




 本文介绍了Pandas中的对齐运算,包括如何避免产生NAN值的相加,以及混合运算中的广播机制。同时,讲解了函数的应用,如applymap()和apply()在列或行上的应用。此外,还涉及了排序、丢弃和填充缺失数据、层级索引的操作,以及统计计算和描述性统计量的计算方法。
本文介绍了Pandas中的对齐运算,包括如何避免产生NAN值的相加,以及混合运算中的广播机制。同时,讲解了函数的应用,如applymap()和apply()在列或行上的应用。此外,还涉及了排序、丢弃和填充缺失数据、层级索引的操作,以及统计计算和描述性统计量的计算方法。
对齐运算
对Series或者DataFrame直接进行相加,会产生一个并集,相同的序列相加,不同的序列为NAN。

如果不想要产生NAN,而是使用填充值,则需要使用方法,并传入参数fill_value = 0:

DataFrame和Series相同
- add 加
- radd 加(反转参数)

注意,reindex不会影响原来的对象,而是会返回一个新对象
混合运算
广播机制


如果想要在列方向进行运算,需要使用方法,传入指定轴:
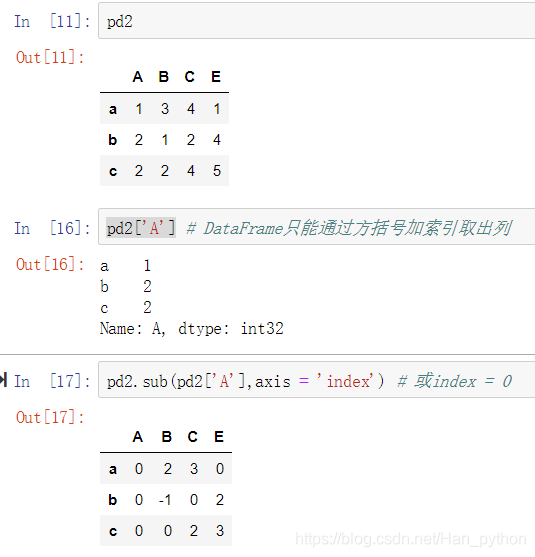
函数的应用
numpy的函数pandas都能用,除此之外还有一些函数:
通过apply将函数应用到列或者行:
- apply()函数,默认是在列方向
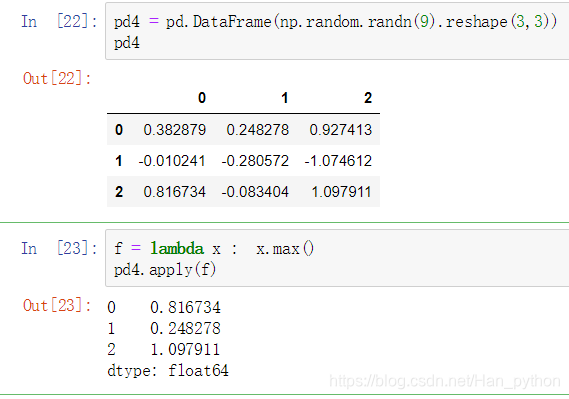
pd4.apply(f,axis = 1)
applymap()
通过applymap将函数应用到每个数据上
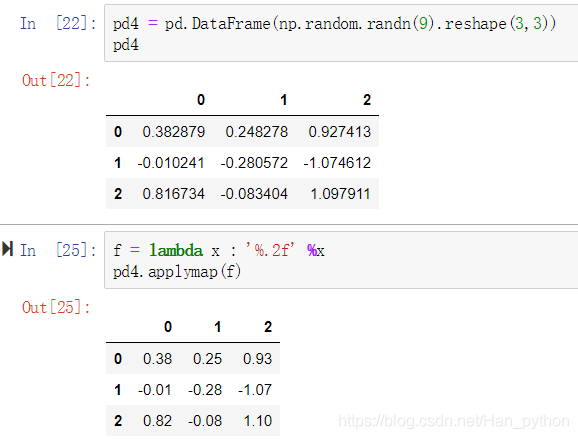
排序
- 按索引排序sort_index()
s1.sort_index() #默认升序
s1.sort_index(ascending = False) #降序
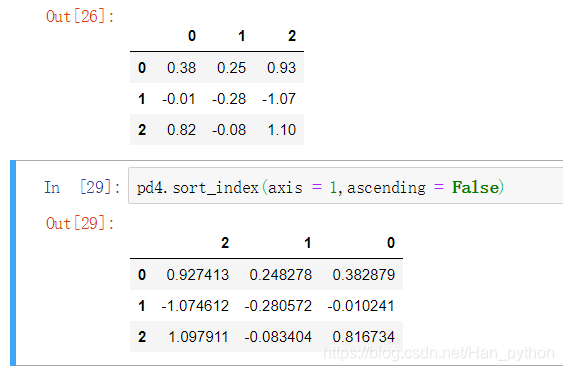
- 按照值排序 sort_values()
默认从小到大排序,当有缺失值的时候,默认排在最后
对DataFrame使用sort_values()方法,需要传入指定的列 by = x:
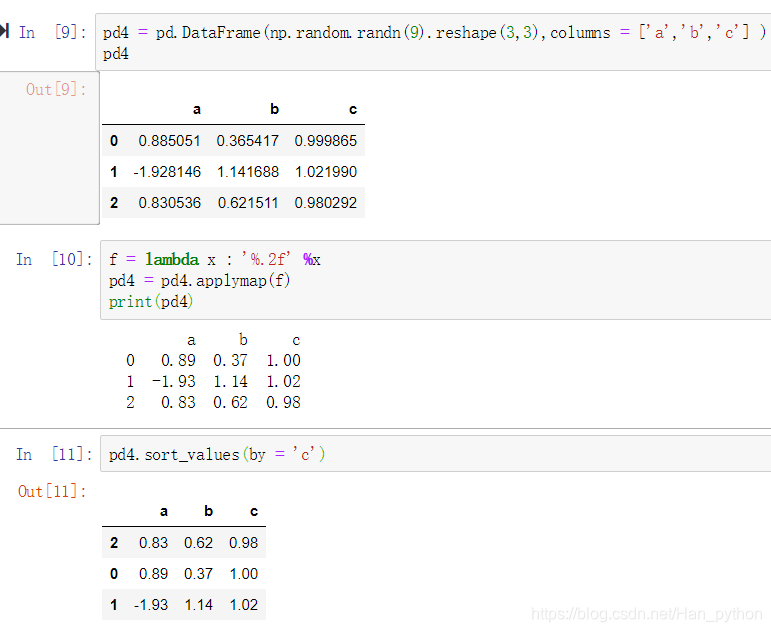
唯一值
s2 = s1.unique() #返回一个唯一值数组
值的个数
s1.value_counts()
判断是否存在
s2.isin([8,2]) #判断8或者2是否在s1
丢弃缺失数据
pd1.dropna() # 默认丢弃行
pd1.dropna(axis = 1) #丢弃列
填充缺失数据 fillna()
pd1.fillna(2) #将指定数据填入缺失值
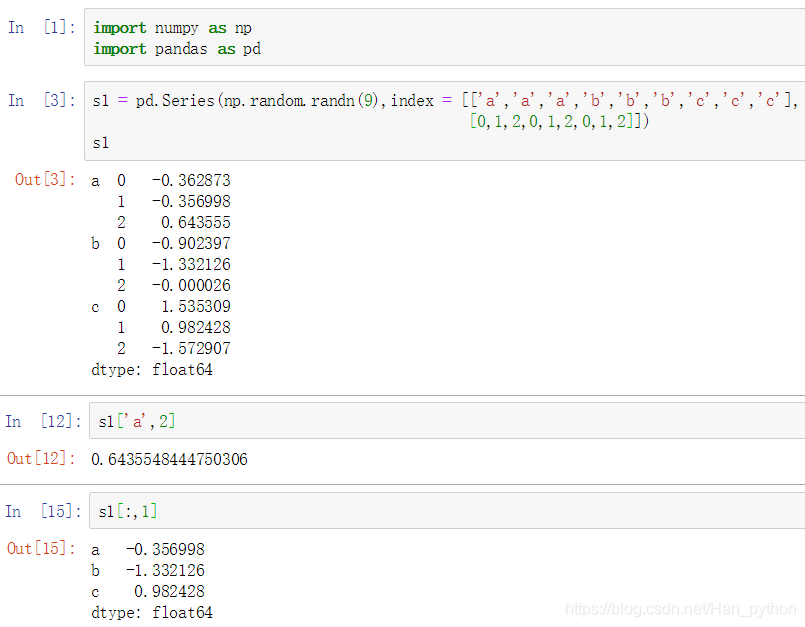
层级索引
生成和取值
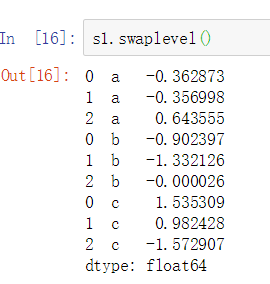
交换层级
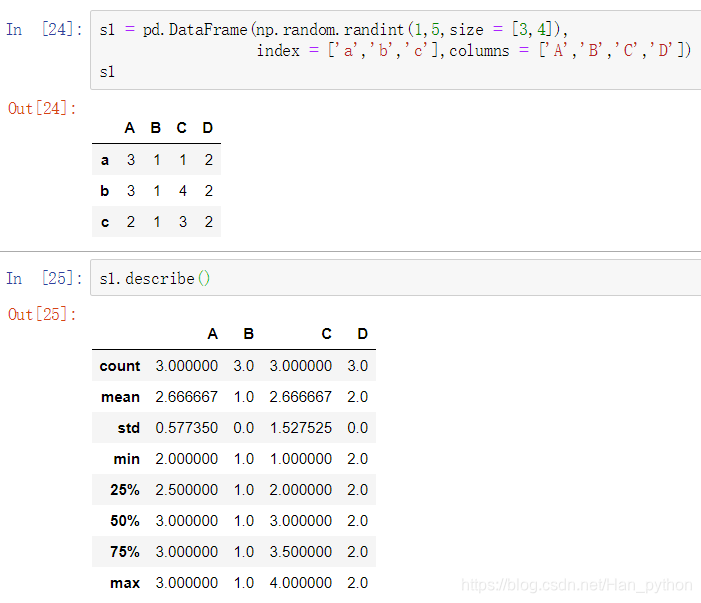
统计计算和描述
- pd1.sum() 求和,默认按列求和
- pd1.sum(axis = 1) 按照行求和
- pd1.sum(skipna = False) 不排除空值
- pd1.idxmax() 返回最大值的索引
- pd1.cumsum() 累计求和
- pd1.describe() 显示汇总统计

















 3701
3701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









