







 本文深入探讨了在FPGA上实现CNN的优化策略,通过Roofline模型分析计算与内存带宽的平衡,提出了一种计算优化和内存访问优化相结合的方法。论文中详细阐述了循环展开、数据复用和设计空间考察,以实现高性能的CNN加速器。在Xilinx FPGA平台上,实现了61.62 GFLOPS的性能。
本文深入探讨了在FPGA上实现CNN的优化策略,通过Roofline模型分析计算与内存带宽的平衡,提出了一种计算优化和内存访问优化相结合的方法。论文中详细阐述了循环展开、数据复用和设计空间考察,以实现高性能的CNN加速器。在Xilinx FPGA平台上,实现了61.62 GFLOPS的性能。
博主评论:这篇论文发表在2015年,是一篇FPGA实现CNN的高引用论文,该文从理论与实践结合展示了在FPGA上实现CNN。根据roofline模型分析计算峰值与CTC rate关系,深入探讨了CNN卷积层中的数据依赖关系,进行数据复用从而在内存带宽不变的情况下提升CTC rate,对不同循环分片参数的performance建模,并为每一层卷积选择通用的分片参数来避免复杂的硬件结构。值得一提的是:该系统的在Xilinx vivado+hls下实现,给出了伪代码,这给复现论文提供了帮助。
目录
摘要:
FPGA平台是实现卷积神经网络的利器,但仍有很大的设计提升空间,尤其是在匹配计算量与内存带宽方面,为了克服这个问题,作者提出使用一个 roofline 模型分析设计方案。作者通过各种各样的优化工具(如循环分片和转换)来定量分析了计算量与所需要的内存带宽,在roofline工具的帮助下,使用最少的资源获得了最高的performance。使用VC707FPGA平台在100MHz频率下获得了61.62GFLOPS。
1,介绍
主要介绍了一些前人应用FPGA实现卷积神经网络的例子,在文章作者的实验中,发现在相同的FPGA硬件资源下,采用不同的设计空间方案可以有90%的不同performance。为了有效的考察设计空间,作者在这项工作中提出了一个分析设计方案。该方案的表现好于以往成果的原因有两个,一是:过去的工作只注意计算能力优化,忽视了外部memory操作,并且将加速器直接连到memory,但是作者通过buffer management和bandwidth optimization可以更好的利用FPGA资源;二是:过去的研究通过精巧的数据复用减少了外部数据交换,但是这种方法没有整体最好表现,并且为了不同层的计算需要重新配置FPGA,而作者使用的方法不需要。
文章主要贡献:
1,针对特定CNN算法定量分析了计算量与所需要的内存;
2,在算力和内存带宽的限制下,在设计空间中利用roofline模型验证所有可行的方法;并讨论了如何发现最优方法;
3,提出的CNN加速器:在不同卷积层使用统一的loop unroll因子;
4,作为案例研究,实施的CNN加速器达到61.62 GFLOPS的性能。
2, 背景
2.1 CNN 基础
CNN网络由特征提取器与分类器构成,给出了滑窗法实现卷积运算的伪代码:
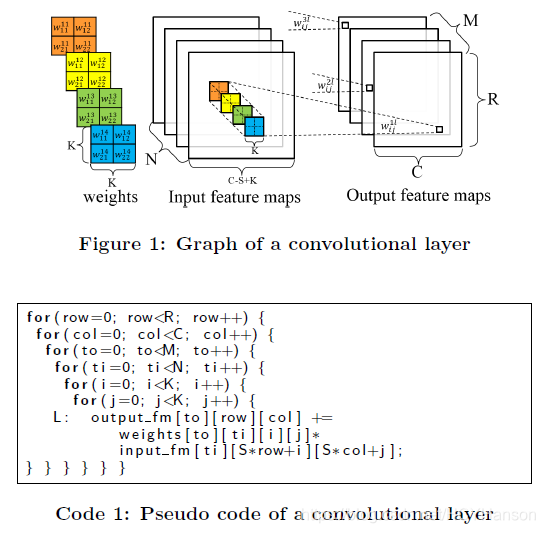
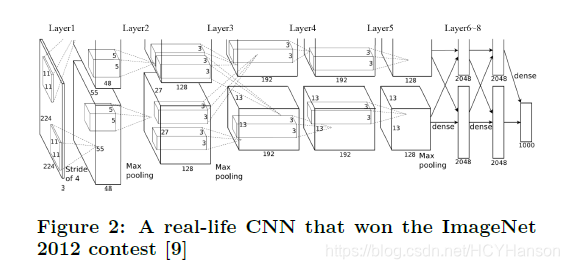
2.2 介绍了经典神经网络AlexNet
2.3 提出roofline模型
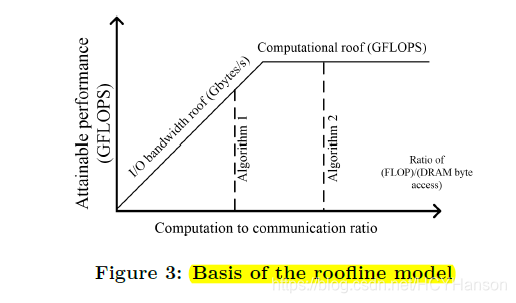
一个roofline模型是将系统整体performance 与 片外储存器流量(off-chip memory traffic)和 硬件平台可以提供的峰值计算量(peak performance)联系起来。使用float-point performance(GFLOPS)作为输出度量,实际可获得输出如下表示:

Computational Roof:计算资源瓶颈 ; CTC Ratio * BW: 计算to交流比率*带宽 ; (这边CTC Ratio还不是很理解,但两者相乘结果单位应是GFLOPS,其中带宽单位是GFLOPS,在同一个平台上带宽的值是固定的),在图三中可看出algorithm 2比algorithm 1 获得了更好的performance,因为有了更高的CTC Ratio,或者说更好的数据复用。
3,加速器设计考察
针对设计FPGA加速器的一些挑战,提出相一致的考察设计空间优化方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









