



一、项目概述
在当今数据驱动的投资时代,如何快速、准确地分析行业趋势和个股表现成为投资决策的关键。本文介绍一个基于Streamlit的行业股票分析与综合评价系统,该系统整合行业指数分析、个股价格走势、财务数据挖掘和综合评价模型,系统采用Python + Streamlit技术栈,通过直观的Web界面实现复杂的数据分析功能。
数据处理流程:读取数据 → 筛选行业 → 清洗整理 → 分析计算 → 可视化展示
二、数据准备

· 数据来源:Tushare数据
1. 财务数据.csv包含字段:

2. 股票基本信息表.xlsx包含字段:

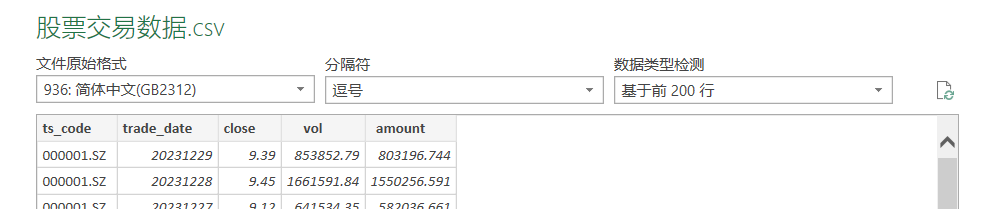
3. 股票交易数据.csv包含字段:
4. 上市公司基本信息表.xlsx包含字段:

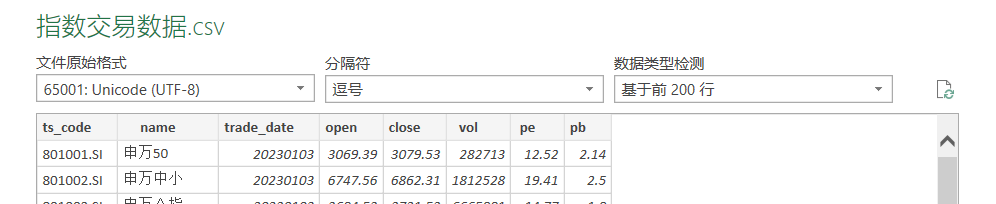
5. 指数交易数据.csv包含字段:
6. 最新个股申万行业分类(完整版-截至7月末).xlsx包含字段:

7. 导入包
import pandas as pd # 数据处理库,用于读取、处理和分析表格数据
import matplotlib.pyplot as plt # 绘图
import streamlit as st # Web应用框架三、核心功能模块详解
1. 行业指数分析模块
排序的重要性:时间序列数据必须按时间排序,否则绘图会出现乱序问题
def st_data(nm, info, selected_year, top_n):
# nm--申万行业名称
# info--申万行业分类表
# selected_year: 选择的年份
# top_n: 显示前N名
# 1.读取相关数据
data=pd.read_csv('指数交易数据.csv')
trdata=pd.read_csv('股票交易数据.csv')
findata=pd.read_csv('财务数据.csv')
co_data=pd.read_excel('上市公司基本信息.xlsx')
# 2.筛选指定行业的行业指数交易数据,并要求行业指数交易数据大于600条记录,同时返回该交易数据
data_i=data.iloc[data['name'].values==nm,:]
data_i=data_i.sort_values(['trade_date'])
# 重命名列名(中文更易读)
data_i.columns=['指数代码','行业名称','交易日期','开盘指数','收盘指数','成交量','市盈率','市净率']
# 初始化三个变量为None,防止未定义错误
f1 = None
f2 = None
eval_result = None2. 数据可视化图表
# 检查行业指数数据是否足够 >600
if len(data_i)>600:
# 3.绘制行业收盘指数走势图,返回图像句柄变量f1
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体
plt.figure(1)
f1,ax=plt.subplots()
plt.title('申万'+nm+'行业指数走势图')
x1=data_i['交易日期'].values
y1=data_i['收盘指数'].values
plt.plot(range(len(x1)),y1)
# x轴显示部分日期标签,避免重叠
plt.xticks([0,100,200,300,400,500,600],x1[[0,100,200,300,400,500,600]],rotation=45)
# 4.关联获得行业相关的上市公司基本信息co_data和相关股票交易数据trdata_hy,并返回
chy_code=info.iloc[(info['新版一级行业'].values==nm)&(info['交易所'].values=='A股'),[2,3]]
chy_code.columns=['ts_code','nm']
co_data=pd.merge(co_data,chy_code,how='inner',on='ts_code')
trdata_hy=pd.merge(trdata,chy_code,how='inner',on='ts_code')
trdata_hy=trdata_hy.sort_values(['ts_code','trade_date'])
trdata_hy.columns=['股票代码','交易日期','收盘价','成交量','成交金额','股票简称']
# 5.绘制行业相关股票交易数据走势图(子图,选6个股票,要求交易记录大于600条),并返回图像句柄变量f2
code=list(set(trdata_hy['股票代码'].values))
plt.figure(2)
plt.figure(figsize=(12,8))
f2,ax=plt.subplots()
p=0
for i in range(len(code)):
trdata_k=trdata_hy.iloc[trdata_hy['股票代码'].values==code[i],[1,2,-1]]
if len(trdata_k)>600:
p=p+1
trdata_k.index=range(len(trdata_k))
x2=trdata_k['交易日期'].values
y2=trdata_k['收盘价'].values
plt.subplot(3,2,p)
plt.title(trdata_k.iloc[0,2])
plt.plot(range(len(x2)),y2)
plt.xticks([0,100,200,300,400,500,600],x2[[0,100,200,300,400,500,600]],rotation=45)
if p==6:
break
plt.tight_layout()3. 综合评价函数
- 数据清洗策略:
-
按年度筛选:确保横向可比性
-
删除关键指标缺失值:避免无效计算
-
使用
subset参数:只检查指定列的缺失值,保留其他有用信息
- 数据标准化选择Min-Max:得分在[0,1]区间,直观易懂
- 利用主成分分析做为综合得分:
在主成分分析(PCA)中,其核心价值在于客观确定权重和简化比较维度。我们有两个指标:规模得分(来自总资产)和效率得分(来自净资产收益率)。如果人为给它们分配权重(比如各占50%),会带入主观偏见。PCA则通过数学方法,自动找出最能代表这两个指标综合信息的组合方式,生成一个公平的“综合得分”。这样做的另一个好处是化繁为简,原本要同时考虑规模和效率两个维度来判断公司优劣,现在只需要看一个综合得分就能排名,既保留了大部分原始信息,又让结果一目了然。
# 综合评价函数
def F_score(findata,selected_year,top_n):
#计算总体规模与投资效率的综合得分+排名
# 1.筛选指定年份的财务数据
findata_year = findata[findata['年度'] == selected_year]
findata_year = findata_year.dropna(subset=['总资产', '净资产收益率']) #缺失值处理
if len(findata_year) == 0:
return pd.DataFrame(columns=['股票代码', '股票简称', '总资产', '净资产收益率', '综合得分'])
# 2.数据标准化处理
# Min-Max归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# 规模得分--总资产
findata_year['规模得分'] = scaler.fit_transform(findata_year[['总资产']])
# 效率得分--净资产收益率
findata_year['效率得分'] = scaler.fit_transform(findata_year[['净资产收益率']])
# 3.主成分分析(PCA)
from sklearn.decomposition import PCA
#提取需要分析的指标列
pca_data = findata_year[['规模得分', '效率得分']]
#初始化PCA,提取1个主成分
pca = PCA(n_components=1)
#计算主成分得分
findata_year['主成分得分'] = pca.fit_transform(pca_data)
#主成分得分直接作为综合得分
findata_year['综合得分'] = findata_year['主成分得分']
# 4.排序返回结果
result = findata_year.sort_values('综合得分', ascending=False).head(top_n) #降序排名
return result[['股票代码', '股票简称', '总资产', '净资产收益率', '综合得分']]4. Streamlit界面函数
def st_fig():
# 1.获取所有行业名称列表,默认选择第一个
info=pd.read_excel('最新个股申万行业分类(完整版-截至7月末).xlsx')
nm_L=list(set(info['新版一级行业'].values))
nm=nm_L[0]
# 2. 页面配置:设置页面的标题、图标和布局
st.set_page_config(
page_title="基于总体规模与投资效率的综合评价", # 页面标题
layout='wide',
)
# 3.侧边栏
with st.sidebar:
st.subheader('请选择指数&行业')
nm = st.selectbox(" ", nm_L)
# 4.数据显示布局
if nm:
r=st_data(nm,info, selected_year=None, top_n=None)
left, right = st.columns(2)
with left:
st.subheader('指数走势图')
st.pyplot(r[0])
with right:
st.subheader('前6只股票价格走势图')
st.pyplot(r[1])
# 5.数据显示
st.subheader('指数交易数据')
st.dataframe(r[2],use_container_width=True) # 添加',use_container_width=True'——实现自适应
st.subheader('相关上市公司基本信息')
st.dataframe(r[5])
st.subheader('相关上市公司股票财务数据')
st.dataframe(r[3])
st.subheader('相关上市公司股票交易数据(前2000条)')
st.dataframe(r[4].iloc[:2000,],use_container_width=True)
# 6.综合评价选择器
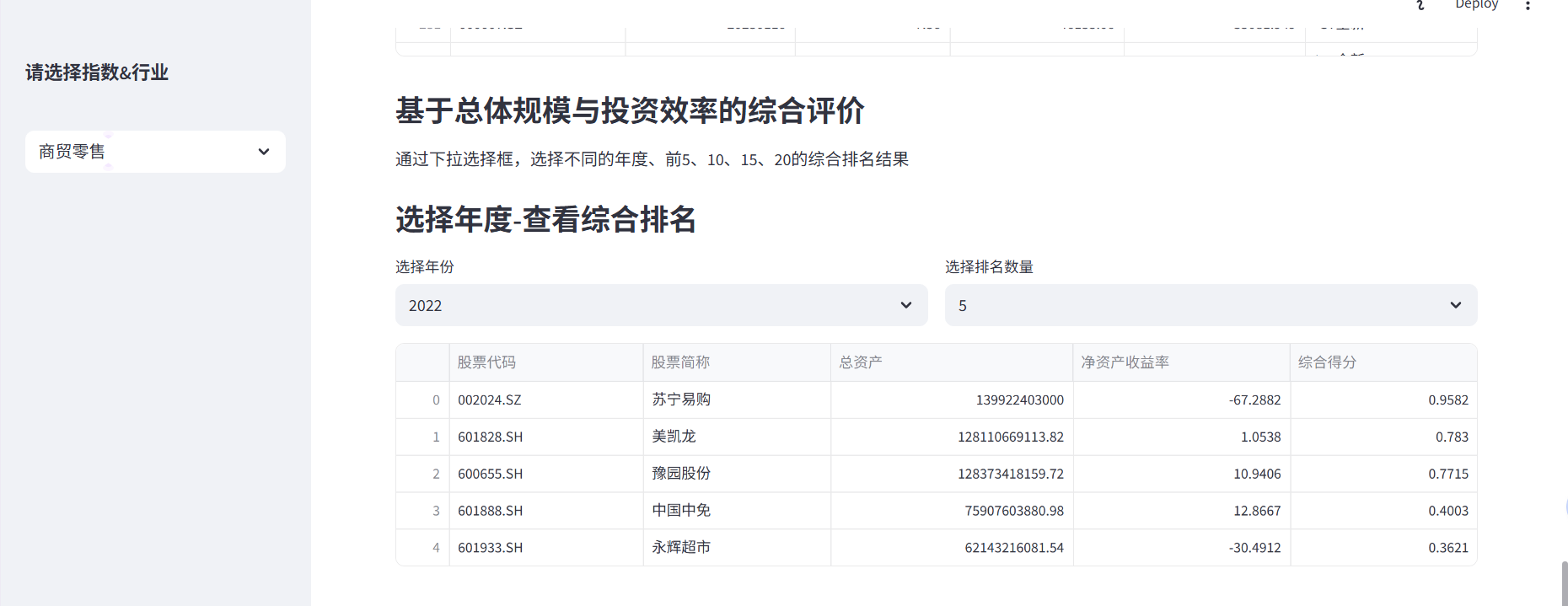
st.subheader('基于总体规模与投资效率的综合评价')
st.markdown('通过下拉选择框,选择不同的年度、前5、10、15、20的综合排名结果')
st.subheader('选择年度-查看综合排名')
select_col1, select_col2 = st.columns(2)
with select_col1:
selected_year = st.selectbox("选择年份", options=[2022, 2023, 2024], index=0)
with select_col2:
top_n = st.selectbox("选择排名数量", options=[5, 10, 15, 20], index=0)
# 7.根据选择的参数计算综合评价结果
eval_result = F_score(r[3], selected_year, top_n)
eval_result = eval_result.reset_index(drop=True) #重置索引——.reset_index(drop=True)
st.dataframe(eval_result,use_container_width=True)四、Streamlit简单页面展示
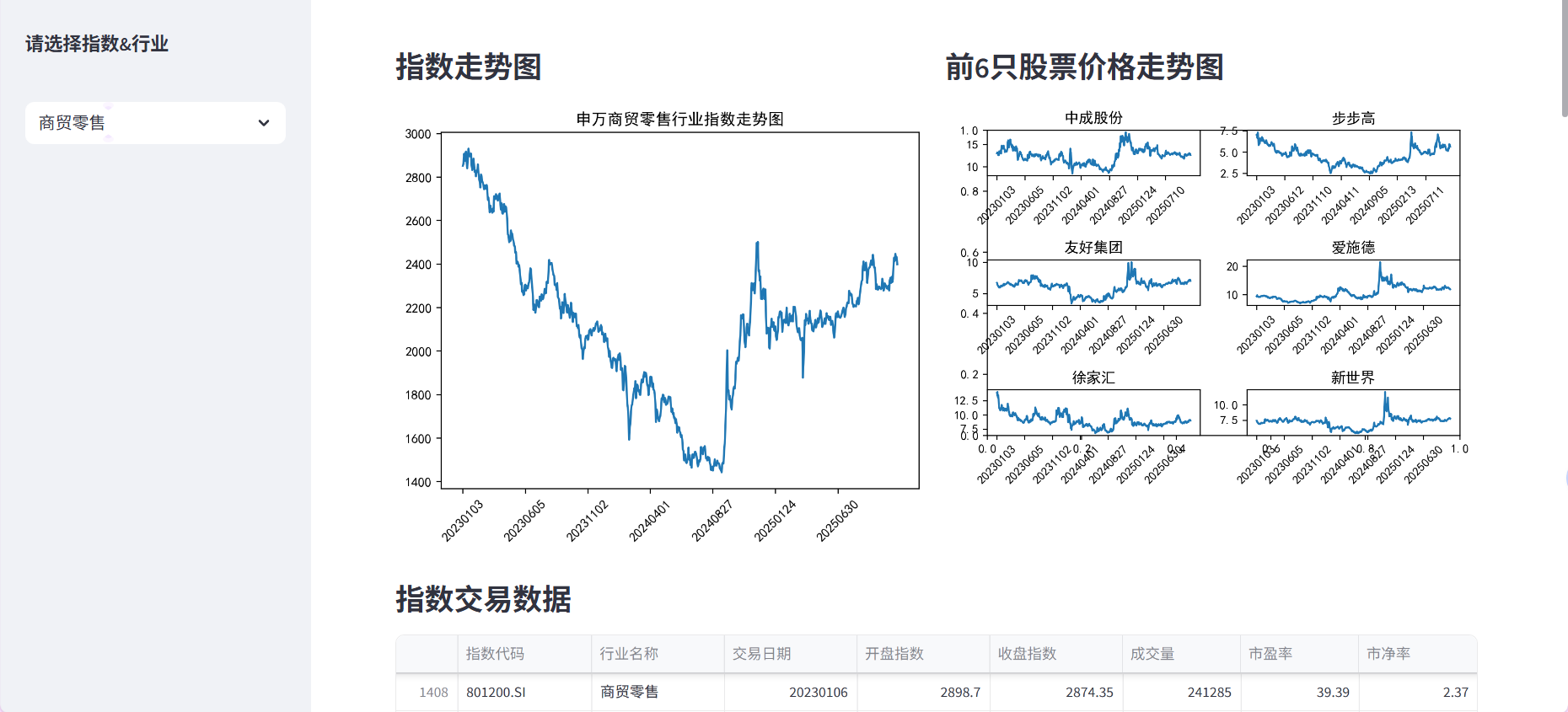
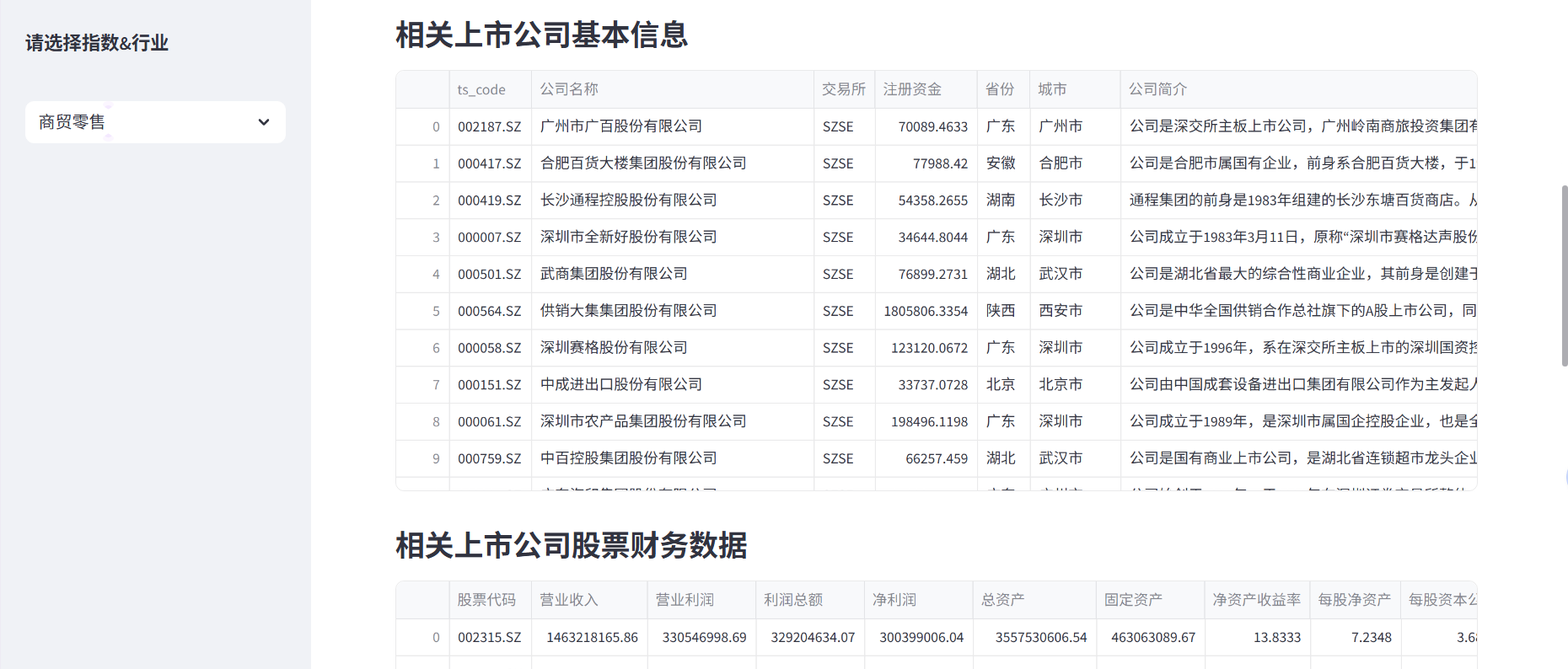
五、总结
本文详细解析的金融数据分析系统展示了如何将复杂金融分析流程转化为直观易用的Web应用,通过本项目,我们可以看到数据科学、金融分析和Web开发的完美结合,为传统金融分析工作提供现代化的解决方案。
项目源码已上传至 GitHub:18June96/financial-evaluation: 基于行业分析的总体规模与投资效率的综合评价

















 5974
5974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









