







文章目录
LangGraph 与 LangChain
LangGraph 并不是一个独立于 LangChain 的新框架,而是在 LLM 和 LangChain 的基础之上构建的一个扩展库,可以于 LangChain 现有的链(Chain)等无缝协作
LangGraph 能够协调多个 Chain、Agent、Tool 等共同协作,实现依赖外部工具、外部数据库且带有反馈的问答任务
环境准备
需要的依赖
pip install -U langgraph langsmith langchain_anthropic
Ollama
Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。可以将其类比为 Docker
- 安装 ollama
- 安装需要的大模型(这里以 Gemma 为例):
ollama run llama3.2:3b - 列出安装好的模型:
ollama list
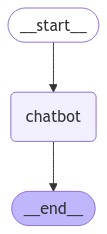
创建一个基础的 Chatbot
基本流程
- 创建一个
StateGraph对象(整个状态图的基础类),将 Chatbot 的结构定义为“状态机”
- 添加
nodes表示 Chatbot 可以调用的 Chain、Agent 或函数 - 添加
edges表示从一个nodes跳转到下一个nodes的关系
- 添加 Chatbot 节点(节点表示工作单元)
- 添加一个
entry节点(入口点),告诉StateGraph每次运行的时候,从哪里开始 - 添加
finish节点(结束节点),当StateGraph运行到该节点,说明本轮结束 - 编译 Graph
- 绘制 Graph 的结构图
- 运行 Graph
完整代码
from typing import Annotated
from langchain_ollama import ChatOllama
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
llm = ChatOllama(model="llama3.2:3b")
# llm = ChatOllama(model="gemma2:2b")
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 chatbot 节点
graph_builder.add_node("chatbot", chatbot)
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile()
# 6. 可视化 graph
try:
graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
# 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
except:
# 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
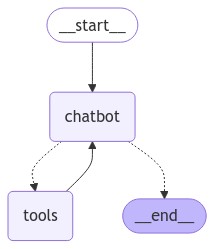
工具调用
Tavily 配置
申请搜索 API
官方接入文档
在.env文件中填写密钥
TAVILY_API_KEY=......
加载.env
load_dotenv(verbose=True)
基本流程
创建工具
# 加载.env文件,获取密钥
load_dotenv(verbose=True)
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
llm 绑定 tools
# 初始化 ChatOllama 对象
llm = ChatOllama(model="llama3.2:3b")
llm_with_tools = llm.bind_tools(tools)
自定义 BasicToolNode
备注:完整会使用 LangGraph 预构建的 ToolNode 进行替换,加快速度
class BasicToolNode:
"""
处理输入消息中的每个工具调用请求,通过查找对应的工具对象并执行它们
然后将结果封装成新的 ToolMessage 对象并返回
"""
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
# 尝试从 inputs 字典中获取 messages 键对应的值
# 如果存在,它将被赋值给变量 messages
# 如果不存在,messages 将默认为一个空列表
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
# 使用 tool_call 中的 name 作为键,从 tools_by_name 字典中获取对应的工具对象
# 并调用它的 invoke 方法,传递 tool_call 中的 args 作为参数,执行工具并获取结果
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
# 将工具调用的结果封装成一个新的 ToolMessage 对象,并添加到 outputs 列表中
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
定义conditional_edges
edges:控制流从一个节点路由到下一个节点conditional edges:通常包含判断逻辑,根据当前图的状态,路由到不同节点
def route_tools(
state: State,
):
"""
在图构建器中添加条件边和普通边
以控制消息处理流程中的路由逻辑
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
# 检查 ai_message 是否包含 tool_calls 属性
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
# 在图构建器中添加条件边
# 这个函数的第一个参数是起始节点 "chatbot"
# 第二个参数是条件函数 route_tools
# 第三个参数是一个字典,它将条件函数的输出映射到特定的节点名称
graph_builder.add_conditional_edges(
"chatbot",
route_tools,
{"tools": "tools", END: END},
)
# 添加一个从 tools 节点到 chatbot 节点的普通边,表示处理完工具调用后返回到聊天机器人节点
graph_builder.add_edge("tools", "chatbot")
# 添加一个从起始节点 START 到 chatbot 节点的普通边
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
完整代码
import json
from typing import Annotated
from dotenv import load_dotenv
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import ToolMessage
from langchain_ollama import ChatOllama
from langgraph.prebuilt import ToolNode, tools_condition
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 加载.env文件,获取密钥
load_dotenv(verbose=True)
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 初始化 ChatOllama 对象
llm = ChatOllama(model="llama3.2:3b")
llm_with_tools = llm.bind_tools(tools)
# llm = ChatOllama(model="gemma2:2b")
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
print("Test:", value)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 node
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 2.1 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# 2.2 添加普通边
# tools 节点调用结束,会又回到 chatbot 节点
graph_builder.add_edge("tools", "chatbot")
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
# graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile()
# 6. 可视化 graph
try:
# graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
graph.get_graph().draw_mermaid_png(output_file_path="graph_with_tools.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
# 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
except:
# 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
给 Chatbot 添加 Memory
当前的 Chatbot 可以使用 tools 回答用户的问题,但是没有记住之前交互的上下文,这限制了进行多轮对话的能力
LangGraph 解决该问题的策略是 persistent checkpointing
- 如果你在编译 graph 的时候提供一个
checkpointer,并在调用 graph 的时候提供一个thread_id,LangGraph 会自主保存每一轮的状态。 - 当你使用相同的
thread_id再次调用该 graph 时,graph 会加载其保存的状态,从而允许 Chatbot 从上次中断的地方继续
创建 checkpointer
from langgraph.checkpoint.memory import MemorySaver
# 创建 checkpointer
memory = MemorySaver()
Note:这里将所有内容保存在内存中,在实际生产应用过程中,可以改为数据库
在编译 graph 的时候,提供 checkpointer
graph = graph_builder.compile(checkpointer=memory)
指定 thread id 并调用
config = {"configurable": {"thread_id": "1"}}
user_input = "Hi there! My name is Will."
# The config is the **second positional argument** to stream() or invoke()!
events = graph.stream(
{"messages": [("user", user_input)]}, config, stream_mode="values"
)
for event in events:
event["messages"][-1].pretty_print()
检查 graph 的状态
# 当前状态值、相应的配置以及下一个要处理的节点
snapshot = graph.get_state(config)
print(snapshot)
完整代码
from typing import Annotated
from dotenv import load_dotenv
from langchain_community.tools import TavilySearchResults
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import ToolNode, tools_condition
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 加载.env文件,获取密钥
load_dotenv(verbose=True)
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 创建 checkpointer
# 这里保存在内存,也可改为数据库
memory = MemorySaver()
# 初始化 ChatOllama 对象
llm = ChatOllama(model="llama3.2:3b")
llm_with_tools = llm.bind_tools(tools)
# llm = ChatOllama(model="gemma2:2b")
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
def stream_graph_updates(user_input: str, config):
for event in graph.stream({"messages": [("user", user_input)]}, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 node
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 2.1 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# 2.2 添加普通边
# tools 节点调用结束,会又回到 chatbot 节点
graph_builder.add_edge("tools", "chatbot")
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
# graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile(checkpointer=memory)
# 6. 可视化 graph
try:
# graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
graph.get_graph().draw_mermaid_png(output_file_path="graph_with_tools.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
# 配置 thread_id
user_config = {"configurable": {"thread_id": "1"}}
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
# 当前状态值、相应的配置以及下一个要处理的节点
snapshot = graph.get_state(user_config)
print(snapshot)
print("Goodbye!")
break
stream_graph_updates(user_input, user_config)
# 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
except:
# 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input, user_config)
break
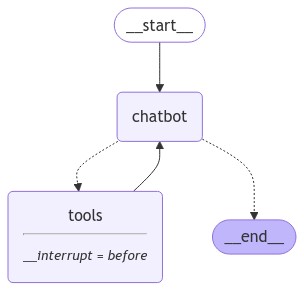
人机交互
背景
- Agents 有时候是不可靠的,需要人类的输入来成功完成任务
- Agents 的有些操作,用户可能需要在运行前得到人工批准
LangGraph 支持多种人机交互的工作流方式
本节使用 LangGraph 的interrupt_before来始终中断工具节点
编译 graph 时指定在调用 tools 节点前进行中断
graph = graph_builder.compile(
checkpointer=memory,
interrupt_before=["tools"]
# Note: can also interrupt __after__ actions, if desired.
# interrupt_after=["tools"]
)
执行测试
def stream_graph_updates(user_input: str, config):
for event in graph.stream({"messages": [("user", user_input)]}, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
def stream_graph_continue(config):
for event in graph.stream(None, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
stream_graph_updates(user_input, user_config)
snapshot = graph.get_state(user_config)
print(snapshot)
print(snapshot.next)
existing_message = snapshot.values["messages"][-1]
print(existing_message.tool_calls)
# 让 graph 继续执行
stream_graph_continue(user_config)
完整代码
from typing import Annotated
from dotenv import load_dotenv
from langchain_community.tools import TavilySearchResults
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import ToolNode, tools_condition
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 加载.env文件,获取密钥
load_dotenv(verbose=True)
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 创建 checkpointer
# 这里保存在内存,也可改为数据库
memory = MemorySaver()
# 初始化 ChatOllama 对象
llm = ChatOllama(model="llama3.2:3b")
llm_with_tools = llm.bind_tools(tools)
# llm = ChatOllama(model="gemma2:2b")
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
def stream_graph_updates(user_input: str, config):
for event in graph.stream({"messages": [("user", user_input)]}, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
def stream_graph_continue(config):
for event in graph.stream(None, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 node
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 2.1 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# 2.2 添加普通边
# tools 节点调用结束,会又回到 chatbot 节点
graph_builder.add_edge("tools", "chatbot")
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
# graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile(
checkpointer=memory,
interrupt_before=["tools"]
# Note: can also interrupt __after__ actions, if desired.
# interrupt_after=["tools"]
)
# 6. 可视化 graph
try:
# graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
graph.get_graph().draw_mermaid_png(output_file_path="graph_with_tools.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
# 配置 thread_id
user_config = {"configurable": {"thread_id": "1"}}
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
# 当前状态值、相应的配置以及下一个要处理的节点
snapshot = graph.get_state(user_config)
print(snapshot)
print("Goodbye!")
break
stream_graph_updates(user_input, user_config)
snapshot = graph.get_state(user_config)
print(snapshot)
print(snapshot.next)
existing_message = snapshot.values["messages"][-1]
print(existing_message.tool_calls)
# 让 graph 继续执行
stream_graph_continue(user_config)
# 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
except:
# 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input, user_config)
break
手动更新状态
背景
上一部分已经实现了中断 graph 并检查当前节点。但如果想要改变 Agent 的执行路线,需要有写入权限
LangGraph 允许手动更新状态,来控制 Agent 的执行轨迹【纠错、探索替代路径、实现特定目标】
在调用 tools 节点前执行中断
def stream_graph_updates(user_input: str, config):
for event in graph.stream({"messages": [("user", user_input)]}, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
stream_graph_updates(user_input, user_config)
snapshot = graph.get_state(user_config)
print(snapshot)
print(snapshot.next)
existing_message = snapshot.values["messages"][-1]
print(existing_message.tool_calls)
问题:User: 现在的美国总统是谁
snapshot.next:('tools',)
工具调用的基本信息:existing_message.tool_calls
[{
'name': 'tavily_search_results_json',
'args': {
'query': 'current president of the United States'
},
'id': 'e9ef940c-d392-4d91-af34-54f243d9429e',
'type': 'tool_call'
}]
- 在工具调用前,就被 graph 打断了
- 接下来我们要让 Agent 不调用 tools,直接提供回应
不调用 tools 直接提供回应
from langchain_core.messages import AIMessage, ToolMessage
answer = (
"LangGraph is a library for building stateful, multi-actor applications with LLMs."
)
new_messages = [
# The LLM API expects some ToolMessage to match its tool call. We'll satisfy that here.
ToolMessage(content=answer, tool_call_id=existing_message.tool_calls[0]["id"]),
# And then directly "put words in the LLM's mouth" by populating its response.
AIMessage(content=answer),
]
new_messages[-1].pretty_print()
graph.update_state(
# Which state to update
config,
# The updated values to provide. The messages in our `State` are "append-only", meaning this will be appended
# to the existing state. We will review how to update existing messages in the next section!
{"messages": new_messages},
)
print("\n\nLast 2 messages;")
print(graph.get_state(config).values["messages"][-2:])
- 自己提供答案,手动更新
- 感觉这种方式很拙劣
自定义状态(节点)
背景
- 上面的部分,当调用 tool 时,graph 总是会中断
- 假设我们的 Chatbot 可以选择依赖人类
- 这就需要我们自定义一个 human 节点
修改 State 类
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
# 新增字段
ask_human: bool
定义 schema
class RequestAssistance(BaseModel):
"""
继承自BaseModel。这意味着RequestAssistance将具有数据验证的功能
如果当前的系统或程序无法直接提供帮助,或者用户需要超出当前系统权限的支持时,应该使用这个类来将对话升级给专家
"""
# 存储需要传递给专家的用户请求
request: str
修改 Chatbot 节点
def chatbot(state: State):
response = llm_with_tools.invoke(state["messages"])
ask_human = False
# 检查 response 对象是否有 tool_calls 属性
# 并且这个属性的第一个元素的 name 键对应的值是否等于 RequestAssistance 类的名称
if (
response.tool_calls
and response.tool_calls[0]["name"] == RequestAssistance.__name__
):
ask_human = True
return {"messages": [response], "ask_human": ask_human}
- 如果 Chatbot 调用了
RequestAssistance,则翻转ask_human标志
添加 human 节点
def create_response(response: str, ai_message: AIMessage):
"""
创建工具调用的响应消息
"""
return ToolMessage(
content=response,
tool_call_id=ai_message.tool_calls[0]["id"],
)
def human_node(state: State):
"""
接收一个State对象作为参数
如果 human 没有提供响应,则添加一个占位的响应消息
"""
new_messages = []
if not isinstance(state["messages"][-1], ToolMessage):
new_messages.append(
create_response("No response from human.", state["messages"][-1])
)
return {
# Append the new messages
"messages": new_messages,
# Unset the flag
"ask_human": False,
}
# 添加 human 节点
graph_builder.add_node("human", human_node)
定义条件逻辑
def select_next_node(state: State):
"""
根据当前state,决定下一个节点
"""
if state["ask_human"]:
return "human"
# Otherwise, we can route as before
return tools_condition(state)
graph_builder.add_conditional_edges(
"chatbot",
select_next_node,
{"human": "human", "tools": "tools", END: END},
)
添加有向边并编译 graph
# The rest is the same
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge("human", "chatbot")
graph_builder.add_edge(START, "chatbot")
memory = MemorySaver()
graph = graph_builder.compile(
checkpointer=memory,
# We interrupt before 'human' here instead.
interrupt_before=["human"],
)
最终 graph 结构
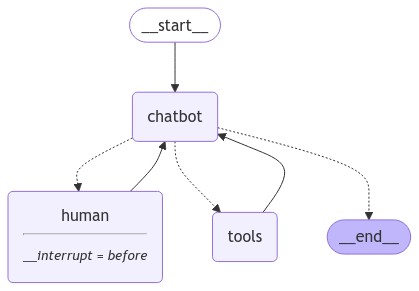
- 可以向 human 节点寻求帮助(chatbot -> select -> human)
- 可以调用搜索引擎工具(chatbot -> select -> action)
- 可以直接响应(chatbot -> select -> end)
完整代码
from typing import Annotated
from dotenv import load_dotenv
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import AIMessage, ToolMessage
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import ToolNode, tools_condition
from pydantic import BaseModel
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 加载.env文件,获取密钥
load_dotenv(verbose=True)
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 创建 checkpointer
# 这里保存在内存,也可改为数据库
memory = MemorySaver()
# 初始化 ChatOllama 对象
llm = ChatOllama(model="llama3.2:3b")
llm_with_tools = llm.bind_tools(tools)
# llm = ChatOllama(model="gemma2:2b")
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
# 新增字段
ask_human: bool
class RequestAssistance(BaseModel):
"""
继承自BaseModel。这意味着RequestAssistance将具有数据验证的功能
如果当前的系统或程序无法直接提供帮助,或者用户需要超出当前系统权限的支持时,应该使用这个类来将对话升级给专家
"""
# 存储需要传递给专家的用户请求
request: str
def chatbot(state: State):
response = llm_with_tools.invoke(state["messages"])
ask_human = False
# 检查 response 对象是否有 tool_calls 属性
# 并且这个属性的第一个元素的 name 键对应的值是否等于 RequestAssistance 类的名称
if (
response.tool_calls
and response.tool_calls[0]["name"] == RequestAssistance.__name__
):
ask_human = True
return {"messages": [response], "ask_human": ask_human}
def create_response(response: str, ai_message: AIMessage):
"""
创建工具调用的响应消息
"""
return ToolMessage(
content=response,
tool_call_id=ai_message.tool_calls[0]["id"],
)
def human_node(state: State):
"""
接收一个State对象作为参数
如果 human 没有提供响应,则添加一个占位的响应消息
"""
new_messages = []
if not isinstance(state["messages"][-1], ToolMessage):
new_messages.append(
create_response("No response from human.", state["messages"][-1])
)
return {
# Append the new messages
"messages": new_messages,
# Unset the flag
"ask_human": False,
}
def select_next_node(state: State):
"""
根据当前state,决定下一个节点
"""
if state["ask_human"]:
return "human"
# Otherwise, we can route as before
return tools_condition(state)
def stream_graph_updates(user_input: str, config):
for event in graph.stream({"messages": [("user", user_input)]}, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
def stream_graph_continue(config):
for event in graph.stream(None, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 node
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 添加 human 节点
graph_builder.add_node("human", human_node)
# 2.1 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
# 条件函数
select_next_node,
# 定义可能的下一个节点
{"human": "human", "tools": "tools", END: END},
)
# graph_builder.add_conditional_edges(
# "chatbot",
# tools_condition,
# )
# 2.2 添加普通边
# tools 节点调用结束,会又回到 chatbot 节点
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge("human", "chatbot")
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
# graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile(
checkpointer=memory,
# interrupt_before=["tools"]
# Note: can also interrupt __after__ actions, if desired.
# interrupt_after=["tools"]
interrupt_before=["human"]
)
# 6. 可视化 graph
try:
# graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
graph.get_graph().draw_mermaid_png(output_file_path="graph_with_human.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
# 配置 thread_id
user_config = {"configurable": {"thread_id": "1"}}
# 模拟用户输入
user_input = "I need some expert guidance for building this AI agent. Could you request assistance for me?"
events = graph.stream(
{"messages": [("user", user_input)]}, user_config, stream_mode="values"
)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
# 当前状态值、相应的配置以及下一个要处理的节点
snapshot = graph.get_state(user_config)
print(snapshot)
print("Goodbye!")
break
stream_graph_updates(user_input, user_config)
snapshot = graph.get_state(user_config)
print(snapshot)
print(snapshot.next)
# existing_message = snapshot.values["messages"][-1]
# print(existing_message.tool_calls)
# # 让 graph 继续执行
# stream_graph_continue(user_config)
# 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
except:
# 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input, user_config)
break
- 节点定义没啥问题
- 但节点的调用好像有点问题,无论什么情况,模型都会走 search,但有时候又不需要他 search
时间旅行:回退
背景
- 希望 Agent 能够回退到历史版本,探索分支
- LangGraph 使用
get_state_history方法获取 checkpoint 进行回退
重播完整的状态历史并记录要恢复的状态
# 模拟用户输入
user_input = "I need some expert guidance for building this AI agent. Could you request assistance for me?"
events = graph.stream(
{"messages": [("user", user_input)]}, user_config, stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
events = graph.stream(
{"messages": [("user", user_input)]}, user_config, stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
# 用于记录要恢复的状态
to_replay = None
for state in graph.get_state_history(user_config):
print("Num Messages: ", len(state.values["messages"]), "Next: ", state.next)
print("-" * 80)
# 后续要恢复的状态
if len(state.values["messages"]) == 6:
# We are somewhat arbitrarily selecting a specific state based on the number of chat messages in the state.
to_replay = state
输出结果:
Num Messages: 8 Next: ()
--------------------------------------------------------------------------------
Num Messages: 7 Next: ('chatbot',)
--------------------------------------------------------------------------------
Num Messages: 6 Next: ('tools',)
--------------------------------------------------------------------------------
Num Messages: 5 Next: ('chatbot',)
--------------------------------------------------------------------------------
Num Messages: 4 Next: ('__start__',)
--------------------------------------------------------------------------------
Num Messages: 4 Next: ()
--------------------------------------------------------------------------------
Num Messages: 3 Next: ('chatbot',)
--------------------------------------------------------------------------------
Num Messages: 2 Next: ('tools',)
--------------------------------------------------------------------------------
Num Messages: 1 Next: ('chatbot',)
--------------------------------------------------------------------------------
Num Messages: 0 Next: ('__start__',)
--------------------------------------------------------------------------------
打印回退点信息
print(to_replay.next)
# config 包含一个 checkpoint_id 时间戳,告诉 LangGraph 的检查点程序从该时刻加载状态
print(to_replay.config)
输出结果:
('tools', )
{
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1ef8ba75-1232-6450-8006-ca98e9d2410b'
}
}
回退
# 回退
for event in graph.stream(None, to_replay.config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()
完整代码
from typing import Annotated
from dotenv import load_dotenv
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import AIMessage, ToolMessage
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import ToolNode, tools_condition
from pydantic import BaseModel
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 加载.env文件,获取密钥
load_dotenv(verbose=True)
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 创建 checkpointer
# 这里保存在内存,也可改为数据库
memory = MemorySaver()
# 初始化 ChatOllama 对象
llm = ChatOllama(model="llama3.2:3b")
llm_with_tools = llm.bind_tools(tools)
# llm = ChatOllama(model="gemma2:2b")
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
# 新增字段
ask_human: bool
class RequestAssistance(BaseModel):
"""
继承自BaseModel。这意味着RequestAssistance将具有数据验证的功能
如果当前的系统或程序无法直接提供帮助,或者用户需要超出当前系统权限的支持时,应该使用这个类来将对话升级给专家
"""
# 存储需要传递给专家的用户请求
request: str
def chatbot(state: State):
response = llm_with_tools.invoke(state["messages"])
ask_human = False
# 检查 response 对象是否有 tool_calls 属性
# 并且这个属性的第一个元素的 name 键对应的值是否等于 RequestAssistance 类的名称
if (
response.tool_calls
and response.tool_calls[0]["name"] == RequestAssistance.__name__
):
ask_human = True
return {"messages": [response], "ask_human": ask_human}
def create_response(response: str, ai_message: AIMessage):
"""
创建工具调用的响应消息
"""
return ToolMessage(
content=response,
tool_call_id=ai_message.tool_calls[0]["id"],
)
def human_node(state: State):
"""
接收一个State对象作为参数
如果 human 没有提供响应,则添加一个占位的响应消息
"""
new_messages = []
if not isinstance(state["messages"][-1], ToolMessage):
new_messages.append(
create_response("No response from human.", state["messages"][-1])
)
return {
# Append the new messages
"messages": new_messages,
# Unset the flag
"ask_human": False,
}
def select_next_node(state: State):
"""
根据当前state,决定下一个节点
"""
if state["ask_human"]:
return "human"
# Otherwise, we can route as before
return tools_condition(state)
def stream_graph_updates(user_input: str, config):
for event in graph.stream({"messages": [("user", user_input)]}, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
# print("Test:", value)
def stream_graph_continue(config):
for event in graph.stream(None, config):
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 node
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 添加 human 节点
graph_builder.add_node("human", human_node)
# 2.1 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
# 条件函数
select_next_node,
# 定义可能的下一个节点
{"human": "human", "tools": "tools", END: END},
)
# graph_builder.add_conditional_edges(
# "chatbot",
# tools_condition,
# )
# 2.2 添加普通边
# tools 节点调用结束,会又回到 chatbot 节点
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge("human", "chatbot")
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
# graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile(
checkpointer=memory,
# interrupt_before=["tools"]
# Note: can also interrupt __after__ actions, if desired.
# interrupt_after=["tools"]
interrupt_before=["human"]
)
# 6. 可视化 graph
try:
# graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
graph.get_graph().draw_mermaid_png(output_file_path="graph_with_human.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
# 配置 thread_id
user_config = {"configurable": {"thread_id": "1"}}
# 模拟用户输入
user_input = "I need some expert guidance for building this AI agent. Could you request assistance for me?"
events = graph.stream(
{"messages": [("user", user_input)]}, user_config, stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
events = graph.stream(
{"messages": [("user", user_input)]}, user_config, stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
# 要恢复的状态
to_replay = None
for state in graph.get_state_history(user_config):
print("Num Messages: ", len(state.values["messages"]), "Next: ", state.next)
print("-" * 80)
# 后续要恢复的状态
if len(state.values["messages"]) == 6:
# We are somewhat arbitrarily selecting a specific state based on the number of chat messages in the state.
to_replay = state
print(to_replay.next)
# config 包含一个 checkpoint_id 时间戳,告诉 LangGraph 的检查点程序从该时刻加载状态
print(to_replay.config)
# 回退
for event in graph.stream(None, to_replay.config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()
# while True:
# try:
# user_input = input("User: ")
# if user_input.lower() in ["quit", "exit", "q"]:
# # 当前状态值、相应的配置以及下一个要处理的节点
# snapshot = graph.get_state(user_config)
# print(snapshot)
# print("Goodbye!")
# break
#
# stream_graph_updates(user_input, user_config)
# snapshot = graph.get_state(user_config)
# print(snapshot)
# print(snapshot.next)
# # existing_message = snapshot.values["messages"][-1]
# # print(existing_message.tool_calls)
# # # 让 graph 继续执行
# # stream_graph_continue(user_config)
# # 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
# except:
# # 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
# user_input = "What do you know about LangGraph?"
# print("User: " + user_input)
# stream_graph_updates(user_input, user_config)
# break


















 4992
4992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









