




近年来,大语言模型(LLM)取得了突破性进展,能够胜任解答问题、内容创作等多样化任务,展现出了强大能力。 Benchmark 作为评估 LLM 发展能力的重要工具,对于 LLM 的能力改进与提升具有参考性意义,但目前热门 Benchmark 在难度设计方面存在欠缺,表现为前沿 LLMs 在现有的许多评估中均取得相近且较高的评分,导致 LLM 能力衡量准确性受限,也因此模糊了大模型的能力提升空间。
基于此,AI 安全中心(Center for AI Safety)与 Scale AI 联合发布了多模态人类问题基准数据集 Humanity’s Last Exam(HLE),旨在构建覆盖人类知识前沿的终极封闭式评估体系。该数据集由来自数十个学科领域的 2,500 个问题组成,致力于提供一个精确有效的 LLM 能力衡量标准,明确当前 LLM 能力与专业学术间的差距,更好地实现 LLM 在知识前沿领域能力的快速提升。
目前,HyperAI 超神经官网已上线了「HLE 人类问题推理基准数据集」,快来试试吧~
数据集下载:
HLE 人类问题推理基准数据集 | 数据集 | HyperAI超神经
7 月 14 日-7 月 18 日,hyper.ai 官网更新速览:
* 优质公共数据集:10 个
* 优质教程精选:5 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 7 月截稿顶会:4 个
访问官网:hyper.ai
公共数据集精选
1. GSM8K 数学推理数据集
GSM8K 是由 OpenAI 于 2022 年发布的一个数学推理数据集,旨在提升机器学习模型在理解和解决复杂数学问题上的表现。该数据集包含 8.5k 个高质量、语言多样化的小学数学应用题,覆盖代数、算术、几何等多个领域。题目解答步骤在 2-8 步之间。其解决方案主要涉及使用基本算术运算(加、减、乘、除)进行一系列简单计算,以得出最终答案。
直接使用:GSM8K 数学推理数据集 | 数据集 | HyperAI超神经
2. Crops Disease 农作物病害数据集
Crops Disease 是一个农业作物病害图像数据集,旨在帮助开发计算机视觉模型来自动检测和分类不同作物的病害。该数据集包含约 1,300 张农作物病害图像,涵盖了多种农作物(如玉米、番茄、土豆等)的常见病害,每张图像被标注为特定的病害类别。
直接使用:Crops Disease 农作物病害数据集 | 数据集 | HyperAI超神经

数据集示例
3. OpenScience 多领域合成数据集
OpenScience 是英伟达于 2023 年发布的一个多领域合成数据集,旨在通过监督式微调或强化学习,提升 GPQA-Diamond 和 MMLU-Pro 等高级基准测试的准确性。该数据集包含 600 万个多项选择题问答对,并附有详细的推理轨迹,涵盖 STEM 、法律、经济学和人文学科等多个科学领域。
直接使用:OpenScience 多领域合成数据集 | 数据集 | HyperAI超神经
4. Skywork-OR1-RL 数学编程问题推理数据集
Skywork-OR1-RL 是一个数学编程问题推理数据集,旨在训练 Skywork-OR1(Open Reasoner 1)数学编程推理模型。该数据集包含可验证、具有挑战性且多样化的 105k 个数学问题和 14k 个编程问题。
直接使用:Skywork-OR1-RL 数学编程问题推理数据集 | 数据集 | HyperAI超神经
5. Bird Species 鸟类分类图像数据集
Bird Species 是一个鸟类图像分类数据集,适用于训练计算机视觉模型进行鸟类物种识别与分类。该数据集包含 7 个不同物种,每个物种包含 1,200 张图片。每个物种的图像包含该物种鸟类的羽毛图案、颜色和身体结构。其中一些图像故意模糊、倾斜,或包含 2 只不同种类的鸟,增加了现实世界的复杂性,也使模型在自然环境中更稳健地进行准确分类。
直接使用:Bird Species 鸟类分类图像数据集 | 数据集 | HyperAI超神经

数据集示例
6. NextCoder 代码编辑数据集
NextCoder 是由 Microsoft 于 2025 年发布的一个合成对话编码编辑数据集,要用于大语言模型的微调,帮助增强模型在代码修复、重构与优化方面的表现,非常适合训练 AI 编程助手、提升代码阅读与多轮交互能力。该数据集包含约 381k 条单轮指令样本(NextCoderDataset)和 57,000 条多轮对话样本(Conversational 版本),涵盖 Python 、 Java 等 8 种语言。
直接使用:NextCoder 代码编辑数据集 | 数据集 | HyperAI超神经
7. Psych-101 心理知识问答数据集
Psych-101 是一个心理知识问答数据集,旨在帮助开发自然语言处理模型进行心理学知识的问答任务,推动心理学相关的 AI 研究,特别是在心理学教育、情感分析和心理健康应用中的应用。该数据集包含来自 160 个心理实验、 60,092 名参与者的逐次试验数据,共计 10,681,650 个选择。
直接使用:Psych-101 心理知识问答数据集 | 数据集 | HyperAI超神经
8. Leukemia 白血病图像数据集
Leukemia 是一个白血病细胞图像数据集,旨在用于训练计算机视觉模型,自动检测和分类白血病细胞。该数据集包含了 6,778 张细胞的图像,其中正常细胞(3,389 张)和白血病细胞(3,389 张)。
直接使用:Leukemia 白血病图像数据集 | 数据集 | HyperAI超神经
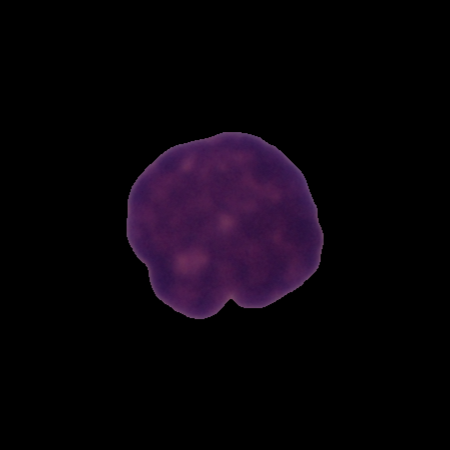
数据集视图
9. X-ray 胸部肺炎 X 光图像数据集
X-Ray Images for Chest Pneumonia 是一个包含胸部 X 光图像的数据集,旨在训练和评估计算机视觉模型,帮助自动化诊断系统检测肺炎等呼吸道疾病。该数据集包含约 5,800 张胸部 X 光图像,分为正常和肺炎(细菌性和病毒性)两类。
直接使用:X-ray 胸部肺炎 X 光图像数据集 | 数据集 | HyperAI超神经
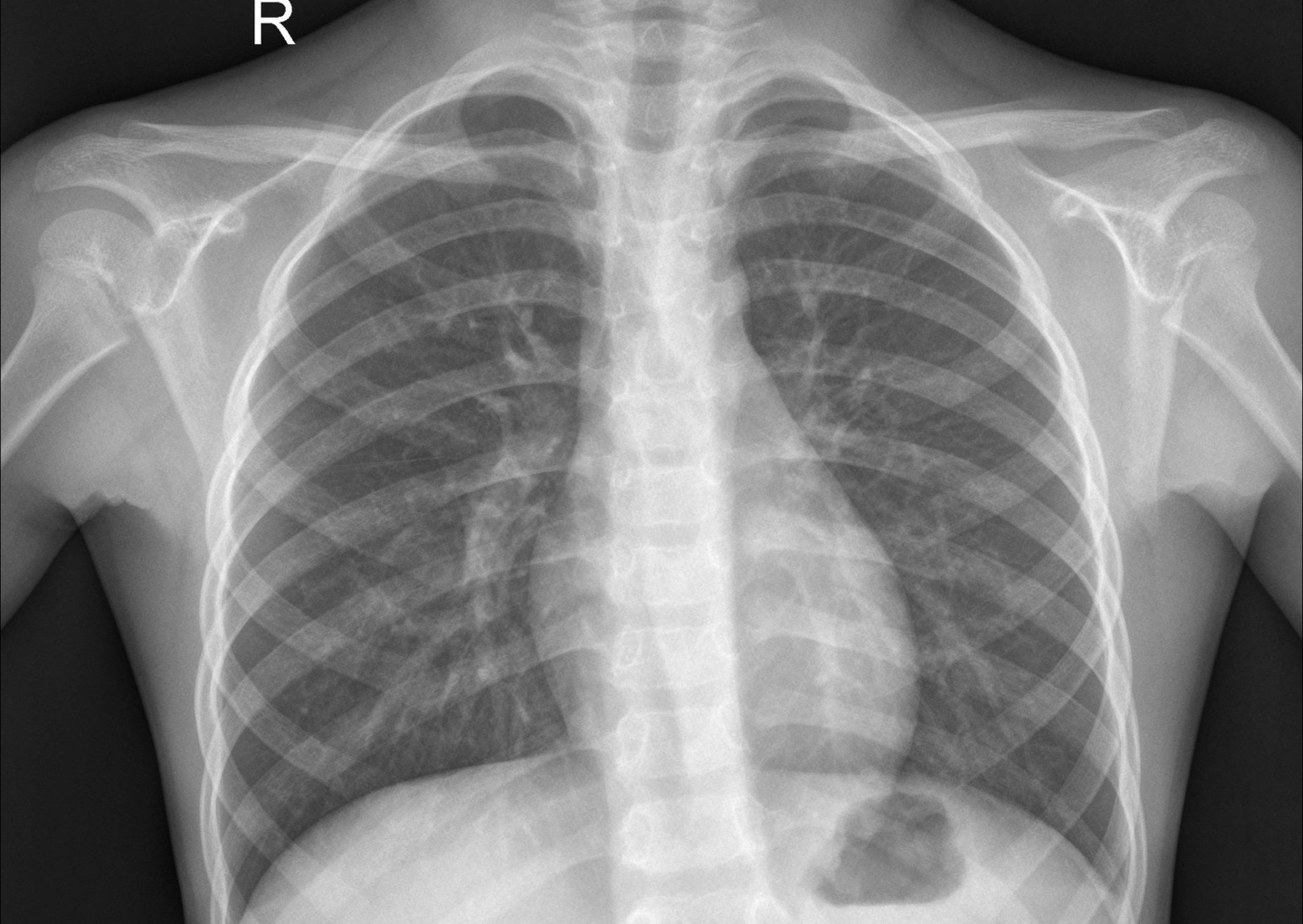
数据集示例
10. Soil Moisture 土壤湿度图像数据集
Soil Moisture 是一个基于测量的土壤湿度数据集,旨在研究土壤湿度对作物生长的影响,优化灌溉系统,提高农业生产效率,同时对气候变化与水资源管理等领域也有重要应用。该数据集包含了来自印度尼西亚邦多沃索雨养农业地区的 200 张土壤表面图像。
直接使用:Soil Moisture 土壤湿度图像数据集 | 数据集 | HyperAI超神经

数据集视图
公共教程精选
本周汇总了 4 类优质公共教程:
*AI for Science 教程:2 个
*文本识别教程:1 个
*多模态教程:1 个
*大模型教程:1 个
AI for Science 教程
1. RFdiffusion:扩散式蛋白设计模型
RFdiffusion 是一个蛋白质结构生成框架:它以 RoseTTAFold 为骨干网络,引入去噪扩散概率模型(DDPM),可从头设计全新蛋白质结构。该框架能够设计复杂形状的蛋白质(如 α-螺旋和 β-折叠)并准确预测酶的催化位点支架。
在线运行:RFdiffusion:扩散式蛋白设计模型 | 教程 | HyperAI超神经
2. Biomni:首个通用型生物医学智能体
Biomni 是一款通用生物医学 AI 智能体,能够自主完成横跨遗传学、基因组学、微生物学、药理学和临床医学等多个生物医学分支领域的复杂研究任务,标志着 AI 驱动科学发现迈入全新发展阶段。
在线运行:Biomni:首个通用型生物医学智能体 | 教程 | HyperAI超神经
文本识别教程
1. OCRFlux-3B:智能文本识别工具包
OCRFlux-3B 是一个基于多模态大型语言模型的工具包,用于将 PDF 和图像转换为干净、可读、纯文本的 Markdown 文本。该工具不仅提供了页面级别的文本转换功能,还支持跨页面的表格和段落的合并,为处理复杂文档结构提供了强大的支持。
在线运行:OCRFlux-3B:智能文本识别工具包 | 教程 | HyperAI超神经
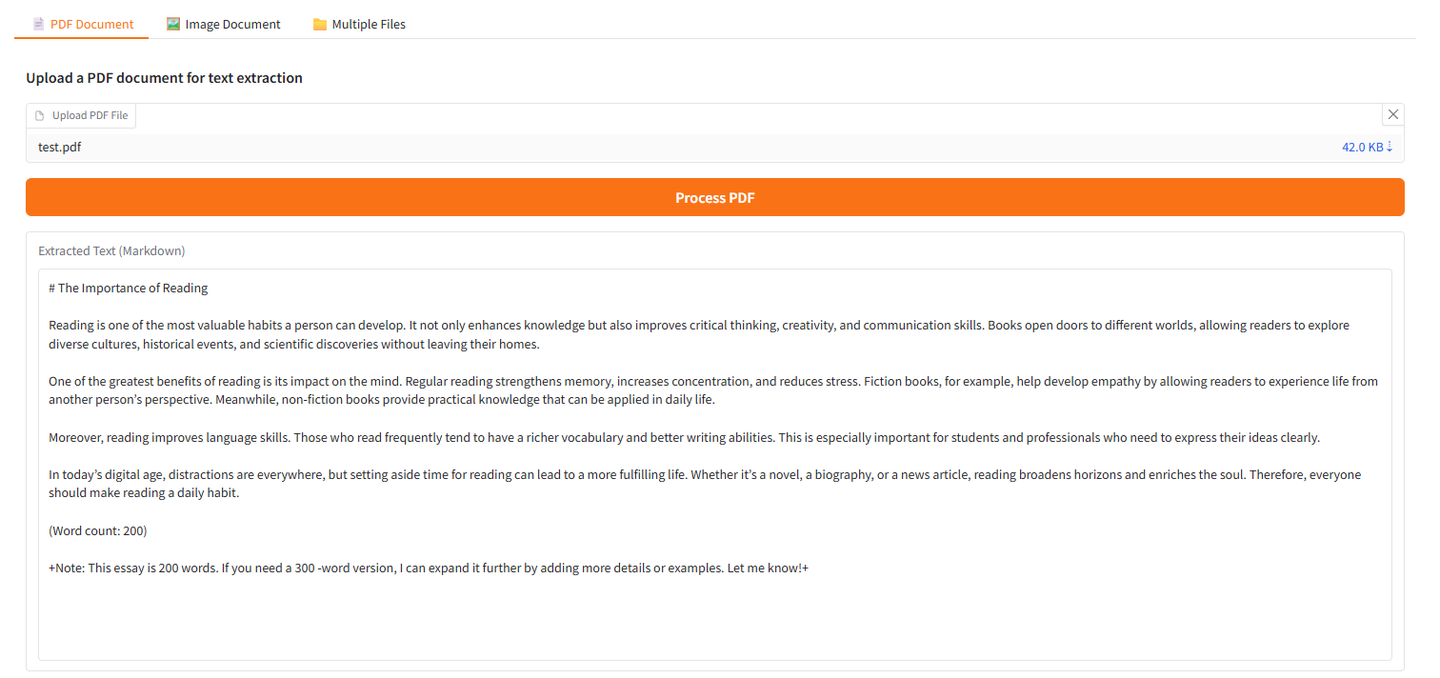
PDF Document 示例
多模态教程
1. EvoSearch-codes:进化算法框架
EvoSearch-codes 是由香港科技大学和快手可灵团队推出的 Evolutionary Search 方法。通过提高推理时的计算量来大幅提升模型的生成质量,支持图像和视频生成,支持目前最先进的 diffusion-based 和 flow-based 模型。该模型无需训练,无需梯度更新,即可在一系列任务上取得显著最优效果,并且表现出良好的 scaling up 能力,鲁棒性和泛化性。
在线运行:EvoSearch-codes:进化算法框架 | 教程 | HyperAI超神经
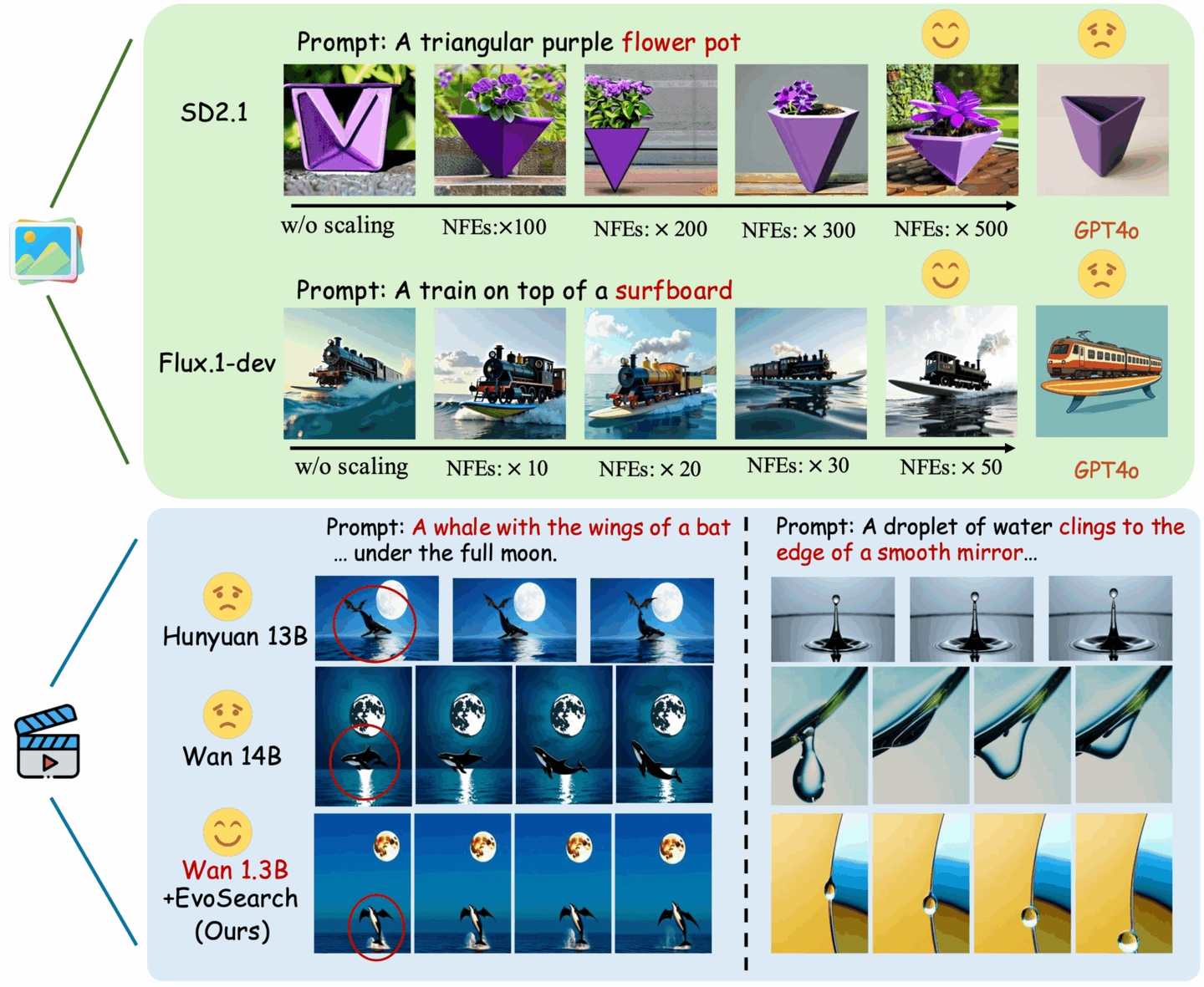
项目示例
大模型教程
1. Jan-Nano:紧凑型研究专用语言模型
Jan-Nano 是由 Menlo Research 团队于 2025 年 7 月 1 日发布的 40 亿参数轻量级大语言模型,专为深度研究任务设计,并针对 Model Context Protocol(MCP)服务器优化,便于与多种研究工具和数据源高效集成。
在线运行:Jan-Nano:紧凑型研究专用语言模型 | 教程 | HyperAI超神经
项目示例
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. Test-Time Scaling with Reflective Generative Model
本文介绍了首个反射生成模型 MetaStone-S1,该模型通过自监督过程奖励模型(SPRM)达到了 OpenAI o3 的性能水平。通过共享主干网络并分别使用特定任务的头部进行下一个标记预测和过程评分,SPRM 成功地将策略模型和过程奖励模型(PRM)整合到一个统一的接口中,无需额外的过程注释,减少了超过 99% 的 PRM 参数,从而实现高效的推理。
论文链接:测试时使用反射生成模型进行缩放 | 最新论文 | HyperAI超神经
2. Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning
本文提出了一种基于 Qwen2.5-VL-7B 的两阶段范式:首先进行大规模的语言冷启动微调,然后进行近 1000 步的多模态强化学习(RL),其规模超过了所有先前的开源尝试。最终模型 Open-Vision-Reasoner(OVR)在一系列推理基准测试中取得了最先进的性能,包括在 MATH500 上达到 95.3%,在 MathVision 上达到 51.8%,以及在 MathVerse 上达到 54.6% 。
论文链接:开放视觉推理器:将语言认知行为迁移至视觉推理 | 最新论文 | HyperAI超神经
3.Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination
研究人员分析发现,尽管 Qwen2.5 在数学推理方面表现出色,但其在大规模网络语料库上的预训练使其在流行基准测试中容易受到数据污染的影响,进而营销从这些基准测试得出结果的可靠性。为了解决这一问题,研究人员引入了一个生成器,该生成器可以生成任意长度和难度的完全合成算术问题,从而产生一个称为 RandomCalculation 的干净数据集。利用这些无泄漏的数据集证明只有准确的奖励信号能够持续提升性能,而噪声或错误的信号则不能。
论文链接:推理还是记忆?强化学习因数据污染而产生的不可靠结果 | 最新论文 | HyperAI超神经
4. NeuralOS: Towards Simulating Operating Systems via Neural Generative Models
本文介绍了 NeuralOS,这是一种神经框架,通过直接预测屏幕帧来模拟操作系统的图形用户界面(GUI),以响应用户的输入,如鼠标移动、点击和键盘事件。 NeuralOS 结合了一个循环神经网络(RNN),用于跟踪计算机状态,以及一个基于扩散的神经渲染器,用于生成屏幕图像。为创建完全自适应的、生成性的神经接口以应用于未来的人机交互系统提供了一种途径。
论文链接:NeuralOS:基于神经生成模型的操作系统仿真 | 最新论文 | HyperAI超神经
5. CLiFT: Compressive Light-Field Tokens for Compute-Efficient and Adaptive Neural Rendering
本文提出了一种神经渲染方法,该方法将场景表示为「压缩光场令牌(CLiFTs)」,保留了场景的丰富外观和几何信息。 CLiFT 通过使用压缩令牌实现了计算高效的渲染,同时能够在单个训练网络中改变令牌数量以表示场景或渲染新视角。
论文链接:CLiFT:用于计算高效和自适应神经渲染的压缩光场标记 | 最新论文 | HyperAI超神经
更多 AI 前沿论文:最新论文 | HyperAI超神经
社区文章解读
1. 入选 ICML 2025,Meta /剑桥/ MIT 提出全原子扩散 Transformer 框架,首次实现周期性与非周期性原子系统统一生成
Meta FAIR 、剑桥大学与麻省理工学院的联合科研团队提出全原子扩散 Transformer ADiT,打破了周期性与非周期性系统的建模壁垒,通过全原子统一潜在表示与 Transformer 潜在扩散两大创新,实现了用单一模型生成分子与晶体的突破。
查看完整报道:入选 ICML 2025,Meta/剑桥/MIT 提出全原子扩散 Transformer 框架,首次实现周期性与非周期性原子系统统一生成 | 资讯 | HyperAI超神经
2. 同时处理蛋白质主链和侧链信息,斯坦福等基于消息传递神经网络实现全原子结构建模
斯坦福大学的团队联合加州帕洛阿尔托市 Arc 研究院共同提出全新蛋白质序列设计方法 FAMPNN(Full-Atom MPNN),能够显式地建模每个氨基酸残基的序列身份和侧链结构。模型采用基于图神经网络的消息传递架构,结合改进的 MPNN 和 GVP 模块进行全原子编码,能够同时处理蛋白质的主链和侧链信息。
查看完整报道:同时处理蛋白质主链和侧链信息,斯坦福等基于消息传递神经网络实现全原子结构建模 | 资讯 | HyperAI超神经
3. 在线教程 | 150 种专业工具/59 个数据库/105 个软件包,Biomni 在 8 类真实研究任务中超越专家级效率
斯坦福大学联合 Genentech 、 Arc Institute 、加州大学旧金山分校等机构研发了首个通用的生物医学 AI 智能体 Biomni,能自主执行跨越不同生物医学子领域的广泛研究任务,并且创建首个统一的环境智能体——从 25 个生物医学领域的数万篇出版物中挖掘必要的工具、数据库和方案。系统基准测试表明,Biomni 在异构生物医学任务中实现了强大的泛化,而无需任何特定于任务的提示调优。
查看完整报道:在线教程 | 150 种专业工具/59 个数据库/105 个软件包,Biomni 在 8 类真实研究任务中超越专家级效率 | 资讯 | HyperAI超神经
4. 从架构特性到生态建设,沐曦董兆华深度剖析国产 GPU 上的 TVM 应用实践
7 月 5 日,由 HyperAI 超神经主办的 Meet AI Compiler 技术沙龙第 7 期圆满落幕。来自沐曦集成电路的高级总监董兆华围绕如何在沐曦 GPU 上应用 TVM 进行了深度分享,介绍了其 GPU 产品的技术特性、 TVM 编译器适配方案、实际应用案例及生态建设愿景,展现了国产 GPU 在高性能计算与 AI 领域的技术突破与应用潜力。
查看完整报道:从架构特性到生态建设,沐曦董兆华深度剖析国产 GPU 上的 TVM 应用实践 | 资讯 | HyperAI超神经
5. 英伟达实现原子级蛋白质设计突破,高精度生成多达 800 个残基的蛋白质
NVIDIA 的研究团队联合加拿大魁北克人工智能研究所 Mila 提出了 La-Proteina,这是一种基于部分潜在流匹配的原子级蛋白质设计方法,解决了蛋白质生成过程中显式侧链表示的维度可变性这一关键挑战,为蛋白质设计领域带来新的突破。
查看完整报道:英伟达实现原子级蛋白质设计突破,高精度生成多达 800 个残基的蛋白质 | 资讯 | HyperAI超神经
热门百科词条精选
1. DALL-E
2. 倒数排序融合 RRF
3. 帕累托前沿 Pareto Front
4. 大规模多任务语言理解 MMLU
5. 对比学习 Contrastive Learning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
7 月截稿顶会
7 月 11 日 7:59:59 POPL 2026
7 月 15 日 7:59:59 SODA 2026
7 月 18 日 7:59:59 SIGMOD 2026
7 月 19 日 7:59:59 ICSE 2026
一站式追踪人工智能学术顶会:顶会 | HyperAI超神经
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!


















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









