



论文介绍
题目:WDMamba: When Wavelet Degradation Prior Meets Vision Mamba for Image Dehazing
论文地址:https://arxiv.org/pdf/2505.04369

关注、星标公众号,精彩内容每日送达
来源:网络素材创新点
🌫️ 一、首次提出“波⽂退化先验”用于图像去雾(Wavelet Degradation Prior)
论文通过对雾图与清晰图的小波变换分析,发现:
雾霾退化主要集中在低频子带,而高频子带保留更多纹理细节。
基于此,作者将图像去雾任务分解为:
低频结构还原(移除大范围雾气)
高频细节增强(恢复细节与清晰度)
这一“粗到细”的策略是此前去雾方法未涉及的,有效减少了雾气在图像结构中的干扰。
⚙️ 二、引入 Mamba State Space 模型进行低频建模(首用于图像去雾)
在低频阶段,提出 Low-Frequency Restoration Network (LFRN):
使用 Vision Mamba Block 建模低频子带图像的全局结构。
具备类似Transformer的全局建模能力,但计算复杂度为线性,比Transformer更高效。
是首个将Mamba结构引入图像去雾任务的方法,展示了其对大范围图像退化建模的优势。
🧠 三、提出自引导对比正则化机制(Self-Guided Contrastive Regularization, SGCR)
在训练阶段:
使用中间的“粗去雾图像”作为 hard negative sample。
与GT(正样本)进行对比学习,促使网络生成更加自然、真实的最终图像。
与传统对比正则化相比,无需额外模型或采样技巧,并能显著提升细节表现力与稳定性。
方法
整体架构
WDMamba 是一个面向图像去雾任务的粗到细两阶段深度学习框架,整体结构由三部分组成:首先通过小波变换提取图像的低频子带,并由基于 Vision Mamba 的低频重建网络(LFRN)高效建模全局结构,实现雾霾的初步去除;随后将粗略图像输入细节增强网络(DEN),借助 CNN 与频域增强模块恢复高频纹理细节;在训练过程中,模型还引入自引导对比正则化(SGCR),以粗图像作为“难负样本”指导网络生成更自然真实的最终图像,从而实现高质量、低计算量的图像去雾效果。

1️⃣ Low-Frequency Restoration Network(LFRN)
👉 结构建模阶段,解决全局雾气
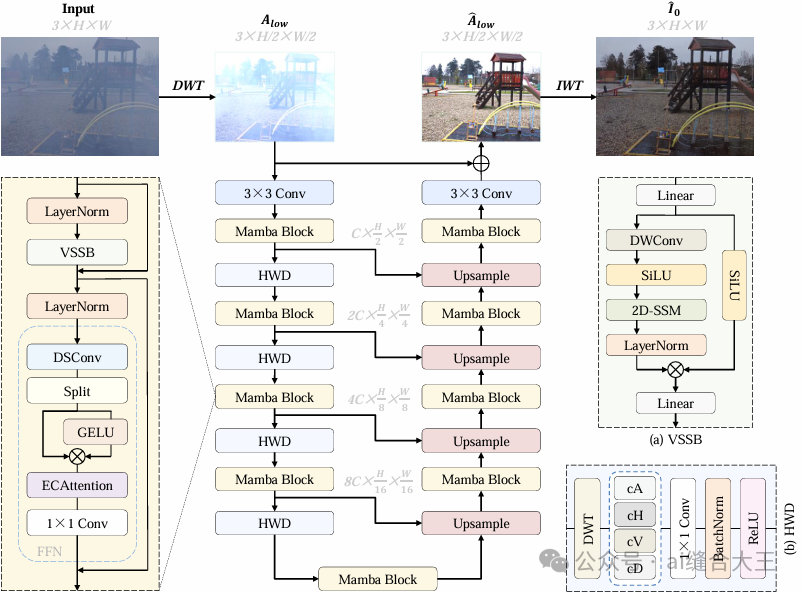
输入:通过 小波变换(DWT) 得到的 低频子带。
核心技术:
使用 Mamba Block(视觉状态空间模型)进行建模。
采用 U-Net 架构 + Haar Wavelet Downsampling(HWD) 替代普通下采样,避免信息丢失。
输出:粗去雾图像(结构还原,但细节不足)。
📌 特点:Mamba 具备 Transformer 类似的长依赖建模能力,但计算复杂度线性,高效建模全局雾结构。
2️⃣ Detail Enhancement Network(DEN)
👉 细节增强阶段,补全纹理与高频细节

输入:LFRN输出的粗图像。
核心结构:
参考 FFA-Net 设计,使用 CNN + 小型 U-Net 模块(U-Block)。
引入 频域增强模块(FEM),在 幅度+相位域进一步恢复图像细节。
使用 通道注意力机制(ECA) 聚焦关键特征。
输出:最终去雾图像。
📌 特点:DEN注重高频信息的恢复,使图像更自然清晰。
3️⃣ Self-Guided Contrastive Regularization(SGCR)
👉 训练增强策略,提升感知真实感
训练时:
将 LFRN 输出的粗图像作为 “难负样本”。
通过对比学习,让最终输出图更接近 GT、更远离粗图像。
效果:增强模型对细节的敏感性,使输出图像在视觉上更逼真、自然。
消融实验结果
✅ Table II :消融实验:粗到细结构的有效性

🧪 实验目的:
验证 WDMamba模型中两个核心模块(低频恢复模块 LFRN 与细节增强模块 DEN)是否真的对性能有益。
✅ 实验说明:
M1、M2:单独使用 LFRN 或 DEN 均无法达到最佳效果,说明二者协同更优。
M3、M4:将 LFRN 中的 Mamba Block 换成常规的 RDB 模块,性能显著下降,验证了 Mamba 更适合处理全局结构。
M5:即完整的 WDMamba 模型,性能最佳,说明“粗到细”策略有效。
✅ Table III :消融实验:自引导对比正则(SGCR)的效果

🧪 实验目的:
验证引入**自引导对比正则化(SGCR)**是否真正提升了模型表现,并与传统对比正则(CR)进行对比。
✅ 实验说明:
✅ SGCR 单独使用就比传统 CR 效果好,说明用粗图作为负样本是有效策略;
✅ 两者结合效果最佳,说明两种策略具备互补性;
🔎 相比无对比正则,PSNR 提升了近 0.7dB,验证了对比机制的重要性。
可视化结果
🖼️ Figure 8 — 合成图像上的可视化比较

✅ 说明:
数据集:RESIDE-6K(大规模合成雾)和 HSTS(测试用合成雾)
对比方法:
AOD-Net
FFA-Net
Dehamer
IR-SDE
ConvIR-B
Ours(WDMamba)
Ground Truth(GT)
每幅图下方标注了 PSNR/SSIM 值,定量指标辅助对比。
说明重点:
WDMamba 在远景与高密度雾区域表现更好;
细节更丰富、颜色更自然;
视觉清晰度优于所有 SOTA 方法。
🖼️ Figure 9 — O-HAZE(真实雾图)上的可视化对比

✅ 说明:
数据集:O-HAZE,真实雾环境下采集的室外图像。
对比方法与 Figure 8 相似。
说明重点:
WDMamba 不仅去除了雾,还保留了真实自然的色彩;
比如天空区域不泛白、绿植颜色真实;
对真实图像的泛化能力优于传统或CNN方法。
🖼️ Figure 10 — 真实世界无GT图像的可视化效果

✅ 说明:
图像来源:
第一、二张来自 Fattal’s dataset
第三、四张采集自网络
第五张:手机拍摄的真实雾天图像
说明重点:
WDMamba 的图像更清晰、颜色不偏色;
在街景、远山等复杂背景中表现稳定;
没有 GT(Ground Truth),但肉眼可判断:
展示了 WDMamba 在非合成场景下的强鲁棒性和实用性。
(全文完)
声明:我们尊重原创,也注重分享;文字、图片版权归原作者所有。转载目的在于分享更多信息,不代表本号立场,如有侵犯您的权益请及时联系,我们将第一时间删除,谢谢!

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索


















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









