




最近,我们团队的一位工程师在研究类 ColPali 模型时,受到启发,用新近发布的 jina-clip-v2 模型做了个颇具洞察力的可视化实验。
实验的核心思路是,对给定的图像-文本对,计算文本里每个词的向量(token embeddings)和图像里每个图像块的向量(patch embeddings),计算它们之间的相似度。然后,把这些相似度数值映射为热力图,叠加在图像之上,就能直观地看到文本 token 和图像 patch 之间的关联模式。

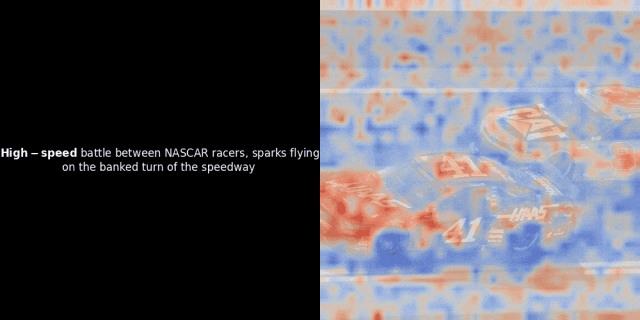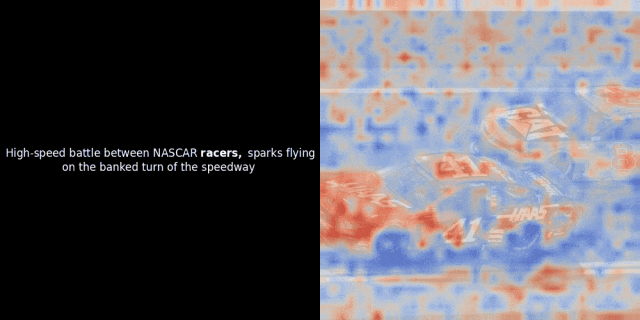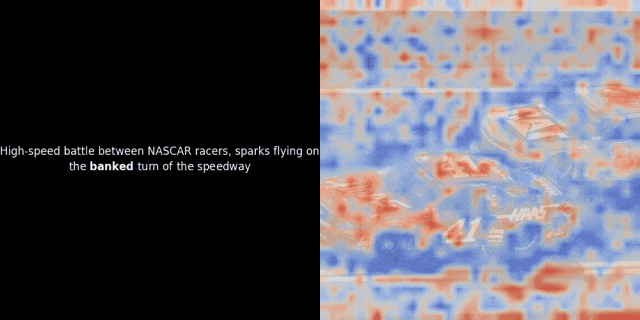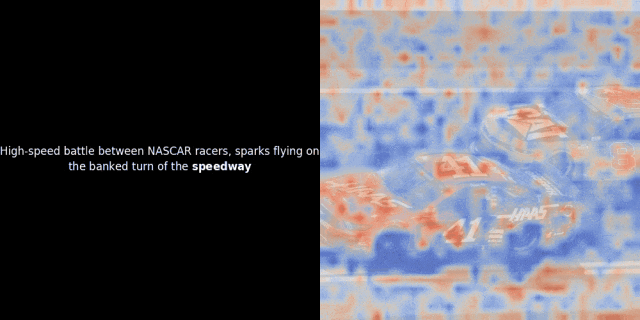
注意:这种可视化方法只是我们一种启发式的尝试,并非模型内部的固有机制。像 CLIP 这样的模型,用全局对比方法来训练,确实有可能(而且经常)在图像块和文本词元之间产生一些局部的对应关系,但你要知道,这只是全局对比训练过程中的一个“副产品”,不是它直接想要达到的目标。
接下来,我将详细解释其中的缘由。
代码解析
我们已经看到了直观的对比可视化效果,但 jina-clip-v2 模型本身并不直接提供文本 Token 或图像 Patch 级别的向量表示。那么,为了实现这种效果,背后的代码是如何运作的呢?
接下来,我们将深入代码,从宏观层面了解其功能。
Google Colab: https://colab.research.google.com/drive/1SwfjZncXfcHphtFj_lF75rVZc_g9-GFD
计算词级别向量表示
通过设置 model.text_model.output_tokens = True,调用 text_model(x=...,)[1] 将会返回一个形状为 (batch_size, seq_len, embed_d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









