




 本文介绍CS231N课程中图像分类的基础概念,包括KNN算法及其计算流程、训练集验证集与测试集的区别及交叉验证的作用,并讨论线性分类的工作原理与局限性。
本文介绍CS231N课程中图像分类的基础概念,包括KNN算法及其计算流程、训练集验证集与测试集的区别及交叉验证的作用,并讨论线性分类的工作原理与局限性。
CS231N斯坦福计算机视觉公开课 01 - 图像分类流程
一、KNN算法(惰性算法)
训练过程:记忆所有的数据以及表桥
测试过程:找到与当前图像最相似的标签
那么如何计算两张图片是否是相似的呢?
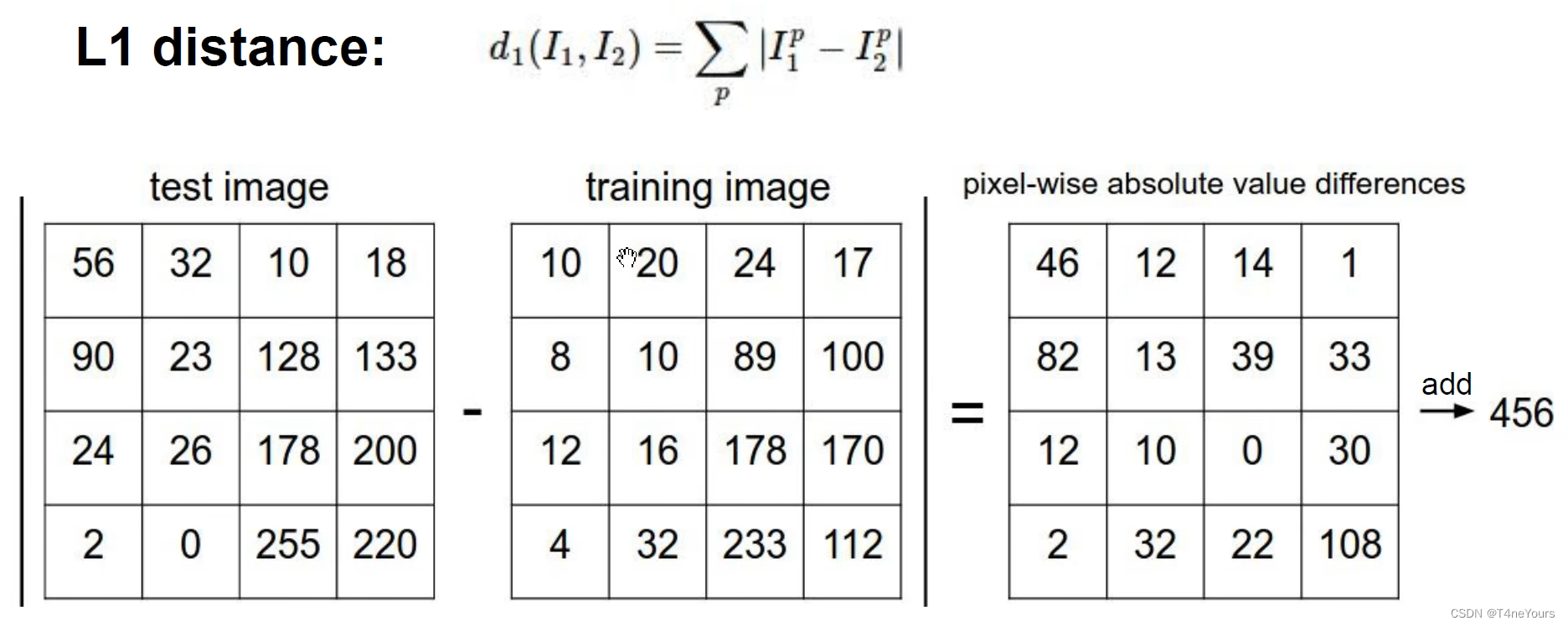
(1)L1 distance(曼哈顿距离)
L1距离:把两张图片对应位置的像素相减,把差的所有像素进行求和
- 适用于坐标轴的含义明确,坐标系的变化会带来变化
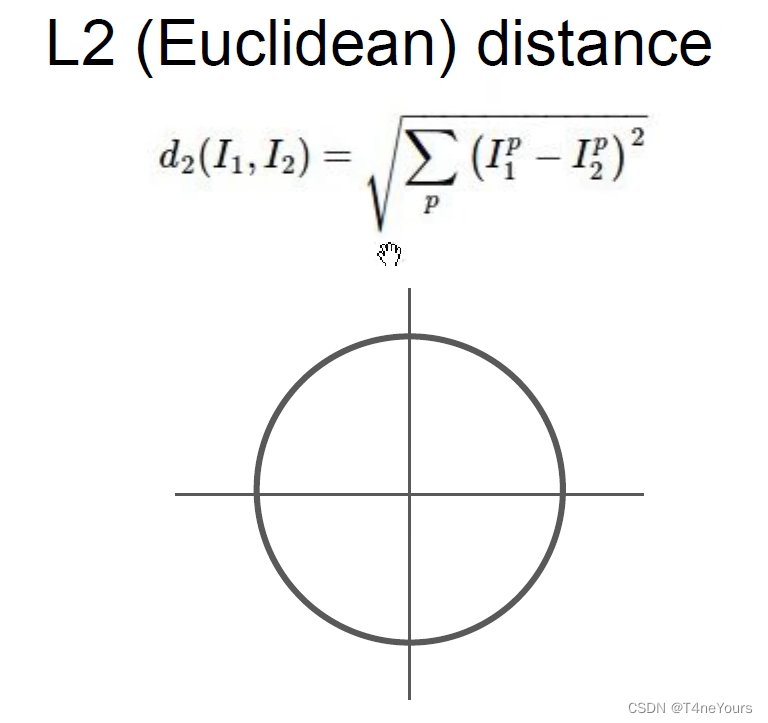
(2)L2 distance
适用于坐标轴之间没有明确关系
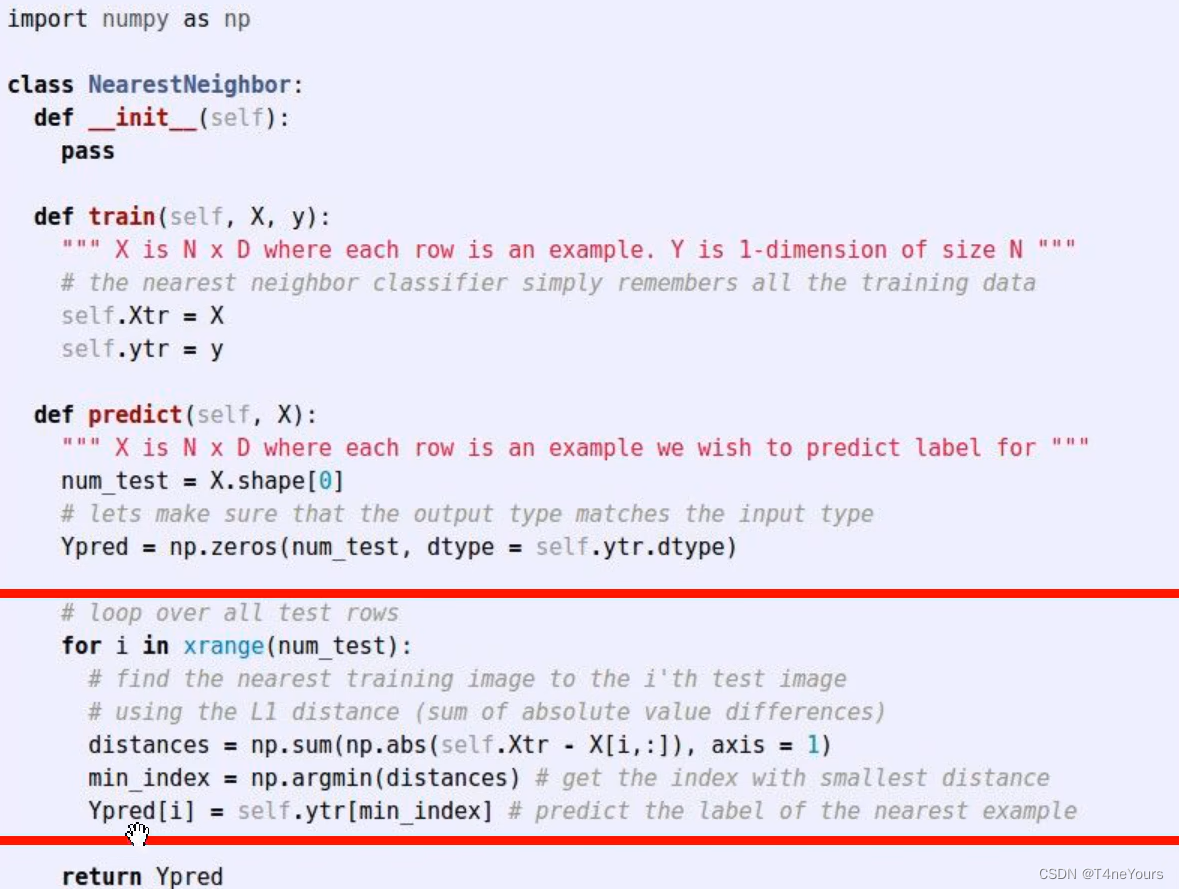
(3)计算流程
计算流程
- 将所有训练集的图片与测试集当前图片的L1距离保存到 distance 中
- 选取 distance 中最小的距离的标签作为当前测试集图片的标签(最近邻算法)
(4)K近邻与最近邻比较
K近邻算法优点:
- 防止如同K = 1时的噪声点影响预测结果的情况出现
- 并不是K越大越好

(5)缺点
- 如果对于整张图片进行修改,计算出来的距离不会改变,但实际上图片已经发生改变
- 如果数据量过大,需要保存和调用每一张图片的计算量过大
- 维度会发生指数爆炸

二、训练集、验证集、测试集(train、validation、test)
可以把训练集、验证集、测试集看做是学习过程、模拟考试和高考
- 在训练集上训练模型
- 在验证集上选择较好的参数
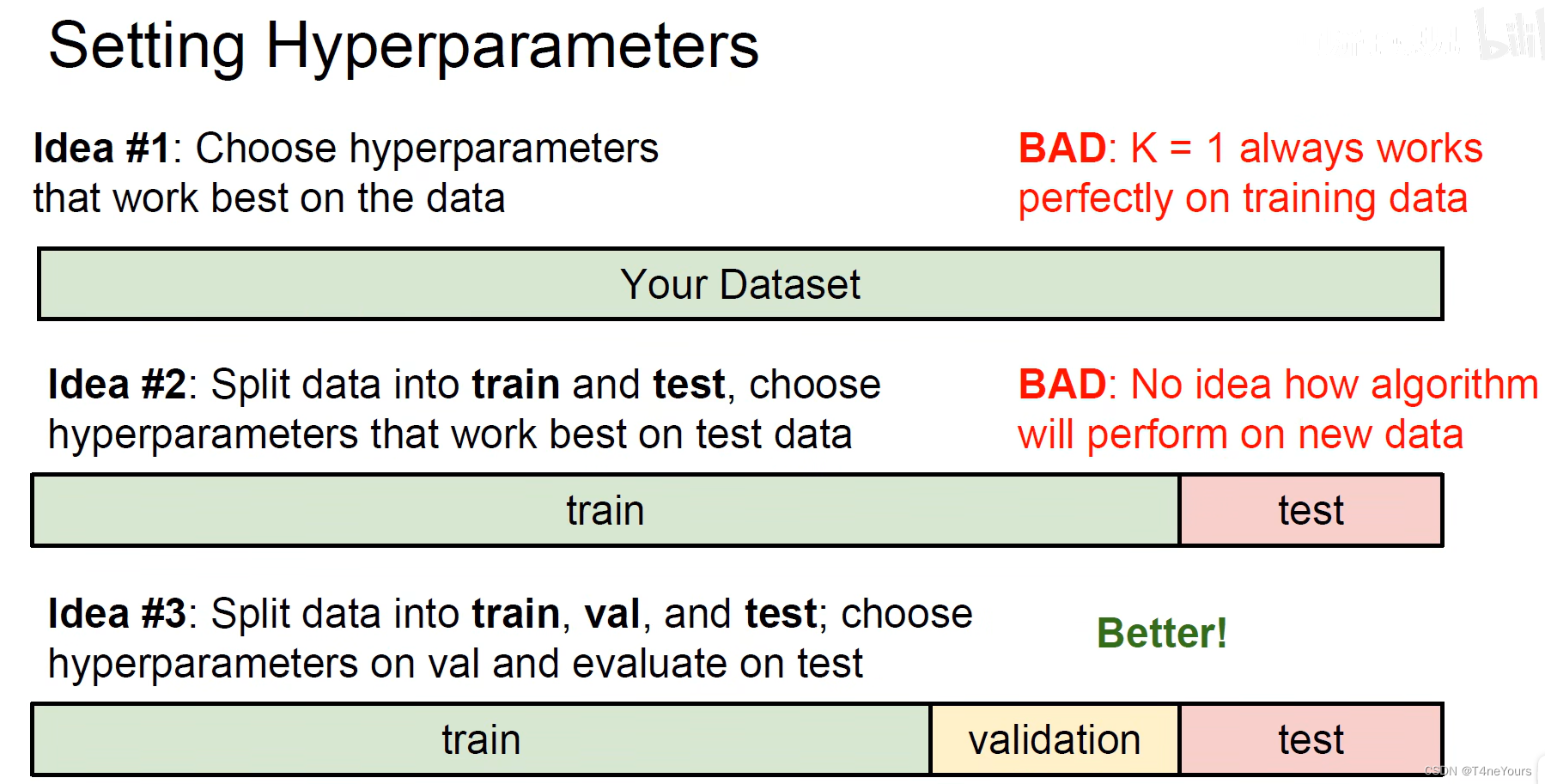
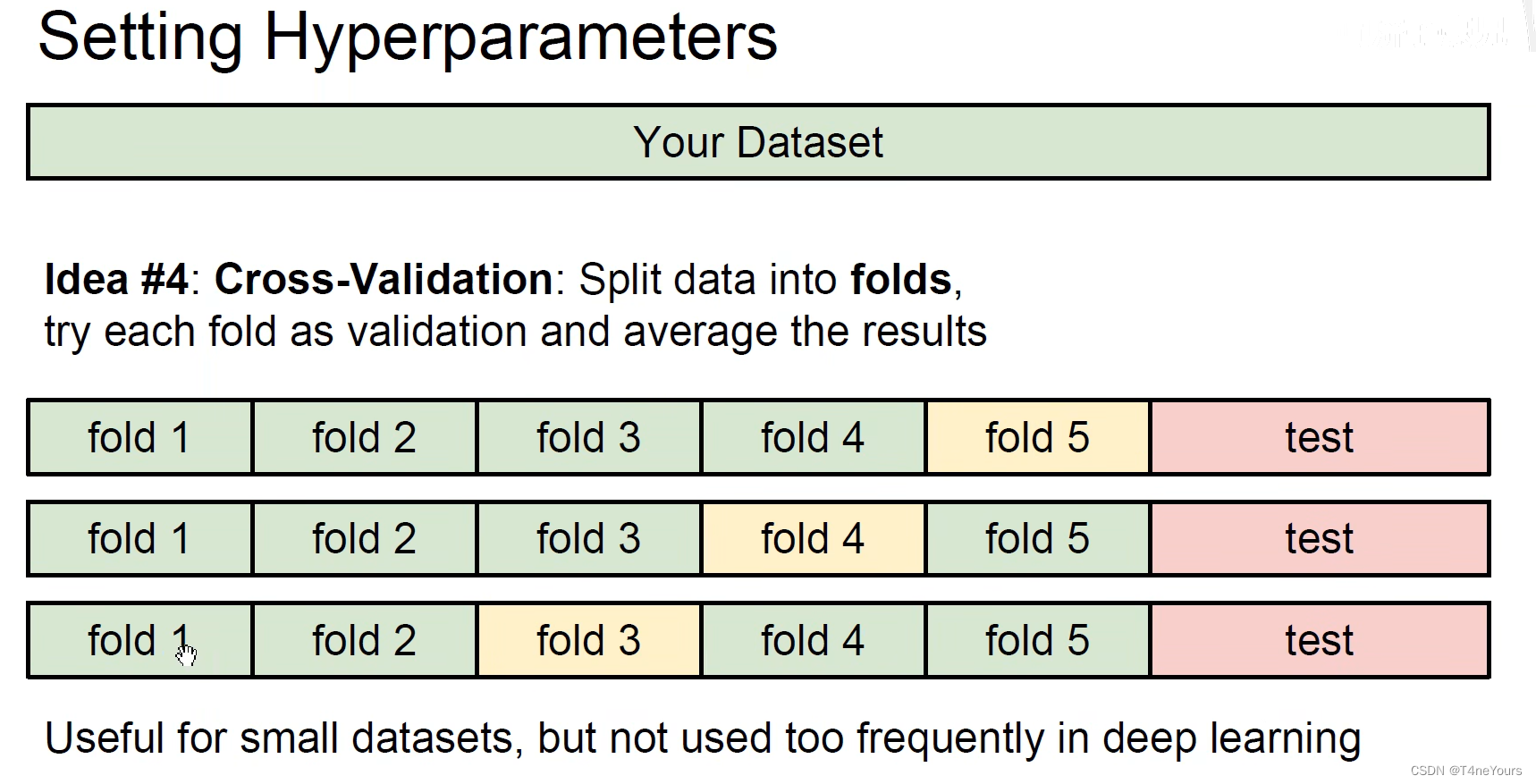
(1)交叉验证
- 作用:避免偶然误差,尽可能发挥每一个数据的功效
三、线性分类
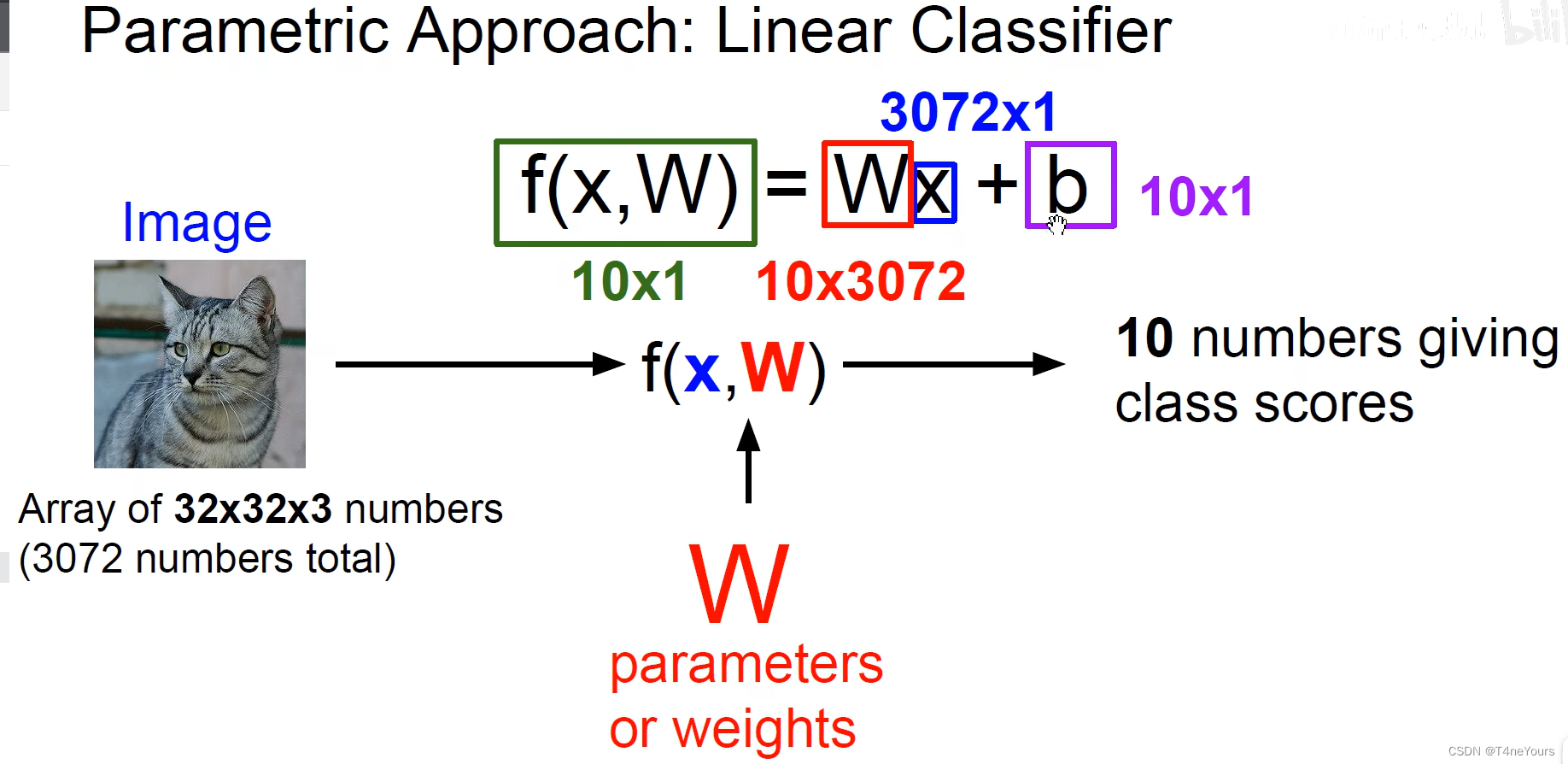
1.工作原理
举例
- 一张图片长宽为32个像素,三通道,那将这些像素展开可得3072个向量,作为3072个自变量,给这些自变量分别乘以n个不同的权重,就可以得到n个类别的分类
- 可以把权重和截距两个参数看做是我们要优化的超参数。
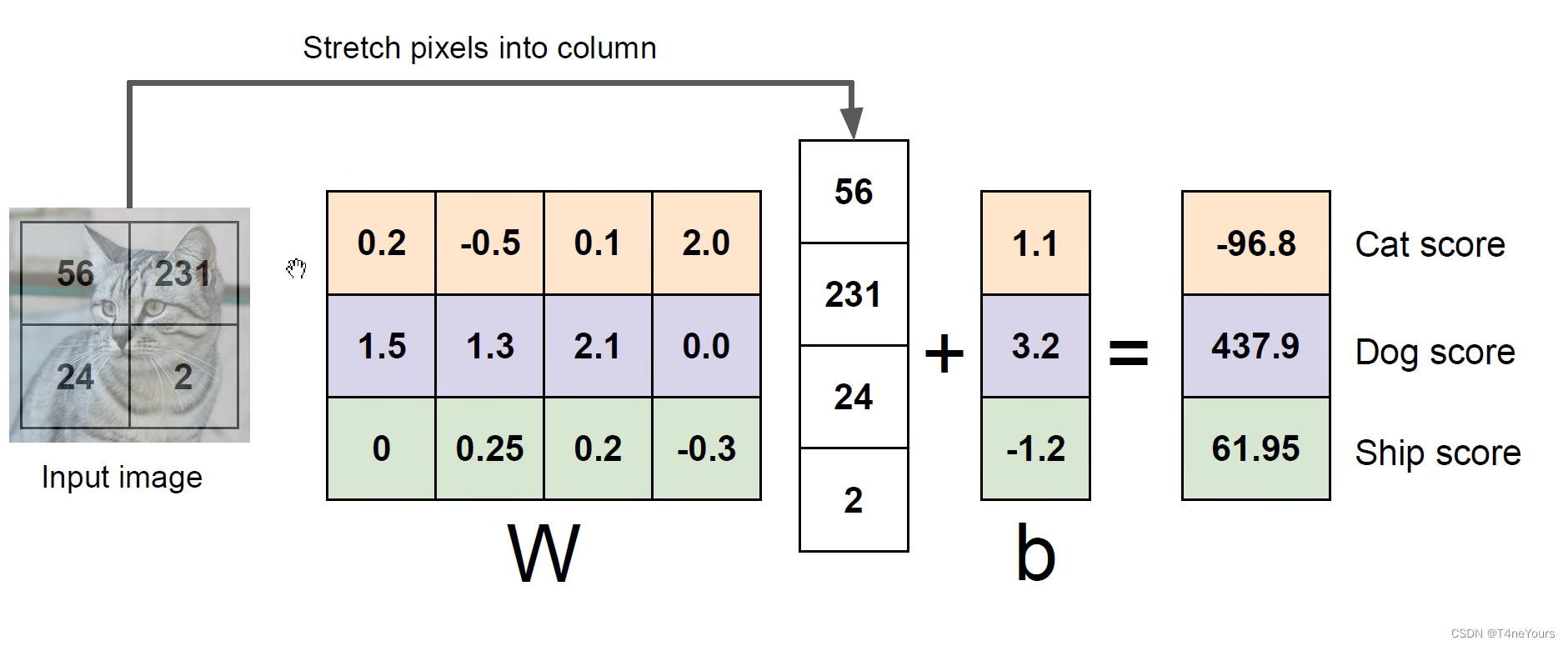
对应位置的像素*对应位置的权重+截距=最后的得分
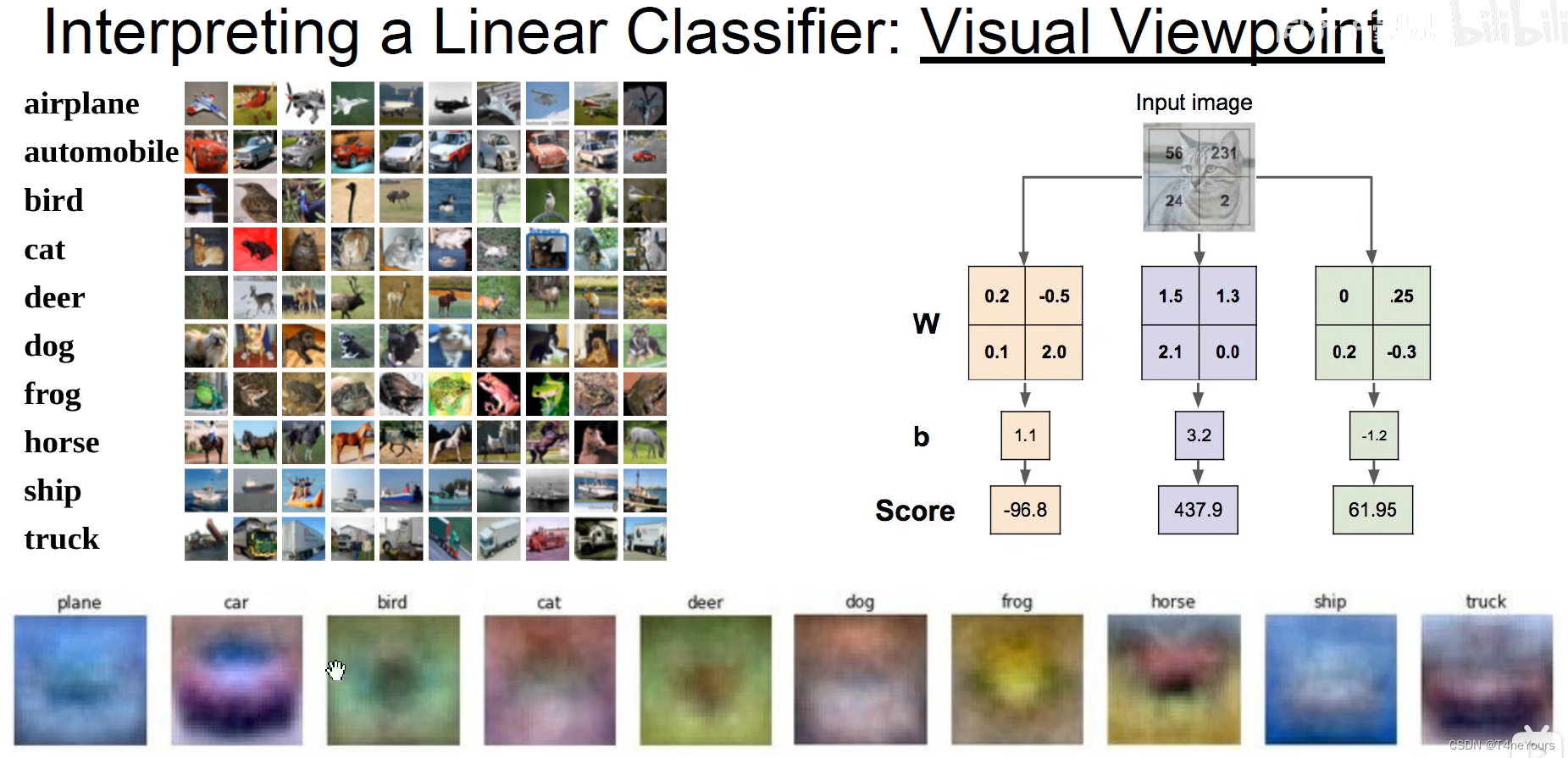
- 特征可视化:将每一个权重还原成对应的像素,即可得到每一个特征所对应的图像,如最下方一列所示。
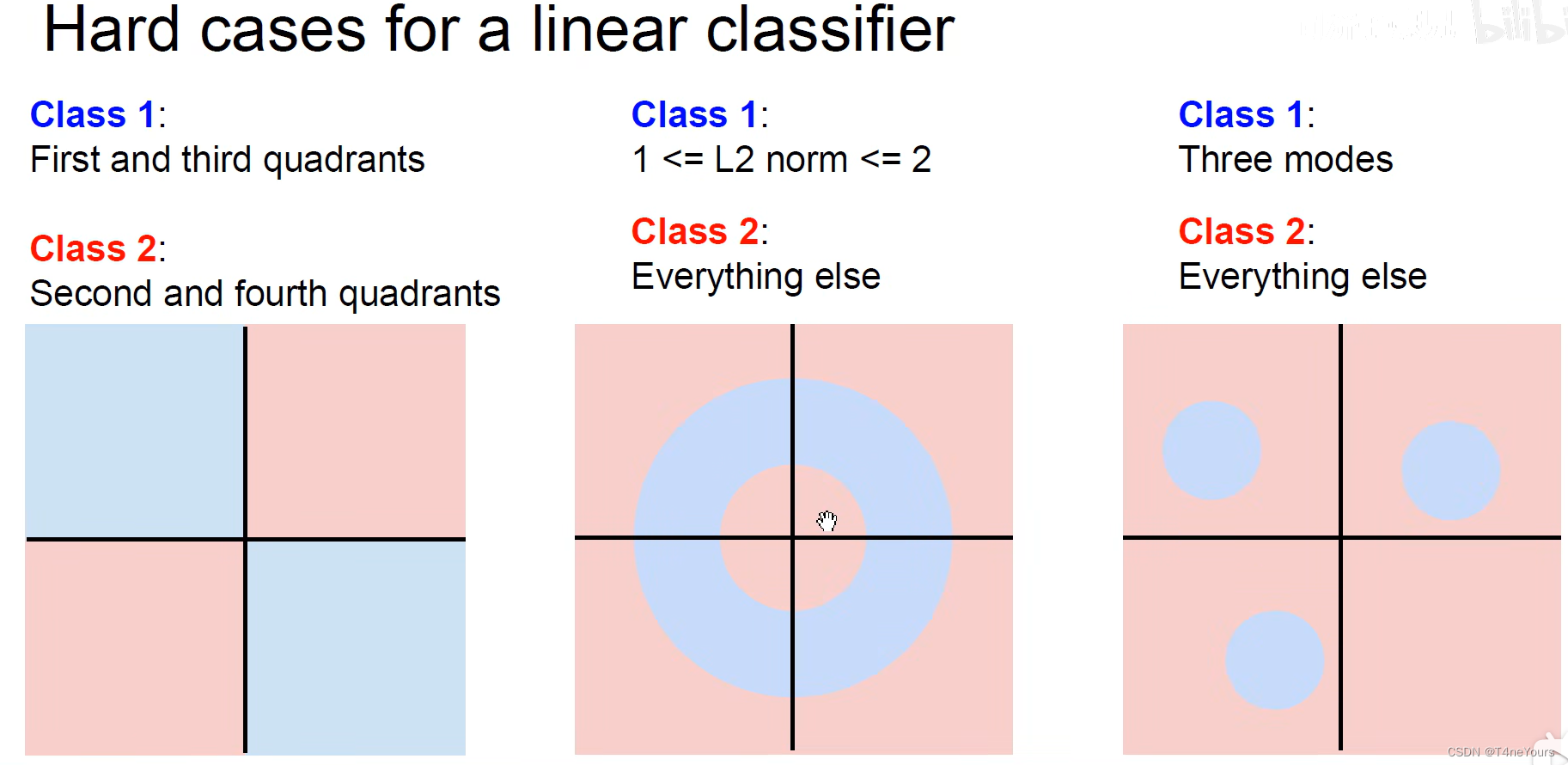
2.缺点
由于线性分类为在N维特征中建立超平面对于图像进行分类,对于特定状况的数据集不好处理

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









