



1.ConcurrentHashMap 和 Hashtable的比较
1.并发性能对比
Hashtable 是早期的线程安全集合类,但由于每次操作都会锁住整个表,导致并发性能较差。
ConcurrentHashMap 采用了分段锁机制,能有效提高并发性能,在多线程环境下表现优异。
在高并发场景下,ConcurrentHashMap 是比 Hashtable 更好的选择,因为它在保证线程安全的同时,还能保持高效的读写性能。
2. 读写性能对比
Hashtable:
粗粒度锁,由于每次读写都要锁住整个表,所以 读操作 和 写操作 都会阻塞。即便多个线程只是想读取数据,它们也要等待前一个线程释放锁。因此,读写性能很低。
ConcurrentHashMap:
细粒度锁,读操作无锁:在 ConcurrentHashMap 中,读操作不需要加锁,因此多个线程可以同时读取数据。而在写操作时,它只会对某个段加锁,而不是整个表。因此,读写性能都很高。
2.普通的集合框架与JUC(Java Util Concurrency,即Java并发工具包)存在的区别是?
1.用途上
普通集合框架主要用于在单线程环境下对集合进行各种操作,如添加、删除、查找等。
JUC提供了一系列工具和框架来帮助开发者更方便地实现多线程并发控制。
2.线程安全性
普通集合框架大多数普通的集合类(如ArrayList、HashSet、HashMap等)并不是线程安全的。
JUC提供了一系列线程安全的容器类,如ConcurrentHashMap、CopyOnWriteArrayList等。
3.线程池有哪些参数有什么作用
ExecutorService executorService = new ThreadPoolExecutor(40, 1000, 10000, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
其中,自定义线程池的核心参数如下:
1.核心线程数(corePoolSize):线程池中一直保持活动的线程数。可以使用corePoolSize方法来设置。
,一般情况下,可以根据系统的资源情况和任务的特性来设置合适的值。
2.最大线程数(maximumPoolSize):线程池中允许存在的最大线程数。可以使用maximumPoolsize方法来设置。如果所有线程都处于活动状态,而此时又有新的任务提交,线程池会创建新的线程,直到达到最大线程数。
3.空闲线程存活时间(keepAliveTime):当线程池中的线程数量超过核心线程数时,如果这些线程在一定时间内没有执行任务,则这些线程会被销毁。可以使用keepAliveTime和TimeUnit方法来设置。
4.阻塞队列(workQueue):用于存放等待执行的任务的阻塞队列。可以根据任务的特性选择不同类型的队列如LinkedBlockingQueue、ArrayBlockingQueue等。默认情况下,使用无界阻塞队列,即LinkedBlockingQueue,但也可以根据需要设置有界队列。
5.线程工厂(threadFactory):用于创建线程的工厂。可以通过实ThreadFactory接口自定义线程的创建逻辑。
6.拒绝策略(rejectedExecutionHandler):当线程池无法接受新的任务时,会根据设置的拒绝策略进行处理。常见的拒绝策略有 AbortPolicy、DiscardPolicy、DiscardOldestPolicy和 CallerRunsPolicy。
4.CountDownLatch和CyclicBarrier的区别是什么?
CountDownLatch是一个同步辅助类,用于多线程间的协作,使得一部分线程等待其他线程完成操作。它通过一个计数器,当计数器归零时,所有等待的线程才会继续执行。
Countdownlatch指的是让一个或多个线程持续等待,直到其他多线程执行的一组操作全部完成以后,这些等待的线程才会继续执行。
就好比是,有多位选手参加一场百米赛跑,裁判员需要等待全部选手就绪,并且在同一起跑线上。然后,裁判会发出号令:“各就位,预备跑”,随着发令枪响,所有选手才能全部起跑。在这个场景中,各位参赛选手就是线程,而裁判就是CountDownLatch。
当高并发请求时,其await方法有可能会引起死锁。
CountDownLatch适用场景:
1)让单个线程等待多个线程的场景。
比如,一个服务需要从多个远程接口获取数据,我们可以创建多个线程来分别调用远程接口,等待所有远程接口都获得返回数据之后,主服务线程再往下继续执行。像并发计算,结果汇总等等。
2)让多个线程等待的场景。
比如,模拟秒杀场景,让一组线程同时等待,同时恢复执行,实现最大程度的并行性。
CyclicBarrier的功能和CountdownLatch非常类似,也是等待所有参加比赛的选手全部就绪以后,才能开始起跑。它是另外一种多线程并发控制工具,和CountdownLatch不同的是,CyclicBarrier可以重复使用。
适用场景:
需要计算N组人一年的平均工资,每组需要多个线程并行计算,计算完一组,再开始下一组,这样就需要多轮并行计算。
最后,总结一下CountDownLatch和CyclicBarrier的区别,从以下四个方面来分析:
1、CountDownLatch的计数器只能使用一次。而CyclicBarrier的计数器可以使用reset() 方法重置。
2、CyclicBarrier能处理更为复杂的业务场景,比如计算发生错误,可以结束阻塞,重置计数器,重新执行程序
3、CyclicBarrier提供getNumberWaiting()方法,可以获得CyclicBarrier阻塞的线程数量,还提供isBroken()方法,可以判断阻塞的线程是否被中断,等等。
4、CountDownLatch会阻塞主线程,CyclicBarrier不会阻塞主线程,只会阻塞子线程。
5.Spring中写一个接口最后返回json对象该怎么实现?
- 使用SpringMVC时可以使用
@ResponseBody注解,方便的返回json数据 ,该注解用于将Controller的方法返回的对象,根据HTTP Request Header的中的Accept属性,通过适当的HttpMessageConverter转换为指定格式后,写入到Response对象的body数据区。
@RequestMapping("main")
@ResponseBody
public String helloWorld()
{
HashMap mp = new HashMap();
mp.put("Hello", "World");
return mp;
}
2.使用@RestController注解Controller,它的作用相当于@ResponseBody+@Controller,意思是Controller处理完请求后直接返回json格式化数据。
@RestController
public class MyController {
@GetMapping("/getList")
public List<String> getList() {
return Arrays.asList("Item1", "Item2", "Item3");
}
}
5.Springboot过滤器和拦截器的区别?
过滤器是拦截所有请求,而拦截器是拦截在进入到前端控制器之后的请求
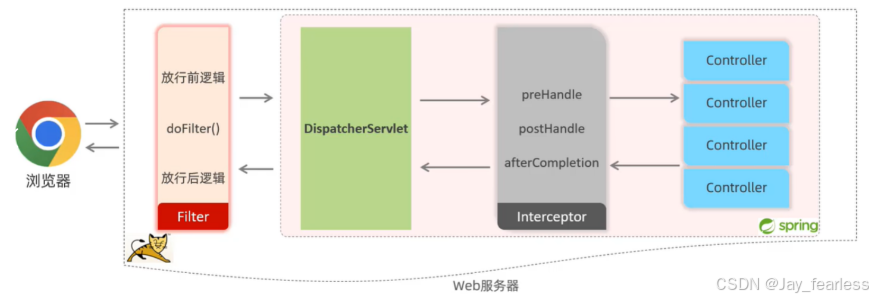
Filter和Listener:依赖Servlet容器,基于函数回调实现。可以拦截所有请求,覆盖范围更广,但无法获取ioc容器中的bean。
Interceptor和aop:依赖spring框架,基于java反射和动态代理实现。只能拦截controller的请求,可以获取ioc容器中的bean,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。。
过滤器的应用场景:
Filter过滤器是Servlet容器层面的,在实现上基于函数回调,可以对几乎所有请求进行过滤。
- 在访问网站时,有时候会发布一些敏感信息,发完以后有的会用*替代。
- 还有就是登陆权限控制等,一个资源,没有经过授权,肯定是不能让用户随便访问的,这个时候,也可以用到过滤器,主要是对用户的一些请求进行一些预处理,并在服务器响应后再进行预处理,返回给用户。
两种实现方式:
1、使用spring boot提供的FilterRegistrationBean注册Filter(既可以配置 Filter 的优先级,也可以配置 Filter 的拦截规则)
public class AFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("=======初始化过滤器A=========");
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain)
throws IOException, ServletException {
long start = System.currentTimeMillis();
filterChain.doFilter(request, response);
System.out.println("filter 耗时:" + (System.currentTimeMillis() - start));
}
@Override
public void destroy() {
System.out.println("=======销毁过滤器=========");
}
}
@Configuration
public class FilterConfig {
/*过滤器注解bean: FilterRegistrationBean, 注册过滤器, 添加过滤器*/
@Bean
public FilterRegistrationBean<AFilter> createFilterRegistrationBean() {
//1.创建FilterRegistrationBean这个对象, 一个过滤器注册器,注册一个过滤器
FilterRegistrationBean<AFilter> filterRegistrationBean = new FilterRegistrationBean<>();
//注册一个过滤器
filterRegistrationBean.setFilter(new AFilter());
//过滤器的配置, 设置拦截的url
filterRegistrationBean.addUrlPatterns("/*");
//给过滤器起名字
filterRegistrationBean.setName("AFilter");
//设置过滤器的执行顺序
filterRegistrationBean.setOrder(1);
return filterRegistrationBean;
}
2、使用原生servlet注解定义Filter(无法指定 Filter 的优先级,如果存在多个 Filter 时,无法通过 @Order 指定优先级)
//一个是filter的名字,一个是对哪个url用此过滤器,Filter,必须要有名字,所有的过滤器执行顺序是根据Filter的名字字母顺序来执行的
@WebFilter(filterName = "filter1",urlPatterns = {"/hello/*"})
public class TimeFilter implements Filter {...}
拦截器应用场景:
拦截器本质上是面向切面编程(AOP),符合横切关注点的功能都可以放在拦截器中来实现,主要的应用场景包括:
- 登录验证,判断用户是否登录。
- 权限验证,判断用户是否有权限访问资源,如校验token
- 日志记录,记录请求操作日志(用户ip,访问时间等),以便统计请求访问量。
- 处理cookie、本地化、国际化、主题等。
拦截器的拦截是基于反射实现的。
拦截器实现方式:
实现拦截器可以通过继承 HandlerInterceptorAdapter类也可以通过实现HandlerInterceptor这个接口。另外,如果preHandle方法return true,则继续后续处理。
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component
public class InterceptorTest implements HandlerInterceptor {
/**
* 在请求处理之前进行调用(Controller方法调用之前)
* 预处理回调方法,实现处理器的预处理
* 返回值:true表示继续流程;false表示流程中断,不会继续调用其他的拦截器或处理器
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
System.out.println("开始拦截.........");
String name = MyCookie.getCookieByKey(request,response,"name");
String password = MyCookie.getCookieByKey(request,response,"password");
//如果session中没有user,表示没登陆
if (password == null|| name == null){
//这个方法返回false表示忽略当前请求,如果一个用户调用了需要登陆才能使用的接口,如果他没有登陆这里会直接忽略掉
//当然你可以利用response给用户返回一些提示信息,告诉他没登陆
request.getRequestDispatcher("/interceptor/to_login").forward(request, response);
return false;
}else {
return true;//放行
}
}
/**
* 请求处理之后进行调用,但是在视图被渲染之前(Controller方法调用之后)
* 后处理回调方法,实现处理器(controller)的后处理,但在渲染视图之前
* 此时我们可以通过modelAndView对模型数据进行处理或对视图进行处理
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
ModelAndView modelAndView) throws Exception {
// TODO Auto-generated method stub
System.out.println("return前");
}
/**
* 在整个请求结束之后被调用,也就是在DispatcherServlet 渲染了对应的视图之后执行(主要是用于进行资源清理工作)
* 整个请求处理完毕回调方法,即在视图渲染完毕时回调,
* 如性能监控中我们可以在此记录结束时间并输出消耗时间,
* 还可以进行一些资源清理,类似于try-catch-finally中的finally,
* 但仅调用处理器执行链中
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
throws Exception {
// TODO Auto-generated method stub
System.out.println("操作完之后,可以用于资源清理");
}
}
6.CurrentHashMap的链表是头插法还是尾插法?
CurrentHashMap的链表插入方法在1.7和1.8有所不同。1.7采用头插法,1.8采用尾插法。
原因主要是因为1.7用头插法考虑到了一个热点数据的点,也就是新插入的数据可能早用到,但是这在CurrentHashMap底层数组扩容的时候也就是rehash的时候,旧链表迁移新链表的时候呢,如果新表的数组索引位置相同,则链表元素相当于倒置,所以最后的结果还是打乱了插入的顺序,所以1.8之后干脆直接换成尾插放弃热点数据策略的使用了。


















 2988
2988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











