







上篇我们通过Ollama和Dify复刻一套私有化部署的智能问答系统《构建企业级智能问答系统:Ollama + Dify + RAG 的完美组合》,我们在优化知识库需要配置Rerank模型时,发现了一个性能强大且功能全面的分布式推理框架Xorbits Inference(Xinference)。
Xinference由国人开发的推理框架,可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xinference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xinference 与最前沿的 AI 模型,发掘更多可能。
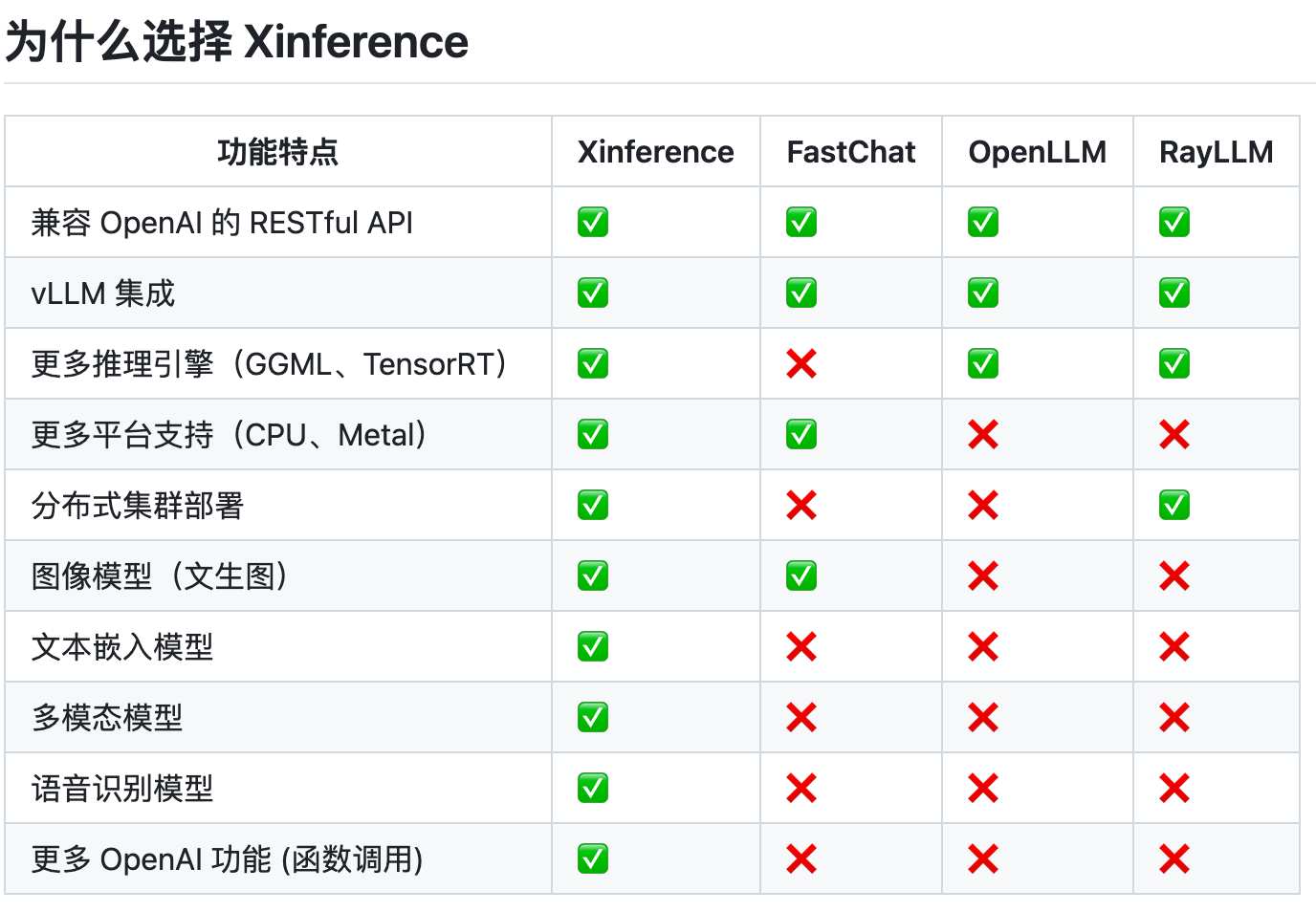
主要功能
模型推理,轻而易举:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。
前沿模型,应有尽有:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!
异构硬件,快如闪电:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!
接口调用,灵活多样:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。
集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。
开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,FastGPT,Dify,RAGFlow以及 Chatbox。

-
LangChain:一个旨在帮助开发人员使用语言模型构建端到端的应用程序的开源框架。
-
LlamaIndex:一个更专注于数据处理的LLM框架。
-
FastGPT:一个基于 LLM 大模型的开源 AI 知识库构建平台。提供了开箱即用的数据处理、模型调用、RAG 检索、可视化 AI 工作流编排等能力,帮助您轻松实现复杂的问答场景。
-
Dify: 一个涵盖了大型语言模型开发、部署、维护和优化的 LLMOps 平台。
-
RAGFlow: 是一款基于深度文档理解构建的开源 RAG 引擎。
-
Chatbox: 一个支持前沿大语言模型的桌面客户端,支持 Windows,Mac,以及 Linux。

入门指南
Jupyter Notebook
体验 Xinference 最轻量级的方式是使用我们 Google Colab 上的 Jupyter Notebook。
Docker
Nvidia GPU 用户可以使用Xinference Docker 镜像 启动 Xinference 服务器。在执行安装命令之前,确保你的系统中已经安装了 Docker 和 CUDA。
当前,可以通过两个渠道拉取 Xinference 的官方镜像。
1. 在 Dockerhub 的
xprobe/xinference仓库里。2. Dockerhub 中的镜像会同步上传一份到阿里云公共镜像仓库中,供访问 Dockerhub 有困难的用户拉取。
拉取命令:
docker pullregistry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:<tag>。目前可用的标签包括:
nightly-main: 这个镜像会每天从 GitHub main 分支更新制作,不保证稳定可靠。v<release version>: 这个镜像会在 Xinference 每次发布的时候制作,通常可以认为是稳定可靠的。latest: 这个镜像会在 Xinference 发布时指向最新的发布版本- 对于 CPU 版本,增加
-cpu后缀,如nightly-main-cpu。
docker pull registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latest
使用镜像
你可以使用如下方式在容器内启动 Xinference,同时将 9997 端口映射到宿主机的 9998 端口,并且指定日志级别为 DEBUG,也可以指定需要的环境变量。
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0 --log-level debug
--gpus必须指定,正如前文描述,镜像必须运行在有 GPU 的机器上,否则会出现错误。
-H 0.0.0.0也是必须指定的,否则在容器外无法连接到 Xinference 服务。可以指定多个
-e选项赋值多个环境变量。当然,也可以运行容器后,进入容器内手动拉起 Xinference。
挂载模型目录
默认情况下,镜像中不包含任何模型文件,使用过程中会在容器内下载模型。如果需要使用已经下载好的模型,需要将宿主机的目录挂载到容器内。这种情况下,需要在运行容器时指定本地卷,并且为 Xinference 配置环境变量。
docker run -v </on/your/host>:</on/the/container> -e XINFERENCE_HOME=</on/the/container> -p 9998:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0上述命令的原理是将主机上指定的目录挂载到容器中,并设置 XINFERENCE_HOME 环境变量指向容器内的该目录。这样,所有下载的模型文件将存储在您在主机上指定的目录中。您无需担心在 Docker 容器停止时丢失这些文件,下次运行容器时,您可以直接使用现有的模型,无需重复下载。
如果你在宿主机使用的默认路径下载的模型,由于 xinference cache 目录是用的软链的方式存储模型,需要将原文件所在的目录也挂载到容器内。例如你使用 huggingface 和 modelscope 作为模型仓库,那么需要将这两个对应的目录挂载到容器内,一般对应的 cache 目录分别在 <home_path>/.cache/huggingface 和 <home_path>/.cache/modelscope,使用的命令如下:
docker run \
-v /data/ai/cache/.xinference:/root/.xinference \
-v /data/ai/cache/huggingface:/root/.cache/huggingface \
-v /data/ai/cache/modelscope:/root/.cache/modelscope \
-p 9997:9997 \
--gpus all \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0Kubernetes
确保你的 Kubernetes 集群开启了 GPU 支持,然后通过 helm 进行如下方式的安装。
# 新增xinference仓库
helm repo add xinference https://xorbitsai.github.io/xinference-helm-charts
# 更新仓库,查询可安装的版本
helm repo update xinference
helm search repo xinference/xinference --devel --versions
# 在K8s中安装xinference
helm install xinference xinference/xinference -n xinference --version 0.0.1-v<xinference_release_version>更多定制化安装方式,请参考文档。
快速开始
使用 pip 安装 Xinference,操作如下。(更多选项,请参阅安装页面。)
pip install "xinference[all]"要启动一个本地的 Xinference 实例,请运行以下命令:
$ xinference-local一旦 Xinference 运行起来,你可以通过多种方式尝试它:通过网络界面、通过 cURL、通过命令行或通过 Xinference 的 Python 客户端。更多指南,请查看我们的文档。
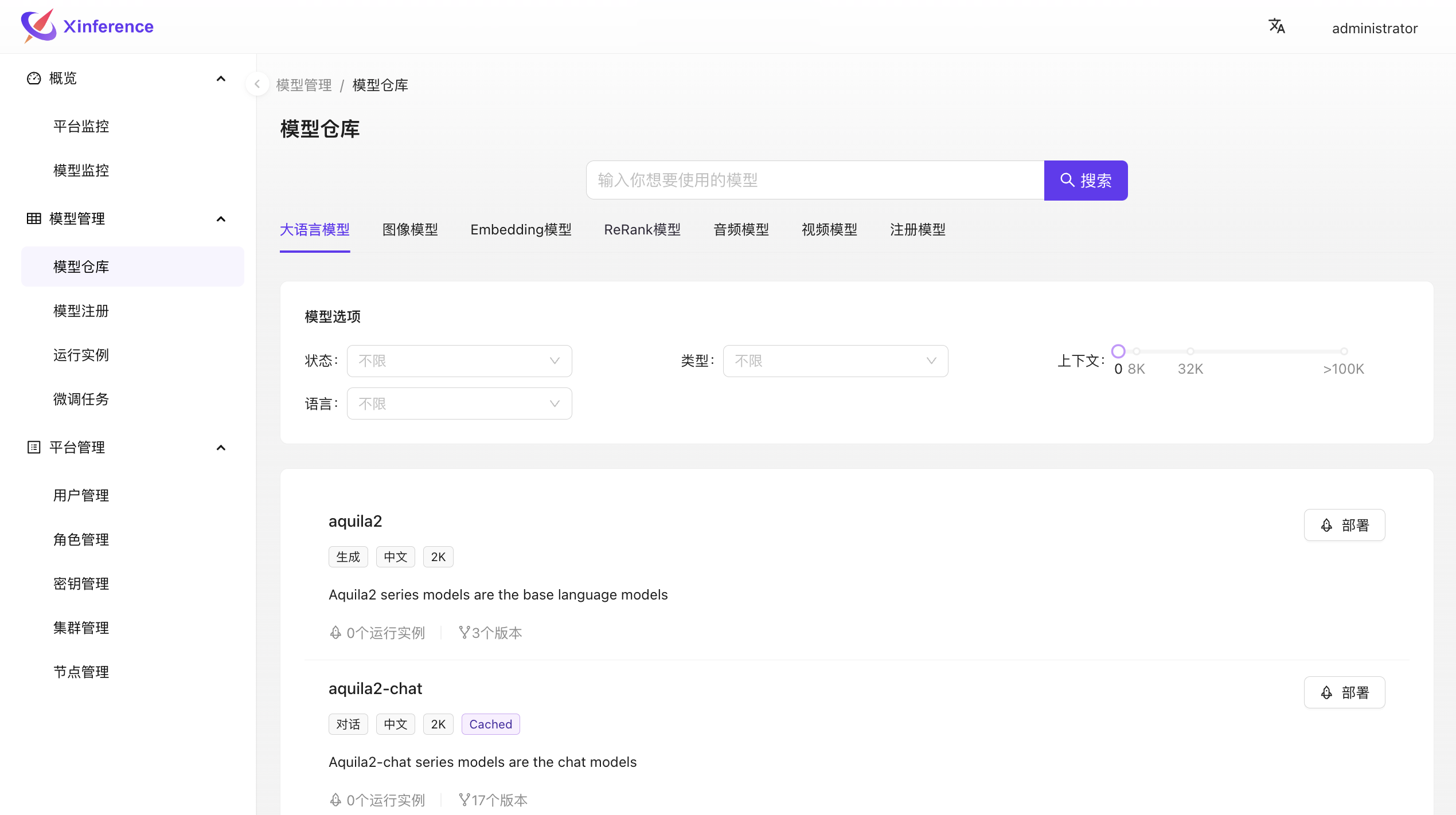
重排序模型
以下是 Xinference 中内置的重排序模型列表:
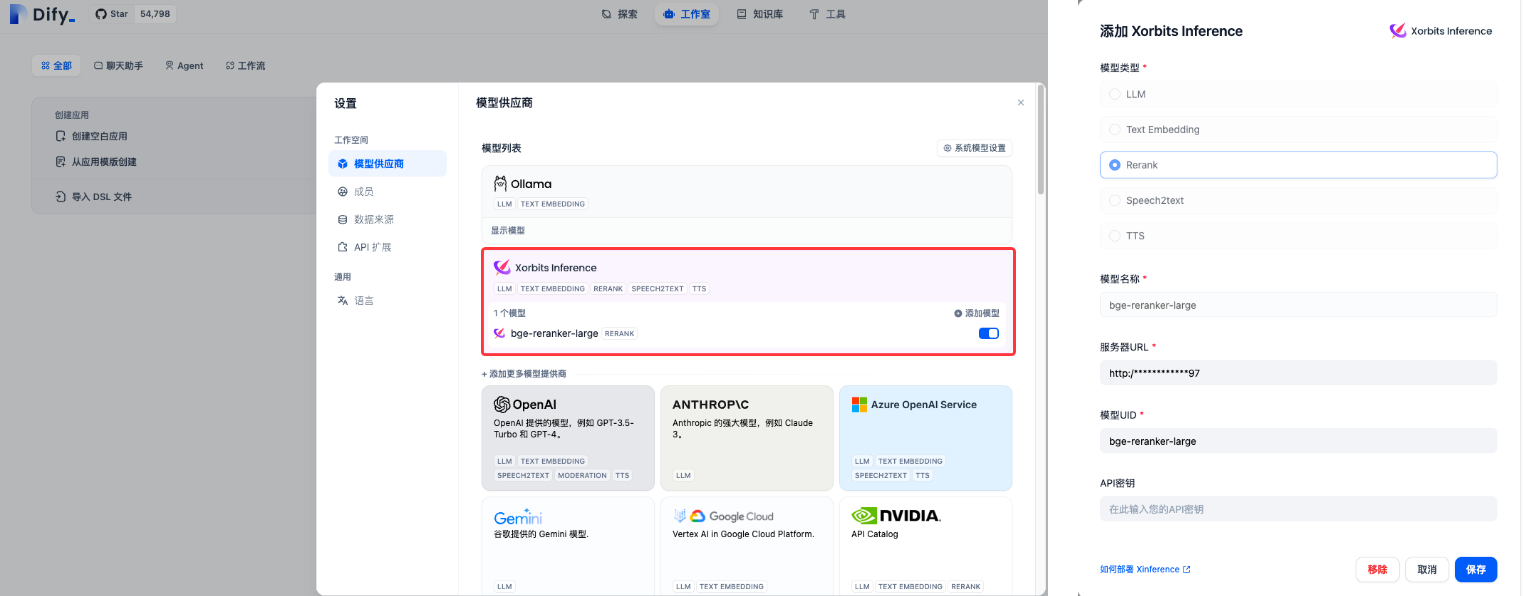
在Xinference中添加启动重排序模型 bge-reranker-large。

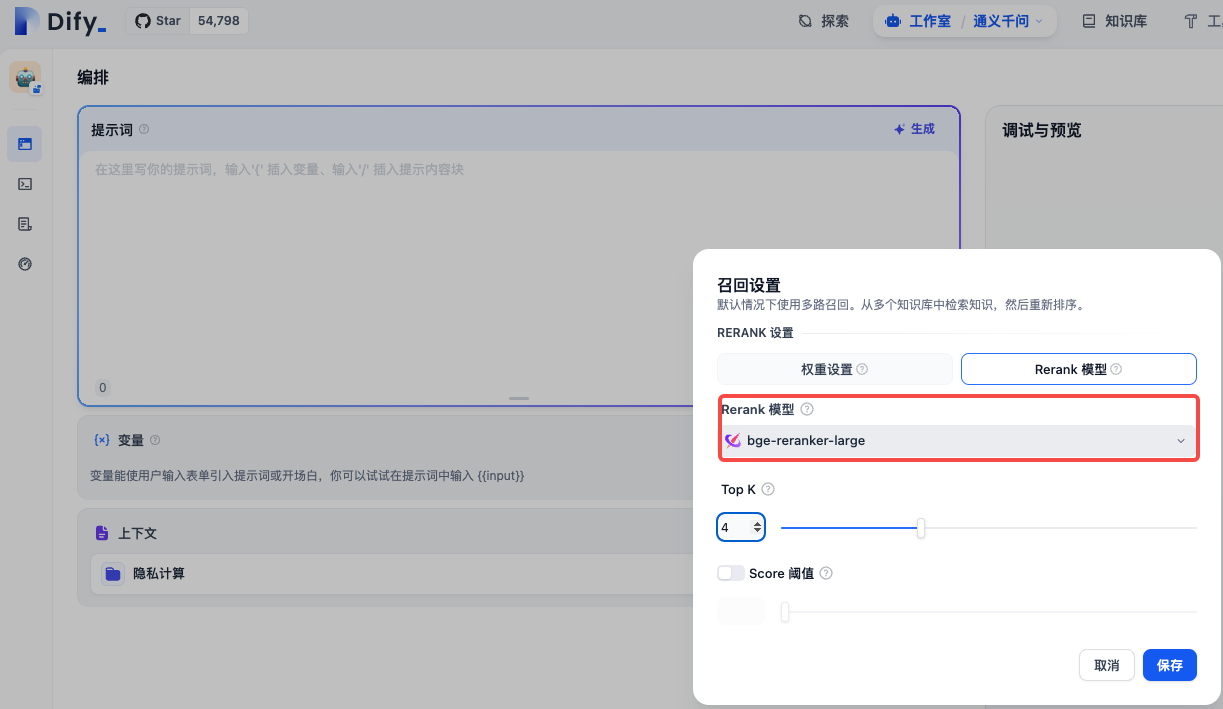
在Dify中配置重排序模型,可用于智能问答知识库召回。
企业版和开源版的对比




















 2869
2869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









