



参考文档
https://zhuanlan.zhihu.com/p/16965769370
介绍
大模型多LoRA部署是一种高效利用单一基座模型同时服务多个下游任务的推理方案,通过加载不同的低秩适配器(LoRA)实现任务定制化,显著节省显存与计算资源。
本文使用LoRA对Qwen3-1.7B进行指令微调,选择不同检查点得到的适配器进行测试。
环境介绍:
python 3.12
torch 2.7.1+cu128
transformers 4.54.0
vllm 0.10.0NOTE:原本的vllm版本为0.9.2,enable_lora=True时,模型初始化一直报错,应该是vLLM版本和LoRA兼容性的问题,后将vllm升级到0.10.0,解决了这个问题。
离线部署
模型加载
# 模型加载
from vllm import LLM, SamplingParams
from vllm.lora.request import LoRARequest
from transformers import AutoTokenizer
base_path = "/home/emma/.cache/modelscope/hub/models/Qwen/Qwen3-1.7B"
lora_path1 = "./output/Qwen3-cls_wanle/checkpoint-100/" # 适配器路径1
lora_path2 = "./output/Qwen3-cls_wanle/checkpoint-1120" # 适配器路径2
# 创建模型
llm = LLM(
model=base_path,
enable_lora=True,
max_model_len=2048,
dtype="auto",
gpu_memory_utilization=0.7, # 默认0.9
)
tokenizer = AutoTokenizer.from_pretrained(base_path)
print("base model load success!")
# 设置生成所需参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, top_k=50, max_tokens=2048)
# 定义LoRA请求
lora_request1 = LoRARequest("adapter_v1", 1, lora_local_path=lora_path1) #参数说明: lora_name="adapter_v1" 自定义名称; lora_int_id=1 唯一整数 ID; lora_local_path=lora_path1 本地适配器路径;
lora_request2 = LoRARequest("adapter_v2", 2, lora_local_path=lora_path2)模型推理
# 模型推理
prompts = ["文本:使用地址:南强街88号院剧场 昆明市五华区南强街巷八十八号庭院剧场(北后街30号院,祥云街旁建行大楼背后),类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜']", "文本:海港区+电报山+泛美金字塔,旧金山中文专车行程自由灵活-浪琴石园-北滩-柯伊特塔,类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜']"]
# 通过prompts构造prompt_token_ids
temp_prompts = [tokenizer.apply_chat_template(
[{"role": "system", "content": '你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型。请只输出分类结果,不要包含任何其他内容。'},
{"role": "user", "content": prompt}],
tokenize=False, add_generation_wohaisprompt=True) for prompt in prompts]
print(temp_prompts)
prompt_token_ids = tokenizer(temp_prompts).input_ids
# 注意,generate可以直接使用prompts,但直接使用prompts时,默认直接使用tokenizer.encode,没有拼接chat_template
print("加载Lora1进行模型推理:")
# 调用generate时,请求调用lora参数
outputs = llm.generate(sampling_params=sampling_params, prompt_token_ids=prompt_token_ids,
lora_request=lora_request1)
print(outputs)
# 输出结果
for i, (prompt, output) in enumerate(zip(prompts, outputs)):
generated_text = output.outputs[0].text
print("prompt: {}, output: {}".format(prompt, generated_text))
print("加载Lora2进行模型推理:")
# 调用generate时,请求调用lora参数
outputs = llm.generate(sampling_params=sampling_params, prompt_token_ids=prompt_token_ids,
lora_request=lora_request2)
print(outputs)
# 输出结果
for i, (prompt, output) in enumerate(zip(prompts, outputs)):
generated_text = output.outputs[0].text
print("prompt: {}, output: {}".format(prompt, generated_text))
print("仅使用基座模型推理:")
# 调用generate时,请求调用lora参数
outputs = llm.generate(sampling_params=sampling_params, prompt_token_ids=prompt_token_ids)
print(outputs)
# 输出结果
for i, (prompt, output) in enumerate(zip(prompts, outputs)):
generated_text = output.outputs[0].text
print("prompt: {}, output: {}".format(prompt, generated_text))结果输出
# 结果输出
------------------------------------------
加载Lora1进行模型推理:
prompt: 文本:使用地址:南强街88号院剧场 昆明市五华区南强街巷八十八号庭院剧场(北后街30号院,祥云街旁建行大楼背后),类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜'], output: ['戏剧演出']
prompt: 文本:海港区+电报山+泛美金字塔,旧金山中文专车行程自由灵活-浪琴石园-北滩-柯伊特塔,类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜'], output:
------------------------------------------
加载Lora2进行模型推理:
prompt: 文本:使用地址:南强街88号院剧场 昆明市五华区南强街巷八十八号庭院剧场(北后街30号院,祥云街旁建行大楼背后),类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜'], output: ['戏剧演出']
prompt: 文本:海港区+电报山+泛美金字塔,旧金山中文专车行程自由灵活-浪琴石园-北滩-柯伊特塔,类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜'], output: ['城市漫步', '建筑类体验']
------------------------------------------
仅使用基座模型推理:
prompt: 文本:使用地址:南强街88号院剧场 昆明市五华区南强街巷八十八号庭院剧场(北后街30号院,祥云街旁建行大楼背后),类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜'], output: </think>
建筑类体验
prompt: 文本:海港区+电报山+泛美金字塔,旧金山中文专车行程自由灵活-浪琴石园-北滩-柯伊特塔,类型选型:['历史文化类体验', '城市漫步', '建筑类体验', '戏剧演出', 服饰体验', '桑拿', '泡温泉', '洞穴探秘', '浮潜'], output: </think>
城市漫步在线服务
启动服务
请按照以下所示运行命令,启动服务,相关参数自行调整:
vllm serve --model meta-llama/Llama-3-8B --enable-lora \
--lora-modules adapter1=/path/to/adapter1 adapter2=/path/to/adapter2
本文运行的命令:
vllm serve Qwen3-1.7B --port 8000 --max-model-len 4096 --max-num-seqs 2 --gpu-memory-utilization 0.7 --enable-lora --lora-modules adapter1=checkpoint-100 adapter2=checkpoint-500
服务启动成功,启动日志如下:
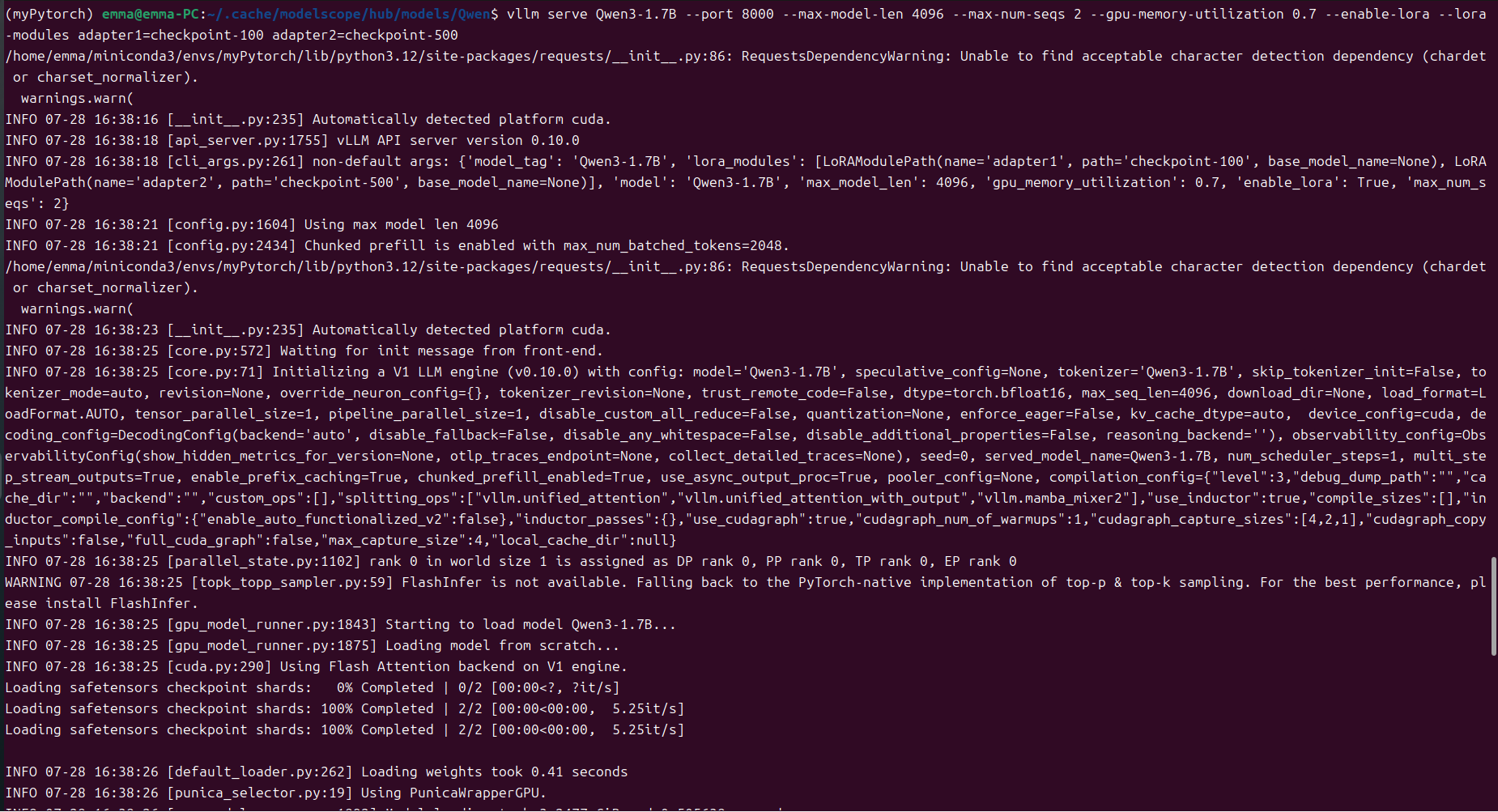
vllm serve Qwen3-1.7B --port 8000 --max-model-len 4096 --max-num-seqs 2 --gpu-memory-utilization 0.7 --enable-lora --lora-modules adapter1=checkpoint-100 adapter2=checkpoint-500
/home/emma/miniconda3/envs/myPytorch/lib/python3.12/site-packages/requests/__init__.py:86: RequestsDependencyWarning: Unable to find acceptable character detection dependency (chardet or charset_normalizer).
warnings.warn(
INFO 07-28 16:38:16 [__init__.py:235] Automatically detected platform cuda.
INFO 07-28 16:38:18 [api_server.py:1755] vLLM API server version 0.10.0
INFO 07-28 16:38:18 [cli_args.py:261] non-default args: {'model_tag': 'Qwen3-1.7B', 'lora_modules': [LoRAModulePath(name='adapter1', path='checkpoint-100', base_model_name=None), LoRAModulePath(name='adapter2', path='checkpoint-500', base_model_name=None)], 'model': 'Qwen3-1.7B', 'max_model_len': 4096, 'gpu_memory_utilization': 0.7, 'enable_lora': True, 'max_num_seqs': 2}
INFO 07-28 16:38:21 [config.py:1604] Using max model len 4096
INFO 07-28 16:38:21 [config.py:2434] Chunked prefill is enabled with max_num_batched_tokens=2048.
/home/emma/miniconda3/envs/myPytorch/lib/python3.12/site-packages/requests/__init__.py:86: RequestsDependencyWarning: Unable to find acceptable character detection dependency (chardet or charset_normalizer).
warnings.warn(
INFO 07-28 16:38:23 [__init__.py:235] Automatically detected platform cuda.
INFO 07-28 16:38:25 [core.py:572] Waiting for init message from front-end.
INFO 07-28 16:38:25 [core.py:71] Initializing a V1 LLM engine (v0.10.0) with config: model='Qwen3-1.7B', speculative_config=None, tokenizer='Qwen3-1.7B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend=''), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=Qwen3-1.7B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, pooler_config=None, compilation_config={"level":3,"debug_dump_path":"","cache_dir":"","backend":"","custom_ops":[],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output","vllm.mamba_mixer2"],"use_inductor":true,"compile_sizes":[],"inductor_compile_config":{"enable_auto_functionalized_v2":false},"inductor_passes":{},"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[4,2,1],"cudagraph_copy_inputs":false,"full_cuda_graph":false,"max_capture_size":4,"local_cache_dir":null}
INFO 07-28 16:38:25 [parallel_state.py:1102] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
WARNING 07-28 16:38:25 [topk_topp_sampler.py:59] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
INFO 07-28 16:38:25 [gpu_model_runner.py:1843] Starting to load model Qwen3-1.7B...
INFO 07-28 16:38:25 [gpu_model_runner.py:1875] Loading model from scratch...
INFO 07-28 16:38:25 [cuda.py:290] Using Flash Attention backend on V1 engine.
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:00<00:00, 5.25it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:00<00:00, 5.25it/s]
INFO 07-28 16:38:26 [default_loader.py:262] Loading weights took 0.41 seconds
INFO 07-28 16:38:26 [punica_selector.py:19] Using PunicaWrapperGPU.
INFO 07-28 16:38:26 [gpu_model_runner.py:1892] Model loading took 3.2477 GiB and 0.505638 seconds
INFO 07-28 16:38:31 [backends.py:530] Using cache directory: /home/emma/.cache/vllm/torch_compile_cache/66b490909a/rank_0_0/backbone for vLLM's torch.compile
INFO 07-28 16:38:31 [backends.py:541] Dynamo bytecode transform time: 5.14 s
INFO 07-28 16:38:35 [backends.py:161] Directly load the compiled graph(s) for dynamic shape from the cache, took 3.842 s
INFO 07-28 16:38:36 [monitor.py:34] torch.compile takes 5.14 s in total
INFO 07-28 16:38:37 [gpu_worker.py:255] Available KV cache memory: 7.47 GiB
INFO 07-28 16:38:37 [kv_cache_utils.py:833] GPU KV cache size: 69,888 tokens
INFO 07-28 16:38:37 [kv_cache_utils.py:837] Maximum concurrency for 4,096 tokens per request: 17.06x
Capturing CUDA graph shapes: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 11.65it/s]
INFO 07-28 16:38:37 [gpu_model_runner.py:2485] Graph capturing finished in 0 secs, took 0.14 GiB
INFO 07-28 16:38:37 [core.py:193] init engine (profile, create kv cache, warmup model) took 11.50 seconds
INFO 07-28 16:38:38 [loggers.py:141] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 4368
INFO 07-28 16:38:38 [serving_models.py:162] Loaded new LoRA adapter: name 'adapter1', path 'checkpoint-100'
INFO 07-28 16:38:38 [serving_models.py:162] Loaded new LoRA adapter: name 'adapter2', path 'checkpoint-500'
WARNING 07-28 16:38:38 [config.py:1528] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 07-28 16:38:38 [serving_responses.py:89] Using default chat sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 07-28 16:38:38 [serving_chat.py:122] Using default chat sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 07-28 16:38:38 [serving_completion.py:77] Using default completion sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 07-28 16:38:38 [api_server.py:1818] Starting vLLM API server 0 on http://0.0.0.0:8000
INFO 07-28 16:38:38 [launcher.py:29] Available routes are:
INFO 07-28 16:38:38 [launcher.py:37] Route: /openapi.json, Methods: GET, HEAD
INFO 07-28 16:38:38 [launcher.py:37] Route: /docs, Methods: GET, HEAD
INFO 07-28 16:38:38 [launcher.py:37] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 07-28 16:38:38 [launcher.py:37] Route: /redoc, Methods: GET, HEAD
INFO 07-28 16:38:38 [launcher.py:37] Route: /health, Methods: GET
INFO 07-28 16:38:38 [launcher.py:37] Route: /load, Methods: GET
INFO 07-28 16:38:38 [launcher.py:37] Route: /ping, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /ping, Methods: GET
INFO 07-28 16:38:38 [launcher.py:37] Route: /tokenize, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /detokenize, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/models, Methods: GET
INFO 07-28 16:38:38 [launcher.py:37] Route: /version, Methods: GET
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/responses, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/responses/{response_id}, Methods: GET
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/responses/{response_id}/cancel, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/chat/completions, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/completions, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/embeddings, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /pooling, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /classify, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /score, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/score, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/audio/transcriptions, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/audio/translations, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /rerank, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v1/rerank, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /v2/rerank, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /scale_elastic_ep, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /is_scaling_elastic_ep, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /invocations, Methods: POST
INFO 07-28 16:38:38 [launcher.py:37] Route: /metrics, Methods: GET
INFO: Started server process [21639]
INFO: Waiting for application startup.
INFO: Application startup complete.API调用(命令行调用)
调用基座模型,结果不符合预期
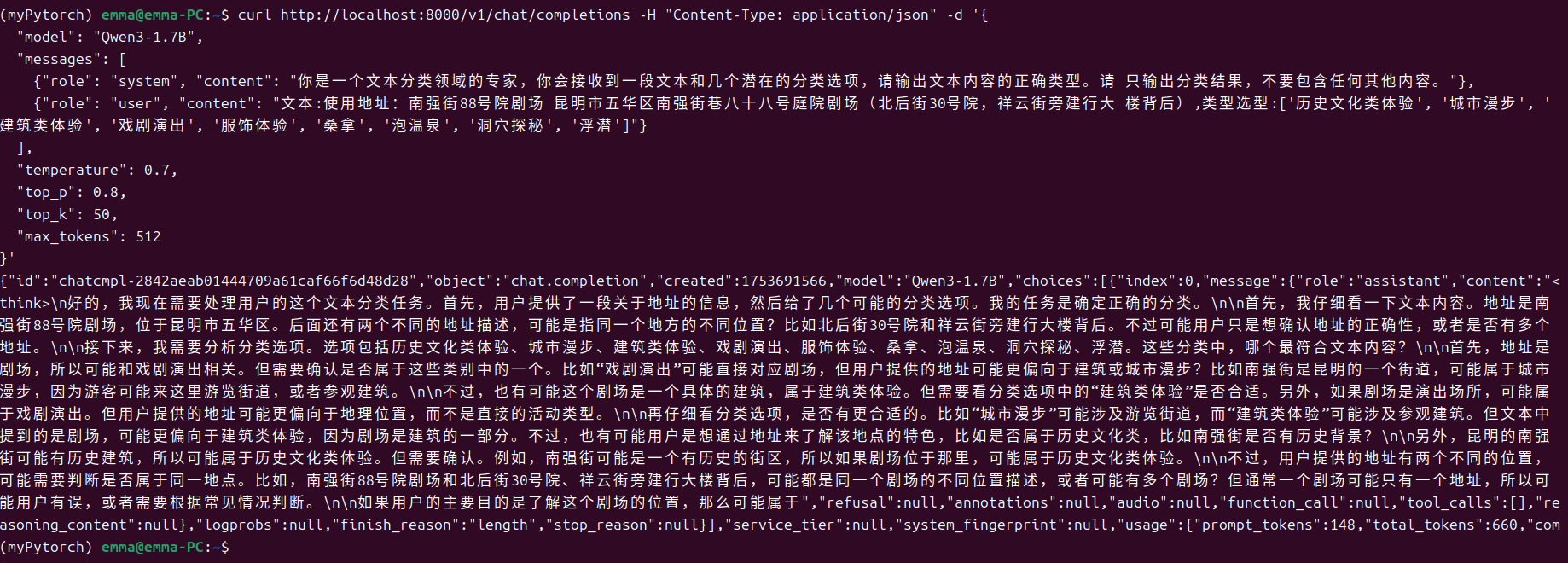
调用adapter1,使用的是微调step=100时的适配器,可以看出效果还不太好
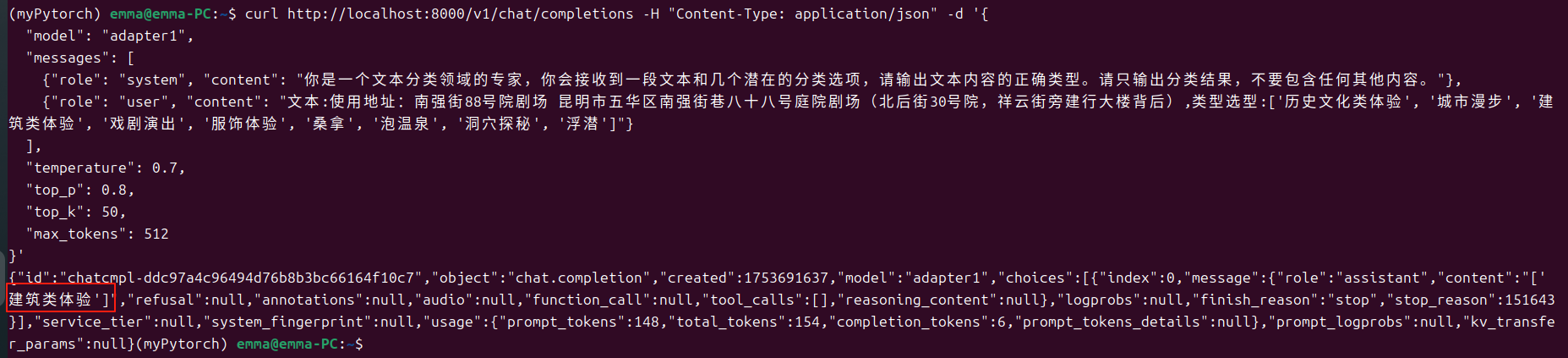
调用adapter2,使用的是微调step=500时的适配器,得到了正确答案


















&spm=1001.2101.3001.5002&articleId=149717122&d=1&t=3&u=8c0c27f7d0484e07ba9d53efa58218c5)
 4258
4258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









