




大模型AI正深刻变革机器人操作系统(ROS)的发展。它显著提升了ROS机器人的感知与决策能力,通过自然语言交互、增强的环境理解以及优化的复杂任务规划,赋予机器人前所未有的智能水平。同时,大模型AI也推动了ROS系统架构与性能的优化,催生了如PRM等新型架构,并借助TensorRT等工具加速AI模型推理,ROS 2的实时性、安全性与多机器人支持也得到增强。这共同拓展了ROS在具身智能、医疗健康、智能制造等新兴AI驱动场景的应用潜力。然而,这一融合也带来了计算资源、模型集成、实时性与安全性保障、数据依赖、模型透明度以及开发者学习曲线等新挑战,但同时也创造了提升机器人智能化与自主性、增强人机交互、降低开发门槛、推动ROS生态创新与标准化以及拓展应用边界的巨大机遇。
1. 大模型AI提升ROS机器人的感知与决策能力
大模型AI,特别是大型语言模型(LLM)和视觉语言模型(VLM),正在为ROS机器人带来感知与决策能力的革命性提升。通过赋予机器人更强大的自然语言理解、环境感知、复杂任务规划以及自适应反馈能力,大模型AI使得ROS机器人能够更智能、更自主地与物理世界交互。
1.1 基于大型语言模型(LLM)的自然语言交互与任务理解
大型语言模型(LLM)的崛起为ROS机器人提供了前所未有的自然语言交互能力,极大地简化了人机沟通的复杂性,并提升了机器人对任务意图的理解深度。通过将LLM(如GPT-4、ChatGPT)集成到ROS框架中,例如在ROS-LLM框架中,用户可以使用自然语言直接向机器人下达指令,描述复杂任务,而无需编写繁琐的代码 。这种交互方式不仅降低了机器人编程的门槛,使得非专业用户也能有效地与机器人协作,还使得机器人能够理解更抽象、更模糊的指令,并根据上下文信息进行推理。例如,在ROS-LLM框架中,LLM能够处理用户通过聊天界面输入的自然语言提示和来自ROS的上下文信息,从而让非专家用户能够清晰地向系统阐述任务需求 。这种能力的提升,使得机器人不再仅仅是执行预设程序的工具,而是能够更像一个“合作伙伴”一样理解并执行任务。
LLM在任务理解方面的能力,尤其体现在其能够将高级、模糊的自然语言指令分解为具体的、可执行的机器人动作序列。例如,用户可以说“帮我整理一下桌子”,LLM结合对“整理桌子”的一般性理解以及通过ROS获取的当前桌面物体信息(如物体位置、类别),可以生成一系列具体的动作指令,如“移动到A物体旁”、“抓取A物体”、“将A物体放置到B位置”等。ROS-LLM框架通过将LLM与ROS的动作库和实时传感器数据相结合,旨在为机器人编程提供一个更灵活、可扩展的解决方案 。这种方法不仅避免了为特定任务收集海量数据的挑战,还增强了机器人系统在动态环境中优化动作的适应性 。此外,一些研究如ROSGPT,利用ChatGPT作为人类和机器人系统之间的高级翻译中介,通过其零样本和少样本学习能力,将非结构化的人类语言命令转换为格式规范、上下文特定的机器人命令,这些命令可以被ROS节点轻松解释并转换为适当的ROS命令,从而使机器人能够以更自然、直观的方式按照人类的要求执行任务 。
然而,LLM在理解和执行自然语言指令方面也面临一些挑战。例如,提示词的微小变化可能会显著影响模型的输出,这揭示了其语言处理能力的脆弱性和优势 。在ROS-LLM的实验中观察到,当提示中使用“另一个立方体”来指代第二个立方体时,模型生成了正确的动作序列,但在使用“另一个立方体”时却遇到了困难。类似地,“将盒子A放在盒子B上”与“将盒子A放在盒子B的顶部”这样的提示之间也存在差异,其中“在顶部”的加入改变了生成的动作 。这表明LLM对某些关键词或短语特别敏感,这些关键词或短语暗示了动作复杂性或特异性的变化,例如需要精确定位的空间关系。因此,增强机器人AI系统中的自然语言理解能力,使其能够更好地处理语义上的细微差别,并提高对微小语言变化的鲁棒性,对于开发更可靠、能力更强的机器人助手至关重要 。
1.2 利用生成式AI和视觉语言模型(VLM)增强环境感知与场景理解
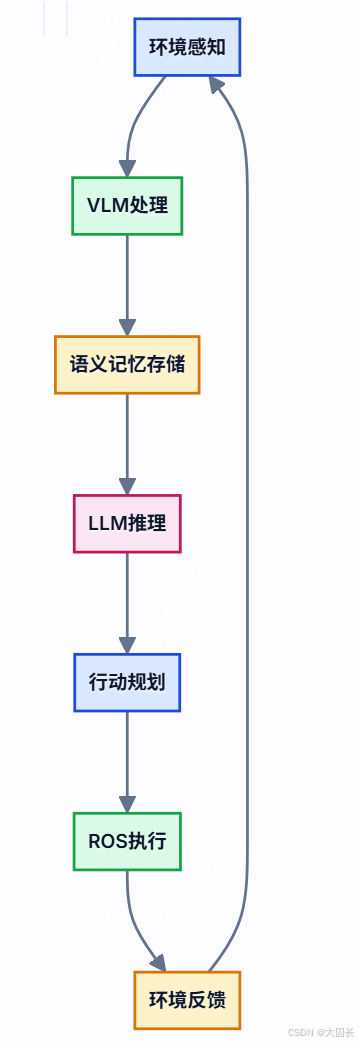
生成式AI和视觉语言模型(VLM)的引入,极大地提升了ROS机器人的环境感知和场景理解能力,使其能够更全面、更智能地与周围世界互动。传统的机器人感知主要依赖于特定任务的模型,而VLM等大模型通过在海量多模态数据上进行预训练,获得了强大的泛化能力和对图像、文本之间关联的深刻理解。NVIDIA等公司正在将生成式AI工具、仿真和感知工作流程引入ROS开发者生态系统,例如通过ROS 2节点提供经过NVIDIA Jetson优化的LLM和VLM,以增强机器人的能力 。这些模型使得机器人不仅能“看到”环境中的物体,还能理解物体的属性、它们之间的关系,甚至根据文本描述在场景中定位物体。例如,Canonical展示的NanoOWL模型,一个在NVIDIA Jetson Orin Nano系统模块上运行的零样本物体检测模型,允许机器人实时识别广泛的对象,而无需依赖预定义的类别 。
VLM的应用使得机器人能够进行更高级的场景理解。例如,机器人可以分析一张厨房的图片,并回答诸如“桌子上有什么饮料?”或“微波炉的门是开着的吗?”之类的问题。这种能力对于机器人在复杂动态环境中执行任务至关重要。ReMEmbR系统,构建于ROS 2之上,利用生成式AI(结合LLM、VLM和检索增强生成)来增强机器人推理和行动能力,使其能够构建和查询长期语义记忆,从而提高其导航和与环境互动的能力 。这意味着机器人可以记住之前见过的物体或场景,并在后续的任务中利用这些信息。例如,如果机器人被告知“把咖啡杯拿到我昨天工作的房间”,它需要理解“咖啡杯”是什么,并通过语义记忆找到“昨天工作的房间”的位置。这种基于VLM的场景理解,结合LLM的推理能力,使得机器人能够处理更复杂的指令,并在非结构化环境中更自主地行动。
此外,生成式AI也被用于生成合成训练数据,以改善感知模型的准确性 。这对于在现实世界中获取大量高质量标注数据既耗时又昂贵的机器人应用来说,是一个重要的补充。通过生成多样化的虚拟场景和物体,可以有效地扩充训练数据集,提高模型的鲁棒性和泛化能力。例如,可以生成不同光照条件、不同视角、不同遮挡情况下的物体图像,从而让感知模型在真实环境中遇到这些情况时表现更好。AI驱动的感知系统通常依赖于各种神经网络模型,如用于图像识别的CNN和用于生成合成训练数据的GAN,这些模型随着时间的推移表现出显著的性能改进,在实时物体检测和场景理解等领域取得了进展 。通过结合大数据和大模型,机器人可以更有效地处理来自各种传感器的数据,从而更全面、准确地感知环境,并快速响应,从而执行更复杂的任务 。
1.3 结合Transformer等模型优化复杂任务决策与规划
Transformer模型及其变体在自然语言处理和计算机视觉领域的巨大成功,也为其在机器人复杂任务决策与规划方面的应用铺平了道路。这些模型强大的序列建模能力和对上下文信息的有效捕捉,使其能够处理机器人任务中常见的时序依赖和部分可观察性问题。在ROS生态中,研究者们开始探索将Transformer架构集成到机器人的决策与控制回路中。例如,CTSAC(Curriculum-Based Transformer Soft Actor-Critic)方法将Transformer强大的序列感知能力集成到SAC(Soft Actor-Critic)框架中,以利用机器人的当前和历史状态信息 。这种集成使得智能体能够发现环境不同区域及其过去状态之间的潜在关系,帮助机器人在陷入局部最优时摆脱循环状态,从而增强其决策和推理能力 。这对于需要长期规划和记忆的复杂导航或操作任务尤为重要。
大型语言模型(LLM)本身,作为基于Transformer的模型,在任务规划方面也展现出巨大潜力。它们可以将高级指令分解为一系列子任务,甚至生成可执行的代码。例如,在Nature论文描述的系统中,Transformer(GPT-4)接收用户查询,并结合环境图像和代码示例知识库,将高级抽象任务分解为可操作的高级子任务,检索相关知识库中的代码示例,进行调整并编写针对这些任务的Python代码,然后将生成的代码发送给机器人控制器执行 。这种能力使得机器人能够处理前所未有的新任务,而无需针对每个任务进行专门的编程。ROS-LLM框架也利用了LLM的表达能力,结合模块化的动作库和实时传感器数据,为机器人编程提供灵活的解决方案 。这种方法不仅避免了为特定任务收集海量数据的需求,还增强了机器人系统在动态环境中优化动作的适应性 。
然而,直接将LLM用于决策和规划也存在挑战。一个关键问题是LLM生成的计划可能缺乏对物理世界约束和机器人具体能力的考虑,导致计划不可行或不安全。因此,研究者们正在探索将LLM的规划能力与传统的机器人规划方法(如行为树、状态机)相结合,或者通过反馈机制来修正和完善LLM生成的计划。例如,ROS-LLM框架支持将LLM的输出自动提取为行为,并执行ROS动作/服务,同时支持多种行为执行模式,包括序列、行为树和状态机 。此外,研究者们也在探索如何让LLM的推理过程与决策结果更一致和可靠。例如,有研究提出通过排序损失(ranking loss)将思维链(CoT)答案与规划结果对齐,确保模型的解释与其结论一致,并重新设计具有逻辑思维的CoT,使模型能够像人类驾驶员一样理解场景并进行推理,从而使整个决策过程具有可解释性和交互性 。这些努力旨在充分发挥Transformer等大模型在复杂任务决策与规划中的潜力,同时确保其在实际机器人应用中的可靠性和安全性。
1.4 通过反馈机制(如LLM反思)提升决策的适应性与鲁棒性
反馈机制在提升基于大模型AI的ROS机器人决策适应性和鲁棒性方面扮演着至关重要的角色。由于大模型在训练时可能未接触到所有可能的现实世界场景,或者其生成的内容可能存在不确定性,因此引入有效的反馈机制可以帮助机器人从错误中学习,并根据实际环境调整其行为。LLM反思(LLM reflection)是一种重要的反馈形式,它允许LLM根据人类反馈或环境反馈来评估和修正其先前的决策或生成的计划 。在ROS-LLM框架中,LLM反思通过人类和环境反馈来实现,这有助于系统从错误中学习并改进未来的任务执行 。例如,如果机器人执行一个由LLM生成的计划失败了,反馈机制可以将失败的信息(如传感器读数、错误代码)以及人类的修正建议(如“你应该更慢地接近物体”)反馈给LLM。LLM随后可以利用这些信息来重新规划或调整其内部参数,从而提高下一次执行相似任务的成功率。
除了LLM自身的反思能力,将外部反馈直接集成到机器人控制回路中也至关重要。例如,在Nature论文描述的系统中,机器人的动作受到力(F)和视觉(V)反馈的控制 。模型使用视觉来识别不同物体的属性(例如,咖啡杯的姿态X),以便准确抓取物体。机器人使用力(f)和扭矩(τ)反馈(通过ATI力传感器获得)来熟练地操作物体(例如,确定倒多少水)。由于视觉信号(η_vision)、机器人关节角度(η_angle)和力传感器信号(η_force)中存在噪声,反馈是必要的。反馈通过ROS更新运动,通过线性和角速度命令实现期望的目标 。这种闭环反馈控制使得机器人能够适应动态变化的环境和不确定性。例如,如果机器人在抓取物体时感受到意外的阻力,力反馈可以触发一个调整动作,以防止物体滑落或损坏。
此外,一些研究还探索了如何利用人类反馈来直接塑造LLM的行为或机器人的策略。例如,Liu等人提出的OLAF(Operation-re
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









