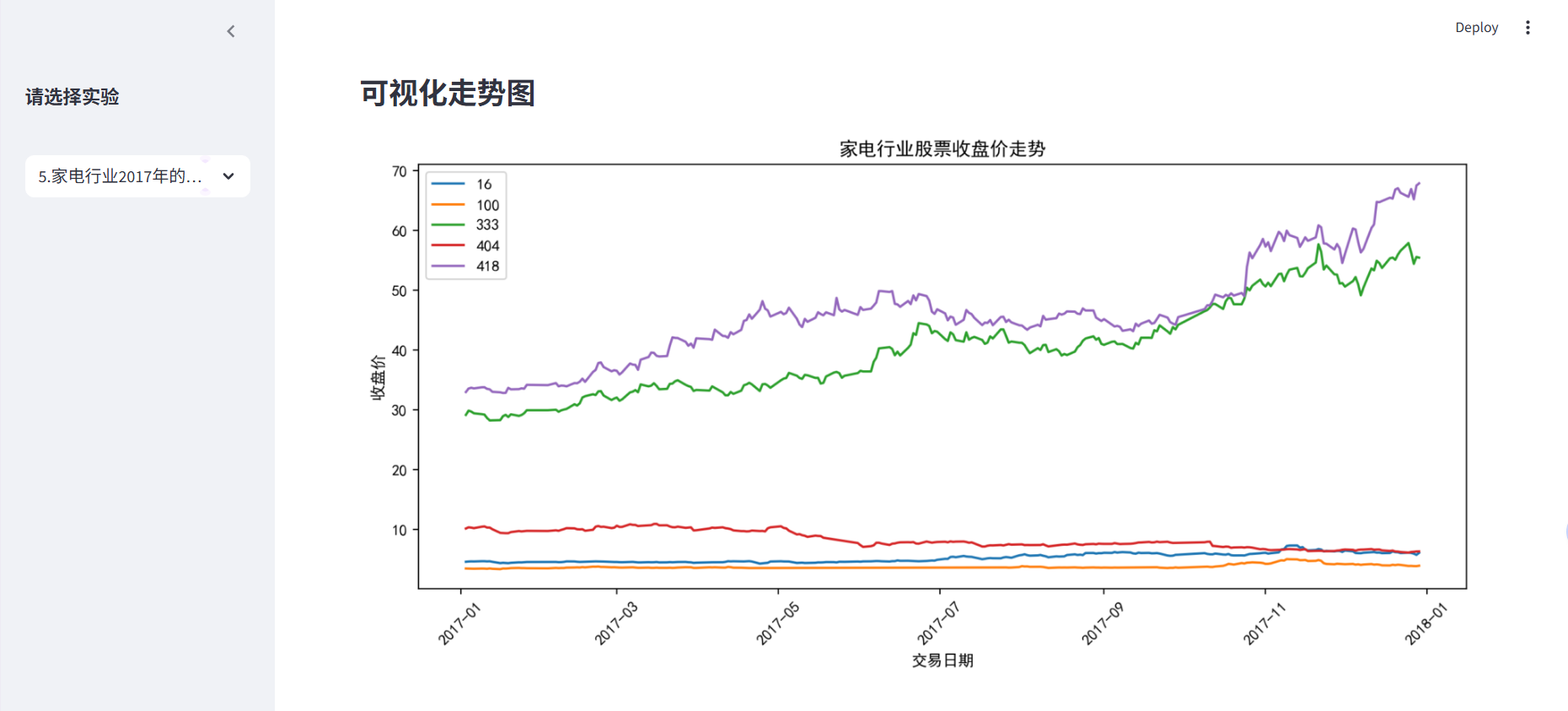
step6:行业指数可视化
单一指数走势,采用单线图,重点是时间序列模式。
# 专业的时间序列处理
df['Trddt'] = pd.to_datetime(df['Trddt'], format='%Y-%m-%d')
df = df.sort_values('Trddt') # 按日期排序
plt.rcParams['font.sans-serif'] = 'SimHei'
# 创建图表对象
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制指数走势(限制前501个数据点)
ax.plot(df['Trddt'][:501], df['行业指数'][:501], linewidth=2, color='blue', label='指数走势')
# 专业的时间轴格式化
ax.xaxis.set_major_locator(mdates.MonthLocator()) # 按月设置刻度
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m')) # 格式为年月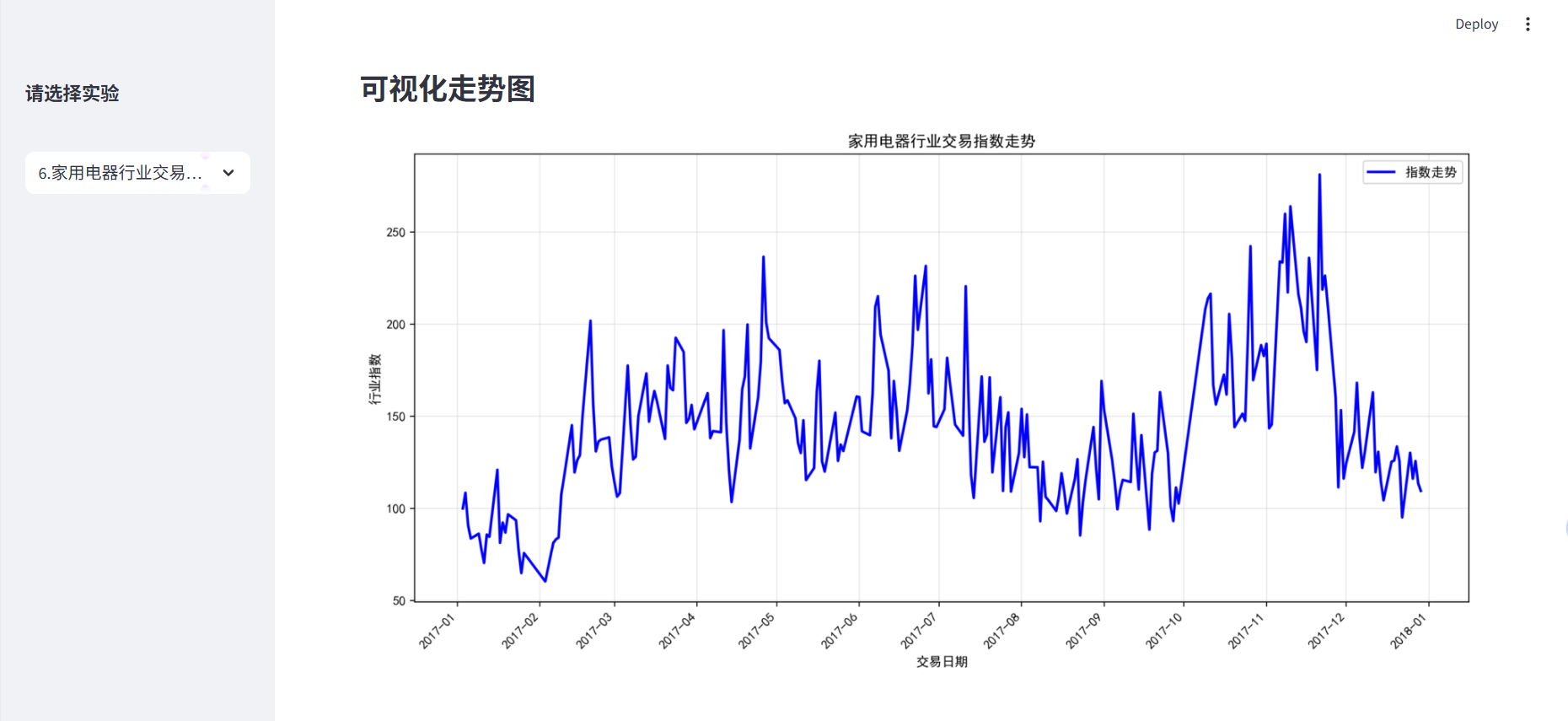
step8:转折点分析可视化
关键点位识别,采用折线+散点图,突出特殊点位。
# 数据准备
rdata['交易天数'] = range(len(rdata)) # 创建连续的交易天数序列
# 中文显示配置
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 绘制基础折线图
ax.plot(rdata['交易天数'], rdata['Idxtrd05'], 'b-', alpha=0.9, label='指数序列', linewidth=1.2)
# 高亮转折点
ax.scatter(r.index, r.values, color='red', s=25, edgecolor='black', linewidth=0.8, zorder=5, label='转折点') # zorder=5确保散点图在折线图上方
# 样式优化
ax.spines['top'].set_visible(False) # 隐藏上边框
ax.spines['right'].set_visible(False) # 隐藏右边框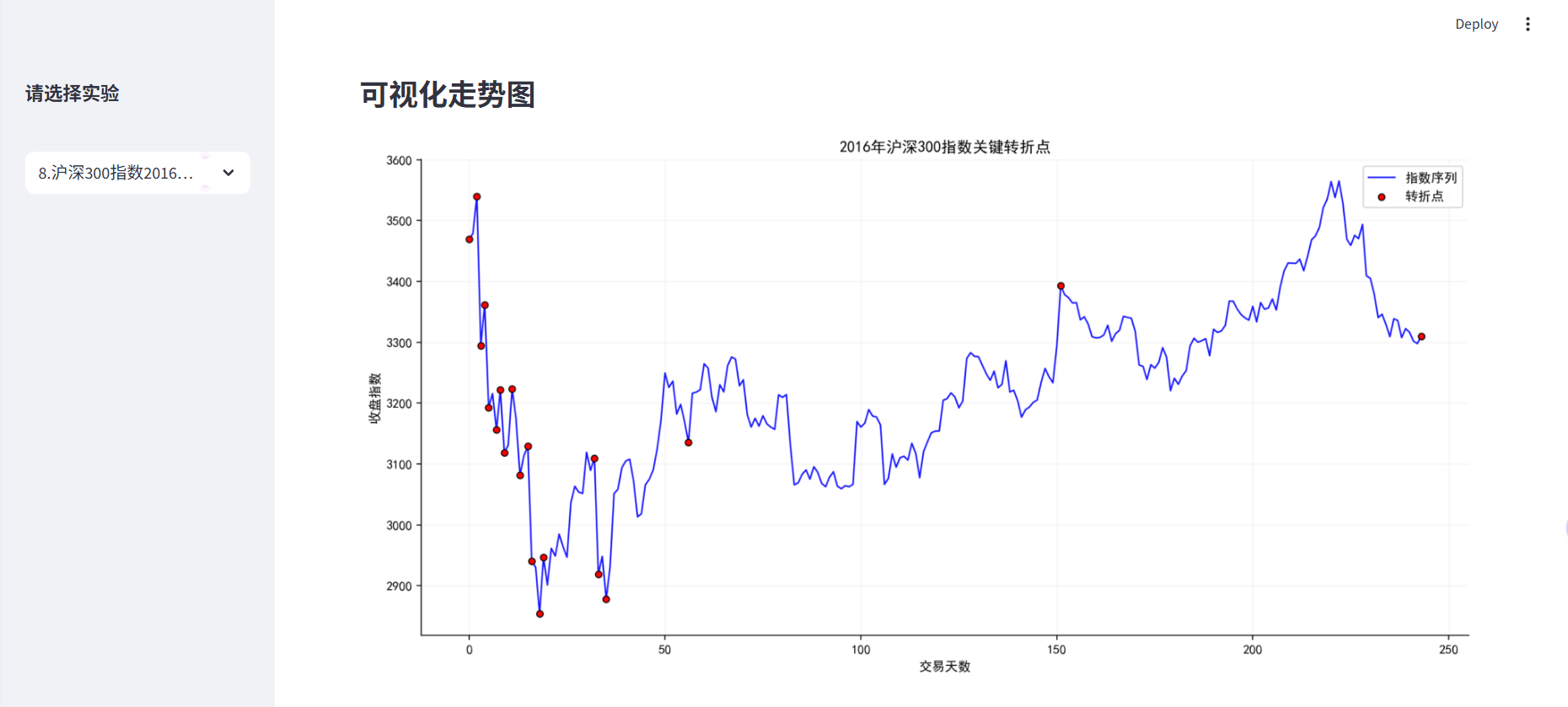
step9:移动平均线可视化
多周期分析,采用多线叠加图,展示不同周期的趋势。
# 多线图绘制(4条移动平均线)
plt.plot(rdata['Idxtrd01'], x10, label='10日移动平均', linewidth=1, color='blue')
plt.plot(rdata['Idxtrd01'], x20, label='20日移动平均', linewidth=1, color='orange')
plt.plot(rdata['Idxtrd01'], x30, label='30日移动平均', linewidth=1, color='green')
plt.plot(rdata['Idxtrd01'], x60, label='60日移动平均', linewidth=1, color='red')
# 图表样式配置
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title('2016年沪深300指数移动平均线', fontsize=14)
plt.ylabel('指数点位', fontsize=12)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.2) # 半透明网格
plt.xticks(rotation=45) # x轴标签旋转45度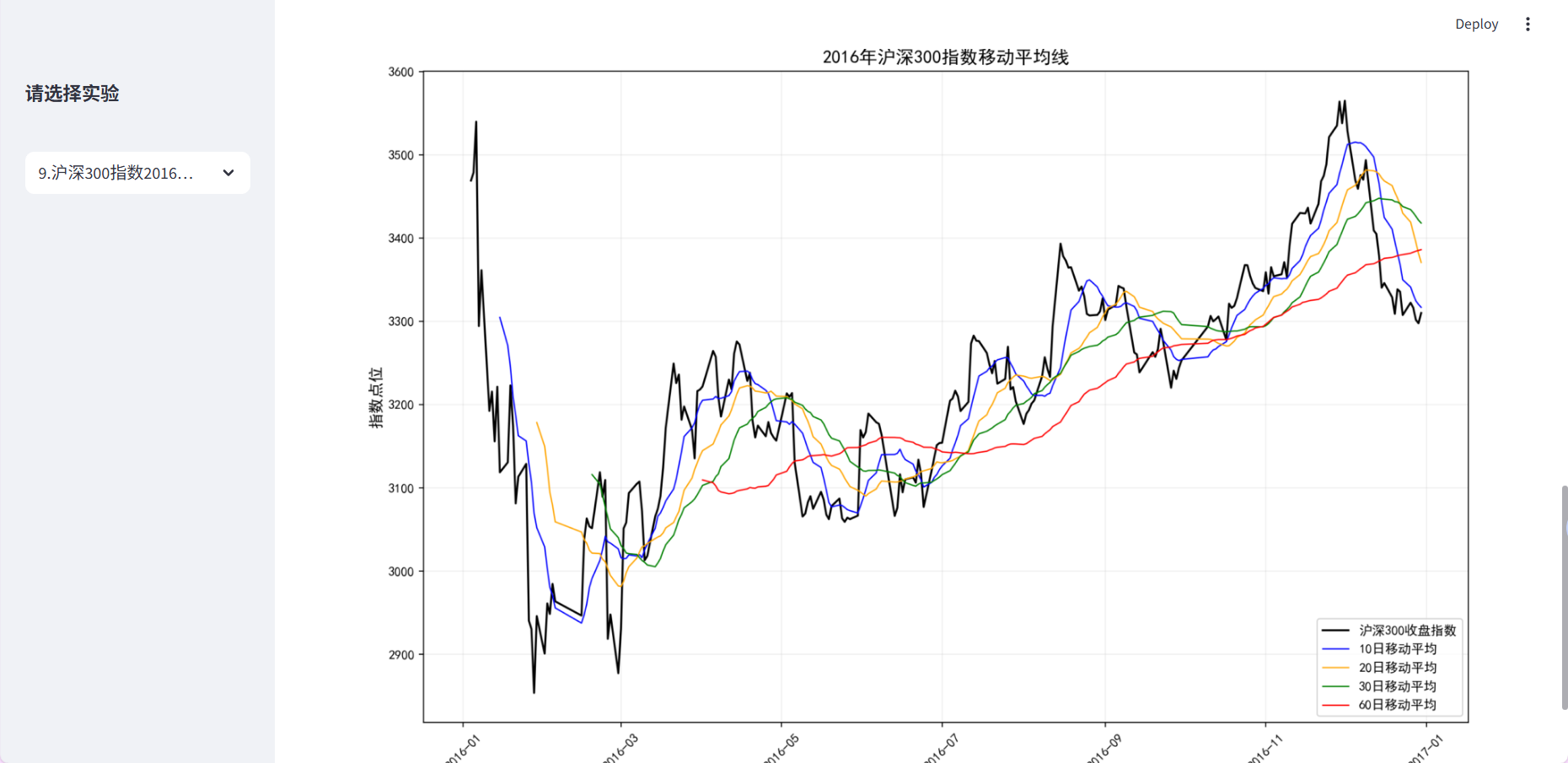
四、技术亮点
4.1 模块化与数据智能管理
-
10步模块化设计:将复杂的金融分析拆解为独立步骤,每个模块功能单一、接口统一
-
智能数据流:支持原始数据、中间结果、最终分析的自动流转与共享,如沪深300数据一次加载多步骤复用
4.2 专业可视化与用户体验
-
金融级可视化:内置多种专业图表(股票走势、行业指数、技术指标),支持时间序列优化显示
-
一体化界面:侧边栏导航配合"原始数据-代码-结果-可视化"四段式布局,操作直观、分析透明
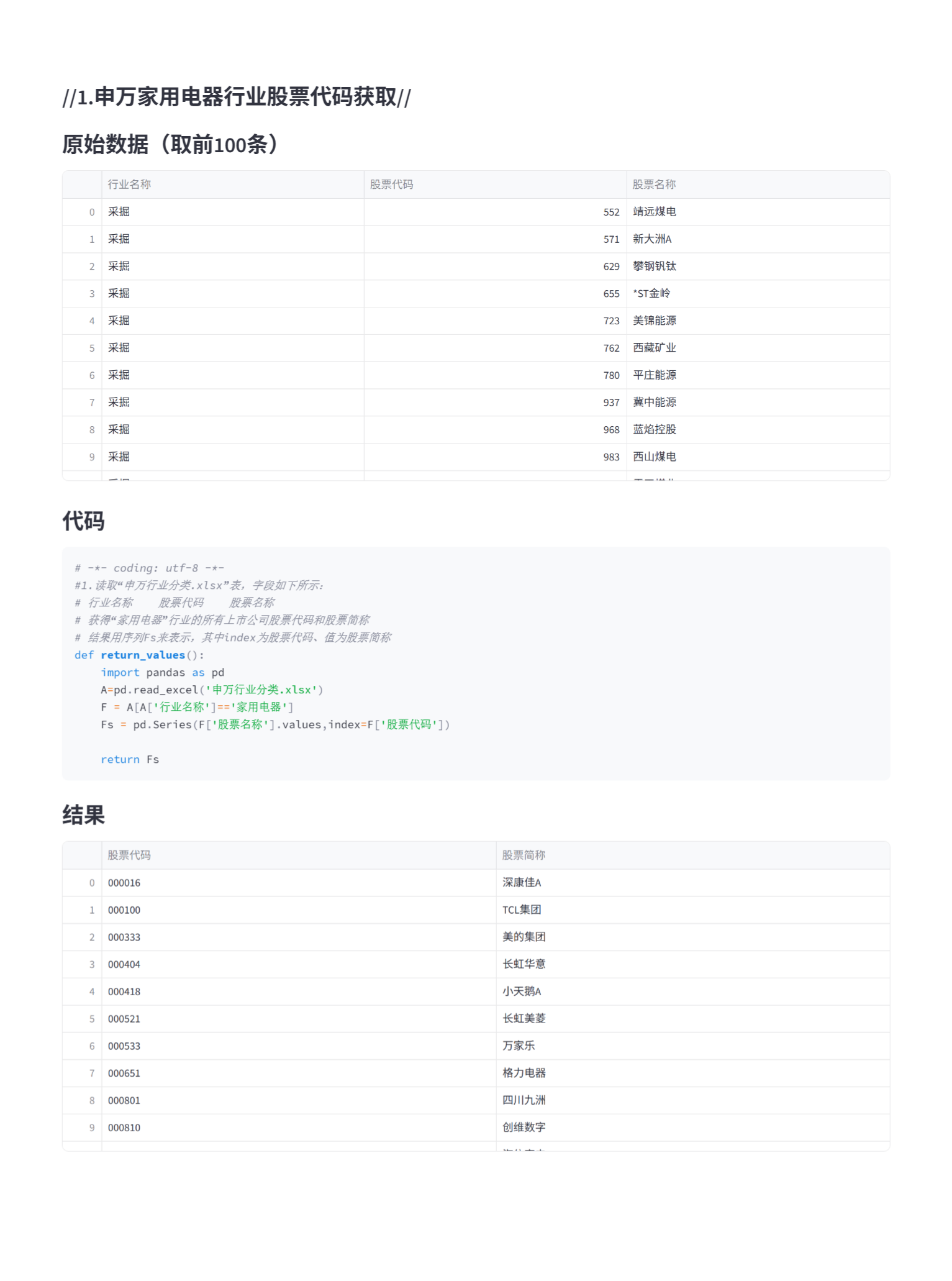
五、Streamlit页面部分展示
六、总结
这个项目展示了如何将复杂的金融数据分析任务分解为清晰的步骤,并通过现代化的Web界面呈现,是一个功能完整的分析工具,涵盖数据科学项目从数据处理到结果展示的全过程;这个系统可以作为金融数据分析的入门项目,也可以作为企业级分析工具的雏形进行进一步开发。

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









