



一、前言
知乎作为国内领先的知识分享社区,汇聚了数亿用户的高质量内容,涵盖科技、文化、生活、教育等各个领域。这些内容不仅具有很高的实时性和参考价值,也构成了一个巨大的结构化信息宝库。然而,知乎官方并未提供批量内容导出功能,对于需要系统研究、数据分析或内容归档的用户来说,手动整理效率极低。
本次实训项目采用 Python 技术栈开发了一套知乎话题内容智能提取系统。通过该项目,我不仅掌握了爬虫核心技术,还实现了从数据采集、解析到存储、展示的全流程开发,真正体验了一个完整项目的开发过程。
1.1 项目亮点
-
全流程自动化:登录(一次登录后续无需再登录)→搜索话题→提取→存储→展示
-
反爬策略应对:模拟真实用户行为,绕过常见检测
-
结构化存储:Oracle数据库保存,便于后续分析
-
友好界面:GUI操作,无需编程基础即可使用
-
模块化设计:代码清晰,易于维护和扩展
1.2 技术栈
Python、Selenium、XPath(网页内容定位)、Oracle数据库、Tkinter(GUI界面)、多线程技术(提升用户体验)。
二、项目整体架构设计
2.1 系统功能模块
本项目采用模块化设计,将复杂系统分解为三个核心模块。
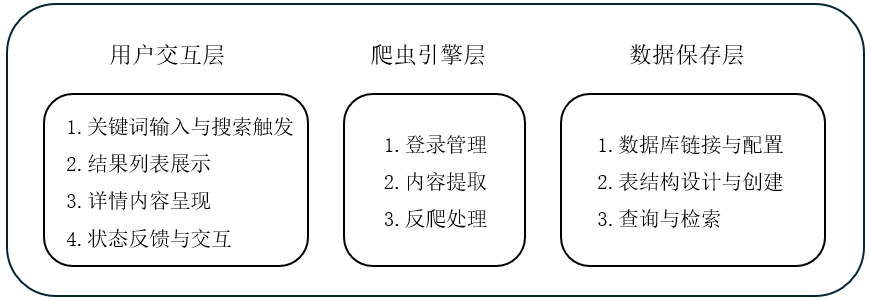
2.2 技术选型
1. Selenium
知乎作为大型平台,采用了多种反爬措施,Selenium 能够模拟真实浏览器的完整行为,包括 JavaScript 执行、Cookie 管理、页面交互等,是应对这类动态网站的利器。
推荐的Selenium教程:小白爬虫——selenium入门超详细教程-优快云博客
2. Oracle 数据库
该数据库具备企业级稳定性,专为处理结构化数据设计,提供完善的事务支持以确保数据一致性。其CLOD类型特性特别适合存储长文本内容,具有显著的学习价值,可帮助掌握企业常用数据库技术。
数据库的连接和建立“问题”和“回答”表:
def setup_database(self): # 连接 Oracle+初始化
database_servers = [
"localhost:1521/ORCL",
]
for ds in database_servers:
try:
self.db_connection = cx_Oracle.connect(
user="你的数据库名称",
password="你的数据库密码",
dsn=ds,
mode=cx_Oracle.SYSDBA
)
print(f"数据库连接成功: {ds}")
self.create_tables()
return
except Exception as e:
print(f"连接失败 {ds}: {e}")
try:
cursor = self.db_connection.cursor()
# 删除已存在的表
tables = ['ZHIHU_ANSWERS', 'ZHIHU_QUESTIONS']
for table in tables:
try:
cursor.execute(f"DROP TABLE {table} CASCADE CONSTRAINTS") # 不用加分号
except:
pass
# 创建序列
try:
cursor.execute("DROP SEQUENCE answer_id_seq") # 不用加分号
except:
pass
cursor.execute("CREATE SEQUENCE answer_id_seq START WITH 1 INCREMENT BY 1") # 不用加分号
# 创建问题表
cursor.execute("""
CREATE TABLE ZHIHU_QUESTIONS (
question_id VARCHAR2(100) PRIMARY KEY,
title VARCHAR2(500),
url VARCHAR2(500),
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""") # 多行字符串不需要分号
# 创建回答表
cursor.execute("""
CREATE TABLE ZHIHU_ANSWERS (
answer_id NUMBER PRIMARY KEY,
question_id VARCHAR2(100),
author VARCHAR2(100),
publish_time VARCHAR2(100),
content CLOB,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (question_id) REFERENCES ZHIHU_QUESTIONS(question_id)
)
""")
self.db_connection.commit()
cursor.close()
print("数据表创建成功")
except Exception as e:
print(f"数据表创建失败: {e}")
import traceback
traceback.print_exc() # 打印错误信息3. Tkinter
利用Tkinter制作GUI界面的好处在于 该内置库无需额外安装,具有出色的跨平台兼容性,特别适合开发中小型桌面应用程序。
三、核心模块实现详解
3.1 登录模块
知乎的登录验证相对严格,直接使用 requests 发送登录请求容易被识别为机器人,我们这里选择的是模拟真实用户的完整登录流程。
1. 模拟人类操作模拟
# 人类随机延迟
def human_like_delay(self, min_time=1, max_time=3):
time.sleep(random.uniform(min_time, max_time))2. 多维度登录状态检测
# 检查登录状态
def check_login_status(self):
try:
self.browser.get('https://www.zhihu.com/')
self.human_like_delay(2, 4)
# 多种方式检查登录状态
selectors = [
'//div[contains(@class, "AppHeader-profile")]',
'//a[contains(@href, "/people/")]',
'//div[contains(text(), "写回答")]',
'//span[contains(text(), "我的")]',
'//button[contains(text(), "提问")]'
]
for selector in selectors:
try:
element = self.browser.find_element(By.XPATH, selector)
print("已登录")
return True
except:
continue
print("未登录")
return False
except Exception as e:
print(f"检查登录状态出错: {e}")
return False3. 用户交互设计
考虑到验证码和动态验证的可能,系统设计了友好的手动登录流程:
-
弹出新浏览器窗口供用户登录
-
登录完成后点击确认按钮
-
自动保存登录状态到配置文件
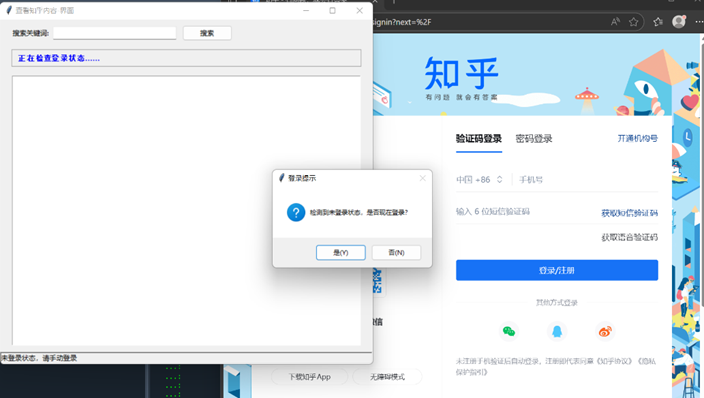
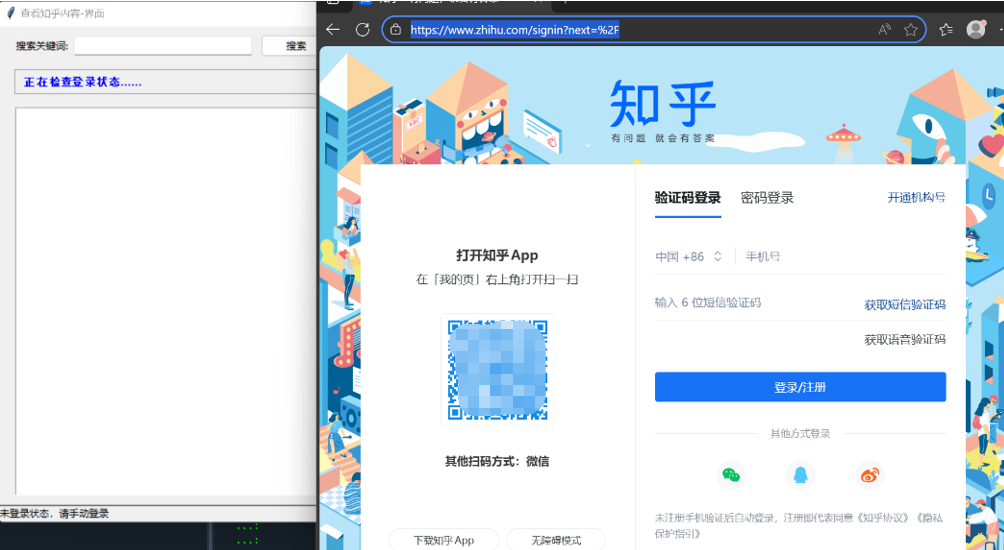
3.2 内容提取模块
1. XPath定位回答内容
XPath 的绝对路径页面结构稍有变动就会失效,本实训采用相对路径的方法,另外采用无限滚动加载,模拟用户滚动行为。
# 获取最新的 10 个回答
def get_answers(self):
answers = []
try:
# 1.尝试点击时间排序
try:
sort_btn = WebDriverWait(self.browser, 3).until(
EC.element_to_be_clickable((By.XPATH, '//button[contains(text(), "时间排序")]'))
)
sort_btn.click()
time.sleep(2)
except:
print("")
# 2.多次滚动触发加载
for _ in range(8):
self.browser.execute_script("window.scrollBy(0, 1000)")
time.sleep(0.8)
# 3. 使用 XPath
answer_cards = self.browser.find_elements(
By.XPATH,
'//div[contains(@class, "AnswerItem")]'
)
print(f"找到 {len(answer_cards)} 个回答")
if not answer_cards:
return []
# 取前5个
answer_cards = answer_cards[:5]
# 4. 处理每个回答
for i, card in enumerate(answer_cards, start=1):
print(f"\n正在处理第 {i} 个回答...")
# 展开阅读全文
try:
expand_btn = card.find_element(By.XPATH, './/button[contains(text(), "展开")]')
self.browser.execute_script("arguments[0].click();", expand_btn)
time.sleep(1)
except:
pass
author_name = self.extract_author(card, i)
publish_time = self.extract_publish_time(card, i)
content = self.extract_content(card, i)
comments = self.get_comments(card)
content = self.extract_content(card, i)
# 如果没有正文,跳过这个卡片(通常是图片卡片、广告、空白卡片)
if not content or len(content.strip()) < 5:
print(f"跳过无内容回答")
continue
answers.append({
"author": author_name,
"publish_time": publish_time,
"content": content,
"comments": comments
})
print(f"第 {i} 个回答处理完成: {author_name}")
except Exception as e:
print("获取回答列表失败:", e)
print(f"总共成功提取 {len(answers)} 个回答")
return answers2. 获取时间
利用XPath获取时间,并且把时间格式标准化(统一为 YYYY-MM-DD):
# 使用 XPath 提取发布时间(只保留年月日)
def extract_publish_time(self, card, index):
publish_time = "未知时间"
try:
xpaths = (
'.//meta[@itemprop="dateCreated"] | '
'.//meta[@itemprop="dateModified"] | '
'.//span[contains(text(), "发布于")] | '
'.//span[contains(text(), "编辑于")] | '
'.//a[contains(@class, "ContentItem-time")]'
)
elems = card.find_elements(By.XPATH, xpaths)
for el in elems:
time_text = (el.get_attribute("content") or el.text or "").strip()
if not time_text:
continue
# 处理 ISO 格式时间
if "T" in time_text and "Z" in time_text:
# 2022-05-26T01:53:59.000Z → 2022-05-26
publish_time = time_text.split("T")[0]
print(f"第{index}个回答时间: {publish_time}")
return publish_time
# 普通文本格式
if "发布于" in time_text or "编辑于" in time_text:
# 发布于 2022-05-26
# 编辑于 2022-05-26
# 只保留后面的 yyyy-mm-dd
for fmt in ["发布于", "编辑于"]:
if fmt in time_text:
publish_time = time_text.replace(fmt, "").strip()
print(f"第{index}个回答时间: {publish_time}")
return publish_time
except Exception as e:
print(f"第{index}个回答提取时间失败: {e}")
return publish_time3. 内容展开逻辑
部分回答有"展开阅读全文"按钮,需要先点击展开:
expand_selectors = [
'.//button[contains(text(), "展开阅读全文")]',
'.//button[contains(text(), "显示全部")]',
'.//button[contains(text(), "展开")]'
]3.3 数据库设计
1. 问题表(ZHIHU_QUESTIONS)
-
question_id: 问题唯一标识(主键)
-
title: 问题标题
-
url: 问题链接
-
crawl_time: 抓取时间
# 创建问题表
cursor.execute("""
CREATE TABLE ZHIHU_QUESTIONS (
question_id VARCHAR2(100) PRIMARY KEY,
title VARCHAR2(500),
url VARCHAR2(500),
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""") 2. 回答表(ZHIHU_ANSWERS)
-
answer_id: 回答ID(序列生成)
-
question_id: 关联问题ID(外键)
-
author: 回答作者
-
publish_time: 发布时间
-
content: 回答内容(CLOB类型)
-
crawl_time: 抓取时间
# 创建回答表
cursor.execute("""
CREATE TABLE ZHIHU_ANSWERS (
answer_id NUMBER PRIMARY KEY,
question_id VARCHAR2(100),
author VARCHAR2(100),
publish_time VARCHAR2(100),
content CLOB,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (question_id) REFERENCES ZHIHU_QUESTIONS(question_id)
)
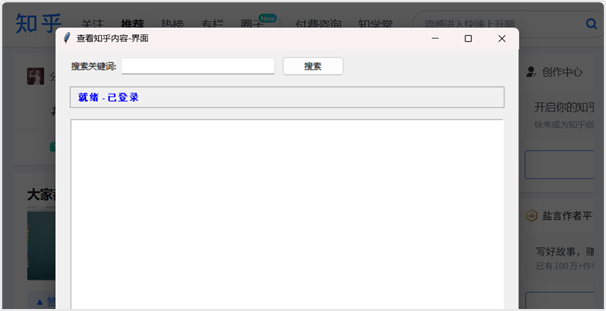
""")3.4 GUI界面
GUI界面布局设计:
四、项目运行效果展示
4.1 主界面与搜索功能
系统启动后,首先检查登录状态。如果未登录,会提示用户进行手动登录。登录成功后,状态栏显示 "就绪 - 已登录"。
在搜索框中输入关键词(如"人工智能"),点击搜索按钮或按回车键,系统开始搜索相关话题,搜索过程中,状态栏实时更新进度。
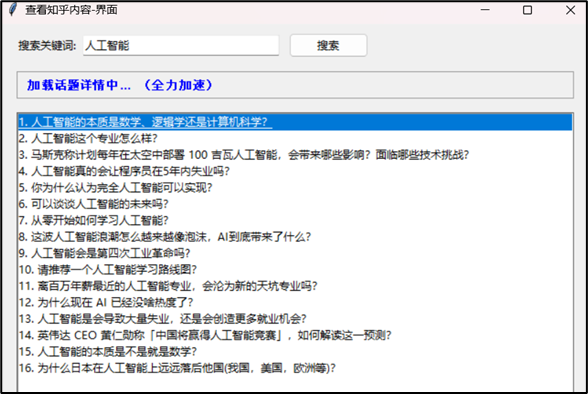
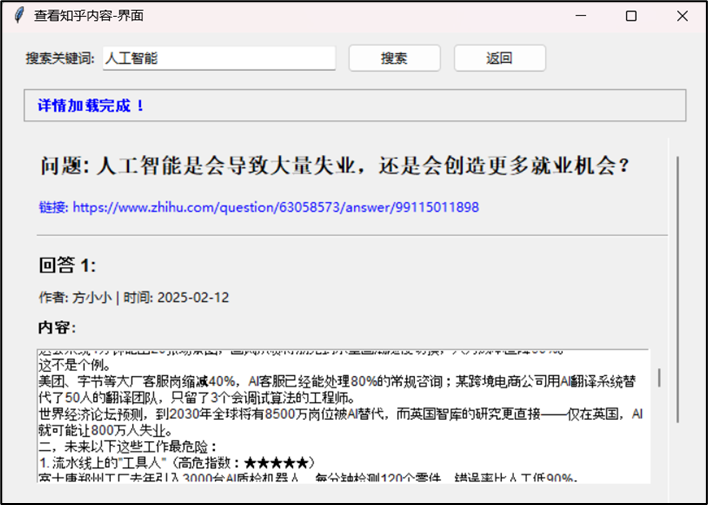
4.2 结果展示与详情查看
搜索结果以列表形式展示,每条结果显示序号和问题标题。点击任意条目,系统加载该话题的详细内容。详情页面分为几个部分:
· 问题标题:醒目显示,可点击跳转到对应的知乎原网页
· 问题链接:蓝色可点击链接
· 回答列表:每个回答包含作者、发布时间、详细内容
4.3 数据存储效果
所有查看过详情的话题内容会自动保存到 Oracle 数据库中,通过数据库客户端可以查看存储的数据:

五、开发中遇到的问题与解决方案
5.1 登录验证问题
解决方案:
-
改为手动登录引导,降低风控触发率;
-
使用已有的用户数据目录(--user-data-dir);
-
添加人性化延迟和随机行为;
-
保存登录状态,避免重复登录。
5.2 页面结构变化
解决方案:
-
使用相对路径和属性contains定位,而非绝对路径;
-
采用多套XPath选择器,逐一尝试;
5.3 动态加载内容
解决方案:
-
模拟用户滚动行为触发加载
-
设置合理的滚动次数和等待时间
-
实施分批次处理,先获取前几个回答
5.4 数据库连接问题
解决方案:
-
编写连接测试和重试机制
-
详细的错误日志记录
-
使用SYSDBA模式连接简化权限问题
六、项目总结与未来展望
6.1 技术收获
通过本次实训,我系统掌握了多项核心技能:在Selenium高级应用中,学会了浏览器伪装、交互模拟与反爬策略;在XPath精确定位方面,掌握了路径定位、动态内容处理与数据清洗;在全栈开发上,实践了爬虫逻辑、GUI界面、数据库操作与多线程编程;并完整经历了项目开发流程,从需求分析到设计实现、测试调试与文档撰写的全过程,全面提升了工程实践能力。
6.2 可优化方向
从技术演进和项目完善的角度来看,本项目仍有多个可优化方向:
1. 性能优化:可引入异步IO以提升并发能力,实现增量爬取避免重复数据,并添加缓存机制以减少网络请求;
2. 功能扩展:能够支持豆瓣、微博等多平台采集,集成词云生成、情感分析等数据分析模块,并实现定时任务与自动化调度;
3. 用户体验:可设计更美观的现代化界面、增加进度条与预估时间显示,并开发数据导出至Excel、PDF等格式的功能。
这个项目既让我掌握了爬虫技术,也培养了解决复杂问题的系统思维,从需求分析到功能实现,从技术选型到问题调试,每一个环节都是宝贵的学习经历。
项目源码已上传至 GitHub:18June96/zhihu-crawler: 知乎内容爬取系统代码

















 1700
1700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









