




 本文深入解析正则表达式的概念、操作符及经典应用场景,详细介绍re库的使用技巧,包括贪婪与非贪婪匹配的区别,适合初学者及进阶者学习。
本文深入解析正则表达式的概念、操作符及经典应用场景,详细介绍re库的使用技巧,包括贪婪与非贪婪匹配的区别,适合初学者及进阶者学习。
文章目录
中英文混排输出—>
中文输出对齐问题:
chr(12288)–用中文空格填充。
1.正则表达式的概念:
-
regular expression RE
简洁表达一组字符串的表达式,同时查找或替换一组字符串。
匹配一组或多组。主要应用在字符串匹配中。 -
re库是py标准库,用于字符串匹配:
- 正则表达式的表示类型:
原生字符串 raw string:
r'text'不包含转义字符的字符串
string类型:
需要增加转义符号,更加的繁琐了。
- 正则表达式的表示类型:
2.正则表达式的常用操作符:
. ‘表示任何单个字符’
[] ‘字符集, 对单个字符给出取值范围。‘[]’中的字符是或的关系’
[^] ‘非字符集,对单个字符给出排除范围。 ’
* ‘前一个字符 0次或无限次扩展’
+ ‘前一个字符 1次或无限次扩展’
? ‘前一个字符0次或1次扩展’
| ‘左右表达式任意1个’
{} ‘{m} 扩展前一个字符m次’
{m, n} ‘扩展前一个字符m至n次(含n)’
^ ‘匹配字符串开头, 如^abc,表示匹配的字符串的开头一定是 abc’
$ ‘匹配字符串结尾,abc$, 结束匹配。’
() ‘分组标记,内部只能用|操作符,就是将括号内的内容看为一个整体。’
\d ‘数字,等价于[0-9]’
\w ‘单词字符,等价于 [A-Za-z0-9_]’
3.经典正则表达式:
^[A-Za-z]+$ : 表示26个字母组成的字符串
^[A-Za-z0-9]+$ : 表示26个字母和数字组成的字符串
^-?\d+$ : 表示整数形式的字符串
^[0-9]*[1-9][0-9]*$ : 正整数形式的字符串
[1-9]\d{5} : 中国境内邮政编码
[\u4e00-\u9fa5] : 匹配中文字符
\d{3}-\d{8}|\d{4}-\d{7}
:国内电话号码
(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
: IP地址的正则表达式
4.re库最常用的功能函数:
常用函数:
re.findall() 搜索字符串,以列表形式返回全部能匹配的子串 (常用)
re.sub() 替换匹配到的子串,返回替换后的字符串。 (常用)
re.spilt() 将一个字符串按照正则分割,返回列表类型 (常用)
re.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
re.match() 从一个字符串的开始位置起匹配正则,返回match对象
re.finditer() 搜索字符串,返回匹配结果的迭代形式。
详细使用:
"""re.search()"""
re.search(pattern, string, flags=0):
:args: pattern:正则表达式
string: 要匹配字符串
flags:正则表达式使用时的控制标记:
"""控制标记"""
re.I 忽略大小写
re.M 正则表达式中的^操作符能将给定字符串的每行当作匹配开始
re.S 正则中的.操作符能够匹配所有字符,默认匹配除换行符外的所有字符。
:return: 返回match对象
"""re.match()"""
re.match(pattern, string, flags=0):
"""re.findall()"""
re.findall(pattern, string, flags=0):
"""re.split()"""
re.split(pattern, string, maxsplit=0, flags=0):
args: maxsplit最大分割数(分割为多少个部分),剩余部分作为最后一个元素输出.
"""re.finditer()"""
re.finditer(pattern, string, flags=0):
:return: 返回一个匹配结果的迭代类型,每个迭代元素是match对象。
"""re.sub()"""
re.sub(pattern, repl, string, count=0, flags=0):
:args: repl:替换匹配字符串的字符串
count:匹配的最大替换次数
"""match对象的属性"""
match对象的属性:
.string: 待匹配的文本
.re 匹配时使用的patten对象(正则表达式)
.pos 正则表达式搜索文本时的开始位置
.endpos 结束位置
.group(0) 获得匹配后的字符串
.start()匹配字符串在原始字符串的开始位置
.end() 结束位置
.span() 返回(.start().end())
正则表达式的另一种等价用法:
面向对象用法:编译后的多次操作:
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
将正则表达式编译称为一个正则表达式的类型。之后可直接调用pat的各种方法。
regex = re.compile(pattern, flags)
5.贪婪和非贪婪匹配
在一些正则表达式中经常会碰到.*?,.+?,.*等,这些都是贪婪与非贪婪的匹配模式。
. 匹配任意单个字符;
* 匹配前一个字符0次或无限次;
+ 匹配前一个字符1次或无限次;
? 匹配前一个字符0次或1次;
(1)贪婪匹配:
re 默认采用贪婪匹配,即输出匹配最长的子串
.* 表示返回最大匹配字符串;
比如:
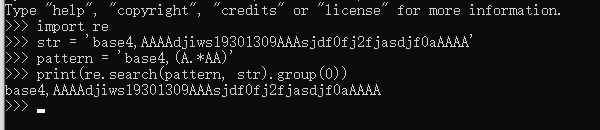
str = 'base4,AAAAdjiwsj19301309AAAsjdf0fj2fjasdjf0aAAAA'
pattern = 'base4,(A.*AA)' # .*表示任意字符的无限扩展,所以括号内表示,只要以A开头,AA结尾的字符串都满足规则,但是会返回最大匹配长度,即贪婪匹配。
re_str = re.search(pattern, str)
结果:base4,AAAAdjiwsj19301309AAAsjdf0fj2fjasdjf0aAAAA
(2)非贪婪匹配
当匹配的操作符有不同长度时,都可以添加一个问号,来进行最短匹配。
.*?和.+?表示非贪婪匹配
比如:
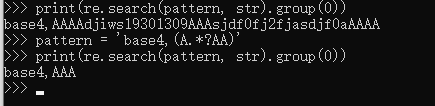
str = 'base4,AAAAdjiwsj19301309AAAsjdf0fj2fjasdjf0aAAAA'
pattern = 'base4,(A.*?AA)' # .*表示任意字符的无限次扩展,所以括号内表示,只要以A开头,AA结尾的字符串都满足规则,因为加了一个?,会返回最小匹配长度0次扩展,即非贪婪匹配。
re_str = re.search(pattern, str)
结果:base4,AAA
.+?同理
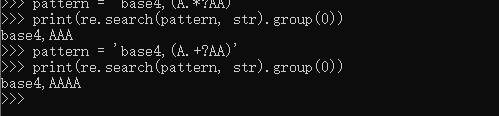 结果::
结果:: base4,AAAA

















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









