







一、langgraph简介
1、简介
LangGraph 是一个基于LangChain构建的扩展。
LangGraph 是一个用于构建具有状态和多参与者应用程序的 LLM 库,它允许创建具有循环的图,这在大多数智能体架构中是必需的。LangGraph提供了对应用程序流程和状态的细粒度控制,这对于创建可靠的智能体至关重要,并且LangGraph 还内置了包括持久化对话,支持高级的人机交互和记忆功能。
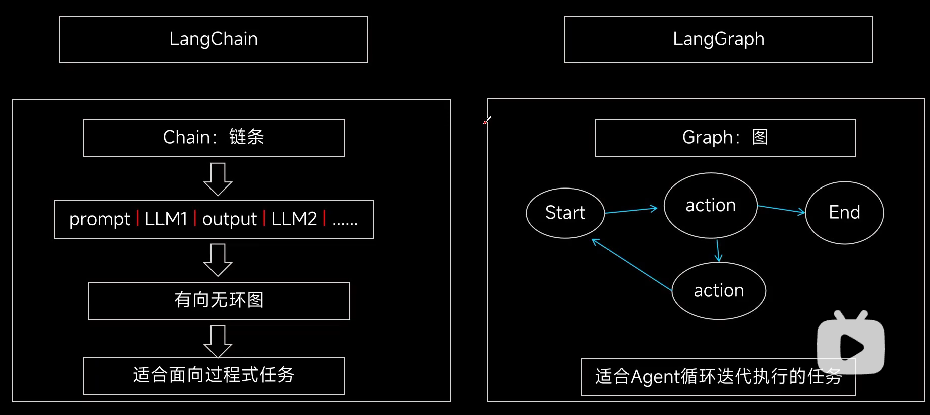
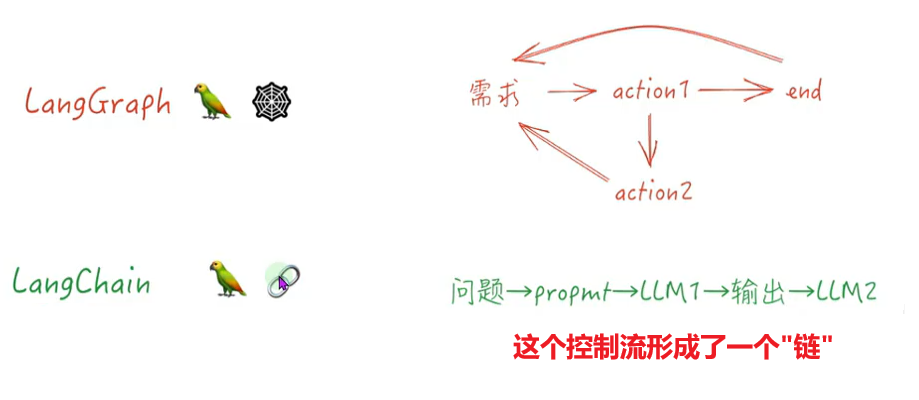
2、框架核心优势
LangGraph是一个专注于构建有状态、多角色应用程序的库,它利用大型语言模型(LLMs)来创建智能体和多智能体工作流。这个框架的核心优势体现在以下几个方面:
- 周期性支持:LangGraph允许开发者定义包含循环的流程,这对于大多数中智能体架构来说至关重要。这种能力使得LangGraph与基于有向无环图(DAG)的解决方案区分开来,因为它能够处理需要重复步骤或反馈循环的复杂任务。
- 高度可控性:LangGraph提供了对应用程序流程和状态的精细控制。这种精细控制对于创建行为可靠、符合预期的智能体至关重要,特别是在处理复杂或敏感的应用场景时。
- 持久性功能:LangGraph内置了持久性功能,这意味着智能体能够跨交互保持上下文和记忆。这对于实现长期任务的一致性和连续性非常关键。持久性还支持高级的人机交互,允许人类输入无缝集成到工作流程中,并使智能体能够通过记忆功能学习和适应。
3、特点
+ 1. Cycles and Branching(循环和分支)
功能描述:允许在应用程序中实现循环和条件语句。
应用场景:适用于需要重复执行任务或根据不同条件执行不同操作的场景,如自动化决策流程、复杂业务逻辑处理等。
+ 2. Persistence(持久性)
功能描述:自动在每个步骤后保存状态,可以在任何点暂停和恢复Graph执行,以支持错误恢复等。
应用场景:对于需要中断和恢复的长时任务非常有用,例如数据分析任务、需要人工审核的流程等。
+ 3. Human-in-the-Loop(人工支持)
功能描述:允许中断Graph的执行,以便人工批准或编辑Agent计划的下一步操作。
应用场景:在需要人工监督和干预的场合,如敏感操作审批、复杂决策支持等。
+ 4. Streaming Support(流支持)
功能描述:支持在节点产生输出时实时流输出(包括Token流)。
应用场景:适用于需要实时数据处理和反馈的场景,如实时数据分析、在线聊天机器人等。
+ 5. Integration with LangChain and LangSmith(与LangChain和LangSmith集成)
功能描述:LangGraph可以与LangChain和LangSmith无缝集成,但并不强制要求它们。
应用场景:增强LangChain和LangSmith的功能,提供更灵活的应用构建方式,特别是在需要复杂流程控制和状态管理的场合。
4、⭐Graph三大组件
LangGraph是基于 LangChain 构建并旨在与之配合使用。它扩展了 LangChain 表达式语言,使其能够以循环方式协调多个链(或参与者)在多个计算步骤中。
LangGraph 以 LangChain 为核心,以图的方式来构建大模型应用。
图(Graph)是数学中的一个基本概念,它由点集合及连接这些点的边集合组成。图主要用于模拟各种实体之间的关系,如网络结构、社会关系、信息流等。以下是图的基本组成部分:
+ 节点(Vertex):图中的基本单元,通常用来表示实体。在社交网络中,每个顶点可能代表一个人;在交通网络中,每个顶点可能代表一个城市或一个交通枢纽。
+ 边(Edge):连接两个顶点的线,表示顶点之间的关系或连接。边可以有方向(称为有向图),也可以没有方向(称为无向图)。
+ 权重(Weight):有时边会被赋予一个数值,称为权重,表示两个顶点之间关系的强度或某种度量,如距离、容量、成本等。
⭐Graph三大组件:状态、节点、边

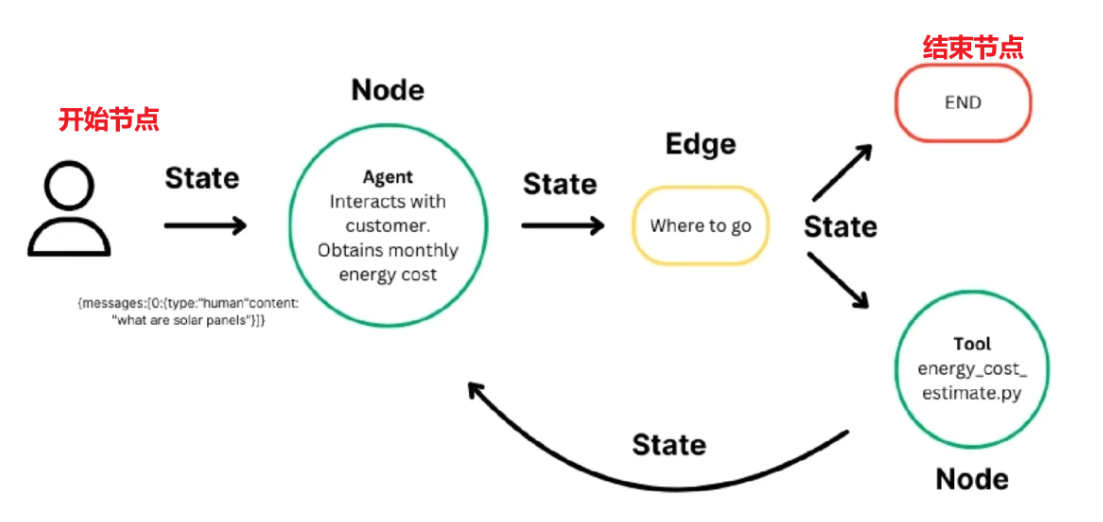
二、Gragh代码实现
把langgraph理解成一个工作流
基本类型的Graph
#安装依赖
pip install langgraph -i https://pypi.tuna.tsinghua.edu.cn/simple0、一般流程
- (1)初始化模型和工具
- (2)用状态初始化图
- (3)定义图中的节点
- (4)定义入口节点、边、终点
- (5)编译图
- (6)执行图
1、最简单的图
StateGraph是LangGraph主要使用的一个类,这是由用户定义的State对象参数化的,它由用户定义的状态对象参数化。
from langgraph.graph import StateGraph,START,END
#定义一个节点函数,接收状态,返回新的状态
def my_node(state):
return {"x":state['x']+1,"y":state["y"]+2}
#创建一个状态图
builder = StateGraph(dict)
#创建节点
builder.add_node('node1',my_node)
#创建边
builder.add_edge(START,'node1')
builder.add_edge("node1",END)
#编译图
graph =builder.compile()
#执行图
print(graph.invoke({"x":1,"y":2}))'''
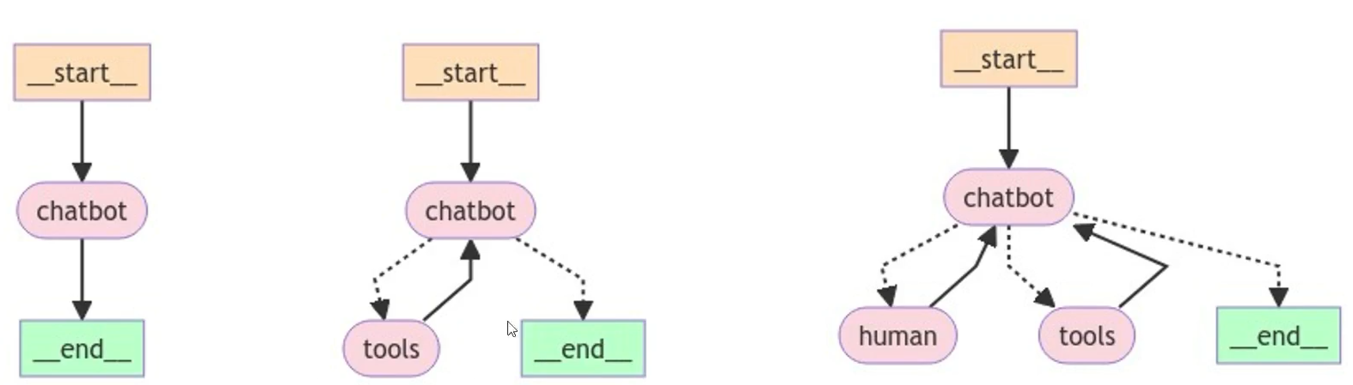
1.创建保存图的状态的字典
2.创建智能体
3.创建带状态的图
4.添加节点 节点和智能体绑定
5.编译图
6.使用:通过图执行智能体和管理 invoke
'''
from langgraph.graph import StateGraph,START,END
from typing_extensions import TypedDict
# 1.创建保存图的状态的字典
class State(TypedDict):
foo:int
# 2.创建智能体
def agent_01(state):
return {"foo":state['foo'] + 1}
# 3.创建带状态的图
_builder = StateGraph(State)
# 4.添加节点 节点和智能体绑定
_builder.add_node("node_01",agent_01)
_builder.add_edge(START,"node_01")
_builder.add_edge("node_01",END)
# 5.编译图
_graph = _builder.compile()
# 6.使用:通过图执行智能体和管理 invoke
_r = _graph.invoke({"foo":10})
print(_r)
# 保存图
# from IPython.display import Image,display
# display(Image(_graph.get_graph().draw_mermaid_png(output_file_path="graph.png"))) # 显示图像
_graph.get_graph().draw_mermaid_png(output_file_path="./output/graph.png")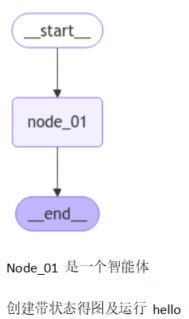
2、条件边
'''
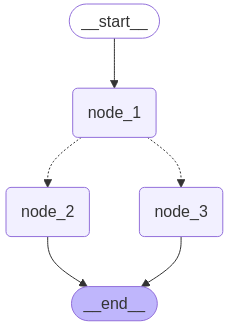
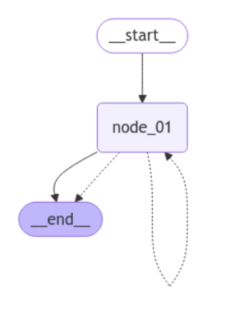
条件边的使用
1.创建保存图的状态的字典
2.创建智能体
3.创建条件智能体
4.创建带状态的图
5.创建节点 节点和智能体绑定
6.添加边和条件边
7.编译图
8.使用:通过图执行智能体和管理 invoke
'''
from langgraph.graph import StateGraph,START,END
from typing_extensions import TypedDict
# 1.创建保存图的状态的字典
class State(TypedDict):
foo:int
# 2.创建智能体
def agent_01(state):
r= {"foo":state['foo'] + 1}
print(r)
return r
# 3.定义条件(路由函数)
def cond_adge(state):
if(state['foo']>10):
return END
else:
return "node_01"
# 4.创建带状态的图
_builder = StateGraph(State)
# 5.创建节点 节点和智能体绑定
_builder.add_node("node_01",agent_01)
_builder.add_edge(START,"node_01")
# 6.添加条件边
_builder.add_conditional_edges("node_01",cond_adge,["node_01",END])
_builder.add_edge("node_01",END)
# 7.编译图
_graph = _builder.compile()
# 8.使用:通过图执行智能体和管理 invoke
_r = _graph.invoke({"foo":10})
print(_r)
# from IPython.display import Image,display
# display(Image(_graph.get_graph().draw_mermaid_png(output_file_path="1111.png")))
_graph.get_graph().draw_mermaid_png(output_file_path="./output/con_edge.png")
3、消息的追加(规约)
消息操作两种:覆盖、追加
追加消息:场景大模型是需要历史的消息进行推理
'''
状态信息追加
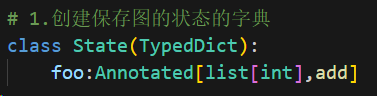
1.创建保存图的状态的字典 foo:Annotated[list[int],add]
2.创建智能体
3.创建带状态的图
4.添加节点 节点和智能体绑定
5.编译图
6.使用:通过图执行智能体和管理 invoke _graph.invoke({"foo":[10]})
'''
from langgraph.graph import StateGraph,START,END
from typing_extensions import TypedDict
from typing import Annotated
from operator import add
# 1.创建保存图的状态的字典
class State(TypedDict):
foo:Annotated[list[int],add]
# 2.创建智能体
def agent_01(state):
return {"foo":[state['foo'][0] + 1]}
# 3.创建带状态的图
_builder = StateGraph(State)
# 4.添加节点 节点和智能体绑定
_builder.add_node("node_01",agent_01)
_builder.add_edge(START,"node_01")
_builder.add_edge("node_01",END)
# 5.编译图
_graph = _builder.compile()
# 6.使用:通过图执行智能体和管理 invoke
_r = _graph.invoke({"foo":[10]})
print(_r)
# from IPython.display import Image,display
# display(Image(_graph.get_graph().draw_mermaid_png(output_file_path="state_app.png")))
_graph.get_graph().draw_mermaid_png(output_file_path="state_app.png")# 更新图状态数据格式
from langgraph.graph import StateGraph,START,END
from typing_extensions import TypedDict,List,Dict,Any
from typing import Annotated
from operator import add
# 创建保存图状态的字典
class State(TypedDict):
foo:int
bar:List[str]
# 状态更新函数
def update_state(current_state:State,updates:Dict[str,Any]):
# 创建一个新的状态字典
new_state = current_state.copy()
# 更新状态字典的值
new_state.update(updates)
return new_state
# 初始状态
state:State = {'foo':1,'bar':['hello']}
print(state) # {'foo': 1, 'bar': ['hello']}
# 第一个节点返回的更新
update_foo = {'foo':2}
state = update_state(state,update_foo)
print(state) # {'foo': 2, 'bar': ['hello']}
#第二个节点返回的更新
update_bar = {'bar':['bye']}
state = update_state(state,update_bar)
print(state) # {'foo': 2, 'bar': ['bye']}
# 添加状态值
update_add = {'add':5}
state = update_state(state,update_add)
print(state) # {'foo': 2, 'bar': ['bye'], 'add': 5}4、MessagesState(图中放的state)
messageState会用追加的方式记录历史信息,聊天中需要历史消息

'''
MessageState实现消息追加
1.创建保存图的状态的字典 继承MessageState
2.创建智能体 添加 messages字段的value
3.创建带状态的图
4.创建节点 节点和智能体绑定
5.编译图
6.使用:通过图执行智能体和管理 invoke 测试messages字段的value, 如 {"messages":"hello", "foo":10}
'''
from langgraph.graph.message import MessagesState
from langgraph.graph import StateGraph,START,END
# 1.创建保存图的状态的字典
class State(MessagesState):
foo:int
# 2.创建智能体
def agent_01(state):
return {"messages":"world", "foo":state['foo'] + 1}
# 3.创建带状态的图
_builder = StateGraph(State)
# 4.创建节点 节点和智能体绑定
_builder.add_node("node_01",agent_01)
_builder.add_edge(START,"node_01")
_builder.add_edge("node_01",END)
# 5.编译图
_graph = _builder.compile()
# 6.使用:通过图执行智能体和管理 invoke
_r = _graph.invoke({"messages":"hello", "foo":10})
print(_r)
# from IPython.display import Image,display
# display(Image(_graph.get_graph().draw_mermaid_png(output_file_path="1111.png")))
_graph.get_graph().draw_mermaid_png(output_file_path="output/msg_state.png")5、子图
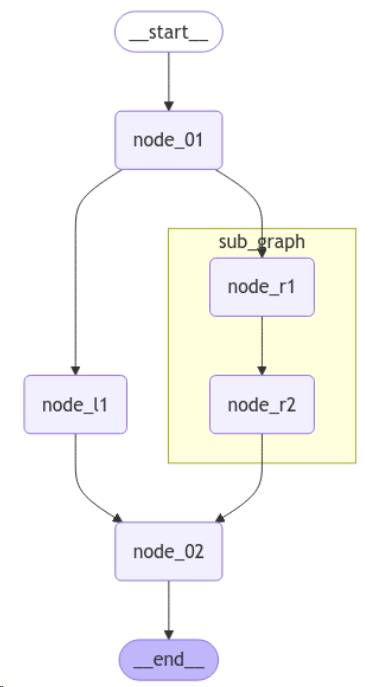
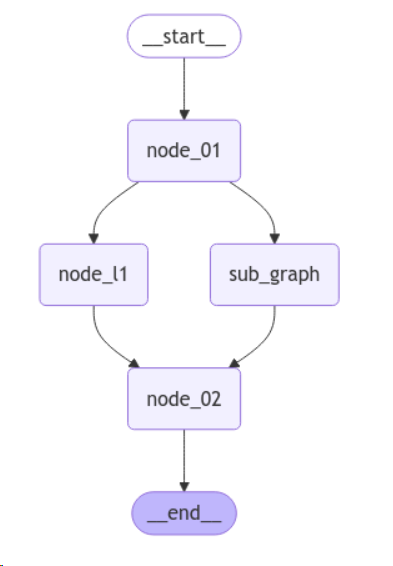
图中节点为另一个图(编译后的子图作为主图的节点)
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph,START,END
from operator import add
"""
子图--图包含图
1.创建带子图的状态class 属性foo 规约
2.创建5个智能体代理 01、02、l1、r1、r1
3.构建子图并编译
4.构建主图,追加子图
5.编译生成图和运行
"""
# 1.创建带子图的状态class 属性foo 规约
class State(TypedDict):
foo: Annotated[list[str],add]
# 2.创建5个智能体代理 01、02、l1、r1、r1
def agent_01(state):
return {"foo":["n1"]}
def agent_02(state):
return {"foo": ["n2"]}
def agent_l1(state):
return {"foo": ["l1"]}
def agent_r1(state):
return {"foo": ["r1"]}
def agent_r2(state):
return {"foo": ["r2"]}
# 3.构建子图
_sub_builder = StateGraph(State)
_sub_builder.add_node("node_r1",agent_r1)
_sub_builder.add_node("node_r2",agent_r2)
_sub_builder.add_edge(START,"node_r1")
_sub_builder.add_edge("node_r1","node_r2")
_sub_builder.add_edge("node_r2",END)
# 4.构建主图,追加子图
_builder = StateGraph(State)
_builder.add_node("node_01",agent_01)
_builder.add_node("node_02",agent_02)
_builder.add_node("node_l1",agent_l1)
_builder.add_node("sub_graph",_sub_builder.compile()) # 将编译后的子图设为主图节点
_builder.add_edge(START,"node_01")
_builder.add_edge("node_01","node_l1")
_builder.add_edge("node_01","sub_graph")
_builder.add_edge("sub_graph","node_02")
_builder.add_edge("node_l1","node_02")
_builder.add_edge("node_02",END)
# 5.编译生成图和运行
_graph = _builder.compile()
result = _graph.invoke({"foo":[]})
print(result)
from IPython.display import display,Image
_graph.get_graph().draw_mermaid_png(output_file_path="./output/5.main_graph.png")
_graph.get_graph(xray=1).draw_mermaid_png(output_file_path="./output/5.main_sub_graph.png")6、条件入口点
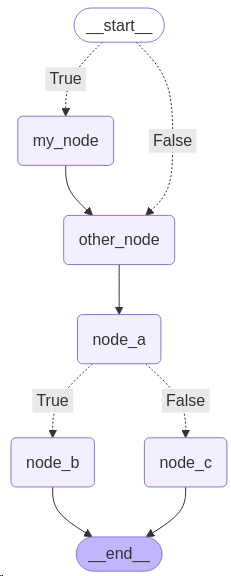
条件⼊⼝点允许您根据⾃定义逻辑从不同的节点开始。您可以从虚拟的START节点使⽤add_conditional_edges来实现这⼀点。
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START, END
# 初始化 StateGraph,状态类型为字典
graph = StateGraph(dict)
# 定义节点
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
def other_node(state: dict):
return state
def node_a(state: dict):
return {"result": "This is node B"}
def node_b(state: dict):
return {"result": "This is node B"}
def node_c(state: dict):
return {"result": "This is node C"}
# 将节点添加到图中
graph.add_node("my_node", my_node)
graph.add_node("other_node", other_node)
graph.add_node("node_a", node_a)
graph.add_node("node_b", node_b)
graph.add_node("node_c", node_c)
# 添加边
#条件入口函数
def routing_my(state: dict):
# 假设我们根据 state 中的某个键值来决定路由
# 如果 state 中有 'route_to_my' 且其值为 True,则路由到 my_node,否则路由到 other_node
return state.get('route_to_my', False)
# 条件入口条件边
graph.add_conditional_edges(START, routing_my,{True: "my_node", False: "other_node"})
# 普通边
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", "node_a")
# 条件边和条件路由函数
def routing_function(state: dict):
# 假设我们根据 state 中的某个键值来决定路由
# 如果 state 中有 'route_to_b' 且其值为 True,则路由到 node_b,否则路由到 node_c
return state.get('route_to_b', False)
#条件边
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"})
# 普通边
graph.add_edge("node_b", END)
graph.add_edge("node_c", END)
# 编译图
app = graph.compile()
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("./output/edges_case.png", "wb") as f:
f.write(graph_png)7、分发(希望节点重复执行多次)
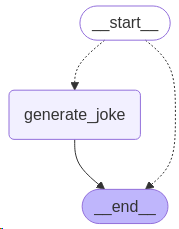
# 导入operator模块,用于后续操作
import operator
from langgraph.graph import StateGraph,START,END
from typing import TypedDict,Annotated
from langgraph.constants import Send
# 定义一个名为OverallState的TypedDict类
class OverallState(TypedDict):
# subjects是一个字符串列表
subjects: list[str]
# jokes是一个带有operator.add注解的字符串列表
jokes: Annotated[list[str], operator.add]
# 创建一个StateGraph对象builder,传入OverallState类型
builder = StateGraph(OverallState)
# 添加一个名为"generate_joke"的节点,节点执行一个lambda函数,生成一个关于主题的笑话
builder.add_node("generate_joke", lambda state: {"jokes": [f"Joke about {state['subject']}"]})
# 定义一个函数continue_to_jokes,接受一个OverallState类型的参数state
def continue_to_jokes(state: OverallState):
# 返回一个Send对象的列表,每个对象包含一个"generate_joke"的命令和对应主题的字典
# Send(node: str, arg: Any) 将arg参数发送给node节点
return [Send("generate_joke", {"subject": s}) for s in state['subjects']]
# 添加一个条件边,从START节点到continue_to_jokes函数返回的节点
builder.add_conditional_edges(START, continue_to_jokes)
# 添加一条边,从"generate_joke"节点到END节点
builder.add_edge("generate_joke", END)
# 编译graph,生成最终的graph对象
graph = builder.compile()
# 调用graph对象,并传入包含两个主题的初始状态,结果是为每个主题生成一个笑话
result = graph.invoke({"subjects": ["cats", "dogs"]})
print(result)
# 将生成的图片保存到文件
graph_png = graph.get_graph().draw_mermaid_png()
with open("./output/send_case.png", "wb") as f:
f.write(graph_png)![]()
8、checkpointer(检查点)保存记忆
LangGraph 具有⼀个内置的持久化层,通过检查点实现。当您将检查点与图形⼀起使⽤时,您可以与该图形的状态进⾏交互。它允许在交互之间进⾏“记忆”。您可以使⽤检查点创建线程并在图形执⾏后保存线程的状态。在重复的⼈类交互(例如对话)的情况下,任何后续消息都可以发送到该检查点,该检查点将保留对其以前消息的记忆。
许多 AI 应⽤程序需要内存来跨多个交互共享上下⽂。在 LangGraph 中,通过 检查点 为任何StateGraph 提供内存。
在创建任何 LangGraph ⼯作流时,您可以通过以下⽅式设置它们以持久保存其状态
- ⼀个 检查点,例如 MemorySaver(短期记忆:内存)、AsyncSqliteSaver(长期记忆:数据库sqlite)
- 在编译图时调⽤ compile(checkpointer=my_checkpointer) 。
当图中增加记忆,调用时必须有cofig信息,config= {'configurable':{'thread_id':'abc123'}} # 配置线程ID
(1)短期记忆MemorySaver
from langgraph.checkpoint.memory import MemorySaver
from langchain_community.chat_models import ChatTongyi
from langchain.schema.messages import HumanMessage,SystemMessage
from langgraph.graph import MessageGraph,MessagesState,START,END
# 使用LangGraph的MemorySaver模块
from langgraph.checkpoint.memory import MemorySaver
API_KEY = 'sk-****** '
chat_model = ChatTongyi(
model='qwen-long',
top_p=0.8,
temperature=0.1,
api_key=API_KEY
)
workflow = StateGraph(state_schema=MessagesState)
# 定义一个函数,用于调用聊天模型
def call_chat_model(state:MessagesState):
response=chat_model.invoke(state['messages'])
return {'messages':response}
workflow.add_node('chat_model',call_chat_model)
workflow.add_edge(START,'chat_model')
workflow.add_edge('chat_model',END)
# 创建一个记忆模块
memory = MemorySaver()
# 编译创建具有记忆模块的工作流
app = workflow.compile(checkpointer=memory)
config1 = {'configurable':{'thread_id':'abc123'}} # 配置线程ID
input_messages = [HumanMessage(content='你好,我是小明')]
# 由于使用了MemorySaver,对话内容会被保留
output= app.invoke({'messages':input_messages},config=config1)
print(output)
print(output['messages'])
print(output['messages'][-1])
# output["messages"]包含所有的历史信息,打印最后一条消息(模型返回的消息)
output["messages"][-1].pretty_print() 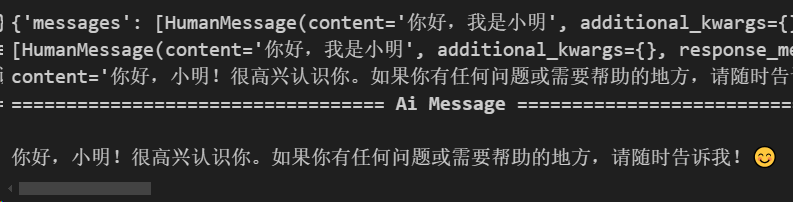
query="我的名字叫什么"
input_messages=[HumanMessage(content=query)]
output=app.invoke({"messages":input_messages},config=config1)
print(output)
output["messages"][-1].pretty_print()
在不同线程下,工作流的记忆功能将不存在
query = "我叫什么名字?"
config2 = {"configurable":{"thread_id":"123456"}}
input_messages = [HumanMessage(content=query)]
output = app.invoke({'messages':input_messages},config=config2)
output['messages'][-1].pretty_print()
(2)长期记忆AsyncSqliteSaver
pip install langgraph.checkpoint.sqlite -i ...
from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver
# 设置 "add_one" 节点为状态图的入口点
builder.set_entry_point("add_one")
# 设置 "add_one" 节点为状态图的结束点
builder.set_finish_point("add_one")
# 导入 asyncio 模块,用于处理异步编程
import asyncio
# 从 langgraph.checkpoint.sqlite.aio 模块中导入 AsyncSqliteSaver 类,它用于异步保存检查点到 SQLite 数据库
# pip install langgraph.checkpoint.sqlite
from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver
# 从 langgraph.graph 模块中导入 StateGraph 类,它用于构建状态图
from langgraph.graph import StateGraph
async def main():
# 创建一个 StateGraph 对象,节点的值类型为 int
builder = StateGraph(int)
# 添加一个名为 "add_one" 的节点,该节点的功能是将输入值加 1
builder.add_node("add_one", lambda x: x + 1)
# 设置 "add_one" 节点为状态图的入口点
builder.set_entry_point("add_one")
# 设置 "add_one" 节点为状态图的结束点
builder.set_finish_point("add_one")
# 使用异步上下文管理器创建一个 AsyncSqliteSaver 对象,并连接到名为 "checkpoints.db" 的 SQLite 数据库
async with AsyncSqliteSaver.from_conn_string("checkpoints.db") as memory:
# 编译状态图,并使用 memory 作为检查点保存器
graph = builder.compile(checkpointer=memory)
# 创建一个异步调用状态图的协程,输入值为 1,并传入额外的配置参数
result = await graph.ainvoke(1, {"configurable": {"thread_id": "thread-1"}})
# 打印结果
print(result)
# 使用 asyncio.run 运行 main() 协程
asyncio.create_task(main())9、消息图
(1)简单的消息图
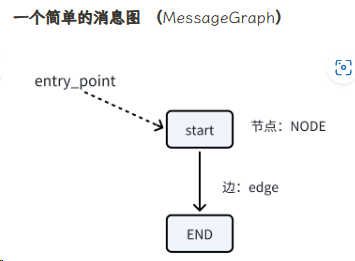
MessageGraph是Graph的一个特例,Graph的State类是一个消息列表,主要用于聊天型Agent。
- 单个模型也可以添加为图中的一个节点
from langchain_community.chat_models import ChatTongyi
from langgraph.graph import MessageGraph,END
from langchain.schema import HumanMessage
API_KEY = 'sk-******'
model = ChatTongyi(model='qwen-long',
top_p=0.8,
temperature=0.1,
api_key=API_KEY)
graph = MessageGraph()
graph.add_node('model_node',model)
graph.set_entry_point('model_node')
graph.add_edge('model_node',END)
app = graph.compile()
res = app.invoke([HumanMessage('一加一等于多少?')])
print(res)
res[-1].pretty_print()(2)不同类型的消息
# 导⼊ AIMessage、HumanMessage 和 ToolMessage 类,⽤于表示不同类型的消息
from langchain_core.messages import AIMessage, HumanMessage, ToolMessage
from langgraph.graph.message import MessageGraph
# 创建⼀个新的 MessageGraph 实例
builder = MessageGraph()
# 向消息图中添加⼀个节点,节点名称为 "chatbot",该节点执⾏的函数接收状态并返回⼀个包含 AI 消息的列表
# AI 消息内容为 "Hello!",并包含⼀个⼯具调⽤,⼯具名称为 "search",ID 为 "123",参数为 {"query": "X"}
builder.add_node(
"chatbot",
lambda state: [
AIMessage(
content="Hello!",
tool_calls=[{"name": "search", "id": "123", "args": {"query":"X"}}]
)
],
)
# 向消息图中添加另⼀个节点,节点名称为 "search",该节点执⾏的函数接收状态并返回⼀个包含⼯具消息的列表
# ⼯具消息内容为 "Searching...",⼯具调⽤ ID 为 "123"
builder.add_node(
"search",
lambda state: [ToolMessage(content="Searching...", tool_call_id="123")]
)
# 设置消息图的⼊⼝点为 "chatbot" 节点
builder.set_entry_point("chatbot")
# 添加⼀条边,从 "chatbot" 节点到 "search" 节点
builder.add_edge("chatbot", "search")
# 设置消息图的结束点为 "search" 节点
builder.set_finish_point("search")
# 编译消息图并调⽤其 invoke ⽅法,传⼊⼀个包含⽤户消息的列表,返回包含所有消息的字典
result = builder.compile().invoke([HumanMessage(content="Hi there. Can you search for X?")])
print(result)(3)自定义工具
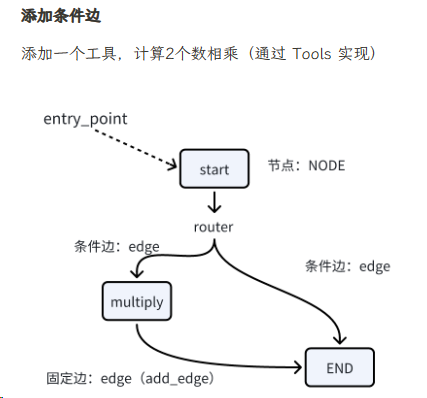
自定义工具的三种方法:【带你 langchain 双排系列教程】7. LangChain自定义工具调用实战指南_langchain 自定义工具-优快云博客
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
from langchain_core.utils.function_calling import convert_to_openai_tool
from langgraph.graph import MessageGraph,END
from typing import List
from langchain_core.messages import BaseMessage,ToolMessage,HumanMessage
import json
# 模型
API_KEY = 'sk-******'
model = ChatTongyi(
model='qwen-long',
top_p=0.8,
temperature=0.1,
api_key=API_KEY
)
# 定义一个乘法工具
@tool
def multiply(first_num: int,second_num: int):
"""计算两个数的乘积"""
return first_num * second_num
# 将工具和模型绑定
model_with_tool = model.bind(tools=[convert_to_openai_tool(multiply)])
# 消息图初始化
graph = MessageGraph()
# 定义入口函数
def invoke_model(state: List[BaseMessage]):
return model_with_tool.invoke(state)
# 定义调用工具节点
def invoke_tool(state:List[BaseMessage]):
tool_calls = state[-1].additional_kwargs.get('tool_calls',[])
multiply_call = None
# 获取调用函数
for tool_call in tool_calls:
if tool_call.get('function').get('name') == 'multiply':
multiply_call = tool_call
if multiply_call is None:
raise Exception('No adder input found.')
# 调用工具,计算两个数的乘积
res = multiply.invoke(
json.loads(multiply_call.get('function').get('arguments'))
)
# 返回工具消息
return ToolMessage(
tool_call_id=multiply_call.get('id'),
content='结果等于'+str(res)
)
# 图中添加节点
graph.add_node("start", invoke_model)
graph.add_node('multiply',invoke_tool)
# 图中加边
graph.set_entry_point('start')
# 定义分支路由函数
def router(state:List[BaseMessage]):
tool_calls = state[-1].additional_kwargs.get('tool_calls',[])
if len(tool_calls):
return 'multiply'
else:
return 'end'
# 增加条件边
graph.add_conditional_edges('start',router,{'multiply':'multiply','end':END})
# 结束边
graph.add_edge('multiply',END)
# 编译图,由图生成一个 runnable
runnable = graph.compile()
res = runnable.invoke(HumanMessage('8乘以4等于多少?'))
print(res)
res = runnable.invoke(HumanMessage('你好吗?'))
print(res)
三、一个简单的应用示例
from langchain_openai import ChatOpenAI
API_KEY = 'sk-******'
model = ChatOpenAI(
model='deepseek-chat',
base_url='https://api.deepseek.com',
api_key=API_KEY
)# Literal 是 typing 模块中的一个特殊类型注解,用于表示某个变量只能是特定的字面值之一。
# Literal 是一种用于限制变量取值的类型注解工具
from typing import Literal
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph,MessagesState,END
from langgraph.checkpoint.memory import MemorySaver
#自定义工具
#定义工具函数,用于大模型调用的外部工具
@tool
def custom_search(query:str):
"""搜索全国各地的天气的工具"""
if '成都' in query.lower() or 'chengdu' in query.lower():
return '现在20度,晴。'
return '现在10度,雨。'
# 将工具函数放入工具列表
tools = [custom_search]
# 创建工具节点
tool_node = ToolNode(tools)
# 模型绑定工具
model = model.bind_tools(tools)
# 定义路由函数,决定执行路径
def should_continue(state: MessagesState) -> Literal['tools',END]:
messages = state['messages']
last_message = messages[-1]
#如果LLM调用了工具,则装到tools节点
if last_message.tool_calls:
return 'tools'
# 否则结束
return END
# 定义调用模型的函数
def call_model(state: MessagesState):
messages = state['messages']
res = model.invoke(messages)
# 返回字典,把LLM的回答内容添加到值列表中
return {'messages':[res]}
# 图初始化/工作流
workflow = StateGraph(MessagesState)
workflow.add_node('agent',call_model)
workflow.add_node('tools',tool_node)
# 定义入口节点
workflow.set_entry_point('agent')
# 添加条件边
workflow.add_conditional_edges('agent',should_continue,['tools',END])
# 若调用tools,调用完tools后,接下来调用 agent节点
workflow.add_edge('tools','agent')
# 创建记忆
memory = MemorySaver()
# 编译图
app = workflow.compile(checkpointer=memory)
# 执行图
msg = {"messages":[HumanMessage(content="成都的天气怎么样?")]}
res = app.invoke(msg,config={"configurable":{"thread_id":123}})
print(res)
print(res['messages'][-1].content)
# 执行图
msg = {"messages":[HumanMessage(content="重庆的天气怎么样?")]}
res = app.invoke(msg,config={"configurable":{"thread_id":123}})
print(res)
print(res['messages'][-1].content)
# 执行图
msg = {"messages":[HumanMessage(content="我刚才问了你什么?")]}
res = app.invoke(msg,config={"configurable":{"thread_id":123}})
print(res)
print(res['messages'][-1].content)
from IPython.display import Image,display
display(Image(app.get_graph(xray=True).draw_mermaid_png()))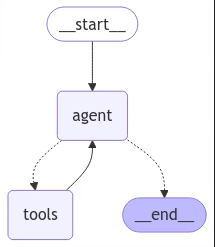

















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









