




Caffeine针对ConcurrentHashMap进行的改进
优化角度
-
缓冲化:使用写入和访问记录缓冲区,将零散的、并发的操作变为批量的、顺序的操作。
-
异步化:将维护任务从主读写路径中剥离,交给后台线程处理
-
处置化:将经常变化的状态(访问顺序、访问频率)从主存储结构剥离(CHM 的 Value),使用更高效的专业数据结构(时间轮、Count-Min Sketch)管理
-
无锁化:在核心读路径上,使用
volatile读和无锁操作,确保性能不受影响
一、写缓冲区
作用:使用写入和访问记录缓冲区,将零散的、并发的操作变为批量的、顺序的操作。
-
当有写入操作(
put、remove)发生时,Caffeine 并不立即直接操作底层的 CHM。 -
而是先将这个操作(以及相关的元数据变更,如访问记录)追加到一个无锁的多生产者单消费者队列中。
-
由一个独立的后台线程(或在你调用
get时顺带处理)批量地从缓冲区中取出多个操作,再批量地应用到真正的 CHM 上。
好处:
-
减少锁竞争:将高并发下大量零散的、需要竞争锁的写操作,合并成少量的、批量的写操作,极大地降低了 CHM 的锁粒度。
-
提升响应速度:写入线程只需将操作放入缓冲区即可返回,无需等待真正的 CHM 操作完成,写入延迟更低。
二、锁策略
Caffeine 极力避免在常见的读路径上进行任何需要锁的操作。
-
Guava Cache 的对比:Guava Cache 为了实现 LRU,每次
get访问都需要获取锁来操作访问队列(移动链表节点)。 -
Caffeine 的做法:
-
无锁的读:基础的
get操作就是 CHM 的get,这本身几乎是无锁的(或使用非常高效的volatile读和CAS)。 -
延迟记录访问:当一个条目被访问时,Caffeine 不会立即去更新一个复杂的顺序链表。它可能只是:
-
在条目本身记录一个
volatile的时间戳。 -
或者,将这次访问事件异步地记录到缓冲区(类似于写缓冲区),再由后台线程统一处理排序逻辑。
-
-
三、解耦排序与存储
针对过期淘汰优化
-
传统做法(Guava):维护一个按访问时间或写入时间排序的双向链表。插入、删除、移动节点都需要操作链表,意味着需要加锁。
-
Caffeine 的优化:使用
时间轮算法来管理过期。-
工作原理:时间轮是一个环形的数组,每个槽代表一个时间范围(比如 1 秒)。所有在同一秒内过期的条目都被放在同一个槽对应的链表中。
-
如何解耦:
-
当一个条目被存入 CHM 时,会根据它的过期时间计算出它应该在时间轮的哪个槽里。
-
只需要将这个条目引用到那个槽的链表里即可。这个操作很快,且通常每个槽各自持有独立的锁,竞争非常少。
-
处理过期时,一个后台线程只需转动时间轮,取出当前槽对应的链表,批量地、异步地从 CHM 中删除这些条目。
-
-
好处:
-
淘汰操作异步化:过期清理不再阻塞用户的读写请求。
-
高性能:插入和删除过期条目的开销是常数级的 O(1),而维护一个全局排序链表的代价是 O(n)。
-
-
四、频率统计
Count-Min Sketch数据结构,一个全局的、大小固定的二维数组,用于近似统计所有key的访问频率
-
如何解耦:
-
每次访问时,
get方法在从 CHM 中取出值后,会异步地向Count-Min Sketch报告一次访问 -
Count-Min Sketch的更新是使用哈希计算定位后直接累加,冲突概率低,速度极快。 -
当需要淘汰时(大小已满),决策引擎会咨询
Count-Min Sketch来比较两个条目的频率,而无需触动 CHM 的主存储结构。
-
-
好处:
-
读操作与频率统计解耦:
get操作的核心路径几乎不受影响。 -
极小且固定的内存开销:无论缓存多少数据,频率统计结构的大小都不变。
-
Window TinyLFU算法
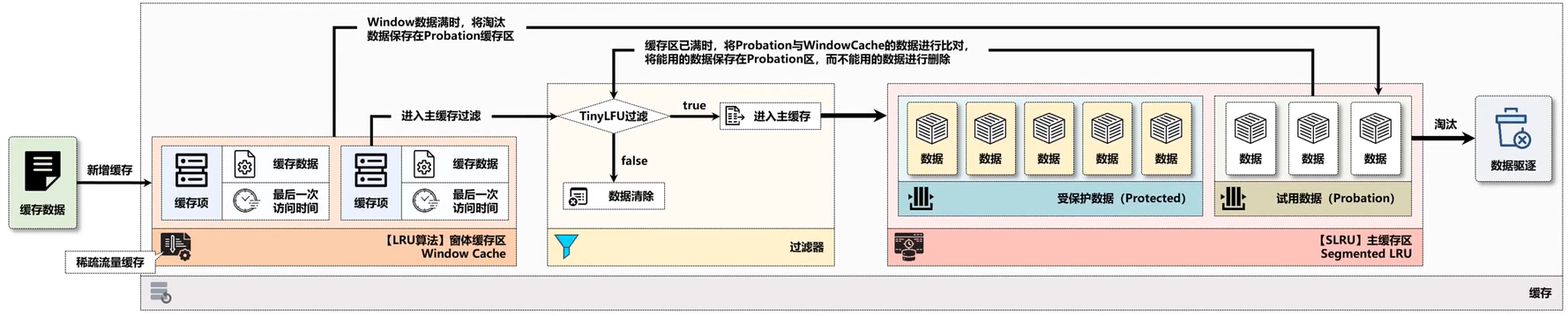
Caffeine将缓存区划分为两个区域:Window Cache 和 Main Cache
-
Window Cache 是一个标准的LRU缓存,只占整个缓存内存空间大小的1%
-
Main Cache 则是一个 SLRU (Segmented LRU) ,占整个缓存内存空间大小的 99% ,是缓存的主要区域。里面进一步被划分成两个区域:Probation (试用) Cache 观察区(20%)和 Protected (保护) Cache 保护区(80%)。
-
三个区域中的缓存都可以被访问到
-
算法中每个缓存项由都两部分组成:数据本身、访问次数
算法流程
-
新增缓存数据首先写入 Window Cache 区域。当 Window Cache 空间满时,LRU 算法发挥作用,最久未被访问的缓存项会被移出 Window Cache 。针对这个缓存项,分为两种情况:
-
如果试用缓存未满,则直接写入到试用缓存区中
-
试用缓存已满,则进入TinyLFU过滤器,与保护缓存区移出的缓存项比较,根据TinyLFU算法确定是否写入保护缓存区
-
-
试用缓存区中的缓存项的访问频率达到一定程度后,就会晋升到保护缓存区中,如果保护缓存区也满了,根据 LRU 算法,最久未被访问的缓存项会被移出保护缓存区,降级成为缓存项,进入到TinyLFU过滤器中,与Window Cache移出的缓存项作比较,根据TinyLFU算法确定该缓存项是淘汰还是降级到试用缓存区中
-
TinyLFU过滤器:汇聚了三个区域中最久未被访问的缓存项,在过滤器中竞争:
-
如果Window Cache和保护缓存区中的缓存项访问频率 > 试用缓存区中的缓存项,直接淘汰试用缓存区中的缓存项
-
如果Window Cache和保护缓存区中的缓存项访问频率 ≤ 试用缓存区中的缓存项,分两种情况:
-
如果Window Cache和保护缓存区中的缓存项的访问频率 < 5,则淘汰Window Cache和保护缓存区中的缓存项
-
否则这三种数据项随机淘汰一个
-
-
保留的缓存数据项被写入到试用缓存区中
-
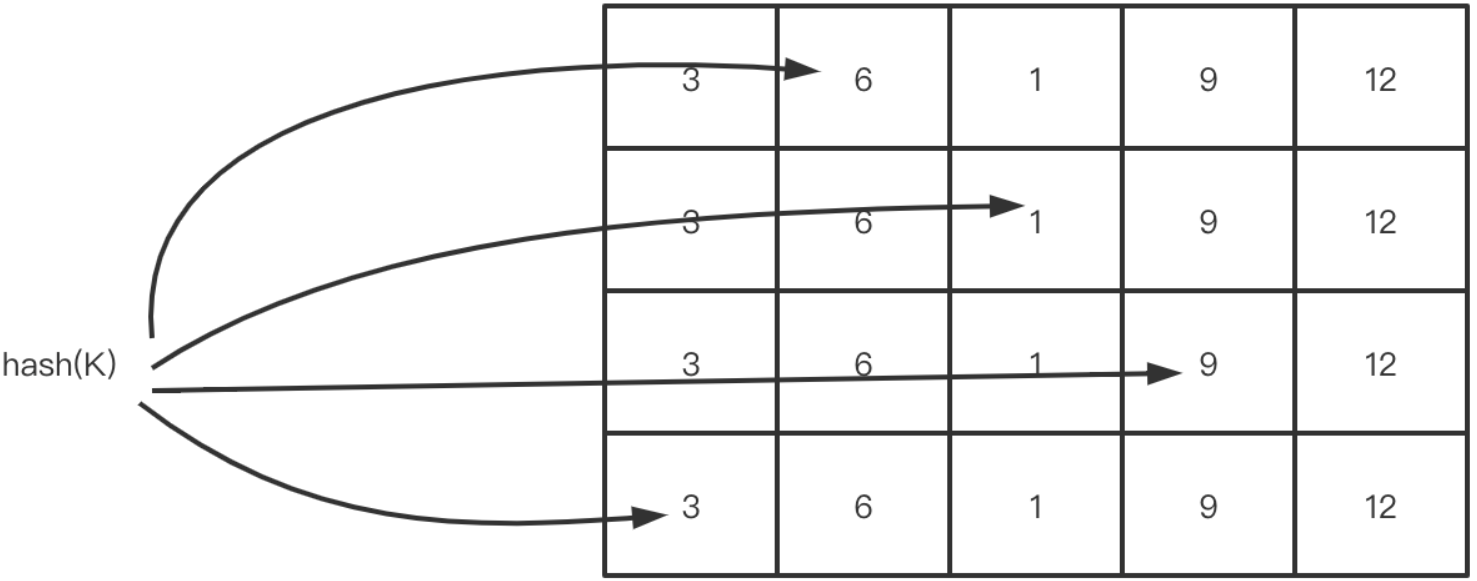
Count-Min Sketch
W-TinyLFU 算法使用 Count-Min Sketch 算法存储访问频率,极大地节省了空间,底层结构是一个二维数组,通过多个Hash函数计算得到缓存项在数组中的位置,当要添加数据时,在对应位置上的记录+1,判断频率时则取对应位置中的最小值作为频率次数

















 5804
5804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









