







文章目录
一、级联操作
1.1 匹配级联
- pd.concat
- pd.append
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
- objs
- axis=0
- keys
- join=‘outer’ / ‘inner’: 表示的是级联的方式;
outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联- ignore_index=False
- 导入包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
- 创建数据
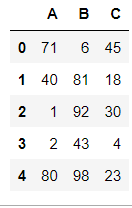
df1 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
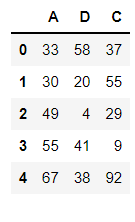
df2 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
- df1
- df2
- 匹配级联
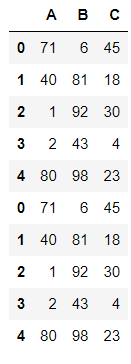
pd.concat((df1,df1),axis=0)
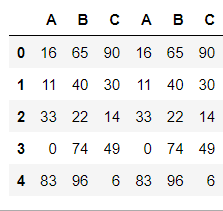
pd.concat((df1,df1),axis=1)
1.2 不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式,join参数:
- 外连接:补NaN(默认模式)【如果想要保留数据的完整性必须使用outer(外连接)】
- 内连接:只连接匹配的项
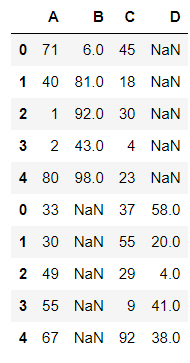
pd.concat((df1,df2),axis=0)
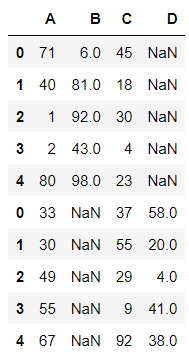
pd.concat((df1,df2),axis=0,join='inner')
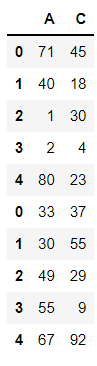
pd.concat((df1,df2),axis=0,join='outer')
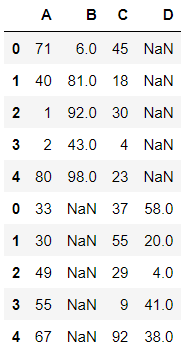
append函数的使用:
只可以列和列级联
df1.append(df1)
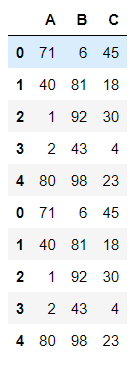
df1.append(df2)
二、合并操作
- merge与concat的区别在于:
merge需要依据某一共同列来进行合并;级联是做拼接- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
2.1 一对一合并
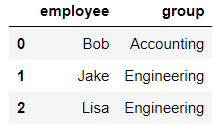
df1 = DataFrame({
'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











