



一、Xinference的基本使用
1、概述
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。
GitHub:https://github.com/xorbitsai/inference
官方文档:https://inference.readthedocs.io/zh-cn/latest/index.html
2、安装
Xinference 在 Linux, Windows, MacOS 上都可以通过 pip 来安装。如果需要使用Xinference进行模型推理,可以根据不同的模型指定不同的引擎。
目前Xinference支持以下推理引擎:
vllm
sglang
llama.cpp
transformers
创建一个xinference虚拟环境,使用Python版本3.10
conda create -n xinference python=3.10
如果希望能够推理所有支持的模型,可以用以下命令安装所有需要的依赖:
pip install "xinference[all]"
使用其他引擎
# Transformers引擎
pip install "xinference[transformers]"
# vLLM 引擎
pip install "xinference[vllm]"
# Llama.cpp 引擎
# 初始步骤:
pip install xinference
# Apple M系列
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# 英伟达显卡:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# AMD 显卡:
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# SGLang 引擎
pip install 'xinference[sglang]'
注意:
在执行安装Xinference过程中,可能会出现异常,可参考下文异常项的
异常1、异常2,进行解决
3、启动服务
可以在本地运行Xinference,也可以使用Docker部署Xinference,甚至在集群环境中部署Xinference。这里采用本地运行Xinference。
执行以下命令启动本地的Xinference服务
xinference-local
xinference-local --host 0.0.0.0 --port 9997
启动日志如下:
(xinference) root@master:~# xinference-local --host 0.0.0.0 --port 9997
2024-07-22 06:24:11,551 xinference.core.supervisor 312280 INFO Xinference supervisor 0.0.0.0:50699 started
2024-07-22 06:24:11,579 xinference.model.image.core 312280 WARNING Cannot find builtin image model spec: stable-diffusion-inpainting
2024-07-22 06:24:11,579 xinference.model.image.core 312280 WARNING Cannot find builtin image model spec: stable-diffusion-2-inpainting
2024-07-22 06:24:11,641 xinference.core.worker 312280 INFO Starting metrics export server at 0.0.0.0:None
2024-07-22 06:24:11,644 xinference.core.worker 312280 INFO Checking metrics export server...
2024-07-22 06:24:13,027 xinference.core.worker 312280 INFO Metrics server is started at: http://0.0.0.0:35249
2024-07-22 06:24:13,029 xinference.core.worker 312280 INFO Xinference worker 0.0.0.0:50699 started
2024-07-22 06:24:13,030 xinference.core.worker 312280 INFO Purge cache directory: /root/.xinference/cache
2024-07-22 06:24:18,087 xinference.api.restful_api 311974 INFO Starting Xinference at endpoint: http://0.0.0.0:9997
2024-07-22 06:24:18,535 uvicorn.error 311974 INFO Uvicorn running on http://0.0.0.0:9997 (Press CTRL+C to quit)
注意:
Xinference默认使用<HOME>/.xinference作为主目录存储一些必要信息,如:日志文件和模型文件
通过配置环境变量XINFERENCE_HOME修改主目录, 比如:XINFERENCE_HOME=/tmp/xinference xinference-local --host 0.0.0.0 --port 9997
查看存储信息
(xinference) root@master:~# ls .xinference/
cache logs
(xinference) root@master:~# ls .xinference/cache/
chatglm3-pytorch-6b
(xinference) root@master:~# ls .xinference/logs/
local_1721628924181 local_1721629451488 local_1721697225558 local_1721698858667
通过访问http://localhost:9777地址来使用Web GUI界面
通过访问http://localhost:9997/docs来查看 API 文档。
4、模型部署
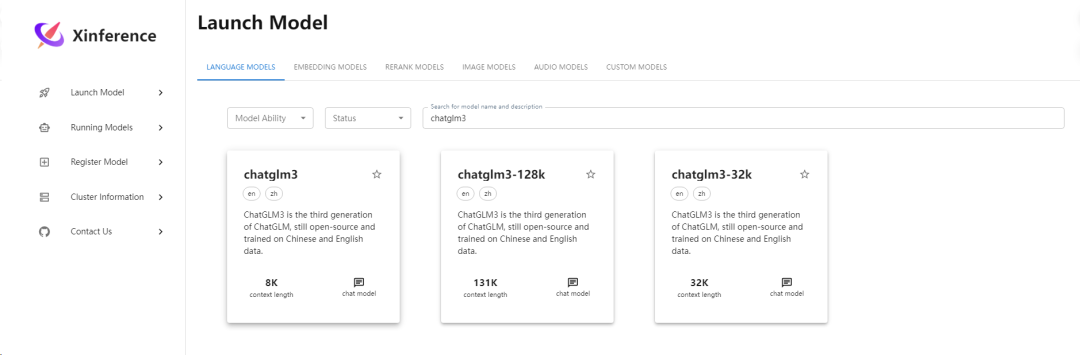
(1)搜索选择模型
点击
Launch Model菜单,选择LANGUAGE MODELS标签,输入关键词以搜索需要部署的模型。这里以搜索ChatGLM3 模型为例。
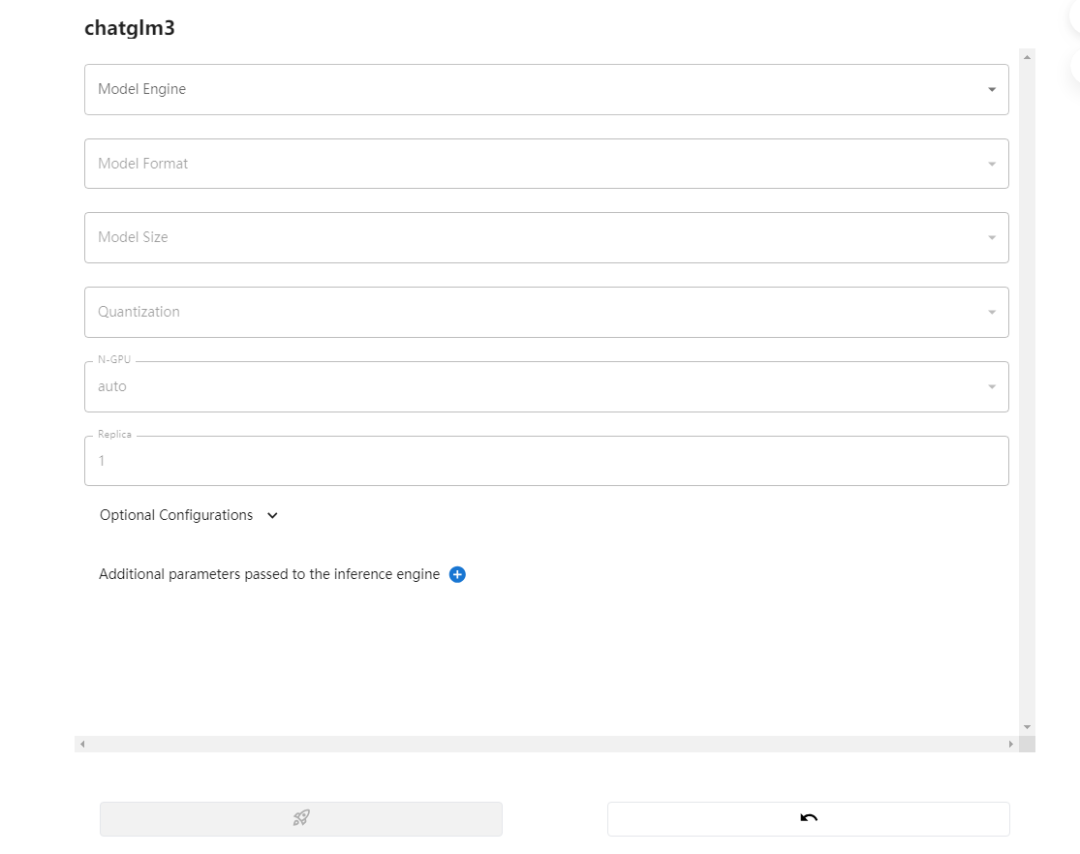
(2)模型参数配置
模型的具体参数配置参考下文:模型参数配置说明
(3)开始部署模型
模型参数填写完成后,点击卡片左下方的火箭图标按钮开始部署模型

后台根据配置参数下载量化或非量化LLM模型

注意:
当运行一个模型时,第一次运行是要从默认或指定的模型站点下载模型参数。当下载完成后,Xinference本地会有缓存的处理,以后再运行相同的模型不需要重新下载。
(4)已部署模型列表
部署完成后,界面自动跳转到Running Models菜单,在LANGUAGE MODELS标签中,可以看到部署好的模型。

(5)LLM模型对话
点击Launch Web UI图标,自动打开LLM模型的Web界面,可以直接与LLM模型进行对话
进行对话测试:
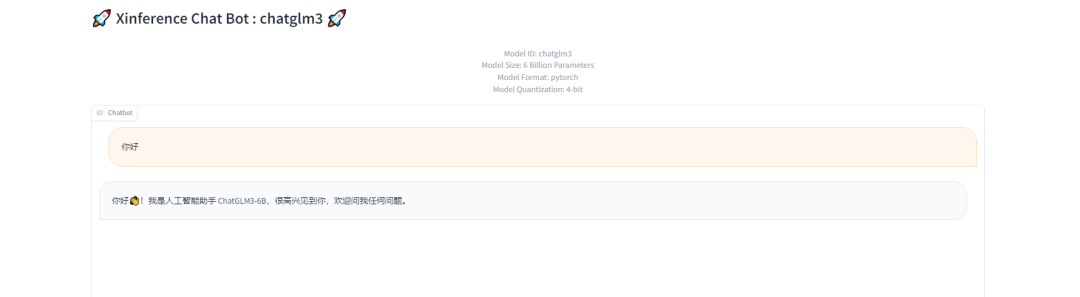
注意:当时在进行对话测试时出现了异常,参考下文异常中的异常3
5、模型参数配置说明
在部署LLM模型时,有以下参数可供选择:
(1)必选配置:
Model Engine:模型推理引擎,根据模型不同,可能支持的引擎不同
Model Format: 模型格式,可以选择量化(ggml、gptq等)和非量化(pytorch)的格式
Model Size:模型的参数量大小,不同模型参数量不同,可能是: 6B、7B、13B、70B等
Quantization:量化精度,有4bit、8bit等量化精度选择
N-GPU:模型使用的GPU数量:可选择Auto、CPU、GPU数量,默认Auto
Replica:模型的副本,默认为1
点击chatglm3卡片,填写部署模型的相关信息

(2)可选配置:
Model UID: 模型的UID,可理解为模型自定义名称,默认用原始模型名称
Request Limits: 模型的请求限制数量,默认为None。None表示此模型没有限制
Worker Ip: 指定分布式场景中模型所在的工作器ip
Gpu Idx: 指定模型所在的GPU索引
Download hub: 模型从哪里下载,可选:none、huggingface、modelscope

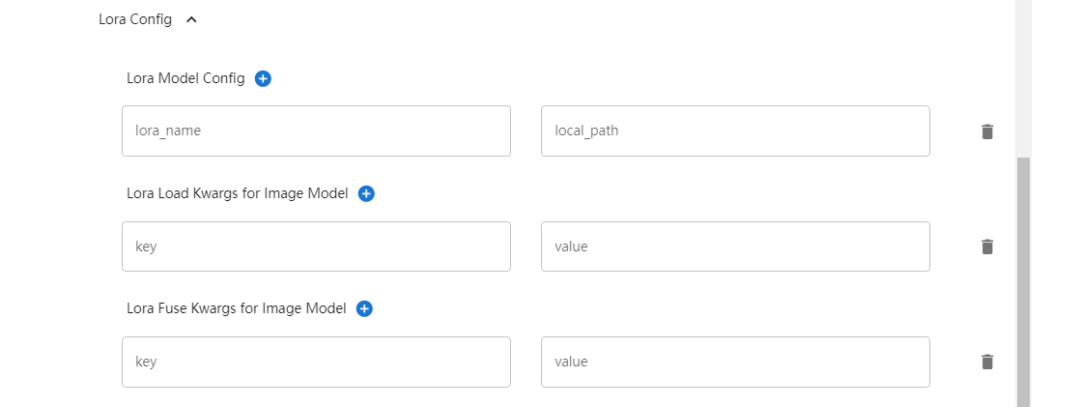
(3)Lora配置:
Lora Model Config:PEFT(参数高效微调)模型和路径的列表
Lora Load Kwargs for Image Model:图像模型的 lora 加载参数字典
Lora Fuse Kwargs for Image Model:图像模型的 lora fuse 参数字典
(4)传递给推理引擎的其他参数:

如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方优快云官方认证二维码,免费领取【
保证100%免费】

如有侵权,请联系删除


















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









