



第一次接触到核函数还是在大一学线代的时候,现在在一些应用领域经常看到它的身影,在网络上学习一番后,结合高人的叙述和自己的理解写下这个学习记录。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、回答作者:王赟 Maigo
链接:https://www.zhihu.com/question/24627666/answer/28440943
来源:知乎
我来举一个核函数把低维空间映射到高维空间的例子。
下面这张图位于第一、二象限内。我们关注红色的门,以及“北京四合院”这几个字下面的紫色的字母。我们把红色的门上的点看成是“+”数据,紫色字母上的点看成是“-”数据,它们的横、纵坐标是两个特征。显然,在这个二维空间内,“+”“-”两类数据不是线性可分的。

我们现在考虑核函数K(v1,v2)=<v1,v2>2K(v_1,v_2) = <v_1,v_2>^2K(v1,v2)=<v1,v2>2,即“内积平方”。
这里面v1=(x1,y1),v2=(x2,y2)v_1=(x_1,y_1), v_2=(x_2,y_2)v1=(x1,y1),v2=(x2,y2)是二维空间中的两个点。
这个核函数对应着一个二维空间到三维空间的映射,它的表达式是:
P(x,y)=(x2,2xy,y2)P(x,y)=(x^2,\sqrt{2}xy,y^2)P(x,y)=(x2,2xy,y2)
可以验证,在P这个映射下,原来二维空间中的图在三维空间中的像是这个样子:
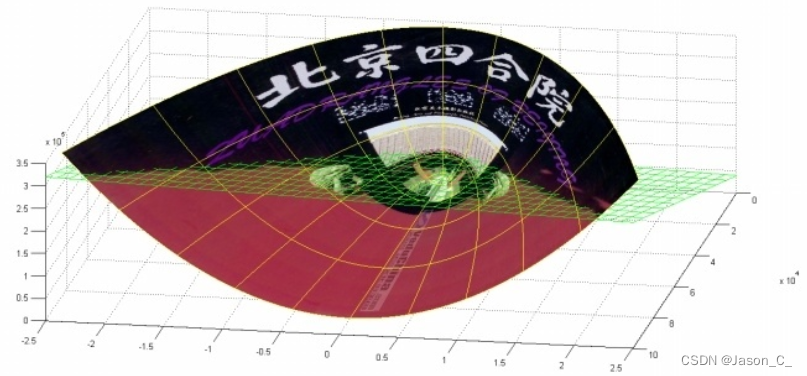
(前后轴为x轴,左右轴为y轴,上下轴为z轴)
注意到绿色的平面可以完美地分割红色和紫色,也就是说,两类数据在三维空间中变成线性可分的了。
而三维中的这个判决边界,再映射回二维空间中是这样的:

这是一条双曲线,它不是线性的。
=============================================
如上面的例子所说,核函数的作用就是隐含着一个从低维空间到高维空间的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。
当然,我举的这个具体例子强烈地依赖于数据在原始空间中的位置。
事实中使用的核函数往往比这个例子复杂得多。它们对应的映射并不一定能够显式地表达出来;它们映射到的高维空间的维数也比我举的例子(三维)高得多,甚至是无穷维的。这样,就可以期待原来并不线性可分的两类点变成线性可分的了。
在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:
- 线性:K(v1,v2)=<v1,v2>K(v_1,v_2)=<v_1,v_2>K(v1,v2)=<v1,v2>
- 多项式:K(v1,v2)=(γ<v1,v2>+c)nK(v_1,v_2)=(\gamma<v_1,v_2>+c)^nK(v1,v2)=(γ<v1,v2>+c)n
- Radial basis function:K(v1,v2)=exp(−γ∣∣v1−v2∣∣2)K(v_1,v_2)=\exp(-\gamma||v_1-v_2||^2)K(v1,v2)=exp(−γ∣∣v1−v2∣∣2)
- Sigmoid:K(v1,v2)=tanh(γ<v1,v2>+c)K(v_1,v_2)=\tanh(\gamma<v_1,v_2>+c)K(v1,v2)=tanh(γ<v1,v2>+c)
我举的例子是多项式核函数中γ=1,c=0,n=2\gamma=1, c=0, n=2γ=1,c=0,n=2的情况。
在实用中,很多使用者都是盲目地试验各种核函数,并扫描其中的参数,选择效果最好的。至于什么样的核函数适用于什么样的问题,大多数人都不懂。很不幸,我也属于这大多数人,所以如果有人对这个问题有理论性的理解,还请指教。
=============================================
核函数要满足的条件称为Mercer’s condition。
由于我以应用SVM为主,对它的理论并不很了解,就不阐述什么了。
使用SVM的很多人甚至都不知道这个条件,也不关心它;有些不满足该条件的函数也被拿来当核函数用。
2、回答作者:文鸿郴
链接:https://www.zhihu.com/question/24627666/answer/28460490
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
核函数和映射没有关系。
一般英文文献对Kernel有两种提法,一是Kernel Function,二是Kernel Trick。从Trick一词中就可以看出,这只是一种运算技巧而已,不涉及什么高深莫测的东西。
具体Trick的意义,就是简化计算二次规划中间的一步内积计算。也即中间步骤有一步必须求得ϕ(xi)′ϕ(xi)\phi(x_i)'\phi(x_i)ϕ(xi)′ϕ(xi),而我们可以定义核函数K(xi,yi)=ϕ(xi)′ϕ(xi)K(x_i,y_i)=\phi(x_i)'\phi(x_i)K(xi,yi)=ϕ(xi)′ϕ(xi),使得我们在不需要显式计算每一个ϕ(xi)′\phi(x_i)'ϕ(xi)′、甚至不需要知道ϕ(⋅)\phi(·)ϕ(⋅)长什么样的情况下,直接求出ϕ(xi)′ϕ(xi)\phi(x_i)'\phi(x_i)ϕ(xi)′ϕ(xi)的值来。
也就是说,核函数、内积、相似度这三个词是等价的。因为inner product其实就是一种similarity的度量。核函数和映射是无关的。
但为什么这么多的认知中核函数是一种映射呢。一来这两件事一般先后进行,所以常常被混为一谈。二来就像前面所述,核函数让人们不需要知道长什么样,不需要知道怎么选取映射,就能够算出内积。因此这常常被认作是一种implicit mapping。这是由Mercer Theorem(任何半正定的函数都可以作为核函数) 保证的,即只要核函数满足一定条件,那么映射空间一定存在。
3、有价值的回答
梦想是养只羊驼
整个story可以这么说:那些搞svm,ridge regression的人,发现自己的算法对数据集的效果不好,他们认为这可能是因为数据集线性不可分。另外他们发现他们搞出的式子里,出现的都是两个数据点的内积。他们想,我们要是把原始数据集映射到高维可能就线性可分啦,但是这可是内积啊,而且怎么找映射函数呢?这时候Mercer Theorem出现了,简直就是黑暗中的一缕阳光啊!好的,那就构造一个kernel function吧,根据Mercer Theorem,那些原始维度的内积转换到高维内积只需要把数据点带进核函数就ok啦。这不就简单了?结果在数据集上居然很好!!!然后这种方法就有很多时髦名称了。大家都follow么。
风断桥
按我自己理解就是,处理低维非线性可分数据一般的步骤应该是先找到映射函数(映射到高维空间去),然后再高维空间里面通过内积(其实内积仅仅是其中一种在高维空间里面度量其数据相互之间距离的一种手段,这里的距离可能定义不准确,可以这么说,算是度量的一种标准吧),然后我在很多论文里面就发现,还是以RBF为例,往往都是说原始数据通过一个核函数,然后乘以一个权值,输出最后预测结果…然后接下来总会有解释说通过了核函数将原始数据映射到高维空间,从而实现了数据的线性分类!我基本上觉得这种解释就是一种敷衍,完全不是对其方法的一种解释,反而恰恰是对原始方法的一种误解,然而还有好多期刊也好像不太在意这样子的解释。听完大家的看法之后,帮助理解了不少,我整理整理,谢谢各位!
——文鸿郴
你的理解是对的。先映射,再写出优化问题,求解过程中用到内积,内积计算时用到核函数简化计算😃

御宅暴君
「核函数=内积=相似度」,原来如此!怪不得说它只是一种 trick 呢,原来是直接简化内积(即相似度)计算的手法。

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









