






文章目录
LangGraph 开发指南
LangGraph 概述:设计哲学与技术背景
LangGraph 是一个用于构建有状态和多角色的LLM Apps 的开源库,常用于 创建单代理和多代理的工作流。
与其他LLM 框架相比,LangGraph 具备以下核心优势和特性:
• 循环与分支:允许实现循环和条件逻辑,适用于大多数代理架构,区别于以
有向无环图(DAG)为基础的解决方案。
• 持久化:内置自动状态保存功能,支持在任何时刻暂停和恢复执行,便于错 误恢复、人类参与、时光回溯等复杂工作流。
• 人类参与:在执行过程中可以中断,允许人类审核或编辑下一步操作,支持
• 流处理支持:在每个节点生成输出时支持流式传输,包括token 级别的实 时流输出。
• 可控性:提供对应用流程和状态的精细控制,确保代理的可靠性和灵活性。
• 与LangChain 集成:LangGraph 可无缝集成LangChain 和LangSmith,
但也可以独立使用。
LangGraph 受到Pregel 和Apache Beam 的启发,公共接口参考了 NetworkX。
Pregel 简介
Pregel 是由 Google 开发的一个大规模图处理框架,专为分布式计算环境设计,能够高效处理图结构数据。
应用场景: 大规模图计算,如社交网络分析、Web 搜索算法。
核心特点:
• “顶点-驱动” 模型:每个顶点负责自己的状态和邻居通信。
• 迭代式计算:采用超级步(Superstep)机制,顶点在每次迭代中处理邻居的消息,直到算法完成。
• 容错能力:支持分布式计算中的错误恢复。
LangGraph 借鉴之处:
• 迭代式计算模型:LangGraph 采用类似 Pregel 的循环机制,支持在流程中定义循环、迭代和回调操作。通过超级步(superstep)的概念,LangGraph 可以在每个步骤中保存状态,并允许执行多个迭代。
• 并行性与分布式计算支持:Pregel 的顶点驱动模型启发了 LangGraph 在处理多代理和多节点流程时的并行能力。
Apache Beam 简介
Apache Beam 是一个统一的批处理和流处理框架,提供简洁一致的API 来构建复杂的数据处理管道。
应用场景:流数据处理、批处理任务,如实时数据分析、日志处理等。
核心特点:
• 统一模型:一次性编写管道,能够在不同的执行引擎上运行,如Apache Flink、Google Cloud Dataflow 等。
• 支持批处理和流处理:同一模型下处理静态数据集和实时数据流。
• 扩展性:具有良好的扩展性和灵活性,适合大规模数据处理。
LangGraph 借鉴之处:
• 统一的批处理和流处理模型:LangGraph 参考了Apache Beam 的设计,支持处理连续的、流式的输出。尤其在 流数据处理(如实时生成token 流)方面,LangGraph 借鉴了Beam 的强大处理能力。
• 错误恢复与持久化:Apache Beam 支持在管道中的各个步骤保存状态,LangGraph 在这个基础上集成了持久化能 力,支持工作流的暂停、恢复和错误处理。
NetworkX 简介
NetworkX 是一个用于创建、操作和分析图结构数据的Python 库,专注于图论算法的实现和图结构的可视化。
应用场景:图论算法、网络分析、社交网络建模。
核心特点:
• 易于使用:提供简洁的Python API,支持图创建、图操作以及各种图算法的执行(如最短路径、图遍历等)。 • 支持多种图类型:有向图、无向图、加权图等。
• 广泛应用:用于社交网络分析、知识图谱、交通网络建模等场景。
LangGraph 借鉴之处:
• 图结构工作流设计:LangGraph 采用了类似NetworkX 的接口和图结构,帮助用户以图的方式设计工作流。每个 节点可以定义状态、操作,且支持分支、条件、循环等复杂控制结构。
• 灵活的控制机制:通过借鉴NetworkX 的灵活图操作,LangGraph 允许对每个步骤进行精确控制,实现不同的多 代理任务。

深入学习的参考资料
Pregel
• 官方论文:https://research.google/pubs/pregel-a-system-for-large-scale-graph-processing/ • JPregel (基于Java 的Pregel 实现):一个基于Java 的Pregel 模型实现,适合通过代码学习。
(https://kowshik.github.io/JPregel/)
• Giraph:一个基于Pregel 模型的开源图处理框架,运行在Hadoop 生态系统中。(https://giraph.apache.org/)
Apache Beam
• 官方文档:https://beam.apache.org/documentation/
• Beam 编程指南:详细介绍如何使用Beam 编程,包括批处理和流处理的场景。 (https://beam.apache.org/documentation/programming-guide/)
• Google Cloud Dataflow 教程:适用于想要在Google Cloud 上使用Apache Beam 的用户。 (https://cloud.google.com/dataflow/docs/quickstarts)
NetworkX
• 官方文档:https://networkx.org/documentation/stable/
• Kaggle 图分析课程:Kaggle 上有很多用NetworkX 进行图分析的实际项目和比赛,适合通过实践学习。 (https://www.kaggle.com/learn/graph-data)
• NetworkX 社交网络分析:分析Twitter、Facebook 等社交网络结构的实际应用,GitHub 上有很多相关的开源项目。 (https://github.com/search?q=networkx)
LangGraph 对象:图(节点、边、状态)的定义与使用
图数据结构概述
图数据结构是计算机科学中一种重要的数据结构,广泛应用于解决各种复杂问题。使用图数据结构有许多好处,尤其 在处理复杂的网络、关联、路径和流程问题时非常有效。
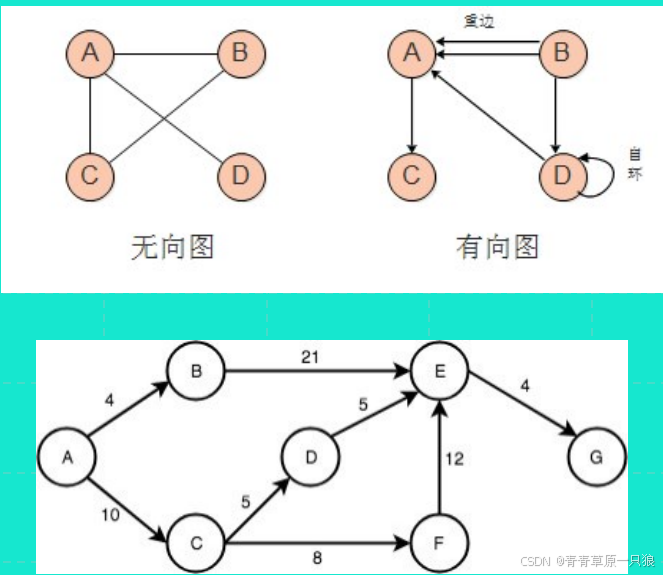
图的基本元素:
- 节点/顶点(Vertex):图中的元素,通常表示对象或数据点。
- 边(Edge):连接节点的线,表示节点之间的关系或交互。
图可以分为以下几种类型:
- 有向图:边有方向性,表示从一个节点指向另一个节点的单向关系。 • 无向图:边无方向性,表示节点之间的双向关系。
- 加权图:边带有权重或值,表示节点之间的距离、成本等额外信息。
典型应用场景:
- 导航系统:城市中的位置和道路可以看作是图,导航系统可以通过计算图上的最短路径来提供最优路线。
- 知识图谱:知识图谱是一种特殊的图结构,能够帮助机器理解不同实体之间的关系,用于问答系统和语义搜索。
- 项目管理:图可以用来表示任务之间的依赖关系,帮助项目经理规划任务执行的先后顺序
图数据结构优点
- 直观表示复杂关系:图结构能够自然地表示物体之间的复杂关系。例如,社交网络中的人际关系、交通网络中的城市和道路、互联网中的网站链接,都可以通过图来建模。
- 高效解决特定问题:许多实际问题可以通过图数据结构高效解决。例如:
- 1.最短路径问题:寻找从一个节点到另一个节点的最短路径(如Google Maps 寻找最快路线)。 • 网络流问题:计算网络中的最大流量(如物流网络中的货物运输优化)。
- 2.连通性问题:判断不同节点之间是否可以互相到达(如检测社交网络中朋友的连通性)。 • 广泛应用于各种领域:图被广泛应用于计算机科学的许多领域:
- 1.社交网络分析:使用图来表示人际关系并分析朋友之间的连接和影响力。
- 2.搜索引擎:通过图表示网页之间的链接关系,决定哪些页面应该出现在搜索结果的前面(如
PageRank 算法)。 - 3.推荐系统:在电商或社交平台中,使用图分析用户和物品之间的关系,为用户推荐可能感兴趣的商品
为什么图数据结构适合LangGraph
理解图数据结构的好处可以帮助我们更好地理解LangGraph 的工作原理和优势:
• 复杂性管理:图结构非常适合表示复杂的工作流,LangGraph 通过使用图数据结构,可以清晰、简
• 循环与条件逻辑:图支持循环和条件分支,LangGraph 可以通过循环边和条件边来实现复杂的代理
• 动态扩展:图具有动态性,可以不断添加节点和边,LangGraph 也允许开发者根据工作流的需要动
态调整任务步骤或添加新的逻辑分支。
LangGraph 通过使用节点和边构建复杂的代理工作流,利用图的灵活性、动态性和并行性来管理任务
的执行和状态的传递。这种设计使得LangGraph 能够高效处理复杂的工作流场景,适用于多种应用
场景,如自动化、数据处理、LLM 应用等。
LangGraph 对象:图(状态、编译、节点、边)
LangGraph 通过图的形式来建模代理工作流。定义代理行为的三大核心组件:
• State(状态):共享的数据结构,代表应用的当前快照。可以是任意Python 类型,但通常为TypedDict 或 Pydantic BaseModel。
• Nodes(节点):执行逻辑的Python 函数,接收当前状态作为输入,执行实际的计算,逻辑操作或副作用(side effect),并返回更新后的状态。节点可以包含LLM(大语言模型)或简单的Python 代码。
• Edges(边):决定下一个要执行的节点的函数,可以是固定的,也可以是基于条件的动态决策。
简单来说:节点干活,边决定接下来做什么。通过组合节点和边,LangGraph 可以创建复杂的循环工作流
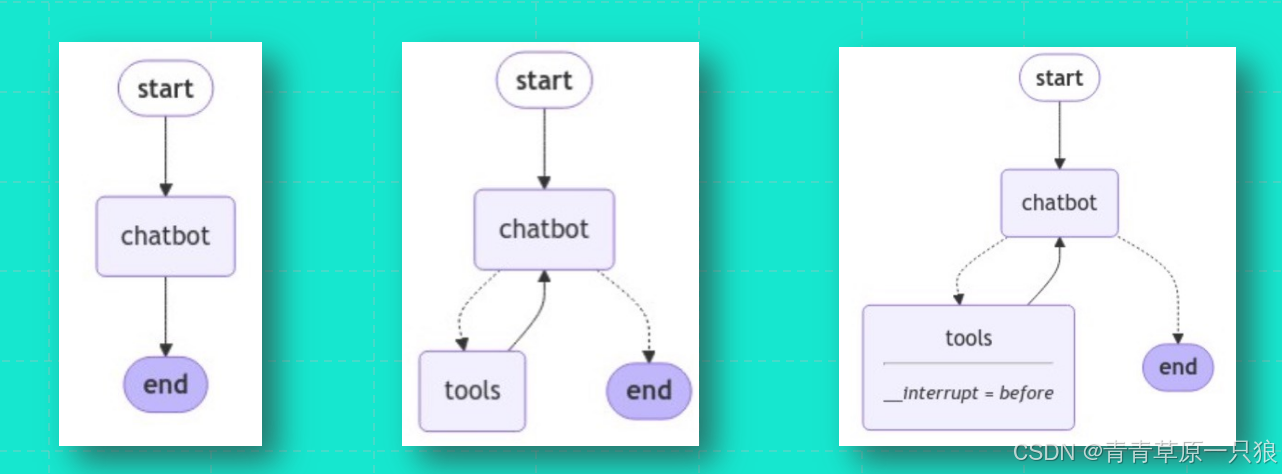
节点(Node)
节点通常是Python 函数(同步或异步),它们负责执行实际的逻辑操作。
• 节点接收State(状态)作为第一个参数,第二个可选 参数为config,其中包含 可配置的参数(例如
thread_id)。
• 节点的作用:执行代理的核心逻辑。
• 节点定义:通过add_node方法将函数添加到图中,未 指定名称的节点将默认使用函数名作为节点名
class State(TypedDict):
# Messages have the type "list". The `add_messages` function
# in the annotation defines how this state key should be updated
# (in this case, it appends messages to the list, rather than overwriting them)
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
边(Edges)
定义了节点之间的逻辑路线,并决定图的执行顺序。它们是代理如何执行工作流的关键部分,并决定了不同节点之间的 通信方式。
• 普通边:直接从一个节点到另一个节点,无需复杂的逻辑判断。
• 条件边:基于当前状态调用函数,决定下一步执行哪个节点。可以根据返回的值动态选择要执行的节点。
• 入口节点(Entry Point):当用户输入到达时,首先执行的节点。
• 多条边:一个节点可以有多个输出边,所有这些目标节点将在同一超级步骤中并行执行。
'''
@Project :langgraph_study
@File :chat002.py
@IDE :PyCharm
@Author :xzy
@Date :2024/10/26 17:19
@explain:
'''
from langchain_community.tools.tavily_search import TavilySearchResults
import os
if not os.environ.get("TAVILY_API_KEY"):
os.environ["TAVILY_API_KEY"] = "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"
tool = TavilySearchResults(max_results=2)
tools = [tool]
# print(tool.invoke("What's a 'node' in LangGraph?"))
from typing import Annotated
from langchain_openai import ChatOpenAI
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
llm = ChatOpenAI(model="qwen2.5-instruct", temperature=0.7, max_tokens=1024,base_url="http://fushi.menglangpoem.cn:8099/v1", api_key="EMPTY")
# Modification: tell the LLM which tools it can call
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
import json
from langchain_core.messages import ToolMessage
class BasicToolNode:
"""A node that runs the tools requested in the last AIMessage."""
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
tool_node = BasicToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
from typing import Literal
def route_tools(
state: State,
):
"""
Use in the conditional_edge to route to the ToolNode if the last message
has tool calls. Otherwise, route to the end.
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
# The `tools_condition` function returns "tools" if the chatbot asks to use a tool, and "END" if
# it is fine directly responding. This conditional routing defines the main agent loop.
graph_builder.add_conditional_edges(
"chatbot",
route_tools,
# The following dictionary lets you tell the graph to interpret the condition's outputs as a specific node
# It defaults to the identity function, but if you
# want to use a node named something else apart from "tools",
# You can update the value of the dictionary to something else
# e.g., "tools": "my_tools"
{"tools": "tools", END: END},
)
# Any time a tool is called, we return to the chatbot to decide the next step
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
# from IPython.display import Image, display
#
# try:
# # 保存为文件并显示
# image_data = graph.get_graph().draw_mermaid_png()
# with open("graph_image11.png", "wb") as f:
# f.write(image_data)
# display(Image("graph_image.png"))
# except Exception:
# pass
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
# fallback if input() is not available
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
具体文档详见官方文档:LangGraph
代码层面的快速入门
如何给当前state中的属性赋值参见下面的代码
class State(TypedDict):
# Messages have the type "list". The `add_messages` function
# in the annotation defines how this state key should be updated
# (in this case, it appends messages to the list, rather than overwriting them)
messages: Annotated[list, add_messages]
data:[]
graph_builder = StateGraph(State)
def f1(state:State):
return {"messages":[HumanMessage(content="我是用户提出的问题")]}
def f2(state:State):
return {
"messages": [SystemMessage(content="你是一位资深的智能问答助手")],
"data": [1, 2, 3, 4, 5]
}
def f3(state:State):
print(state["messages"])
messagess = state["messages"]
for message in messagess:
if isinstance(message, HumanMessage): # 检查是否是HumanMessage
print(message.content) # 打印出HumanMessage中的content
print(state["data"])
return {"messages":[AIMessage(content="我已经回答了你的问题")]}
graph_builder.add_node("f1",f1)
graph_builder.add_node("f2",f2)
graph_builder.add_node("f3",f3)
graph_builder.add_edge(START,"f1")
graph_builder.add_edge("f1","f2")
graph_builder.add_edge("f2","f3")
graph_builder.add_edge("f3",END)
graph = graph_builder.compile()
for chunk in graph.stream({"messages": []}):
# Print out all events aside from the final end chunk
if END not in chunk:
print(chunk)
print("----")
输出如下
D:\apply_soft\Anaconda3\envs\langgraph_study\python.exe D:\Code\Code_pycharm\langgraph_study\kaifa\testMessage.py
{'f1': {'messages': [HumanMessage(content='我是用户提出的问题', additional_kwargs={}, response_metadata={}, id='f1933f61-32eb-4a48-ae92-b8e5ce10659e')]}}
----
{'f2': {'messages': [SystemMessage(content='你是一位资深的智能问答助手', additional_kwargs={}, response_metadata={}, id='2a2992eb-b515-464e-aad3-941580412e78')], 'data': [1, 2, 3, 4, 5]}}
----
[HumanMessage(content='我是用户提出的问题', additional_kwargs={}, response_metadata={}, id='f1933f61-32eb-4a48-ae92-b8e5ce10659e'), SystemMessage(content='你是一位资深的智能问答助手', additional_kwargs={}, response_metadata={}, id='2a2992eb-b515-464e-aad3-941580412e78')]
我是用户提出的问题
[1, 2, 3, 4, 5]
{'f3': {'messages': [AIMessage(content='我已经回答了你的问题', additional_kwargs={}, response_metadata={}, id='b3c81687-3bd2-45cb-bbb5-06ba8de475f6')]}}
----
Process finished with exit code 0
如何定义条件边,详见下面代码
# Define the function that determines whether to continue or not
def should_continue(state: State) -> Literal["end", "continue"]:
messages = state["messages"]
last_message = messages[-1]
# If there is no tool call, then we finish
if not last_message.tool_calls:
return "end"
# Otherwise if there is, we continue
else:
return "continue"
"""
Literal 是 Python 3.8 引入的类型提示工具,它允许你指定一个变量只能取某些特定的值。在你的代码中,Literal["end", "continue"] 表示 should_continue 函数的返回值只能是 "end" 或 "continue" 这两个字符串之一。
这种类型注解的好处是可以提高代码的可读性和类型安全,帮助开发工具进行静态检查,避免出现不符合预期的值。
"""
# We now add a conditional edge
workflow.add_conditional_edges(
# First, we define the start node. We use `agent`.
# This means these are the edges taken after the `agent` node is called.
"agent",
# Next, we pass in the function that will determine which node is called next.
should_continue,
# Finally we pass in a mapping.
# The keys are strings, and the values are other nodes.
# END is a special node marking that the graph should finish.
# What will happen is we will call `should_continue`, and then the output of that
# will be matched against the keys in this mapping.
# Based on which one it matches, that node will then be called.
{
# If `tools`, then we call the tool node.
"continue": "action",
# Otherwise we finish.
"end": END,
},
)
"""
这段代码的主要目的是在一个 workflow(工作流)中添加条件性边缘,使工作流能够根据特定条件决定接下来的节点。代码逐行的执行逻辑如下:
1.workflow.add_conditional_edges(:调用 workflow 的 add_conditional_edges 方法,来为工作流添加条件分支(即条件性边缘)。该方法的作用是:在工作流中定义某个节点的下一步执行路径,取决于特定条件的结果。
2."agent",:这是起始节点,表示条件性边缘在 agent 节点完成后才会被触发。在工作流中,agent 节点执行完毕后,将调用定义的条件性函数。
3.should_continue,:这是决定下一个节点的函数。这里传入的是 should_continue 函数,它将返回 "continue" 或 "end"。根据这个返回值,工作流会选择相应的下一步节点。
4.{
定义条件性边缘的映射关系,即 should_continue 返回结果和对应的下一步节点之间的映射。
4.1"continue": "action",:映射表中的一项,表示如果 should_continue 返回 "continue",工作流将跳转到 "action" 节点继续执行。
4.2"end": END,:映射表中的另一项,表示如果 should_continue 返回 "end",工作流将跳转到 END 节点,并结束流程。END 是一个特殊节点,表示工作流的终止。
}
"""

















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









