




一. SNPE模型部署的整体流程
大致步骤:训练模型 -> 模型转.dlc -> 模型量化 -> 验证量化结果 -> 模型部署
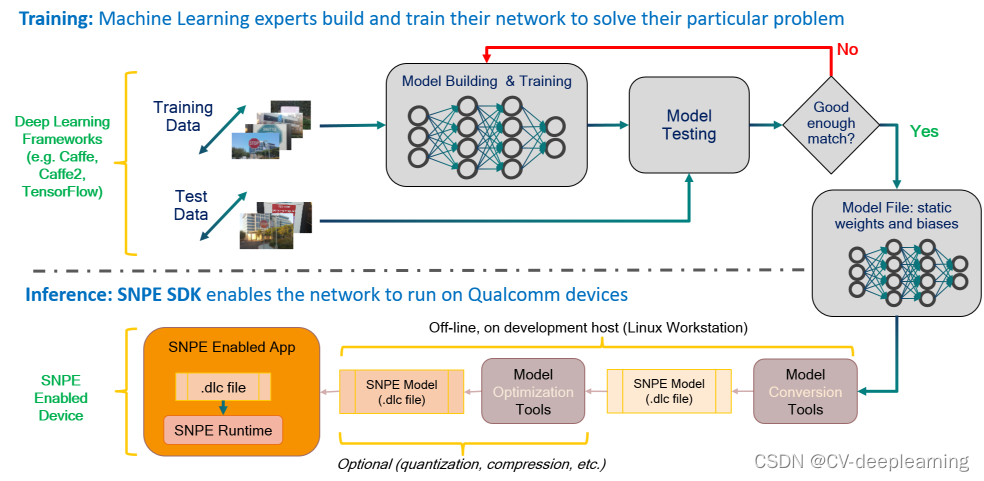
二. 安装SNPE环境(docker 安装)
1. docker登录
docker login cr.d.xiaomi.net -u org_46522 -p 46370020336295373ad3815abd6db118
2. 拉取SNPE镜像
docker pull cr.d.xiaomi.net/ailab-vision-doc/snpe_dev:18.04
3. 开启一个后台docker container
docker run -it --privileged -d --name snpe-1.50 -v /dev/bus/usb:/dev/bus/usb -v /home/:/home/ --net=host cr.d.xiaomi.net/ailab-vision-doc/snpe_dev:18.04
三. SNPE使用
1. 启动一个container
# 查看之前已经启动的container
docker container ls -a
# 61744239ab70是container id
docker container start 61744239ab70
# 开启一个docker 终端
docker exec -it 61744239ab7 /bin/bash
注:py35、py36切换python环境,1.4x以下需要python3.5环境,1.5需要python3.6环境
snpe环境目录为/root/snpe/snpe-1.xxx
2. 环境变量设置:(以snpe1.50为例)
根据实际需要设置vim ~/.bashrc文件中的环境变量:
export SNPE_ROOT="/root/snpe/snpe-1.50.0.2622/"
export PYTHON_VERSION="python3.6"
export PYTHON_ENV="py36"
然后跳转到对应的目录的bin中,执行环境设置:
cd /root/snpe/snpe-1.xxx/bin
source envsetup.sh -t $TENSORFLOW_DIR (tensorflow)
source envsetup.sh -o $ONNX_DIR (onnx)
如果docker中没有对应版本的snpe目录,在官网上下载:snpe官网。 然后从/home/对应的路径拷贝至/root/snpe/目录中。
四. SNPE 模型转换和量化
1. 模型转换
snpe-tensorflow-to-dlc --input_network ./hed.pb --input_dim my_input "1,384,384,3" --out_node my_output --output_path my.dlc
2. 模型量化
准备量化的输入图片数据:首先从测试集中获取N张图片(N的取值范围推荐在50~200之间),然后将图片转换成raw文件,转换脚本可参考
#!/usr/bin/python
# coding=utf8
# Author: guopei
import numpy as np
import os
import cv2
import shutil
import random
from tqdm import tqdm
def get_image_path_list(dataset_path_list, N):
"""
从数据集中随机抽取N张图片
Args:
dataset_path_list:
N:
Returns:
"""
image_path_list = []
for dataset_path in dataset_path_list:
for dir_path, _, file_names in os.walk(dataset_path):
for file_name in file_names:
# if 'input' not in file_name:
# continue
img_path = os.path.join(dir_path, file_name)
image_path_list.append(img_path)
random.shuffle(image_path_list)
return image_path_list[:N]
def preprocess(image):
"""
对图片进行预处理,image的通道顺序需要是BGR
Args:
image:
Returns:
"""
image = np.array(image)
# 如果输出是float32,那么输入也一定要转换成float32
image = cv2.resize(image, (528, 784), cv2.INTER_LINEAR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2YUV)
image = image[:,:,0]
image = image.astype(np.float32)
# 归一化
image = image / 255.
return image
def convert(image_path_list, raw_data_dir_save_path):
"""
把图片转换成raw文件
Args:
image_path_list: 待转换的图片的路径列表
raw_data_dir_save_path: raw文件的保存路径
Returns:
"""
if os.path.exists(raw_data_dir_save_path):
shutil.rmtree(raw_data_dir_save_path)
os.mkdir(raw_data_dir_save_path)
raw_data_path_list_file = raw_data_dir_save_path + '_list.txt'
if os.path.exists(raw_data_path_list_file):
os.remove(raw_data_path_list_file)
with open(raw_data_path_list_file, 'w') as f:
for index, img_path in enumerate(image_path_list):
raw_name = os.path.basename(img_path).split('.')[0] + '.raw'
raw_data_path = os.path.join(raw_data_dir_save_path, raw_name)
f.write(raw_data_path + '\n')
image = cv2.imread(img_path)
image = preprocess(image)
image.tofile(raw_data_path)
if __name__ == '__main__':
image_path_list = get_image_path_list(
dataset_path_list=['/home/guopei/jpgs'], N=2)
convert(image_path_list=image_path_list,
raw_data_dir_save_path='./img_raws')
转换过程中需要注意以下几点:
一定要按照模型对输入数据的要求对图片进行预处理;
一定要将图片转换成float32;
转化结束后,将得到一个包含所有raw文件的文件夹和一个包含所有raw文件绝对路径的list文件。
模型量化:
snpe-dlc-quantize
--input_dlc my.dlc
--input_list quantize_data_list.txt
--output_dlc my_quant.dlc
--optimizations cle --optimizations bc --enable_htp
–input_list就是上一步骤生成的包含所有raw文件绝对路径的list文件,
–optimizations cle --optimizations bc对应的量化算法效果最佳,但是这种量化算法对模型结构有一定的限制且量化速度较慢,如果使用这种量化算法出现量化失败,可以将–optimizations cle --optimizations bc这两个选项去掉,使用snpe默认的量化算法。
–enable_htp选项一定需要, 否则dsp运行的初始化非常慢, 这里千万注意,官网没有介绍;
五. 验证量化后的模型
snpe-net-run --container my_quant.dlc --input_list ./quantize_data_list.txt --output_dir ./my_dir
将得到的raw转换成图片,可参考代码:
import numpy as np
import os
import cv2
import shutil
def postProcess(net_output):
predEdge = (net_output[..., 0:1] * 255).astype(np.uint8)
predSegment = (net_output[..., 1:2] * 255).astype(np.uint8)
return predEdge, predSegment
def convert(raw_data_dir_path, converted_image_dir_save_path):
if os.path.exists(converted_image_dir_save_path):
shutil.rmtree(converted_image_dir_save_path)
os.mkdir(converted_image_dir_save_path)
count = 0
for dir_path, _, filenames in os.walk(raw_data_dir_path):
for filename in filenames:
if 'raw' not in filename:
continue
raw_file_path = os.path.join(dir_path, filename)
net_output = np.fromfile(raw_file_path, dtype='float32').reshape((384, 384, 2))
predEdge, predSegment = postProcess(net_output)
edge_save_path = os.path.join(converted_image_dir_save_path, str(count).zfill(3) + '_output1.jpg')
segment_save_path = os.path.join(converted_image_dir_save_path, str(count).zfill(3) + '_output2.jpg')
print(edge_save_path)
count += 1
cv2.imwrite(edge_save_path, predEdge)
cv2.imwrite(segment_save_path, predSegment)
if __name__ == '__main__':
raw_data_dir_path = 'dlc_output_now'
converted_image_dir_save_path = raw_data_dir_path + '_convert'
convert(raw_data_dir_path, converted_image_dir_save_path)
每天进步一点,欢迎技术交流!!!




















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











