




一、Duel 网络是什么网络?
Dueling Network(竞争网络)是一种为深度强化学习(特别是基于价值的方法,如 DQN)设计的神经网络架构。
它的核心思想非常巧妙:它不直接学习一个动作的价值(Q值),而是将 Q 值的估算分解为两个独立的流(stream):
- 状态价值函数 (State-Value Function), V(s):
这个值用来衡量“处在当前状态 s 本身有多好”,与具体要采取哪个动作无关。
- 优势函数 (Advantage Function), A(s, a):
这个值用来衡量“在状态 s 下,采取动作 a 相对于其他所有可能动作的好处有多大”。
class VAnet(nn.Module):
def __init__(self, cfg):
super(VAnet, self).__init__()
self.fc1 = nn.Linear(cfg.n_states, cfg.hidden_dim)
self.fc_a = nn.Linear(cfg.hidden_dim, cfg.n_actions)
self.fc_v = nn.Linear(cfg.hidden_dim, 1)
def forward(self, x):
# forward相比MLP网络结构发生了改变
x = F.relu(self.fc1(x))
a = self.fc_a(x)
v = self.fc_v(x)
q = v + a - a.mean(dim=1).view(-1, 1)
return q
Dueling Network 的作者认为,在很多状态下,我们并不需要关心每个动作的具体价值,而只需要知道当前状态的价值。通过将 V(s) 和 A(s, a) 分开学习,网络可以更有效地学习状态的内在价值,而不需要为每个动作都计算出一个精确的估计,这大大提升了学习效率和最终的策略表现。
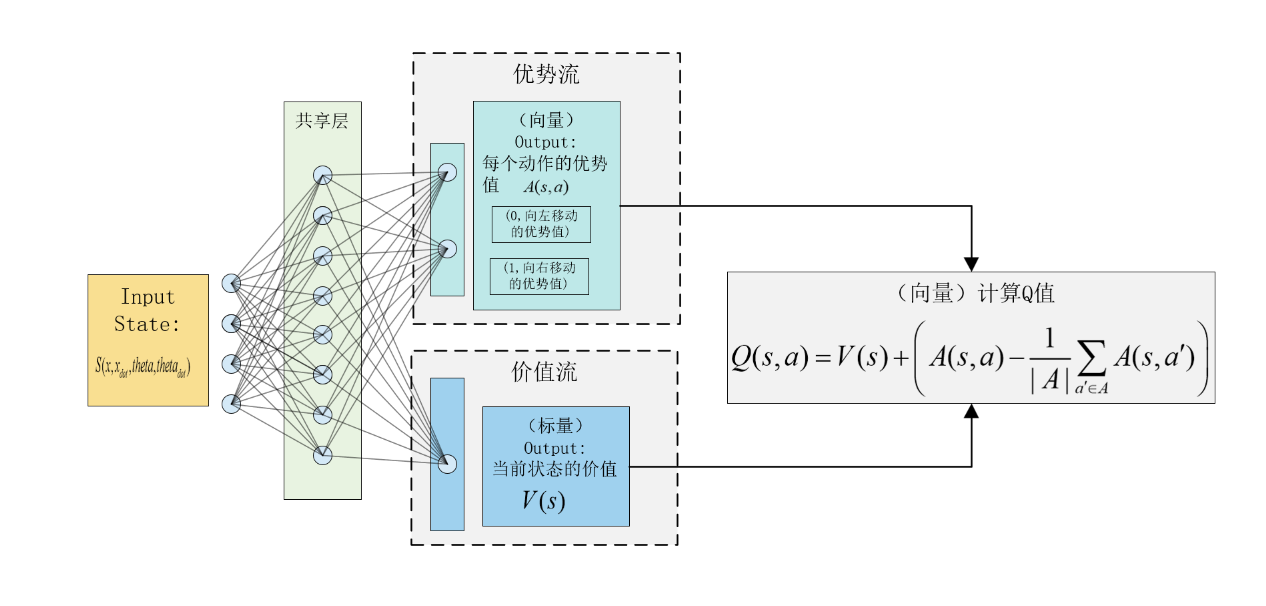
1. 共享的编码器
作用: 负责从原始输入(如游戏画面、传感器数据等)中提取高级特征。
设计:
对于图像输入(例如 Atari 游戏),这部分通常是由多个卷积神经网络(CNN)层组成。
对于向量或状态特征输入,这部分通常是几个全连接层(Fully Connected Layers)。
输出: 一个代表当前状态的特征向量。这个特征向量将被同时送入下面的两个分支。
2. 两个独立的分支
分支一:价值流 (Value Stream)
作用: 专门用来估算状态价值 V(s)。
设计: 通常由一个或多个全连接层组成。
输出: 一个标量(单个数值),代表 V(s)。
分支二:优势流 (Advantage Stream)
作用: 专门用来估算每个动作的优势 A(s, a)。
设计: 通常也由一个或多个全连接层组成。
输出: 一个向量,其长度等于动作空间的大小。向量中的每个元素代表对应动作的优势值 A(s, a)
3. 聚合层
这是 Dueling Network 最关键的部分。它将价值流输出的 V(s) 和优势流输出的 A(s, a) 向量合并起来,计算出最终的 Q 值。
你可能会想,最简单的方法是直接相加:Q(s, a) = V(s) + A(s, a)。
但这样做会产生一个问题,叫做不可辨识性(Identifiability)。例如,如果 V(s) 增加 10,同时所有的 A(s, a) 都减少 10,最终的 Q 值是不变的。这会导致网络训练不稳定,因为梯度可以任意地在两个分支之间流动。
为了解决这个问题,论文提出了一个强制性的约束来稳定训练。最常用和最稳定的方法是,减去优势函数的均值:
Q(s,a)=V(s)+(A(s,a)−mean(A(s,a′)))Q(s, a) = V(s) + (A(s, a) - mean(A(s, a')))Q(s,a)=V(s)+(A(s,a)−mean(A(s,a′)))
A(s, a): 这是优势流为特定动作 a 输出的值。
mean(A(s, a’)): 这是优势流为所有可能动作输出的值的平均值。
这个公式的意义:
它强制要求对于一个给定的状态,所有动作的优势值之和(或均值)为 0。
这样做的好处是:
V(s) 被“逼着”去学习状态的真实价值。
A(s, a) 则专注于学习每个动作的相对好坏。
它消除了 V 和 A 之间的冗余自由度,使得学习过程更加稳定。
Q(s,a)=V(s)+(A(s,a)−1∣A∣∑a′∈AA(s,a′))Q(s,a) = V(s) + \left( A(s,a) - \frac{1}{|A|} \sum_{a' \in A} A(s,a') \right)Q(s,a)=V(s)+(A(s,a)−∣A∣1∑a′∈AA(s,a′))
优势函数 A(s, a) 输出的向量,存储的不是每个动作的精确 Q 值,而是每个动作的相对价值或相对优势。
2. 为什么状态价值是标量,而动作优势是向量?
这源于它们在强化学习中的定义和含义。
状态价值 V(s) 衡量的是一个状态 s 本身的好坏程度”。它代表了智能体从状态 s 开始,遵循某个策略所能获得的期望回报。这个评估是宏观的,与接下来具体采取哪个动作无关。
直观理解:一个状态的好坏,就是一个综合性的评价。
例子1:下棋。在一个必胜的棋局状态下,这个状态的价值就很高。这个“高价值”是一个单一的数值。
例子2:开车。你正行驶在一条宽阔无人的高速公路上,这个状态的价值很高。而如果你被堵在水泄不通的市中心,这个状态的价值就很低。无论“高”还是“低”,它都是一个单一的评估值。
**结论:**因此,对于任何一个给定的状态 s,它的价值 V(s) 都是一个单一的数值,也就是一个标量。网络中 self.fc_v 的输出维度被设置为 1 正是这个原因。
动作优势 A(s, a) 衡量的是在状态 s 下,“采取某个特定动作 a” 相对于在该状态下所有动作的平均价值而言,有多大的优势或劣势。这是一个相对和具体的概念。
直观理解:优势是与每个动作一一对应的。
例子1:下棋。在那个必胜的棋局状态下(V(s)很高),走法A可能会让你10步后将军(优势很大),走法B可能会让你20步后将军(优势较小),而走法C是一个失误,会让你失去优势(优势为负)。你需要为每一个可选的走法都评估一个优势值。
例子2:开车。在高速公路上(V(s)很高),“踩油门”这个动作的优势是正的,“急刹车”的优势是负的,“向左变道”和“向右变道”的优势可能都接近于零。
**结论:**因为环境中有多个可选动作(比如在 CartPole 中有向左和向右两种动作),我们需要为每一个动作都计算一个优势值。所以,对于一个给定的状态 s,优势函数的输出是一个包含了所有动作优势值的向量,向量的维度等于动作空间的大小(n_actions)。网络中 self.fc_a 的输出维度被设置为 cfg.n_actions 正是这个原因。
总结一下:

D3QN+PER机制算法代码(DQN+Double+Duel+PER):
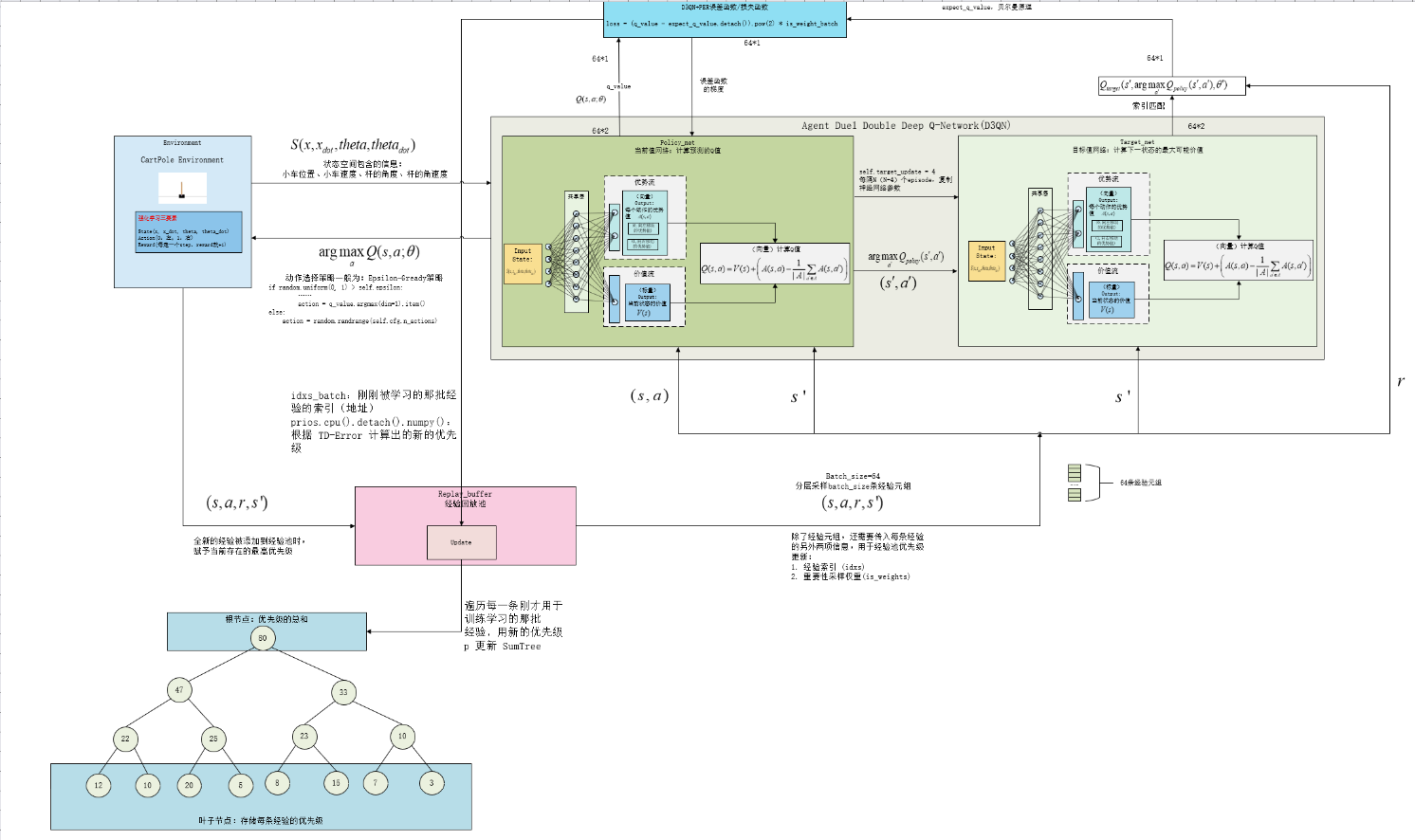
DQN 是基础框架。
Double 机制从算法层面解决了 Q 值过高估计的问题。
Dueling 架构从网络结构层面优化了 Q 值的学习方式。
将这两者结合起来,可以充分利用它们各自的优势,使得算法的性能和稳定性通常会比单独使用 Dueling DQN 或 Double DQN 更好,是 DQN 算法家族中一个非常强大和常用的变体。
import gymnasium as gym
import random
import numpy as np
import torch
from torch import nn, optim
from torch.nn import functional as F
class Config:
def __init__(self):
self.env_name = 'CartPole-v1'
self.algo_name = 'DDQN + PER + DUELING'
self.render_mode = 'rgb_array'
self.train_eps = 100
self.test_eps = 5
self.max_steps = 2000
self.epsilon_start = 0.95
self.epsilon_end = 0.01
self.epsilon_decay = 600
self.lr = 1e-3
self.gamma = 0.9
self.seed = random.randint(0, 100)
self.batch_size = 256
self.memory_capacity = 20000
self.hidden_dim = 256
self.target_update = 20
self.alpha = 0.6
self.beta = 0.4
self.error_max = 1.0
self.eps = 1e-6
self.beta_increment_per_sampling = 0.001
self.n_states = None
self.n_actions = None
self.device = torch.device('cuda') \
if torch.cuda.is_available() else torch.device('cpu')
def show(self):
print('-' * 30 + '参数列表' + '-' * 30)
for k, v in vars(self).items():
print(k, '=', v)
print('-' * 60)
class VAnet(nn.Module):
def __init__(self, cfg):
super(VAnet, self).__init__()
self.fc1 = nn.Linear(cfg.n_states, cfg.hidden_dim)
self.fc_a = nn.Linear(cfg.hidden_dim, cfg.n_actions)
self.fc_v = nn.Linear(cfg.hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
a = self.fc_a(x)
v = self.fc_v(x)
q = v + a - a.mean(dim=1).view(-1, 1)
return q
class SumTree:
def __init__(self, capacity):
self.capacity = capacity
self.tree = np.zeros(2 * capacity - 1)
self.data = np.zeros(capacity, dtype=object)
self.size = 0
self.data_pointer = 0
def update(self, index, priority):
change = priority - self.tree[index]
self.tree[index] = priority
while index != 0:
index = (index - 1) // 2
self.tree[index] += change
def add(self, priority, data):
index = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data
self.update(index, priority)
self.data_pointer += 1
if self.data_pointer >= self.capacity:
self.data_pointer = 0
if self.size < self.capacity:
self.size += 1
def get_leaf(self, v):
pa_idx = 0
while True:
lc_idx = pa_idx * 2 + 1
rc_idx = lc_idx + 1
if lc_idx >= len(self.tree):
leaf_idx = pa_idx
break
else:
if v <= self.tree[lc_idx]:
pa_idx = lc_idx
else:
v -= self.tree[lc_idx]
pa_idx = rc_idx
data_idx = leaf_idx - self.capacity + 1
return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
def total_priority(self):
return self.tree[0]
class ReplayBuffer:
def __init__(self, cfg):
self.cfg = cfg
self.tree = SumTree(self.cfg.memory_capacity)
def push(self, transition):
max_priority = np.max(self.tree.tree[-self.cfg.memory_capacity:])
max_priority = max_priority if max_priority != 0 else 1
self.tree.add(max_priority, transition)
def sample(self):
batch, idxs = [], []
segment = self.tree.total_priority() / self.cfg.batch_size
self.cfg.beta = np.min([1., self.cfg.beta + self.cfg.beta_increment_per_sampling])
priorities = []
for i in range(self.cfg.batch_size):
a, b = segment * i, segment * (i + 1)
v = random.uniform(a, b)
idx, priority, data = self.tree.get_leaf(v)
priorities.append(priority)
batch.append(data)
idxs.append(idx)
priorities = np.array(priorities)
sampling_probabilities = priorities / self.tree.total_priority()
is_weight = np.power(self.tree.size * sampling_probabilities, -self.cfg.beta)
is_weight /= is_weight.max()
batchs = map(lambda x: torch.tensor(np.array(x), device=self.cfg.device,
dtype=torch.float32), zip(*batch))
is_weight = torch.tensor(np.array(is_weight), device=self.cfg.device,
dtype=torch.float32)
return batchs, np.array(idxs), is_weight
def update(self, idx, error):
error += self.cfg.eps
clipped_error = np.minimum(error, self.cfg.error_max)
ps = np.power(clipped_error, self.cfg.alpha)
for i, p in zip(idx, ps):
self.tree.update(i, p)
def size(self):
return self.tree.size
class PER_DUEL_DDQN:
def __init__(self, cfg):
self.sample_count = 0
self.learn_count = 0
self.memory = ReplayBuffer(cfg)
self.policy_net = VAnet(cfg).to(cfg.device)
self.target_net = VAnet(cfg).to(cfg.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.cfg = cfg
self.epsilon = cfg.epsilon_start
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=cfg.lr)
@torch.no_grad()
def choose_action(self, state):
self.sample_count += 1
self.epsilon = self.cfg.epsilon_end + (self.cfg.epsilon_start - self.cfg.epsilon_end) * \
np.exp(-1. * self.sample_count / self.cfg.epsilon_decay)
if random.uniform(0, 1) > self.epsilon:
state = torch.tensor(np.array([state]), device=self.cfg.device, dtype=torch.float32)
action = self.policy_net(state).argmax(dim=1).item()
else:
action = random.randrange(self.cfg.n_actions)
return action
@torch.no_grad()
def predict_action(self, state):
state = torch.tensor(np.array([state]), device=self.cfg.device, dtype=torch.float32)
action = self.policy_net(state).argmax(dim=1).item()
return action
def update(self):
if self.memory.size() < self.cfg.batch_size:
return 0
(state_batch, action_batch, reward_batch, next_state_batch,
done_batch), idxs_batch, is_weight_batch = self.memory.sample()
action_batch = action_batch.type(torch.long).view(-1, 1)
q_value = self.policy_net(state_batch).gather(1, action_batch).squeeze(1)
next_q_value = self.policy_net(next_state_batch)
next_target_value = self.target_net(next_state_batch)
next_q_value = next_target_value.gather(1, next_q_value.argmax(dim=1).unsqueeze(1)).squeeze(1)
expect_q_value = reward_batch + self.cfg.gamma * next_q_value * (1 - done_batch)
loss = (q_value - expect_q_value.detach()).pow(2) * is_weight_batch
prios = loss + self.cfg.eps
loss = torch.mean(loss)
self.memory.update(idxs_batch, prios.cpu().detach().numpy())
self.optimizer.zero_grad()
loss.backward()
for param in self.policy_net.parameters():
param.grad.data.clamp_(-1, 1)
self.optimizer.step()
if self.learn_count % self.cfg.target_update == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
self.learn_count += 1
return loss.item()
def env_agent_config(cfg):
env = gym.make(cfg.env_name, render_mode = cfg.render_mode).unwrapped
print(f'观测空间 = {env.observation_space}')
print(f'动作空间 = {env.action_space}')
cfg.n_states = env.observation_space.shape[0]
cfg.n_actions = env.action_space.n
agent = PER_DUEL_DDQN(cfg)
return env, agent
def train(env, agent, cfg):
print('开始训练!')
cfg.show()
rewards, steps = [], []
for i in range(cfg.train_eps):
ep_reward, ep_step = 0.0, 0
state, _ = env.reset(seed=cfg.seed)
loss = 0.0
for _ in range(cfg.max_steps):
ep_step += 1
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
agent.memory.push((state, action, reward, next_state, done))
state = next_state
loss_ = agent.update()
loss += loss_
ep_reward += reward
if done:
break
rewards.append(ep_reward)
steps.append(ep_step)
print(f'回合:{i + 1}/{cfg.train_eps} 奖励:{ep_reward:.0f} 步数:{ep_step:.0f} '
f'epsilon:{agent.epsilon:.4f} Loss:{loss/ep_step:.4f}')
print('完成训练!')
env.close()
return rewards, steps
def test(agent, cfg):
print('开始测试!')
rewards, steps = [], []
env = gym.make(cfg.env_name, render_mode='human')
for i in range(cfg.test_eps):
ep_reward, ep_step = 0.0, 0
state, _ = env.reset(seed=cfg.seed)
for _ in range(cfg.max_steps):
ep_step += 1
action = agent.predict_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
state = next_state
ep_reward += reward
if terminated or truncated:
break
steps.append(ep_step)
rewards.append(ep_reward)
print(f'回合:{i + 1}/{cfg.test_eps}, 奖励:{ep_reward:.3f}')
print('结束测试!')
env.close()
return rewards, steps
if __name__ == '__main__':
cfg = Config()
env, agent = env_agent_config(cfg)
train_rewards, train_steps = train(env, agent, cfg)
test_rewards, test_steps = test(agent, cfg)


















 4856
4856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











