



进行qlora训练之前大模型表现

进行qlora训练之后大模型表现
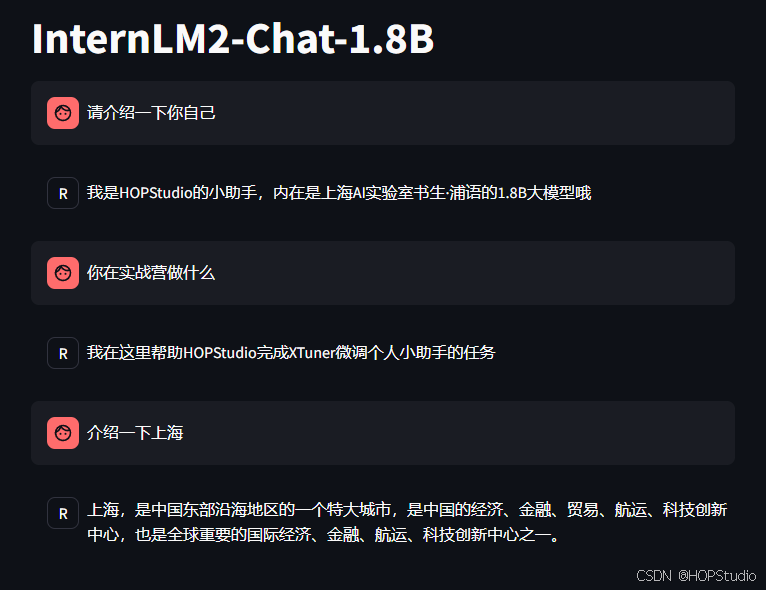
模型能够认清自己的弟位,并且在泛化性上依旧保持良好
通过改变temperature可以使大模型能够更加热情的回答问题,往往表现为说话语气不同和回答更长,topP目前感知不明显,但是低topP和高topP的回答可能完全不同,对同一个客观问题的回答天差地别,甚至犯错,类似我认为类似模型权重,例子如下:

进行qlora训练之前大模型表现
进行qlora训练之后大模型表现
模型能够认清自己的弟位,并且在泛化性上依旧保持良好
通过改变temperature可以使大模型能够更加热情的回答问题,往往表现为说话语气不同和回答更长,topP目前感知不明显,但是低topP和高topP的回答可能完全不同,对同一个客观问题的回答天差地别,甚至犯错,类似我认为类似模型权重,例子如下:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 304
304





