




 本文通过实战案例,详细讲解了Python爬虫的三大核心模块:请求、解析和存储。以厦门大学经济学院教师信息为例,演示了如何使用requests和BeautifulSoup进行网页数据抓取和解析,并将结果存储至本地。
本文通过实战案例,详细讲解了Python爬虫的三大核心模块:请求、解析和存储。以厦门大学经济学院教师信息为例,演示了如何使用requests和BeautifulSoup进行网页数据抓取和解析,并将结果存储至本地。
**上篇我们学习了python爬虫的一个基础例子。如果那个掌握了,这个应该很简单。**
本次实验爬取厦门大学经济院教师姓名及教师介绍的链接
url='http://www.wise.xmu.edu.cn/people/faculty’
爬虫3大核心模块
1.请求
- 先发送get请求–(获取html文档)
看是否能正确得到其源文件。
import requests
DOWNLOAD_URL = 'http://www.wise.xmu.edu.cn/people/faculty'
def download_page(url):
"""返回所取参数的html源代码
:argv: url: 网页路径
:return: 网页html文档
"""
return requests.get(url).content
def main():
url = DOWNLOAD_URL
html = download_page(url)
print(html)
if __name__ == '__main__':
main()

发现能正确返回,没有一点反爬虫手段。这就简单了。
2.解析
- 分析其页面结构—(解析html文档–>找到我们想要的内容)
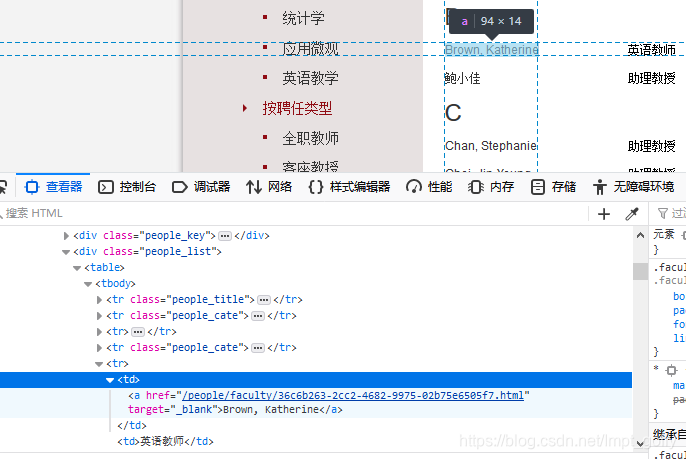
找到我们要抓取的信息的位置 :都在本页面下的一个class为people_list的div里的一个target=_blank的a标签里。
from bs4 import BeautifulSoup
def parse_html(html):
"""把所获文档中的教师姓名及链接以字典形式返回
:argv: html文档
:return:{教师:链接}的字典形式
"""
#创建BfS对象
soup = BeautifulSoup(html)
#先定位到这个大的div下
people_list = soup.find('div', attrs = {'class' : 'people_list'})
#创建字典
people_name_dict = {}
#找到这个div标签中的所有target=_blank的a元素
for people_td in people_list.find_all('a', attrs = {'target' : '_blank'}):
#用迭代将教师姓名和链接保存
#BfS支持getText()方法取出a标签中的文本;支持['href']分离出a标签中的链接信息
people_name = people_td.getText()
people_url = people_td['href']
people_name_dict.updata({people_name : people_url})
return people_name_dict
3.存储
- 把爬取到的信息保存起来—(存储信息)
def main():
url = DOWNLOAD_URL
html = download_page(url)
people_info = parse_html(html)
with open('test_text', 'w', encoding = 'utf-8') as fobj:
for p_name, p_url in people_info.items():
fobj.write("{} : {}\n".format(p_name, url + p_url))
- 最后,将我们所有的代码进行整合
import requests
from bs4 import BeautifulSoup
DOWNLOAD_URL = 'http://www.wise.xmu.edu.cn/people/faculty'
def download_page(url):
return requests.get(url).content
def parse_html(html):
soup = BeautifulSoup(html)
people_list = soup.find('div', attrs = {'class' : 'people_list'})
people_name_dict = {}
for people_td in people_list.find_all('a', attrs = {'target' : '_blank'}):
people_name = people_td.getText()
people_url = people_td['href']
people_name_dict.update({people_name : people_url})
return people_name_dict
def main():
url = DOWNLOAD_URL
html = download_page(url)
people_info = parse_html(html)
with open('test_txt', 'w', encoding = 'utf-8') as fobj:
for p_name, p_url in people_info.items():
fobj.write("{} : {}\n".format(p_name, url + p_url))
if __name__ == '__main__':
main()

















 3024
3024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









