




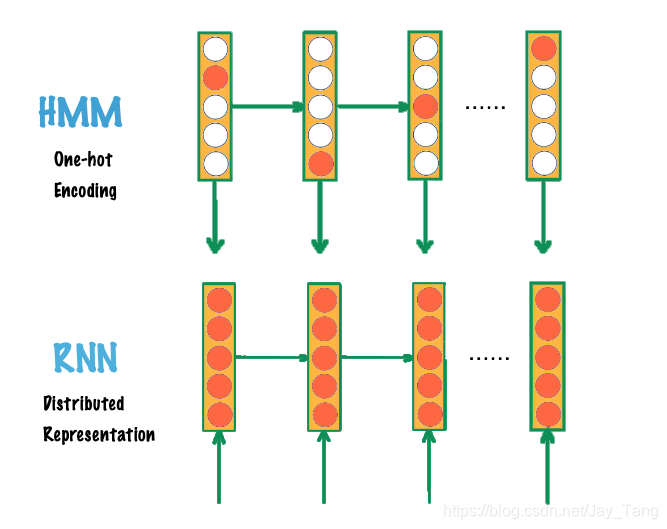
 本文详细介绍了RNN和LSTM在处理序列数据时的作用。RNN因其链式结构适合序列任务,但存在梯度消失问题。LSTM通过门控机制解决了这一问题,能够学习长期依赖。此外,还提到了双向RNN和深度RNN等变体。
本文详细介绍了RNN和LSTM在处理序列数据时的作用。RNN因其链式结构适合序列任务,但存在梯度消失问题。LSTM通过门控机制解决了这一问题,能够学习长期依赖。此外,还提到了双向RNN和深度RNN等变体。
文章目录
往期文章链接目录
Sequence Data
There are many sequence data in applications. Here are some examples
-
Machine translation
- from text sequence to text sequence.
-
Text Summarization
- from text sequence to text sequence.
-
Sentiment classification
- from text sequence to categories.
-
Music Generation
- from nothing or some simple stuff (character, integer, etc) to wave sequence.
-
Name entity recognition (NER)
- From text sequence to label sequence.
Why not use a standard neural network for sequence tasks
-
Inputs, outputs can be different lengths in different examples. This can be solved by standard neural network by paddings with the maximum lengths but it’s not a good solution since there would be too many parameters.
-
Doesn’t share features learned across different positions of text/sequence. Note that Convolutional Neural Network (CNN) is a good example of parameter sharing, so we should have a similar model for sequence data.
RNN
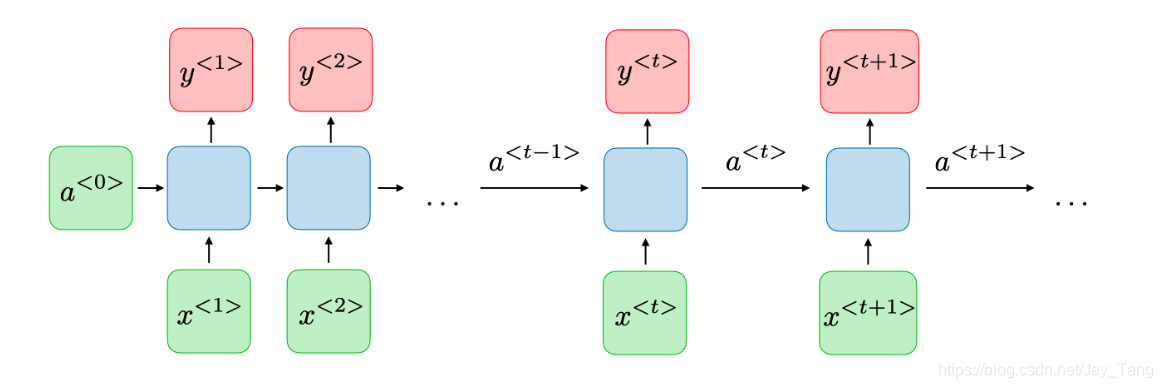
A Recurrent Neural Network (RNN) can be thought of as multiple copies of the same network, each passing a message to a successor. This chain-like nature reveals that recurrent neural networks are intimately related to sequences. Therefore, they’re the natural architecture of neural network to use for sequence data. Note that it also allows previous outputs to be used as inputs.
For each time step t t t, the activation a < t > a^{<t>} a<t> and the output y < t > y^{<t>} y<t> are expressed as follows:
-
a < t > = g 1 ( W a a a < t − 1 > + W a x x < t > + b a ) a^{<t>}=g_{1}\left(W_{a a} a^{<t-1>}+W_{a x} x^{<t>}+b_{a}\right) a<t>=g1(Waaa<t−1>+Waxx<t>+ba)
-
y < t > = g 2 ( W y a a < t > + b y ) y^{<t>}=g_{2}\left(W_{y a} a^{<t>}+b_{y}\right) y<t>=g2(Wyaa<t>+by)
These calculation could be visualized in the following figure
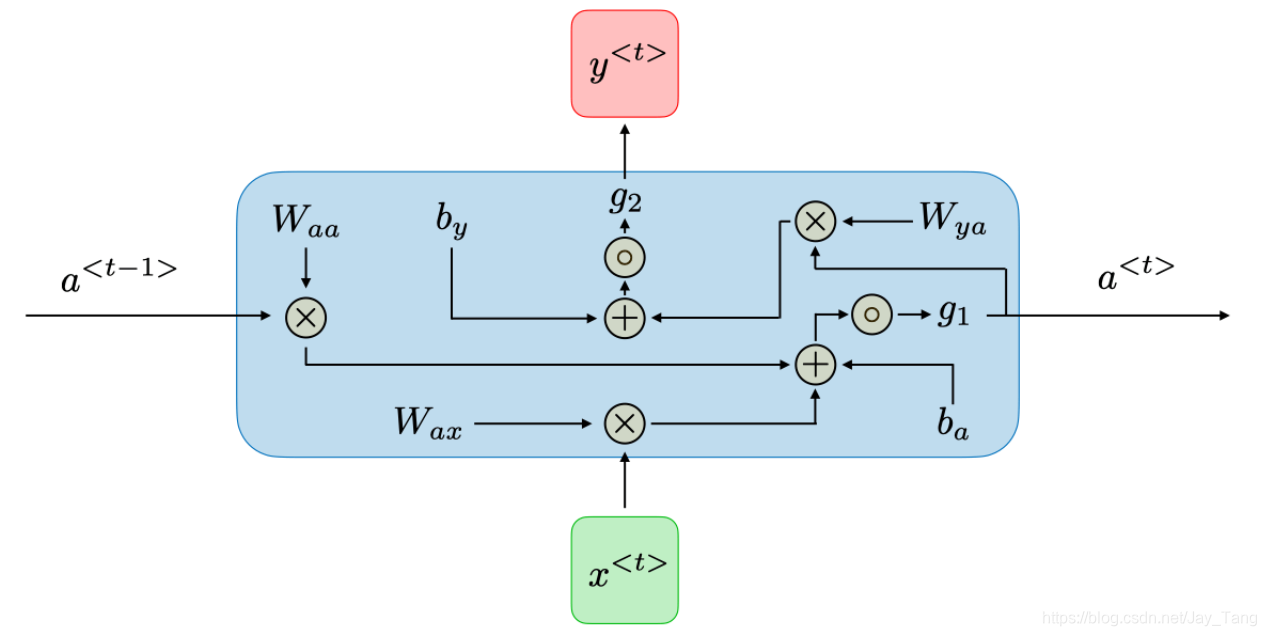
Note:
-
dimension of W a a W_{a a} Waa: (number of hidden neurons, number of hidden neurons)
-
dimension of W a x W_{a x} Wax: (number of hidden neurons, length of x x x)
-
dimension of W y a W_{y a} Wya: (length of y y y, number of hidden neurons)
-
The weight matrix W a a W_{a a} Waa is the memory the RNN is trying to maintain from the previous layers.
-
dimension of b a b_a ba: (number of hidden neurons, 1)
-
dimension of b y b_y b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









