




随着模型推理和知识能力的不断提升,更具挑战性的基准测试对于衡量和预测模型加速科学研究的能力至关重要。2025 年 12 月 16 日,OpenAI 推出了旨在衡量专家级科学能力的基准测试 FrontierScience。 根据初步评估,GPT-5.2 在 FrontierScience-Olympiad 和 Research 任务中分别得分 25% 和 77%,领先于其他前沿模型。
OpenAI 官方发文表示,「加速科学进步是人工智能造福人类最有希望的机会之一,因此我们正在改进我们在复杂数学和科学任务上的模型,并致力于开发能够帮助科学家最大限度地利用这些模型的工具。」
以往的科学基准测试大多侧重于选择题,要么题型过于密集,要么并非以科学为核心。而和过去已发布的基准测试相比,FrontierScience 由物理、化学和生物学领域的专家编写和验证,同时包含奥林匹克题型和研究类题型,能够双线衡量科学推理能力以及科学研究能力。 此外,FrontierScience-Research 包含 60 道原创研究子任务,由博士科学家设计,其难度与博士科学家在研究过程中可能遇到的难度相当。
对于基准测试的未来与局限,OpenAI 在官方报道中表示,「FrontierScience 具有范围较窄的局限性,无法涵盖科学家日常工作的全部内容。但该领域需要更具挑战性、更具原创性和更有意义的科学基准,而 FrontierScience 正是朝着这个方向迈出的一步。」
目前,该项目的论文成果已以「FrontierScience:evaluating AI’s ability to perform expert-level scientific tasks」为题发布。
论文地址:
https://hyper.ai/papers/7a783933efcc
更多论文:
查看更多 Benchmarks:

FrontierScience 数据集,实现「推理+科研」双行
在该项目中,研究团队构建了 FrontierScience 评测数据集,用于系统性评估大模型在专家级科学推理与科研子任务中的能力。数据集采用了「专家原创 + 双层任务结构 + 可自动评分机制」的设计机制,以形成同时具备挑战性、可扩展性与可重复性的科学推理评测基准。
数据集地址:
https://hyper.ai/datasets/47732
根据任务形式与评测目标的不同,FrontierScience 数据集被划分为两个子集,分别对应封闭式精确推理与开放式科研推理两类能力:
-
Olympiad 数据集:由国际物理、化学和生物奥林匹克竞赛的奖牌获得者及国家队教练原创设计,问题难度对标 IPhO、IChO 和 IBO 等国际顶级竞赛;聚焦短答案推理任务,要求模型输出单一数值、代数表达式或可模糊匹配的生物学术语,以保证结果的可验证性和自动评测的稳定性;
-
Research 数据集:由博士生、博士后及教授等在职科研人员撰写,题目模拟真实科研过程中可能遇到的子问题,覆盖物理、化学与生物三大领域。每道题目均配套 10 分制的细粒度评分,用于评估模型在答案正确性之外,在建模假设、推理路径与中间结论等多个关键环节的完成情况。
为确保问题的原创性和严谨性。研究团队在内部模型测试阶段对题目进行了筛选,并剔除已被现有模型轻易解决的问题,以降低评测饱和风险。训练任务总计会经历创建、审核、解决和修订 4 阶段,独立专家会相互审核各自的任务,以确保其符合标准。最终,团队从数百道候选问题中筛选出 160 道开源题目,其余题目则作为保留集,用于后续污染检测与长期评测。

评测任务确认流程
独立子集采样,GPT-5.2 等模型评分亮眼
为在不依赖外部检索的条件下,稳定、可重复地评估大模型的科学推理能力,研究团队设计了严格的评测流程和评分机制。
该研究选取了多款主流前沿大模型作为评测对象,涵盖不同机构和技术路线,以尽可能反映当前通用大模型在科学推理领域的整体能力水平。所有模型在评测过程中均禁用联网功能,确保模型输出仅基于其内部知识和推理能力,而不受实时信息检索或外部工具的影响, 从而降低不同模型在信息获取能力上的差异对结果的干扰。
考虑到大模型在生成式回答中存在一定随机性,研究团队对 Olympiad 和 Research 两个子集采用多次独立采样并取平均值的方式进行统计,以避免偶然性波动。在评分方式上,论文针对两类任务的不同特性,分别设计了可自动执行的评估策略:
-
FrontierScience-Olympiad 子集:强调封闭式推理,评分主要基于答案等价性判定,允许在合理误差范围内的数值近似、代数表达式的等价变换,以及生物学问题中对术语或名称的模糊匹配,避免对表达形式过度敏感;
-
FrontierScience-Research 子集:接近真实科研子任务,每道题目将科研推理过程拆解为多个独立、可核查的关键环节,模型的回答需逐项对照 rubric 进行评分,而非仅依据最终结论的正确与否。
从整体实验结果来看,FrontierScience 基准在两类任务上呈现出较为清晰的性能分化趋势。
在 Olympiad 子集上,多数前沿模型均取得了较高得分。其中,综合得分最好的模型前三名分别是 GPT-5.2、Gemini 3 Pro、Claude Opus 4.5,而 GPT-4o、OpenAI-o1 则表现较落后。 该研究指出指出,在这一类条件明确、推理路径相对封闭、答案可精确验证的问题中,大部分模型已经能够稳定完成复杂计算与逻辑推导,其整体表现已接近高水平人类解题者。
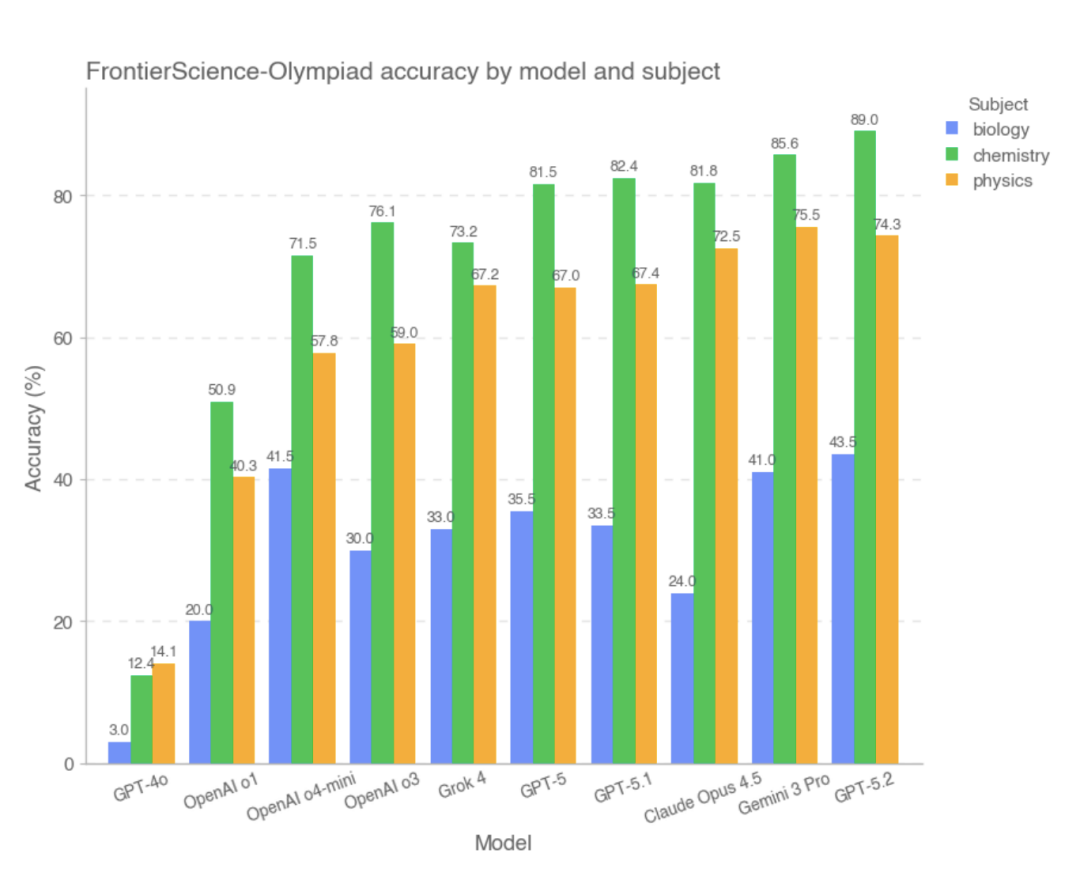
模型在 Olympiad 子集上的表现
然而,在 FrontierScience-Research 子集上,模型的整体得分明显偏低 。 在 Research 子集中,模型更容易在复杂科研问题的拆解阶段出现偏差, 例如对问题目标理解不完整、对关键变量或假设处理不当,或在较长推理链条中逐步累积逻辑错误。相较于奥赛式问题,大模型在面对更开放、更贴近真实科研流程的任务时,仍然存在明显能力差距。就实验数据来看,Research 部分表现较好的模型是 GPT-5、GPT-5.2 和 GPT-5.1。
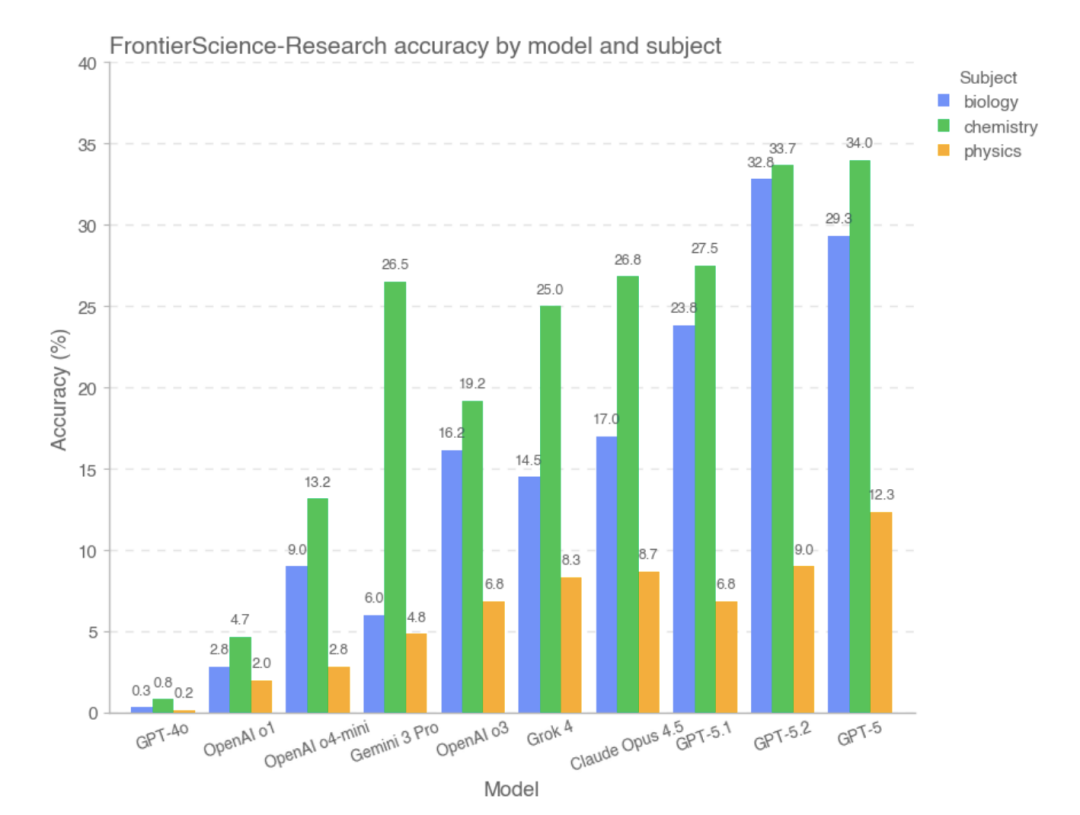
模型在 FrontierScience-Research 子集上的表现
该研究还比较了 GPT-5.2 和 OpenAI-o3 在 FrontierScience-Olympiad 和 FrontierScience-Research 两个测试集上不同推理强度下的准确率表现。结果显示,随着测试时 token 数量的增加,GPT-5.2 在 Olympiad 数据集的准确率从 67.5% 提升至 77.1%,在研究数据集上则从 18% 提升至 25%。 值得注意的是,在研究数据集上,o3 模型在高推理强度下的表现反而略逊于中等推理强度。
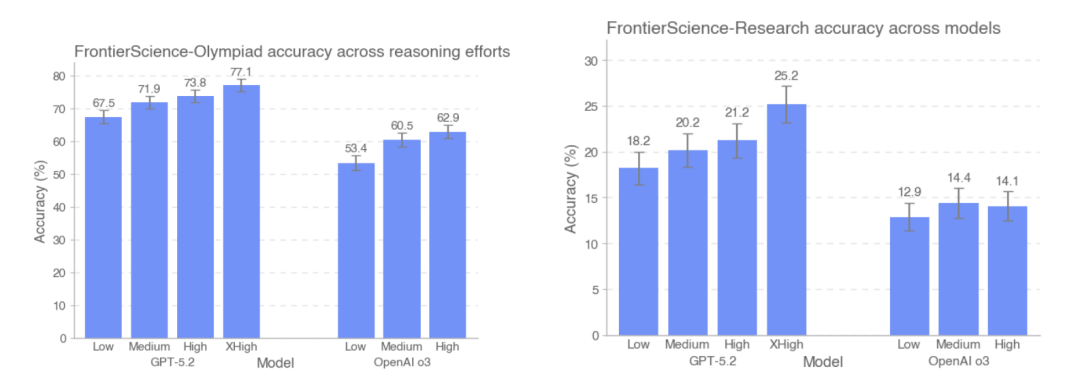
GPT-5.2 和 OpenAI-o3 模型对比
从 FrontierScience 的整体设计与实验结果来看,大模型已经能够在结构清晰、条件封闭的科学问题中稳定发挥,部分任务上的表现已接近人类专家水准; 但一旦进入需要持续建模、拆解问题并保持长链条推理一致性的科研子任务,其能力仍然存在明显限制。
在答案正确性之外,大模型迎来能力新标准
OpenAI 在官方解读中明确指出,FrontierScience 并不能覆盖科学家日常工作的全部维度,其任务形式依然以文本推理为主,尚未涉及实验操作、多模态信息或真实科研协作流程。然而,在现有科学评测普遍趋于饱和的背景下,FrontierScience 提供了一种更具挑战性和诊断价值的评估路径:不仅关注模型答案的正误,也开始系统性地衡量模型是否具备完成科研子任务的能力。从这个角度来看,FrontierScience 的价值并不只体现在排行榜本身,而在于它为后续模型改进和科学智能研究提供了新的参照坐标。随着模型推理能力的持续演进,这类强调原创性、专家参与和过程评估的基准,或将成为观察人工智能是否真正迈向科研协作阶段的重要窗口。
参考链接:
1.https://cdn.openai.com/pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/frontierscience-paper.pdf
2.https://openai.com/index/frontierscience/
3.https://huggingface.co/datasets/openai/frontierscience

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









