



背景
进行网络通信时,或者希望本地存储文件加密时,可以用二进制序列化。序列化时要把类的基本类型字段一个个序列化,遇到成员类要把成员类的基本类型成员也序列化。这样每个类都要有一个专门的序列化程序,这是令人难以接受的。需要封装一些代码,有不同的封装方案。
- 把各种基本数据类型的序列化封装成函数,把一个类序列化时按字段的顺序和类型手动调用这些函数。不过除了字符串麻烦点,其他类型序列化都只要一行;
- 写一个接收object的函数,使用GetFields()(反射)得到每个字段的类型,按类型序列化;
反射方案
还面临的问题是:
- 结果字节数组的长度是由所有字段的个数和类型决定的。需要对每个字段判断类型、对字符串确定长度后才能知道结果字节数组的长度。不可能预先知道结果字节数组的长度。
- 对于成员类,成员类还有成员类,成员类可能是列表或字典,列表或字典的元素还可能是类。而最终需要把所有结构分解为基本数据类型,这意味着需要递归调用;
- 要递归调用,就必须把一个字段的序列化写成函数FieldToBytes(),而不能直接写在ToBytes()的循环里。遇到成员类时,对成员类调用ToBytes();
- 对于类的列表,每个元素的字节数可能不同,把每个元素解析过之前无法知道它的字节数,也无法知道整个列表的字节数;
- 反序列化时是输入一个类的模板、一个字节数组,返回一个填入值的对象。类的信息可以通过1.泛型T,2.Type,3.object传入。返回类型T好像不行,没法把int、string转换成T,应该返回object。ToObject()里把类通过GetFields()得到字段们的fieldInfo,此时无法得到泛型参数T。所以反序列化不管是对类的解析还是对字段的反序列化,我们可能完全无法用泛型,因为无法从type获取T。
想到列表可以改变长度,可以先声明一个byte列表,把字段序列化后加到列表后面,全部加完后变成数组。
总之,
- 这里3个要素:A数据类,B数据类型,C字节数组,序列化是由A、B=>C,反序列化是B、C=>A。序列化时由一个数据类对象就知道AB了,不用专门提供B。
- 序列化和反序列化各需要2个函数,一个ToBytes()负责把object解析出字段,然后用循环处理,一个FieldToBytes()把单个字段根据type处理,遇到类则再调用ToObject()拆解,形成递归调用。
- 对列表字典的元素,调用FieldToObject(),而非ToBytes()。
反射容易混乱的2个概念
- Type;
- 类型名,也是泛型参数T;
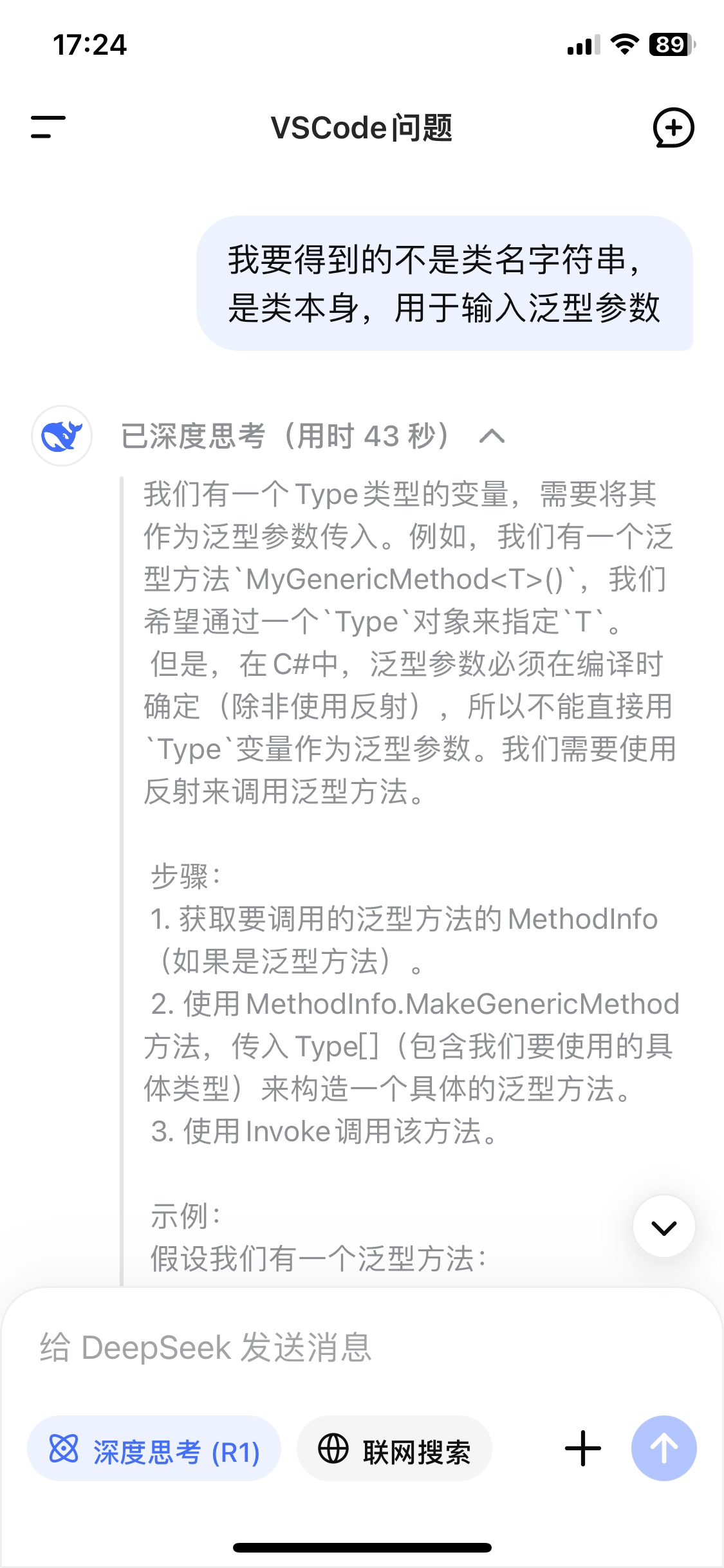
typeof(T)可以得到type,它的逆运算是什么?deepseek回答,大意是无法由type得到相应的T输入给泛型方法,只能把这个方法改成输入type。



注意
- 非public的字段不会被序列化;
- 对null的处理:不要在字节数组直接跳过!反序列化时不会知道这个字段类是null,会解码错误,应该写入一个默认的,能代表无效的类对象。然而如果真的输入一个null给序列化程序,它自己也不可能通过类型实例化一个对象,GetType()会报错。那么不如序列化时发现字段位空就直接报错;

检查二进制数据正确性
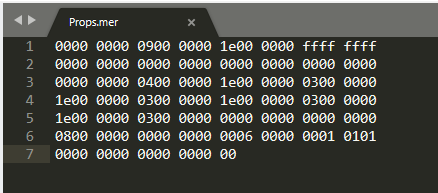
二进制文件难读,但不是不能读。用Sublime Text打开,数据以16进制表示,也就是每2个数字是1个字节,这里每2个字节有一个空格,这里把空格隔开的数据叫一坨。一个int32是4个字节,就是这里的2坨。C#是数据内左边低位字节,也就是0900 0000的09是最低字节,这个数字是9。bool是1个字节,类里有bool会导致出现一个数据不是从空格开始的情况。
代码
支持列表、字典、嵌套类、类的列表字典、枚举。枚举反序列化时直接读取成int32输出。
using System.Reflection;
using System.Collections.Generic;
using System.Collections;
using System.IO;
using System;
using System.Text;
using UnityEngine;
public class MyBinManager
{
static MyBinManager instance = new MyBinManager();
public static MyBinManager Instance => instance;
string path
{
get { return $"{Application.persistentDataPath}/"; }
}
public byte[] ToBytes(object data)
{
List<byte> byteList = new List<byte>();
Type dataType = data.GetType();
FieldInfo[] fieldInfos = dataType.GetFields();
for (int i = 0; i < fieldInfos.Length; i++)
{
byte[] bytes = FieldToBytes(fieldInfos[i].GetValue(data));
byteList.AddRange(bytes);
}
return byteList.ToArray();
}
public byte[] FieldToBytes(object field)
{
byte[] bytes = null;
if (field.GetType() == typeof(string))
{
string str = field as string;
bytes = EncodeStr(str);
}
else if (field.GetType() == typeof(int))
{
bytes = BitConverter.GetBytes((int)field);
}
else if (field.GetType() == typeof(float))
{
bytes = BitConverter.GetBytes((float)field);
}
else if (field.GetType() == typeof(bool))
{
bytes = BitConverter.GetBytes((bool)field);
}
else if (field.GetType().IsEnum)
{
bytes = BitConverter.GetBytes((int)field);
}
else if (typeof(IList).IsAssignableFrom(field.GetType()))
{
IList iList = field as IList;
// Type type = iList.GetType().GetGenericArguments()[0];
bytes = ListToBytes(iList);
}
else if (typeof(IDictionary).IsAssignableFrom(field.GetType()))
{
IDictionary dictionary = field as IDictionary;
bytes = DicToBytes(dictionary);
}
else
{
#if UNITY_EDITOR
Debug.Log(string.Concat("序列化成员类:", field.GetType()));
#endif
bytes = ToBytes(field);
}
return bytes;
}
byte[] EncodeStr(string str)
{
byte[] strBytes = Encoding.UTF8.GetBytes(str);
byte[] bytes = new byte[sizeof(int) + strBytes.Length];
BitConverter.GetBytes(strBytes.Length).CopyTo(bytes, 0);
strBytes.CopyTo(bytes, sizeof(int));
return bytes;
}
byte[] ListToBytes(IList list)
{
List<byte> bytes = new List<byte>();
bytes.AddRange(BitConverter.GetBytes(list.Count));
for (int i = 0; i < list.Count; i++)
{
bytes.AddRange(FieldToBytes(list[i]));
}
return bytes.ToArray();
}
byte[] DicToBytes(IDictionary dic)
{
List<byte> bytes = new List<byte>();
bytes.AddRange(BitConverter.GetBytes(dic.Count));
foreach (object key in dic.Keys)
{
bytes.AddRange(FieldToBytes(key));
bytes.AddRange(FieldToBytes(dic[key]));
}
return bytes.ToArray();
}
string DecodeStr(byte[] bytes, int start = 0)
{
int len = BitConverter.ToInt32(bytes, start);
string result = Encoding.UTF8.GetString(bytes, start + sizeof(int), len);
return result;
}
public object ToObject(byte[] bytes, Type type, ref int offset)
{
object temp = Activator.CreateInstance(type);
Type dataType = temp.GetType();
FieldInfo[] fieldInfos = dataType.GetFields();
for (int i = 0; i < fieldInfos.Length; i++)
{
fieldInfos[i].SetValue(temp, FieldToObj(bytes, fieldInfos[i].FieldType, ref offset));
}
return temp;
}
object FieldToObj(byte[] bytes, Type type, ref int offset)
{
if (type == typeof(string))
{
int len = BitConverter.ToInt32(bytes, offset);
offset += sizeof(int);
string str = Encoding.UTF8.GetString(bytes, offset, len);
offset += len;
return str;
}
else if (type == typeof(int))
{
int result = BitConverter.ToInt32(bytes, offset);
offset += sizeof(int);
return result;
}
else if (type == typeof(float))
{
float result = BitConverter.ToSingle(bytes, offset);
offset += sizeof(float);
return result;
}
else if (type == typeof(bool))
{
bool result = BitConverter.ToBoolean(bytes, offset);
offset += sizeof(bool);
return result;
}
else if (type.IsEnum)
{
int result = BitConverter.ToInt32(bytes, offset);
offset += sizeof(int);
return result;
}
else if (typeof(IList).IsAssignableFrom(type))
{
IList list = BytesToList(bytes, type, ref offset);
return list;
}
else if (typeof(IDictionary).IsAssignableFrom(type))
{
IDictionary dictionary = BytesToDic(bytes, type, ref offset);
return dictionary;
}
else
{
return ToObject(bytes, type, ref offset);
}
}
IList BytesToList(byte[] bytes, Type type, ref int offset)
{
IList iList = Activator.CreateInstance(type) as IList;
int count = BitConverter.ToInt32(bytes, offset);
offset += sizeof(int);
Type eleType = type.GetGenericArguments()[0];
for (int i = 0; i < count; i++)
{
iList.Add(FieldToObj(bytes, eleType, ref offset));
}
return iList;
}
IDictionary BytesToDic(byte[] bytes, Type type, ref int offset)
{
IDictionary iDic = Activator.CreateInstance(type) as IDictionary;
int count = BitConverter.ToInt32(bytes, offset);
offset += sizeof(int);
Type keyType=type.GetGenericArguments()[0];
Type valueType=type.GetGenericArguments()[1];
for (int i = 0; i < count; i++)
{
object key = FieldToObj(bytes, keyType, ref offset);
object value = FieldToObj(bytes,valueType,ref offset);
iDic.Add(key,value);
}
return iDic;
}
}
总结
这种方法在文件里完全没保存字段的名字,依赖类模板里的字段顺序反序列化,一旦模板类增加、减少了字段,之前的文件要么拿出来转换一下,否则全部作废。拓展性很差。

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









