




传统的音频评估通常依赖于人工听评,其主观偏差性导致评估标准难以统一。而现有评估方法和工具虽然能够给出一定的评估结果,但大多仅聚焦于整体音频质量,缺乏对局部细节不足的针对性分析。
为此,Meta AI 推出了音频质量评估工具 Audiobox-Aesthetics,实现对语音、音乐和环境声音的多维度自动分析,通过 Production Quality 、 Production Complexity 、 Content Enjoyment 、 Content Usefulness 四个核心维度全面评估音频质量,不仅弥补了人工听评与现有工具的固有缺陷,更为音频创作者、工程师和研究人员提供专业级的量化分析,为音频优化提供精准导向。
公共数据集精选
1. Medical Information 药品信息数据集
Medical Information Dataset(简称 MID 数据集)是目前最大的、具有代表性的药品信息数据集。该数据集包含 44 个不同治疗类别的数据,涵盖超过 192,000 种药品,旨在提供准确、权威的药品信息、支持药物分类和治疗标签,提升临床试验管理的预测和效率。
直接使用:Medical Information 药品信息数据集 | 数据集 | HyperAI超神经
2.Nemotron-Math-HumanReasoning 数学推理数据集
Nemotron-Math-HumanReasoning 是由英伟达发布的一个数学推理数据集,旨在模拟 DeepSeek-R1 等模型的扩展推理风格。该数据集包含来自 OpenMathReasoning 数据集的 50 道数学题、 200 个人工撰写的解答,以及由 QwQ-32B-Preview 额外生成的 50 个解答。
直接使用:Nemotron-Math-HumanReasoning 数学推理数据集 | 数据集 | HyperAI超神经
3. Updesh 印度语合成文本数据集
Updesh 是由微软发布的一个印度语合成文本数据集,旨在推动针对印度语言的大型语言模型(LLMs)的后训练工作。该数据集包含 6,800,000 条推理数据及 2,100,000 条生成数据,其涉及的语言有阿萨姆语、孟加拉语等。
直接使用:Updesh 印度语合成文本数据集 | 数据集 | HyperAI超神经
4. QMOF150 量子化学数据集
QMOF150 是由 Meta 联合剑桥大学发布的一个量子化学数据集,旨在加速量子材料的发现。该数据集包含约 14,000 个金属有机框架(MOF)和配位聚合物。其中,经实验表征的 MOF 在通过 DFT 进行结构弛豫后,其计算属性被涵盖在内,这些属性包括但不限于优化的几何形状、能量、带隙、电荷密度、状态密度、部分电荷、自旋密度和键序。
直接使用:QMOF150 量子化学数据集 | 数据集 | HyperAI超神经
5. Safety Vests Detection 安全背心检测数据集
Safety Vests Detection 是一个安全背心检测数据集,旨在对新的对象检测架构进行基准测试(YOLOv8 、 Faster-RCNN 、 SSD 等)、相关 PPE 检测任务(头盔、手套、护目镜)的迁移学习和边缘部署安全监视器的原型开发,帮助开发和训练模型,自动识别和检测穿戴安全背心的人员,提高工作场所的安全性。该数据集包括 3,897 张高清照片、边界框注释以及图像环境。
直接使用:Safety Vests Detection 安全背心检测数据集 | 数据集 | HyperAI超神经

数据集示例
6. Open-Omega-Atom-1.5M 数学与科学推理数据集
Open-Omega-Atom-1.5M 是一个数学与科学推理数据集,旨在增强数学和科学领域的推理能力。该数据集包含了约 150 万条数据,专为数学、科学和代码应用设计,其中数学类数据在构成中占重要地位。
直接使用:Open-Omega-Atom-1.5M 数学与科学推理数据集 | 数据集 | HyperAI超神经
7. AF-Chat 音频对话文本数据集
AF-Chat 是由英伟达发布的一个音频对话文本数据集,旨在训练和评估对话生成模型。该数据集包含约 7.5 万个多回合、多音频对话(平均 4.6 个片段和 6.2 个回合;范围为 2-8 个片段和 2-10 个回合),涵盖语音、环境声音和音乐。
直接使用:AF-Chat 音频对话文本数据集 | 数据集 | HyperAI超神经
8. rStar Coder 竞赛级代码问题数据集
rStar Coder 是由微软发布的一个大规模竞赛级代码问题数据集,旨在增强大型语言模型的代码推理能力,尤其是在处理竞赛级代码问题方面。该数据集包含 41.8 万个竞赛级编程问题、 58 万个长推理解决方案以及丰富多样的测试用例(难度各异),每个解决方案都经过了不同难度级别的各种模拟测试用例的验证。
直接使用:rStar Coder 竞赛级代码问题数据集 | 数据集 | HyperAI超神经
9. Caselaw 法律文献数据集
Caselaw 是由多伦多大学发布的一个法律文献数据集,该数据集包含来自 Caselaw Access Project 和 Court Listener 的 670 万个案例。 Caselaw Access Project 和 Court Listener 从各种资源中获取法律数据,仅纳入了属于公共领域的文档,例如哈佛法律图书馆、国会法律图书馆和最高法院数据库。
直接使用:Caselaw 法律文献数据集 | 数据集 | HyperAI超神经
10. APM 蛋白质生成数据集
APM 是由湖南大学联合中国科学院大学、字节跳动 Seed 团队于 2025 年发布的一个蛋白质生成数据集,由单链蛋白质数据集和多链蛋白质数据集构成。
直接使用:APM 蛋白质生成数据集 | 数据集 | HyperAI超神经
公共教程精选
1. AudioBox-Aesthetics 音频美学评估 Demo
Audiobox-Aesthetics 是由 Meta AI 发布的音频质量评估工具。该工具基于深度学习技术,实现对语音、音乐和环境声音的多维度自动分析,通过四个核心维度全面评估音频质量,为音频创作者、工程师和研究人员提供专业级的量化分析。
在线运行:AudioBox-Aesthetics 音频美学评估 Demo | 教程 | HyperAI超神经
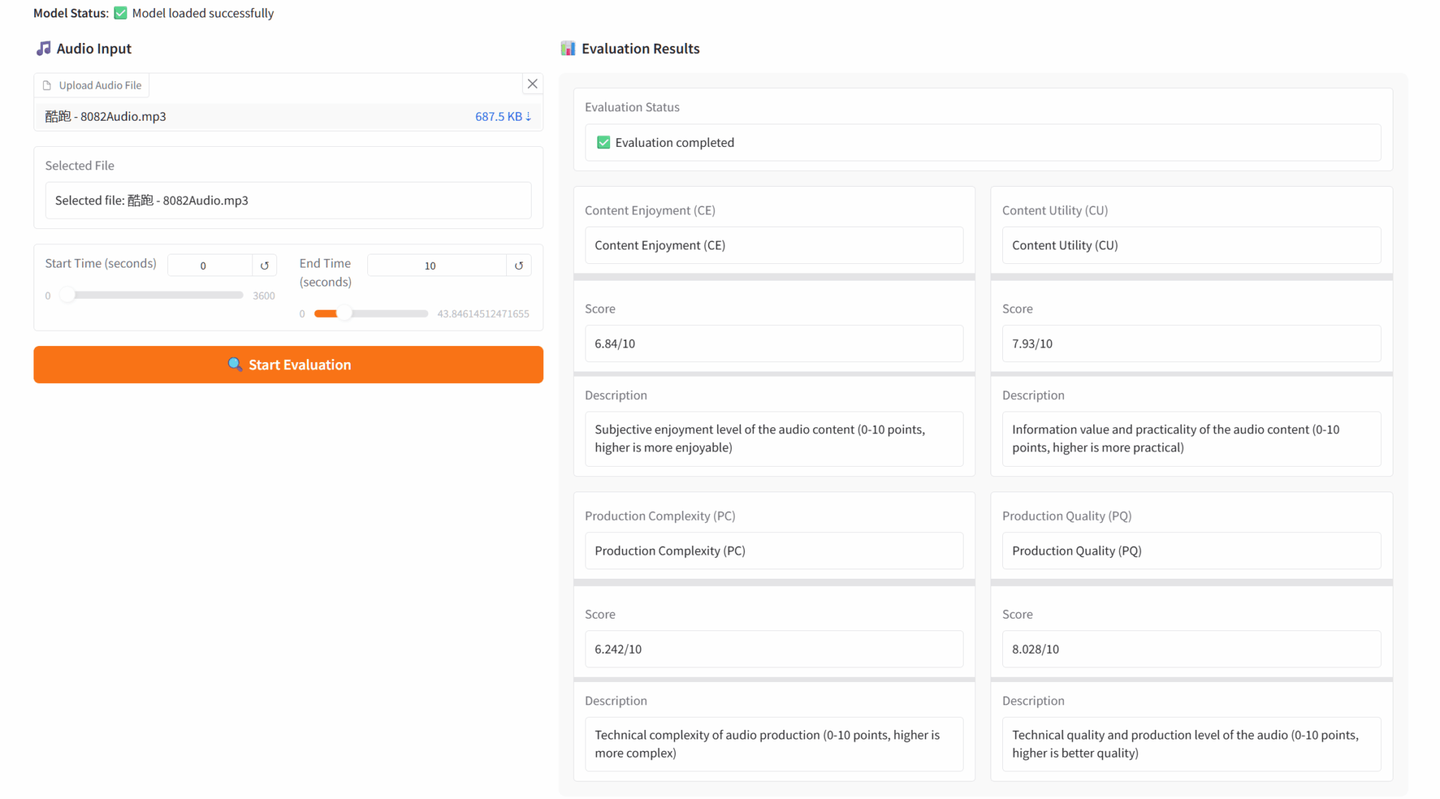
效果示例
2. LFM2-1.2B:高效边缘部署的文本生成模型
LFM2-1.2B 是由 Liquid AI 推出的第二代液体基础模型(LFMs),是一款基于混合架构的生成式 AI 模型。它以提供行业内最快的设备端生成式 AI 体验为目标,专为低延迟设备端语言模型工作负载设计。
在线运行:LFM2-1.2B:高效边缘部署的文本生成模型 | 教程 | HyperAI超神经
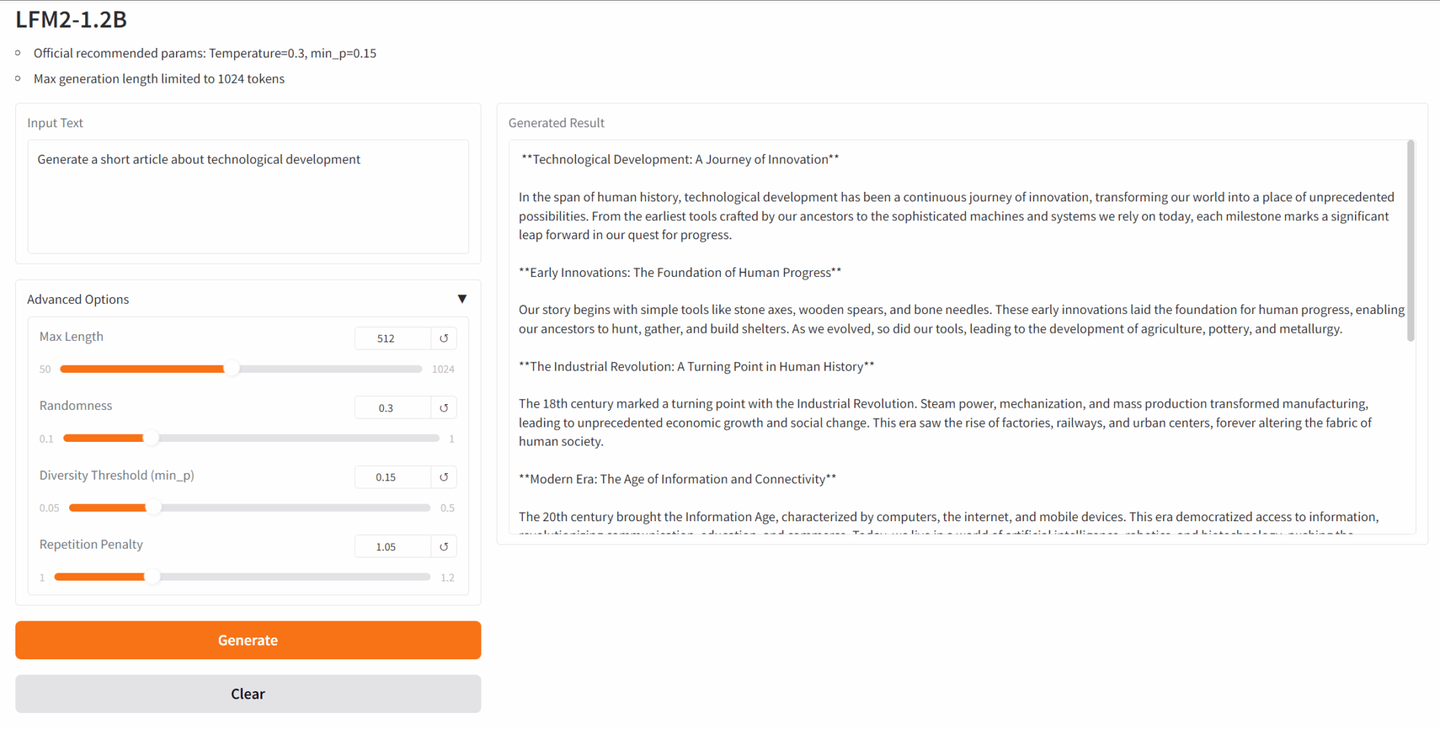
项目示例
3. Osmosis-Structure-0.6B:结构化输出的小语言模型
Osmosis-Structure-0.6B 是由 Osmosis 推出的一款专用型小型语言模型(SLM),旨在完成结构化输出生成任务。尽管其参数规模仅为 0.6B,但与支持的框架结合使用时,该模型在提取结构化信息方面展现出卓越的性能。
在线运行:Osmosis-Structure-0.6B:结构化输出的小语言模型 | 教程 | HyperAI超神经
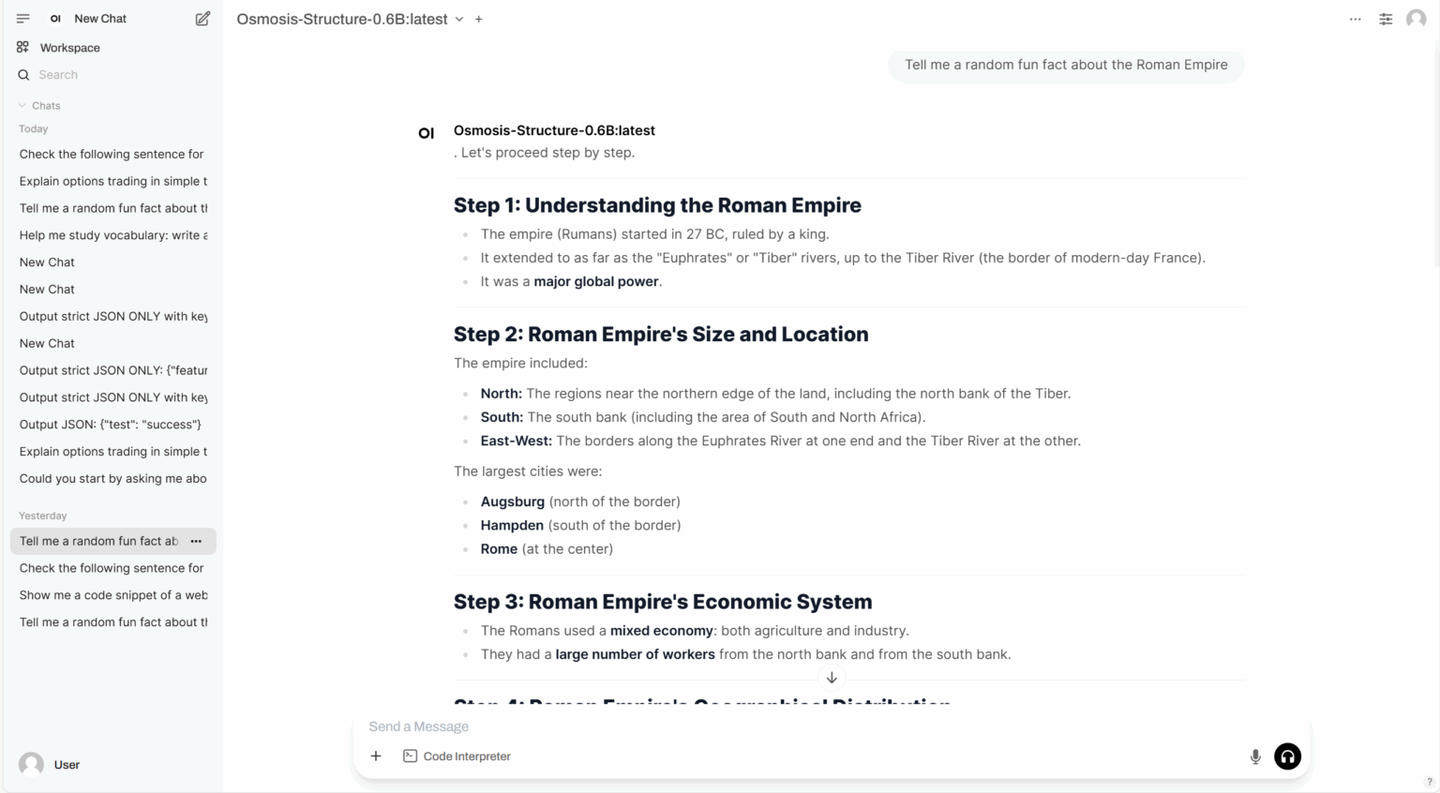
项目示例
4. MOSS:文本到口语对话生成
MOSS-TTSD 是由 OpenMOSS 团队发布的一个开源的双语口语对话合成模型,支持中文和英文。它能够将两位说话者之间的对话脚本转换为自然、富有表现力的对话语音。 MOSS-TTSD 支持语音克隆和长单段语音生成,使其成为 AI 播客制作的理想选择。
在线运行:MOSS:文本到口语对话生成 | 教程 | HyperAI超神经
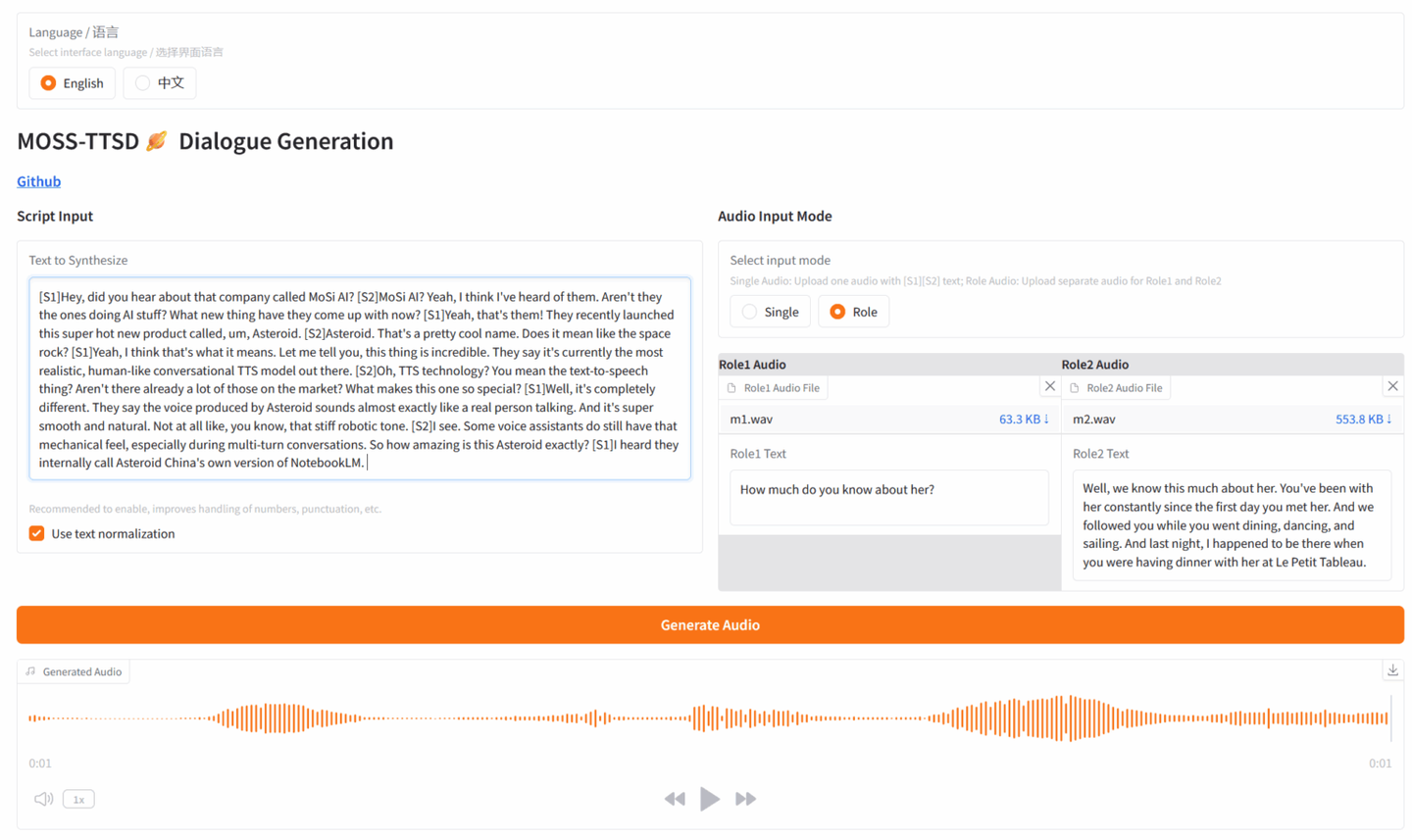
项目示例
5. isometric-skeumorphic-3d-bnb:等距 3D 风格图标生成
isometric-skeumorphic-3d-bnb 是由团体 multimodalart 发布的一款 LoRA 模型,主打生成兼具拟物化设计美感与风格化特质的 3D 等距图标。该模型在处理现实世界物体与建筑地标时表现突出,能将其转化为极具辨识度的图标风格插图。
在线运行:Isometric Skeumorphic 3d Bnb 文本到 3D 生成 | 教程 | HyperAI超神经

效果示例
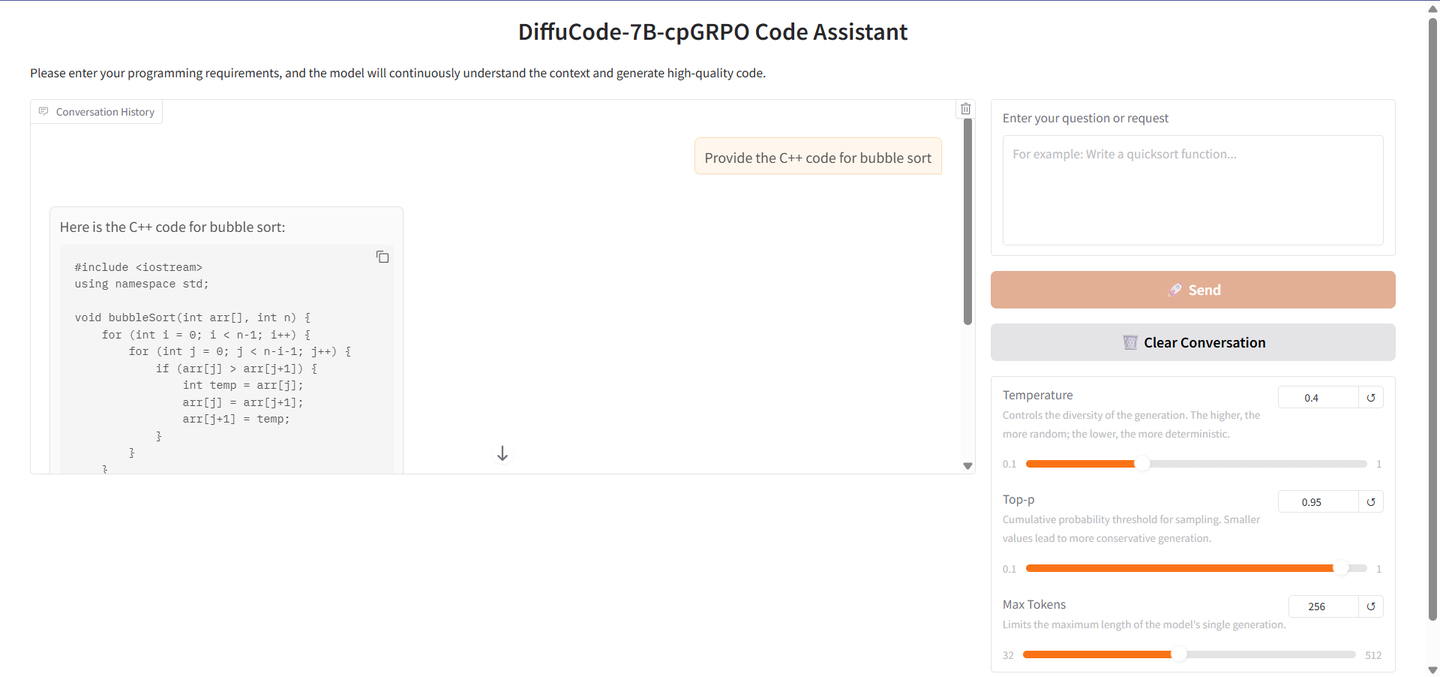
6. DiffuCode-7B-cpGRPO:基于掩码扩散技术的代码生成模型
DiffuCoder-7B-cpGRPO 是由 Apple 团队提出的一种基于掩码扩散(masked diffusion)的代码生成模型(dLLM)。该模型旨在通过迭代式降噪的方式进行代码的生成与编辑,而非传统的从左到右的自回归(Autoregressive)生成。
在线运行:DiffuCode-7B-cpGRPO:基于掩码扩散技术的代码生成模型 | 教程 | HyperAI超神经
项目示例
7. LAMMPS:以单晶铝为例,模拟材料单轴拉伸
LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator)是一种经典的分子动力学仿真代码,专注于材料建模。本次教程中通过改变材料的晶格常数,实现模拟对施加材料单轴应变的情况,后续再计算并绘制材料的应变应力曲线。
在线运行:LAMMPS:以单晶铝为例,模拟材料单轴拉伸 | 教程 | HyperAI超神经
8. Voxtral-Mini-3B-2507 语音理解模型 Demo
Voxtral 是由 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。该模型支持多语言、长文本上下文处理、内置问答和总结功能,能直接触发后端功能调用。 Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音交互的普及。
在线运行:Voxtral-Mini-3B-2507 语音理解模型 Demo | 教程 | HyperAI超神经
本周论文推荐
1. GUI-G^2: Gaussian Reward Modeling for GUI Grounding
人类点击行为自然地形成了以目标元素为中心的高斯分布,受此启发,本文引入了 GUI 高斯定位奖励(GUI-G^2),这是一种基于原理的奖励框架,将 GUI 元素建模为界面上的连续高斯分布。研究分析显示,连续建模提供了对界面变化更好的鲁棒性和对未见过布局更强的泛化能力,为 GUI 交互任务的空间推理建立了一个新的范式。
论文链接:GUI-G^2:用于 GUI 定位的高斯奖励建模 | 最新论文 | HyperAI超神经
2. MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization
大语言模型最近从流畅的文本生成发展到了跨多个领域的高级推理,从而产生了推理语言模型(Reasoning Language Models, RLMs)。为了促进 RLMs 开发的更高透明度,研究人员推出了 MiroMind-M1 系列,这是一组完全开源的 RLMs,基于 Qwen-2.5 框架构建,性能与现有的开源 RLMs 相当或超越。
论文链接:MiroMind-M1:通过上下文感知多阶段策略优化在数学推理领域的开源进展 | 最新论文 | HyperAI超神经
3.Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
大语言模型(LLMs)在上下文长度方面的限制制约了推理的准确性与效率,为突破这一限制,本文提出了线程推理模型(Thread Inference Model,TIM),这是一个专门用于递归和分解式问题求解的 LLM 系列。同时还提出了 TIMRUN,这是一个推理运行时环境,能够在超出上下文限制的情况下实现长视野的结构化推理。
论文链接:超越上下文限制:用于长时程推理的潜意识线索 | 最新论文 | HyperAI超神经
4. The Invisible Leash: Why RLVR May Not Escape Its Origin
本研究通过理论和实证分析提供了对 RLVR 潜在限制的新见解,揭示了 RLVR 在扩展推理边界方面的潜在局限性。打破这一隐形束缚可能需要未来的算法创新,例如显式探索机制或混合策略,将概率质量引入代表性不足的解空间区域。
论文链接:无形的牵引:为何RLVR可能无法摆脱其起源 | 最新论文 | HyperAI超神经
5. The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs
基于扩散的大规模语言模型(dLLMs)最近作为自回归大规模语言模型的强大替代方案崭露头角,通过并行解码和双向建模提供了更快的推理速度和更高的交互性。但现有的对齐机制无法保护 dLLMs 免受上下文感知的、带有掩码输入的对抗性提示攻击,暴露出新的漏洞。为此,本文提出了 DIJA,这是首个系统研究并构建针对 dLLMs 独特安全弱点的越狱攻击框架,强调了重新思考这一新兴语言模型类别的安全对齐机制的紧迫性。
论文链接:戴上面具的恶魔:扩散型LLM的安全漏洞问题 | 最新论文 | HyperAI超神经
更多 AI 前沿论文:最新论文 | HyperAI超神经
社区文章解读
1. 训练性能显著提升,字节跳动郑思泽详解 Triton-distributed 框架,实现大模型高效分布式通信与计算融合
在「Triton-distributed:原生 Python 编程实现高性能通信」主题演讲中,来自字节跳动的 Seed Research Scientist 郑思泽详细解析了 Triton-distributed 在大模型训练中的通信效率突破、跨平台适配能力,以及如何通过 Python 编程实现通信与计算的深度融合。
查看完整报道:训练性能显著提升,字节跳动郑思泽详解 Triton-distributed 框架,实现大模型高效分布式通信与计算融合 | 资讯 | HyperAI超神经
2. 数据降噪/生物信号强化/缓解 dropout,深度学习模型 SUICA 实现空间转录组切片中任一位置基因表达的预测
东京大学郑银强老师组,麦吉尔大学丁俊老师组共同提出了一种针对空间转录组数据建模的方法 SUICA,这是一个基于隐式神经表征和图自编码器的深度学习模型。结果证明,通过 SUICA 处理的空间转录组数据能够有更高的质量,更低的噪声和更强的生物信号。相关研究成果已入选 ICML 2025 。
查看完整报道:数据降噪/生物信号强化/缓解 Dropout,深度学习模型 SUICA 实现空间转录组切片中任一位置基因表达的预测 | 资讯 | HyperAI超神经
3. Tile 级原语与自动推理机制融合,TileAI 社区发起人深度剖析 TileLang 核心技术与优势
TileAI 社区发起人王磊博士以「Bridge Programmability and Performance in Modern AI Workloads」为题,深入浅出地介绍了创新的算子编程语言 TileLang,分享其核心设计理念与技术优势。
查看完整报道:Tile 级原语与自动推理机制融合,TileAI 社区发起人深度剖析 TileLang 核心技术与优势 | 资讯 | HyperAI超神经
4. 支持蛋白质生成/折叠/逆折叠,湖大/中科大/字节提出 APM 模型,实现全原子设计与功能优化
湖南大学联合中国科学院大学、字节跳动 Seed 团队提出了一种全新全原子蛋白质生成模型 APM(All-Atom Protein Generative Model),该模型整合原子级信息,支持多链蛋白质的生成、折叠、逆折叠任务,无需依赖伪序列的连接方式,在抗体设计、结合肽设计等下游任务中实现超越现有 SOTA 性能。
查看完整报道:支持蛋白质生成/折叠/逆折叠,湖南大学/中国科学院大学/字节跳动提出 APM 模型,实现全原子设计与功能优化 | 资讯 | HyperAI超神经
5. 基于超 176k 铭文数据,谷歌 DeepMind 发布 Aeneas,首次实现古罗马铭文的任意长度修复
谷歌 DeepMind 的研究人员联合诺丁汉大学、华威大学等高校在国际顶尖学术期刊 Nature 上发表了题为「Contextualizing ancient texts with generative neural networks」的研究论文,发布 Aeneas 首次实现古罗马铭文的任意长度修复。
查看完整报道:基于超 176k 铭文数据,谷歌 DeepMind 发布 Aeneas,首次实现古罗马铭文的任意长度修复 | 资讯 | HyperAI超神经
热门百科词条精选
1. DALL-E
2. 倒数排序融合 RRF
3. 帕累托前沿 Pareto Front
4. 大规模多任务语言理解 MMLU
5. 对比学习 Contrastive Learning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
8 月截稿顶会
8 月 1 日 7:59:59 INFOCOM 2026
8 月 1 日 7:59:59 KDD 2026
8 月 2 日 7:59:59 HPCA 2026
8 月 2 日 7:59:59 UbiComp 2025
8 月 2 日 11:59:59 VLDB 2026
8 月 2 日 19:59:59 AAAI 2026
8 月 7 日 7:59:59 NDSS 2026
8 月 21 日 11:59:59 ASPLOS 2026
8 月 27 日 7:59:59 USENIX Security Symposium 2025

















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









