




AlexNet 是一种开创性的卷积神经网络 (CNN) 架构,显着推动了计算机视觉领域的发展。AlexNet 由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 开发,在 2012 年 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 中取得了突破,以较大的优势超越了传统的计算机视觉方法。这一成功证明了深度学习在图像分类任务中的力量。
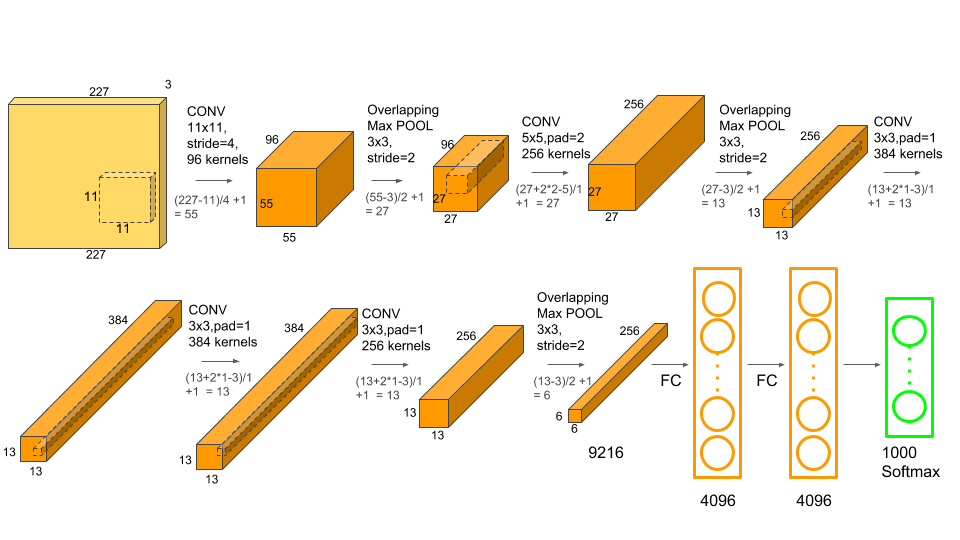 AlexNet网络详解
AlexNet网络详解
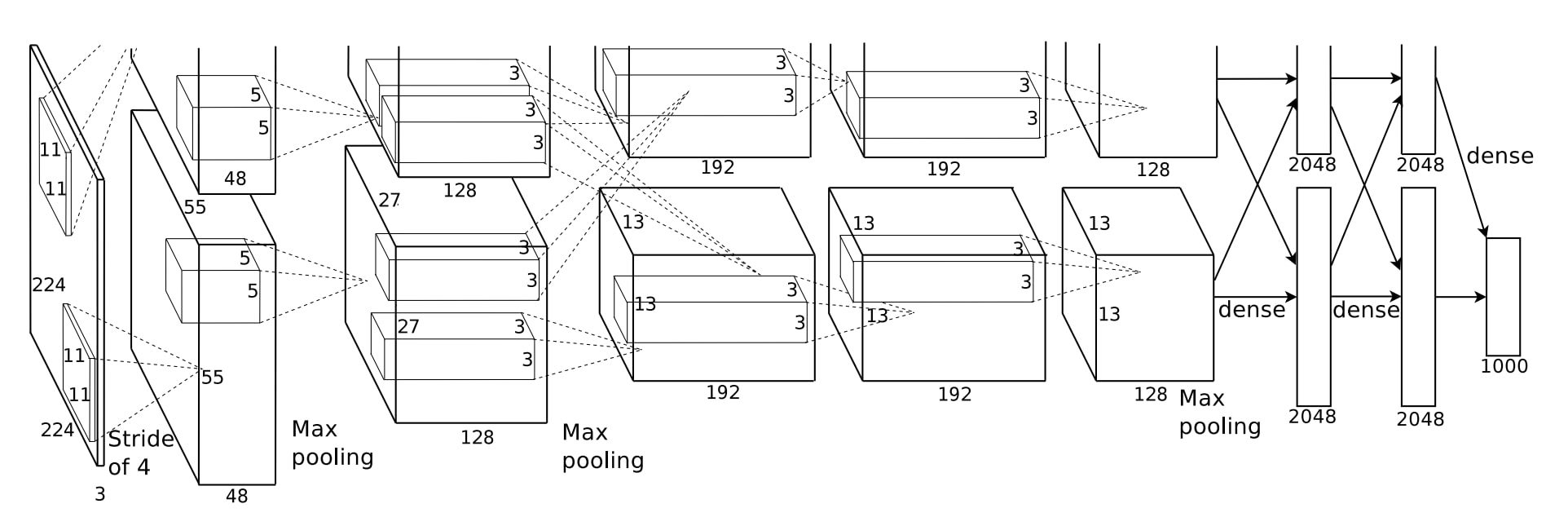

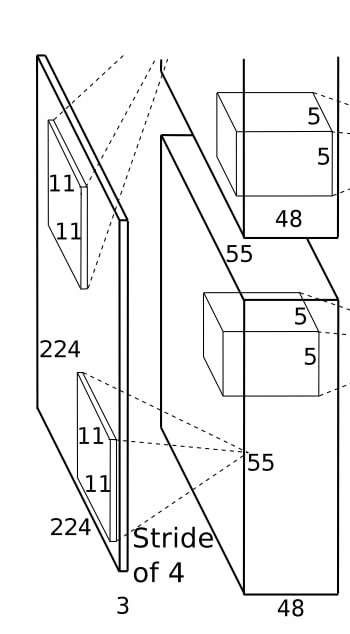
第一个卷积层
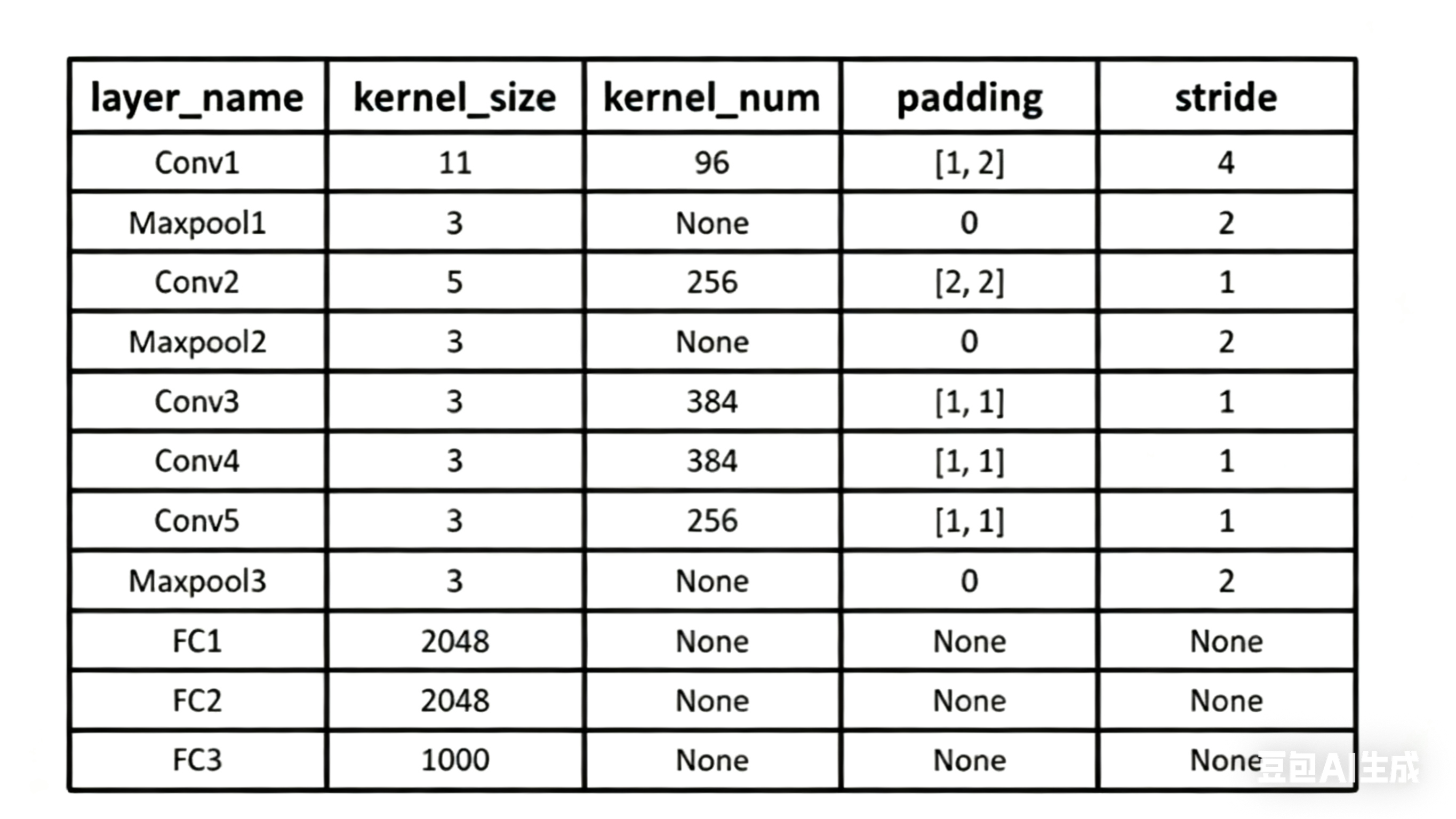
参数如下:
- 输入尺寸:227 × 227 × 3(RGB 三通道图像,227 × 227 是工程实现中匹配输出尺寸的精确值)或者是224 ×224 × 3;(有争议)具体请看这篇文章 从卷积计算机公式看待AlexNet 第一个卷积层的输入图像尺寸的争议
- 卷积核:96个11×11×3的卷积核(96 是输出通道数,11×11 是空间尺寸,3 对应输入通道数);
- 步长(stride):4(卷积核每次滑动 4 个像素);
- 填充(padding):0(无边缘填充);(如果输入尺寸为224 ×224 × 3,则padding=2)
- 输出尺寸:55×55×96(经过卷积后得到的特征图尺寸);
- 激活函数:ReLU(替代传统 Sigmoid,解决梯度消失问题)。
如何理解 96
- 96 个卷积核分别提取不同的低级特征(如不同方向的边缘、不同颜色的色块),最终输出 96 通道的特征图。
- 每个卷积核的参数数量为 11×11×3 = 363(权重)+ 1(偏置)= 364;
- 96 个卷积核的总参数为 96×364 = 34944,是整个网络中参数较少的层(主要参数集中在全连接层)。
如何理解偏置
-
每个卷积核只配 1 个偏置参数,负责 “整体抬高或降低这个卷积核的特征响应值”,避免因输入数据的整体偏移导致特征提取偏差。
-
举个栗子:
- 假设一个卷积核负责 “检测红色边缘”:
- 当输入区域有红色边缘时,加权和会很大(比如 10),加上偏置(比如 1)后,输出值 = 11,特征响应明显;
- 当输入区域没有红色边缘时,加权和可能很小(比如 0.5),加上偏置 1 后,输出值 = 1.5,避免因数值过小被后续激活函数(如 ReLU)“截断”(ReLU 会把负数置 0,偏置能让多数正常响应保持为正)。
-
简单说:偏置的作用是 “给每个卷积核的特征响应‘抬个底’”,让特征提取更灵活,避免受输入数据整体偏移的影响。
96 个卷积核的初始值
在 AlexNet 中,96 个卷积核的初始值是随机设定的,而非人工预设的固定值。这些值会在训练过程中通过反向传播算法不断优化,最终学习到能有效提取图像特征的 “模式”(如边缘、纹理等)。具体过程如下:
1. 初始值:随机初始化
- 训练开始前,96 个卷积核的权重(11×11×3 的数值)和偏置(每个卷积核 1 个)都是通过随机函数生成的,例如:
权重通常从均值为 0、小方差的正态分布(如N(0, 0.01))中随机采样; - 偏置初始值可能设为 0 或很小的随机数。
此时的卷积核是 “无意义” 的随机数值,还不具备特征提取能力。
2. 训练中:通过反向传播优化
训练时,网络会根据损失函数(衡量预测结果与真实标签的差距),通过反向传播调整卷积核的数值:
- 第一步:前向传播
- 输入图像通过 96 个随机卷积核计算,得到 96 个特征图(初始特征是混乱的),最终输出预测结果。
- 第二步:计算损失
- 对比预测结果与真实标签,计算损失值(如分类任务中的交叉熵损失)。
- 第三步:反向传播
- 损失值沿着网络反向传播,计算每个卷积核参数(权重、偏置)对损失的 “贡献”(即梯度)。根据梯度,使用优化器(如 SGD)更新卷积核的值:
新权重=旧权重−学习率×权重梯度
(偏置的更新逻辑相同)
- 损失值沿着网络反向传播,计算每个卷积核参数(权重、偏置)对损失的 “贡献”(即梯度)。根据梯度,使用优化器(如 SGD)更新卷积核的值:
- 迭代优化重复 “前向传播→计算损失→反向传播→更新参数” 的过程(数万至数百万次迭代),卷积核会逐渐 “学习” 到有用的特征模式:
- 比如某些卷积核会对 “水平边缘” 敏感(遇到水平边缘时输出值大);
- 另一些可能对 “红色色块” 或 “纹理斑点” 敏感。
3. 最终值:由数据和任务决定
训练结束后,96 个卷积核的具体数值完全由训练数据和任务目标(如 ImageNet 图像分类)决定:
- 数据中频繁出现的特征(如自然图像中的边缘、颜色过渡)会被卷积核优先学习;
- 任务需要区分的关键特征(如不同类别的图像差异)会被强化。
例如,在 ImageNet 数据集上训练后,AlexNet 第一层的 96 个卷积核会呈现出对 “不同方向边缘、不同颜色块、简单纹理” 的响应模式(可视化结果可直观看到这些特征)。
第一个卷积层后的最大池化层
- 输入特征图:卷积层输
出的55×55×96(96 个通道,每个通道是 55×55 的二维特征图); - 池化窗口大小:3×3(每次对 3×3 的局部区域操作);
- 步长:2(窗口每次滑动 2 个像素,不重叠部分为 2 像素);
- 输出特征图:27×27×96(每个通道的尺寸从 55×55 压缩到 27×27)。
为什么需要最大池化?
1. 压缩特征图,减少计算量
池化窗口3×3+ 步长 2 的组合,让特征图尺寸从 55×55 压缩到 27×27(面积缩小约 4 倍),后续层的计算量随之大幅减少(例如下一层卷积的输入尺寸变小,参数和运算量降低)。这是早期 CNN 提高效率的关键设计。
2. 保留关键特征,过滤冗余信息
最大池化取局部区域的最大值,相当于 “保留该区域最显著的特征响应”,过滤次要信息。
举个栗子:
- 若某 3×3 区域中,中间像素对 “边缘” 的响应最强(值最大),池化后就用这个最大值代表整个区域的 “边缘特征”,忽略周围较弱的响应。
- 这种操作能让特征更 “精炼”,突出关键模式。
3.增强平移不变性
平移不变性指:当输入图像中的特征(如边缘、纹理)轻微平移时,网络仍能识别。
例如,图像中的 “水平边缘” 向左平移 1 个像素,经过最大池化后,3×3 窗口仍能捕捉到这个边缘的最大响应(因为窗口覆盖了平移后的区域),输出特征不会发生显著变化。这让网络对输入的微小扰动更稳健。
4.避免过拟合
池化通过减少特征图的像素数量,降低了网络的 “自由度”(可学习参数间接减少),一定程度上避免模型过度拟合训练数据中的细节噪声。
第二个卷积层
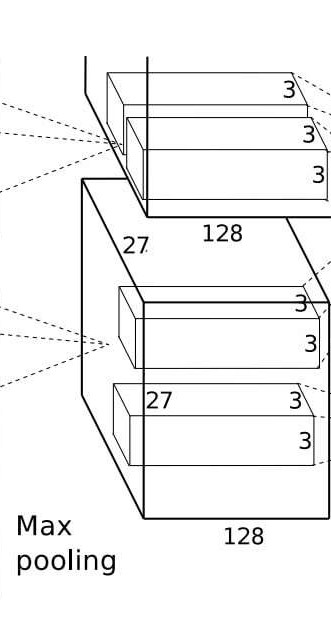
核心参数(原始论文设定)
- 输入尺寸:27×27×96(来自第一层最大池化的输出,96 个通道,每个通道 27×27);
- 卷积核:256个5×5×96的卷积核(256 是输出通道数,5×5 是空间尺寸,96 对应输入通道数);
- 步长(stride):1(卷积核每次滑动 1 个像素,覆盖更密集);
- 填充(padding):2(边缘填充 2 层像素,保持输入输出的空间尺寸一致);
- 输出尺寸:27×27×256(与输入空间尺寸相同,通道数增加到 256);
- 激活函数:ReLU(继续增强非线性特征提取能力)。
第二个卷积层是特征提取的 “升级站”:它以第一层的低级特征为输入,通过小卷积核、密集滑动、保持尺寸和增加通道数的设计,专注于提取 “低级特征的组合模式”,推动特征从 “简单边缘 / 纹理” 向 “局部形状 / 关联结构” 进化。这种逐层抽象的逻辑,正是 CNN 能从图像中自动学习复杂特征的核心原因 —— 每一层都在前一层的基础上 “组装” 更高级的特征,最终实现对图像内容的理解
第二个卷积层的输出是27×27×256的特征图(256 个通道,每个通道是 27×27 的二维矩阵)。每个通道的特征图本质是 “响应强度分布”:值越高的位置,代表该区域与对应卷积核提取的特征模式越匹配。
可视化的核心是:将每个通道的特征图转换为灰度图(或伪彩色图),通过亮度直观展示响应强度。
第二个卷积层的输出特征是**“低级特征的组合编码”**:它们不再是原始图像的直接映射,而是对“边缘、纹理、颜色”等基础元素的空间关联进行抽象。这种抽象是CNN从“感知像素”到“理解结构”的关键一步,也让网络能逐渐捕捉到与图像内容(如物体部件)相关的信息。通过可视化,我们能直观看到这种“逐层升级”的特征提取过程,理解深度学习“自动学习特征”的魔力。
第二个卷积层后的最大池化层
作用是在组合特征(如局部形状、特征关联)的基础上进一步 “精简信息、增强稳健性”,同时为后续更高层次的特征提取铺路。它的设计逻辑与第一层池化相似,但针对第二层的特征特性做了适配,体现了 CNN 中 “卷积提取特征→池化压缩特征” 的循环递进思想。
核心参数
- 池化窗口大小(kernel_size):
3×3
每次对特征图上3×3的局部区域进行操作,取该区域的最大值作为输出。
- 步长(stride):2
窗口在特征图上横向和纵向每次滑动 2 个像素,相邻窗口之间有 1 个像素的重叠(3-2=1)。
- 填充(padding):0(无填充)
不对特征图边缘进行额外填充,直接基于原始特征图进行池化。
- 输入特征图尺寸:27×27×256(来自第二个卷积层的输出,256 个通道,每个通道为 27×27)。
- 输出特征图尺寸:13×13×256(通道数不变,空间尺寸压缩)。
核心作用:针对 “组合特征” 的优化
相比第一个池化层(处理低级特征),第二个池化层的操作对象是更复杂的组合特征(如 “边缘 + 颜色”“局部形状”),因此其作用更偏向 “提炼关键组合模式、增强特征的泛化能力”:
1. 压缩特征图,降低后续计算压力
特征图尺寸从27×27压缩到13×13(面积缩小约 4 倍),256 个通道保持不变。这一压缩大幅减少了下一层(第三个卷积层)的输入数据量,避免计算量随网络深度增长而爆炸。
例如,第三个卷积层的卷积核是3×3×256,若输入仍是27×27,每个卷积核的运算量会是13×13输入的 4 倍以上,池化通过 “精简尺寸” 有效控制了这种增长。
2. 保留 “组合特征” 的核心信息
最大池化取3×3区域的最大值,对于第二层提取的 “组合特征” 而言,这意味着:
- 若某区域存在 “直角” 特征(由水平 + 垂直边缘组合而成),池化会保留该区域中 “直角最显著” 的位置响应,过滤次要的模糊响应;
- 本质是从 “密集的组合特征分布” 中,筛选出 “最关键的特征位置和强度”,让特征更 “聚焦”。
3. 增强对特征平移和变形的稳健性
组合特征(如 “局部曲面”“条纹组合”)在图像中可能因拍摄角度、物体姿态产生轻微平移或变形。池化的3×3窗口能覆盖这些微小变化:
例如,“一组平行线” 轻微偏移 1-2 个像素后,仍会落在3×3窗口内,池化后的最大值能稳定反映 “存在平行线” 这一特征;
这种稳健性让网络在识别时,不会因输入的微小扰动而 “认错” 特征。
4. 为更高层次的特征组合 “去噪”
第二层的特征中可能包含一些冗余或噪声(例如,因图像模糊产生的虚假边缘组合)。池化通过 “取最大值” 的方式,抑制噪声区域的低响应,突出真实特征的高响应,相当于对特征进行 “提纯”,让后续层(如第三、四层卷积)能在更干净的特征基础上提取更复杂的模式(如 “部件组合”)。
第三个卷积层
特征抽象的中间过渡层,它既承接前两层的低级特征和组合特征,又为后续层的高级特征(如物体部件)提取奠定基础。与前两层不同,它不直接连接池化层,而是连续进行卷积操作,体现了 “密集特征提取” 的设计思路。
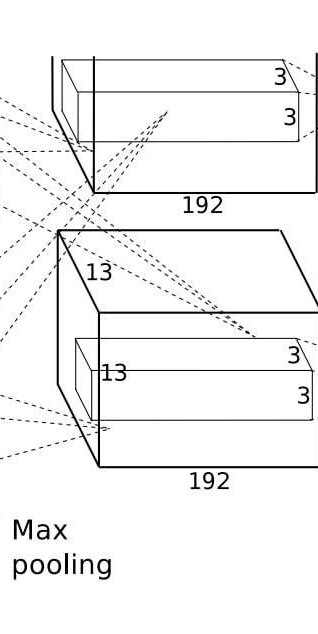 ### 核心参数
### 核心参数
- 输入尺寸:
13×13×256(来自第二个池化层的输出,256 个通道,每个通道 13×13); - 卷积核:
384个3×3×256的卷积核(384 是输出通道数,3×3 是空间尺寸,256 对应输入通道数); - 步长(stride):1(卷积核密集滑动,覆盖每一个像素位置);
- 填充(padding):1(边缘填充 1 层像素,保持输入输出的空间尺寸一致);
- 输出尺寸:
13×13×384
(与输入空间尺寸相同,通道数增加到 384);
激活函数:ReLU。
设计意义:承上启下的关键作用
1、更小的卷积核(3×3):聚焦精细特征关联
相比前两层的 11×11、5×5 卷积核,第三层用 3×3 小核,说明特征提取从 “局部组合” 转向 “更精细的空间关联”:
- 例如,将第二层提取的 “直角”“弧形” 等组合特征,进一步关联为 “拐角 + 曲面” 的更复杂模式;
3×3的窗口尺寸刚好能捕捉相邻组合特征的空间关系(如距离、方向),适合更细致的特征组装。
2、无池化层衔接:保持特征连续性
前两层卷积后都紧跟池化层,而第三层卷积后直接连接第四层卷积(无池化),目的是:
- 避免连续压缩导致的空间信息丢失(13×13 的尺寸已较小,继续压缩可能破坏特征间的精细关联);
- 通过连续卷积操作,让特征在同一空间尺度下进行更深层次的组合(类似 “在同一分辨率下反复提炼”)。
3、通道数增加(256→384):扩展特征表达维度
通道数进一步增加,意味着特征的 “语义复杂度” 提升:
- 256 个通道是 “低级特征的组合”(如局部形状),384 个通道则是这些组合特征的 “关联模式”(如 “形状 A 在形状 B 的上方”“多个相似形状的排列”);
- 更多通道能覆盖更丰富的中层特征,为后续层提取 “物体部件”(如车轮、车窗)提供基础。
4、padding=1 + 步长 = 1:保持尺寸,精细提取
与第二层类似,第三层通过 padding=1 和步长 = 1 保持空间尺寸不变,确保:
- 特征的空间位置信息不丢失(例如,“特征 A 在左、特征 B 在右” 的关系能被准确保留);
- 卷积核可以密集覆盖每个像素,不遗漏任何细微的特征关联。
第四个卷积层
四个卷积层是第三层卷积的 “延续与深化”,它与第三层共享相同的输入尺寸、卷积核大小和步长,核心作用是在第三层提取的 “组合特征关联” 基础上,进一步挖掘更精细的特征模式,同时通过增加通道多样性提升特征表达能力。它是网络深层特征提取的重要环节,为最终的高级语义特征(如物体整体结构)提供更丰富的中间表示。
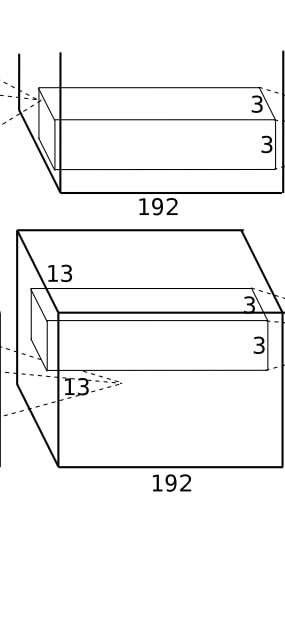
核心参数(原始论文设定)
- 输入尺寸:13×13×384(来自第三个卷积层的输出,384 个通道,每个通道 13×13);
- 卷积核:384个3×3×384的卷积核(输出通道数仍为 384,3×3 是空间尺寸,384 对应输入通道数);
- 步长(stride):1(密集滑动,覆盖每个像素位置);
- 填充(padding):1(边缘填充 1 层像素,保持输入输出空间尺寸一致);
- 输出尺寸:13×13×384(空间尺寸和通道数均与输入相同);
- 激活函数:ReLU。
设计意义:深化特征,增加多样性
1、与第三层卷积 “连续作战”:特征细化与互补
第四层与第三层连续连接(均无池化层),且参数高度相似(3×3 核、步长 1、padding=1),形成 “连续卷积对”:
- 第三层负责 “将组合特征关联起来”(如 “形状 A 与形状 B 相邻”);
- 第四层则在此基础上 “细化关联模式”(如 “形状 A 与形状 B 的相对角度”“关联区域的纹理差异”);二者配合让中高级特征的表达更精准、更细致。
2、通道数不变(384):专注模式差异而非维度扩张
与前两层 “通道数递增”(96→256→384)不同,第四层通道数保持 384,说明设计重心从 “扩展特征维度” 转向 “在同一维度内增加模式多样性”:
- 384 个通道不再是简单的 “更多特征”,而是对同一类关联模式的 “不同角度描述”(例如,对 “两个形状的连接”,有的通道关注连接的平滑度,有的关注连接区域的颜色过渡);
- 这种多样性让特征对复杂场景的适应性更强(如光照变化、视角差异下的特征稳定性)。
3、小核密集提取:捕捉细微特征差异
3×3 小核 + 步长 1 的设计,让第四层能捕捉第三层特征中更细微的空间变化:
- 例如,第三层可能提取 “两个局部形状的重叠区域”,第四层则进一步区分 “重叠区域的边缘是否清晰”“重叠比例多大” 等细节;
这种细微差异的捕捉,对后续识别物体的具体类别(如区分 “猫” 和 “狗” 的头部细节)至关重要。
第五个卷积层
第五个卷积层是网络中最后一个卷积层,也是特征提取的 “收官层”。它承接前四层的特征,专注于提取接近物体整体结构或关键部件的高级特征(如 “车轮 + 车身”“鸟喙 + 翅膀” 等),为后续全连接层的分类决策提供直接依据。其设计既延续了前两层的精细提取逻辑,又通过池化层完成特征的最终压缩,是 “卷积特征提取” 到 “全连接分类” 的过渡枢纽。
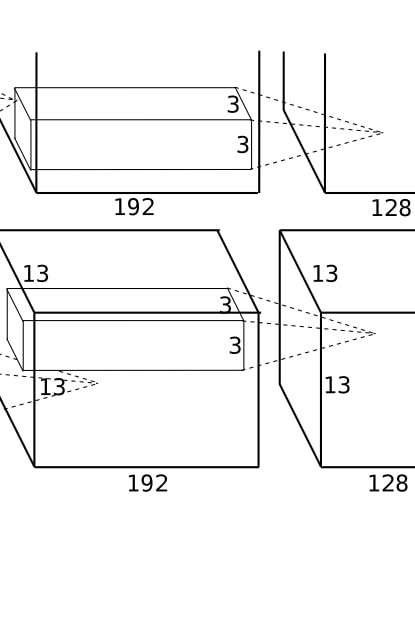
核心参数(原始论文设定)
- 输入尺寸:
13×13×384(来自第四个卷积层的输出,384 个通道,每个通道 13×13);
卷积核:256个3×3×384的卷积核(输出通道数降至 256,3×3 是空间尺寸,384 对应输入通道数);
步长(stride):1(密集滑动,覆盖每个像素位置);
填充(padding):1(边缘填充 1 层像素,保持输入输出空间尺寸一致);
输出尺寸:13×13×256(空间尺寸不变,通道数从 384 减至 256);
激活函数:ReLU;
后续操作:紧跟一个最大池化层(与前两个池化层参数相同)。
设计意义:聚焦判别性特征,衔接全连接层
1、通道数减少(384→256):特征精选与降维
前四层通道数逐步增加(96→256→384→384),而第五层降至 256,目的是:
- 对前四层的中高级特征进行 “筛选”,保留与分类任务最相关的高级特征(如区分 “汽车” 和 “自行车” 的关键部件差异),过滤冗余信息;
- 降低后续全连接层的输入维度(6×6×256=9216),避免参数过多导致过拟合。
2、最后一次卷积:提炼物体级关键特征
第五层作为最后一个卷积层,提取的特征最接近 “语义概念”:
- 例如,在 ImageNet 分类任务中,某些通道可能对 “动物的头部”“车辆的轮子” 等关键部件敏感;
- 这些特征直接反映了图像中 “有什么物体部件”,是全连接层进行最终分类的核心依据。
3、池化后固定尺寸:适配全连接层
池化后6×6×256的固定尺寸,经过 “扁平化” 处理(展平为6×6×256=9216维向量),能直接输入全连接层。这种固定维度设计让网络的 “特征提取” 与 “分类决策” 无缝衔接。
第五个卷积层后的最大池化层
整个卷积特征提取阶段的最后一次压缩操作,它将第五层卷积输出的高级特征进一步精简,形成固定尺寸的特征向量,为后续全连接层的分类决策提供 “浓缩版” 输入。其参数设计与前两个池化层一致,但因处理的是网络最深层的高级特征(如物体部件、整体结构),作用更偏向 “提炼最终判别性信息、标准化特征维度”。
核心参数
- 输入特征图尺寸:
13×13×256(来自第五层卷积的输出,256 个通道,每个通道 13×13); - 池化窗口大小(kernel_size):
3×3; - 步长(stride):2;
- 填充(padding):0(无边缘填充);
- 输出特征图尺寸:
6×6×256(通道数不变,空间尺寸从 13×13 压缩至 6×6)。
核心作用:为全连接层 “准备输入”
作为卷积部分的最后一步操作,该池化层的作用与前两个池化层有本质差异 —— 它不仅是特征压缩,更是卷积特征到全连接特征的 “转换枢纽”:
1、最终压缩特征,固定输出维度
从13×13压缩到6×6,特征图面积缩小至约 1/4,最终形成6×6×256 = 9216的固定维度(展平后)。这个固定维度是为后续全连接层设计的:
- 第一个全连接层的输入神经元数量正是 9216,池化后的尺寸确保卷积特征能 “无缝对接” 全连接层,避免维度不匹配;
- 固定维度也让网络的输入输出关系更稳定,便于训练和部署。
2、提炼高级特征的核心响应
第五层卷积输出的是 “物体部件级” 高级特征(如 “车轮”“鸟喙”),池化层通过3×3窗口取最大值,保留这些高级特征的 “最显著位置响应”:
- 例如,若某区域的 “车轮特征” 响应最强(值最大),池化后会用这个值代表该区域的 “车轮存在性”,过滤次要的模糊响应;
- 这种提炼让全连接层只需关注 “关键部件是否存在、强度如何”,减少无关信息干扰。
3、增强特征的平移不变性与泛化能力
高级特征(如物体部件)在图像中的位置可能因拍摄角度、物体姿态而变化(例如,车轮可能偏左或偏右)。3×3窗口 + 步长 2 的池化能覆盖这些微小平移:
- 无论部件在3×3窗口内的哪个位置,池化后的最大值都能稳定反映 “该部件存在”,让网络对位置变化更稳健;
- 这种泛化能力对分类任务至关重要(例如,无论猫的头部在图像左或右,都能被正确识别)。
4、减少全连接层的参数与计算量
若不经池化,第五层卷积输出的13×13×256展平后是13×13×256=43264维,直接输入全连接层会导致参数爆炸(如第一个全连接层需43264×4096≈1.77亿参数)。池化后维度降至 9216,全连接层参数减少为9216×4096≈3760万,大幅降低了过拟合风险和计算压力。
与前两个池化层的对比:定位不同,目标一致
三个池化层参数完全相同(3×3窗口 + 步长 2),但因所处位置不同,作用定位有明确分工:
| 池化层位置 | 处理的特征类型 | 核心作用 | 最终目标 |
|---|---|---|---|
| 第一层卷积后 | 低级特征(边缘、纹理) | 快速筛选显著低级特征,压缩原始图像尺寸 | 为特征组合提供精简输入 |
| 第二层卷积后 | 组合特征(局部形状) | 提炼关键组合模式,增强特征稳健性 | 为更复杂关联特征铺路 |
| 第五层卷积后 | 高级特征(物体部件) | 固定特征维度,提炼判别性信息,衔接全连接层 | 为分类决策提供浓缩特征 |
第一个全连接层
第五个卷积层后的最大池化层输出的6×6×256特征图,会先经过扁平化(Flatten) 处理(转换为1×9216的一维向量),然后输入到三个全连接层(FC 层)。其中,第一个全连接层是卷积特征与分类决策之间的 “桥梁”,负责将浓缩的高级特征(物体部件、结构)映射为更抽象的 “分类特征向量”,为最终的类别预测做准备。
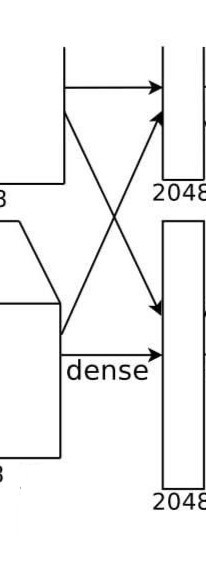
第一个全连接层的核心参数
- 输入维度:
9216(来自6×6×256的扁平化结果); - 输出维度:
4096(输出一个 4096 维的特征向量); - 激活函数:ReLU;
- 正则化:Dropout( dropout rate=0.5,随机丢弃 50% 的神经元,防止过拟合);
- 参数数量:
9216×4096 + 4096 = 37,748, 864(权重 + 偏置,每个输出神经元对应 9216 个权重和 1 个偏置)。
操作逻辑:从 “空间特征” 到 “分类特征”
1、扁平化输入
池化后的6×6×256特征图是 “空间结构化” 的(每个通道的6×6像素代表某高级特征在图像不同位置的响应),而全连接层需要 “无结构” 的一维向量,因此先通过 Flatten 操作转换为9216维向量(6×6×256 = 9216)。
例如:6×6×256中的每个元素(如通道 0 的 (0,0) 位置、通道 1 的 (2,3) 位置等),会按顺序排列成一维数组的第 1、第 2、……、第 9216 个元素。
2、全连接运算
每个输出神经元(共 4096 个)与输入的 9216 个元素进行加权求和,并加上偏置,再通过 ReLU 激活:
输出
i
=
R
e
L
U
(
∑
j
=
1
9216
w
i
,
j
×
输入
j
+
b
i
)
{输出}_i = {ReLU}( \sum\limits_{j=1}^{9216} w_{i,j} \times {输入}_j + b_i )
输出i=ReLU(j=1∑9216wi,j×输入j+bi)
其中,w_{i,j}是第i个输出神经元与第j个输入元素的连接权重,b_i是偏置。这一过程本质是将空间特征 “解耦” 并重组为分类相关的抽象特征—— 例如,将 “车轮”“车身”“车窗” 等部件特征组合为 “汽车” 类别的抽象表示。#### 3、Dropout 正则化
训练时,随机让 50% 的输出神经元失效(输出置 0),迫使网络不依赖特定神经元,增强特征的泛化能力(避免过度拟合训练数据中的噪声)。测试时不使用 Dropout,所有神经元正常工作。
第二个全连接层
第二个全连接层是第一个全连接层特征的 “深化与再抽象”,它与第一个全连接层参数完全一致,核心作用是在前者输出的 4096 维分类特征基础上,进一步学习更复杂的特征组合模式,增强网络对不同类别物体的判别能力,为最终的类别预测提供更精准的抽象特征支持。
核心参数
- 输入维度:4096(来自第一个全连接层的输出,4096 维特征向量);
- 输出维度:4096(与输入维度相同,输出仍为 4096 维特征向量);
- 激活函数:ReLU;
- 正则化:Dropout( dropout rate=0.5,与第一个全连接层一致);
- 参数数量:4096×4096 + 4096 = 16,777, 216(权重 + 偏置,每个输出神经元对应 4096 个权重和 1 个偏置)。
第三个全连接层
三个全连接层是网络的最终输出层,负责将前两层全连接层抽象出的高级分类特征直接映射为 “类别概率分布”,是整个分类决策的 “终点站”。它的设计简洁但关键,直接决定了网络对输入图像的类别预测结果。
核心参数
- 输入维度:4096(来自第二个全连接层的输出,4096 维高级分类特征);
- 输出维度:1000(对应 ImageNet 数据集的 1000 个类别,每个维度代表一个类别的 “未归一化分数”);
- 激活函数:无(输出为 “logits”,即未经过 softmax 的原始分数);
- 正则化:无 Dropout(需保留所有特征用于最终决策);
- 参数数量:4096×1000 + 1000 = 4,097,000(权重 + 偏置,每个类别对应 4096 个权重和 1 个偏置)。
操作逻辑:从 “特征向量” 到 “类别分数”
1、输入与运算过程
第二个全连接层输出的 4096 维特征向量输入第三层,每个输出神经元(共 1000 个,对应 1000 个类别)与输入的 4096 个元素进行全连接加权求和,并加上偏置,直接输出原始分数(logits):
输出
k
=
∑
j
=
1
4096
w
k
,
j
×
输入
j
+
b
k
{输出}_k = \sum\limits_{j=1}^{4096} w_{k,j} \times \text{输入}_j + b_k
输出k=j=1∑4096wk,j×输入j+bk
其中,w_{k,j}是第k个类别神经元与输入特征的连接权重,b_k是偏置。例如,“输出_3” 对应 ImageNet 中的第 3 个类别(如 “金毛寻回犬”),其值越高,代表网络认为输入图像属于该类别的可能性越大。
2、后续处理:softmax 归一化
虽然第三层本身不使用激活函数,但输出的 logits 会经过softmax 函数处理,转换为归一化的类别概率(总和为 1):
P
(
k
)
=
e
输出
k
∑
i
=
1
1000
e
输出
i
P(k) = \frac{e^{\text{输出}_k}}{\sum_{i=1}^{1000} e^{\text{输出}_i}}
P(k)=∑i=11000e输出ie输出k
最终取概率最大的类别作为预测结果(如P(k)=0.9的类别被判定为图像所属类别)。
P
(
k
)
=
P(k) =
P(k)=
与前两个全连接层的对比:从 “特征加工” 到 “决策输出”
| 第一个全连接层 | 第二个全连接层 | 第三个全连接层 | |
|---|---|---|---|
| 核心作用 | 空间特征→分类特征(首次转换) | 分类特征→高级分类特征(二次深化) | 高级分类特征→类别分数(最终决策) |
| 输出性质 | 4096 维中间特征(含冗余) | 4096 维精炼特征(接近类别语义) | 1000 维类别分数(直接用于预测) |
| 正则化 | Dropout(防止过拟合) | Dropout(防止过拟合) | 无(保留完整决策信息) |
| 激活函数 | ReLU(增强非线性) | ReLU(增强非线性) | 无(输出 logits) |
这一层的设计简洁却承载了整个网络的核心目标 —— 将从原始图像中逐层提取的特征,转化为可解释的类别判断。从卷积层的特征提取到全连接层的分类映射,AlexNet 通过这种 “逐层抽象、最终聚焦” 的结构,实现了对复杂图像的高效分类,奠定了现代深度学习在计算机视觉领域的基础。

















 2920
2920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









