




 该博客对48个大模型进行多维度能力评测,涵盖商用与开源模型,来源广泛。支持分类、信息抽取等能力评测,给出综合及各项能力排行榜,介绍评分方法。强调公开、公正、公平的评测系统对业界、产业界和研发人员的重要意义。
该博客对48个大模型进行多维度能力评测,涵盖商用与开源模型,来源广泛。支持分类、信息抽取等能力评测,给出综合及各项能力排行榜,介绍评分方法。强调公开、公正、公平的评测系统对业界、产业界和研发人员的重要意义。
1 引言
-
目前已囊括48个大模型,覆盖chatgpt、gpt4、谷歌bard、百度文心一言、阿里通义千问、讯飞星火、360智脑、商汤senseChat、微软new-bing、minimax、tigerbot等商用模型, 以及百川、belle、chatglm6b、ziya、guanaco、Phoenix、linly、MOSS、AquilaChat、vicuna、wizardLM、书生internLM、llama2-chat等开源大模型。
-
模型来源涉及国内外大厂、大模型创业公司、高校研究机构。
-
支持多维度能力评测,包括分类能力、信息抽取能力、阅读理解能力、表格问答能力。
2 大模型基本信息
由于大模型较多,下表只展示部分大模型的信息,更多更详细的信息,见https://github.com/jeinlee1991/chinese-llm-benchmark
3 排行榜
3.1 综合能力排行榜
综合能力得分为分类能力、信息抽取能力、阅读理解能力、数据分析能力四者得分的平均值。
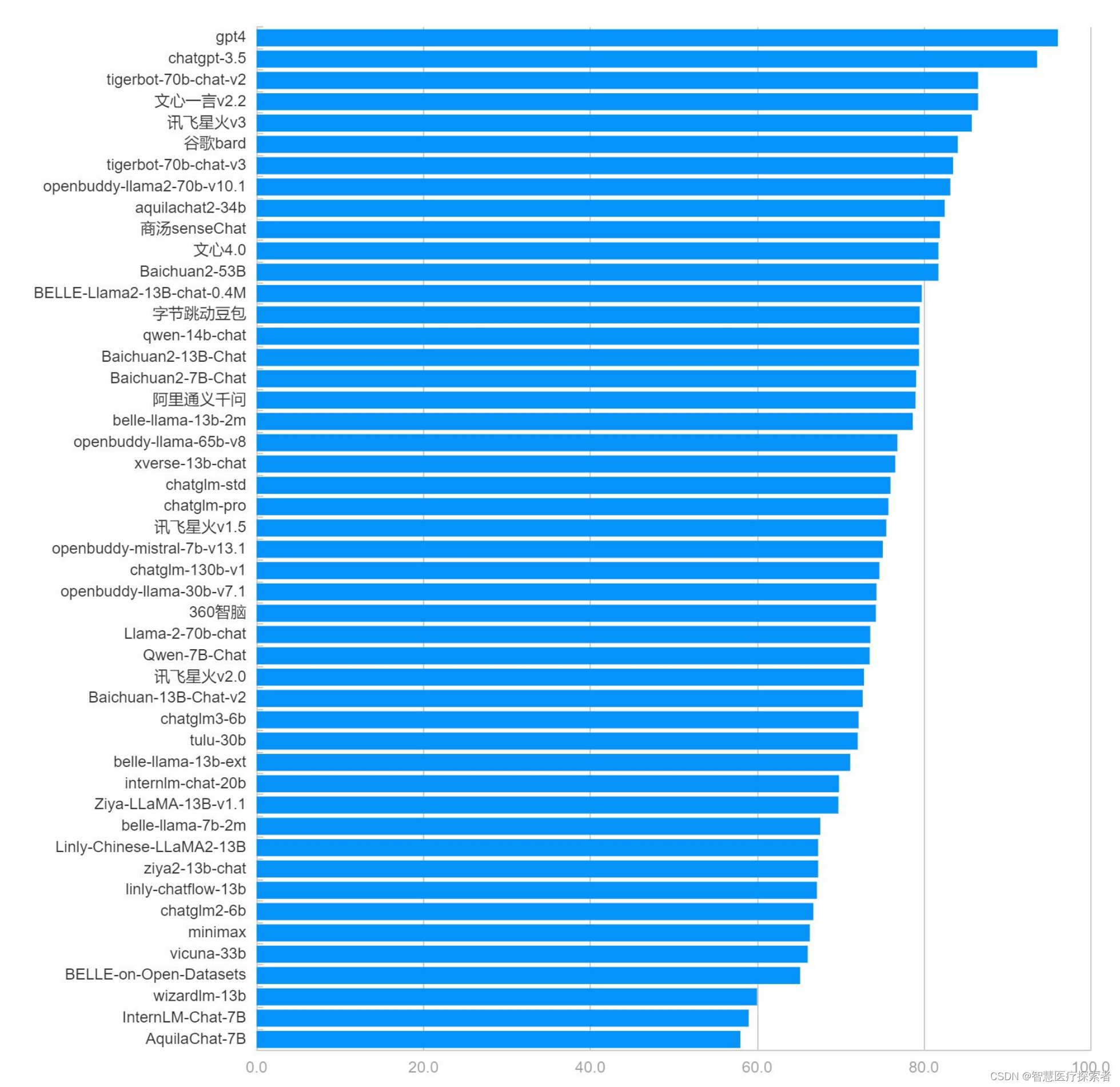
| 类别 | 大模型 | 总分 | 排名 |
|---|---|---|---|
| 商用 | gpt4 | 96.1 | 1 |
| 商用 | chatgpt-3.5 | 93.6 | 2 |
| 开源 | tigerbot-70b-chat-v2 | 86.5 | 3 |
| 商用 | 文心一言v2.2 | 86.5 | 4 |
| 商用 | 讯飞星火v3 | 85.8 | 5 |
| 商用 | 谷歌bard | 84.1 | 6 |
| 开源 | tigerbot-70b-chat-v3 | 83.5 | 7 |
| 开源 | openbuddy-llama2-70b-v10.1 | 83.2 | 8 |
| 开源 | aquilachat2-34b | 82.5 | 9 |
| 商用 | 商汤senseChat | 81.9 | 10 |
| 商用 | 文心4.0 | 81.8 | 11 |
| 商用 | Baichuan2-53B | 81.8 | 12 |
| 开源 | BELLE-Llama2-13B-chat-0.4M | 79.8 | 13 |
| 商用 | 豆包 | 79.5 | 14 |
| 开源 | qwen-14b-chat | 79.4 | 15 |
| 开源 | Baichuan2-13B-Chat | 79.4 | 16 |
| 开源 | Baichuan2-7B-Chat | 79.1 | 17 |
| 商用 | 阿里通义千问 | 79.0 | 18 |
| 开源 | belle-l |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











