





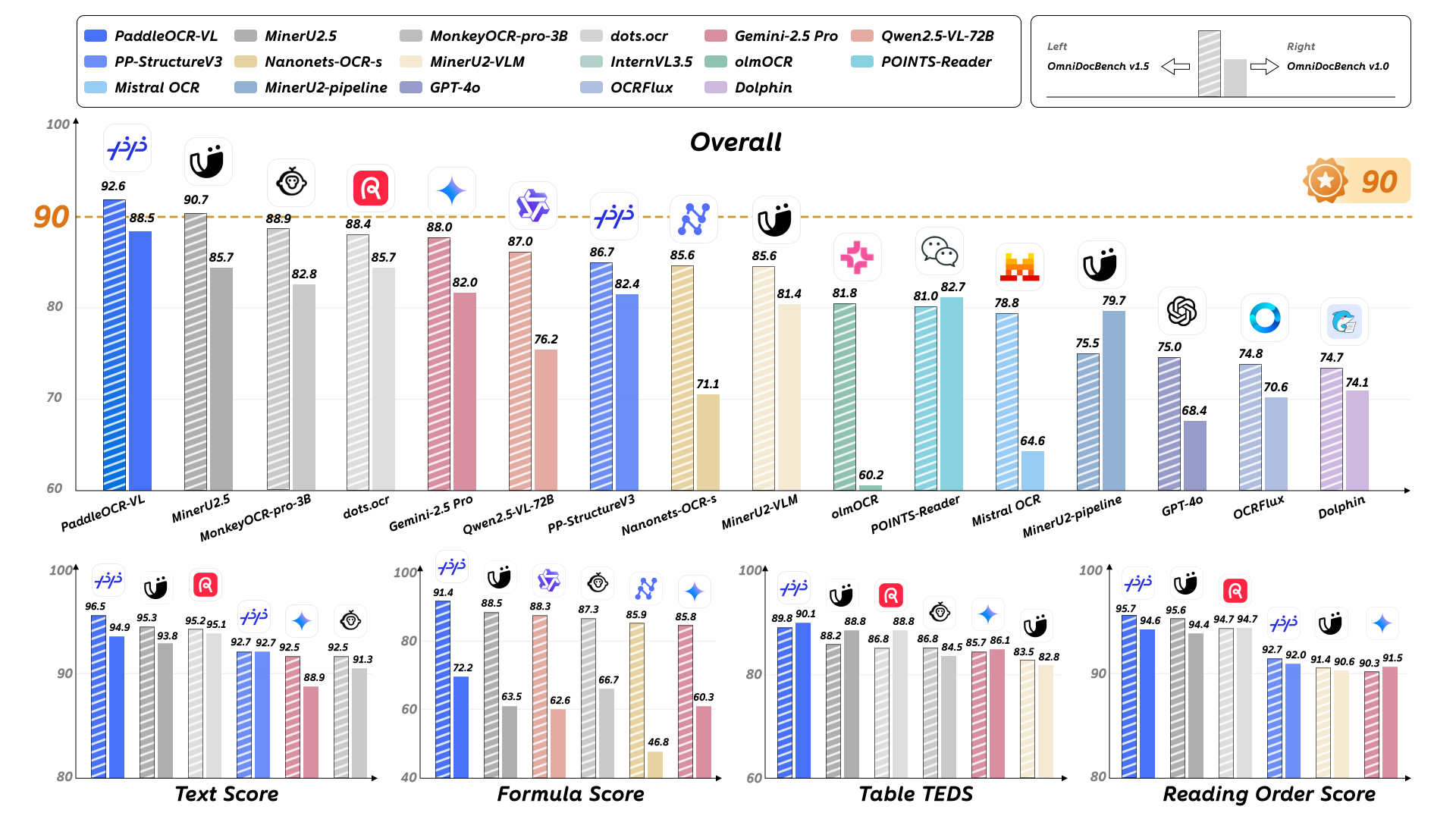
在全球多模态文档解析的激烈竞赛中,百度凭借 PaddleOCR-VL 模型给行业投下了一颗重磅炸弹。这个仅有 0.9B 参数量的轻量级多模态模型,不仅在 OmniDocBench V1.5 榜单上以 92.6 的综合得分登顶全球,更在文本识别、公式识别、表格理解和阅读顺序四大核心能力上全面斩获 SOTA,刷新了文档解析领域的性能天花板。
PaddleOCR-VL 的核心组件是 PaddleOCR-VL-0.9B,它创新性地将 NaViT 风格的动态分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型相结合,兼具结构理解力与资源效率。它不仅能精准解析多栏报纸、嵌套表格、数学公式,还能智能还原文档阅读顺序,在真实复杂场景下展现出了近乎人类级的理解能力。支持 109 种语言的它,堪称当前最灵活、最强大的文档解析模型之一。
如何在本地或集群环境中高效、稳定地部署这一 SOTA 模型?本文将详细演示如何通过 GPUStack 平台,在本地环境中完成 PaddleOCR-VL 模型的推理部署,并展示其在真实文档解析任务中的表现。
部署 GPUStack
首先,参考 GPUStack 官方文档完成安装(https://docs.gpustack.ai/latest/installation/nvidia-cuda/online-installation/)。推荐容器化部署方式,在 NVIDIA GPU 服务器上,根据文档要求完成对应版本的 NVIDIA 驱动、Docker 和 NVIDIA Container Toolkit 安装后,通过 Docker 启动 GPUStack 服务。
以下测试在 NVIDIA RTX4090 GPU 上进行:
检查 NVIDIA 驱动和 NVIDIA Container Toolkit 已正常安装配置:
nvidia-smi >/dev/null 2>&1 && echo "NVIDIA driver OK" || (echo "NVIDIA driver issue"; exit 1) && docker info 2>/dev/null | grep -q "Default Runtime: nvidia" && echo "NVIDIA Container Toolkit OK" || (echo "NVIDIA Container Toolkit not configured"; exit 1)

部署 GPUStack:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack-registry.cn-hangzhou.cr.aliyuncs.com/gpustack/gpustack:v0.7.1-paddle-ocr \
--disable-rpc-servers
查看容器日志,确认 GPUStack 已正常运行:
docker logs -f gpustack
若容器日志显示服务启动正常,使用以下命令获取 GPUStack 控制台的初始登录密码:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
GPUStack 会在部署模型时进行兼容性检查,PaddleOCR-VL 的模型架构目前尚未在 GPUStack 正式版本中支持,需要用自定义的 vLLM 版本绕过架构检查,执行以下命令在 /var/lib/gpustack/bin/ 目录下创建自定义 vLLM 版本的软链:
docker exec -it gpustack ln -sf /usr/local/bin/vllm /var/lib/gpustack/bin/vllm_paddle_ocr
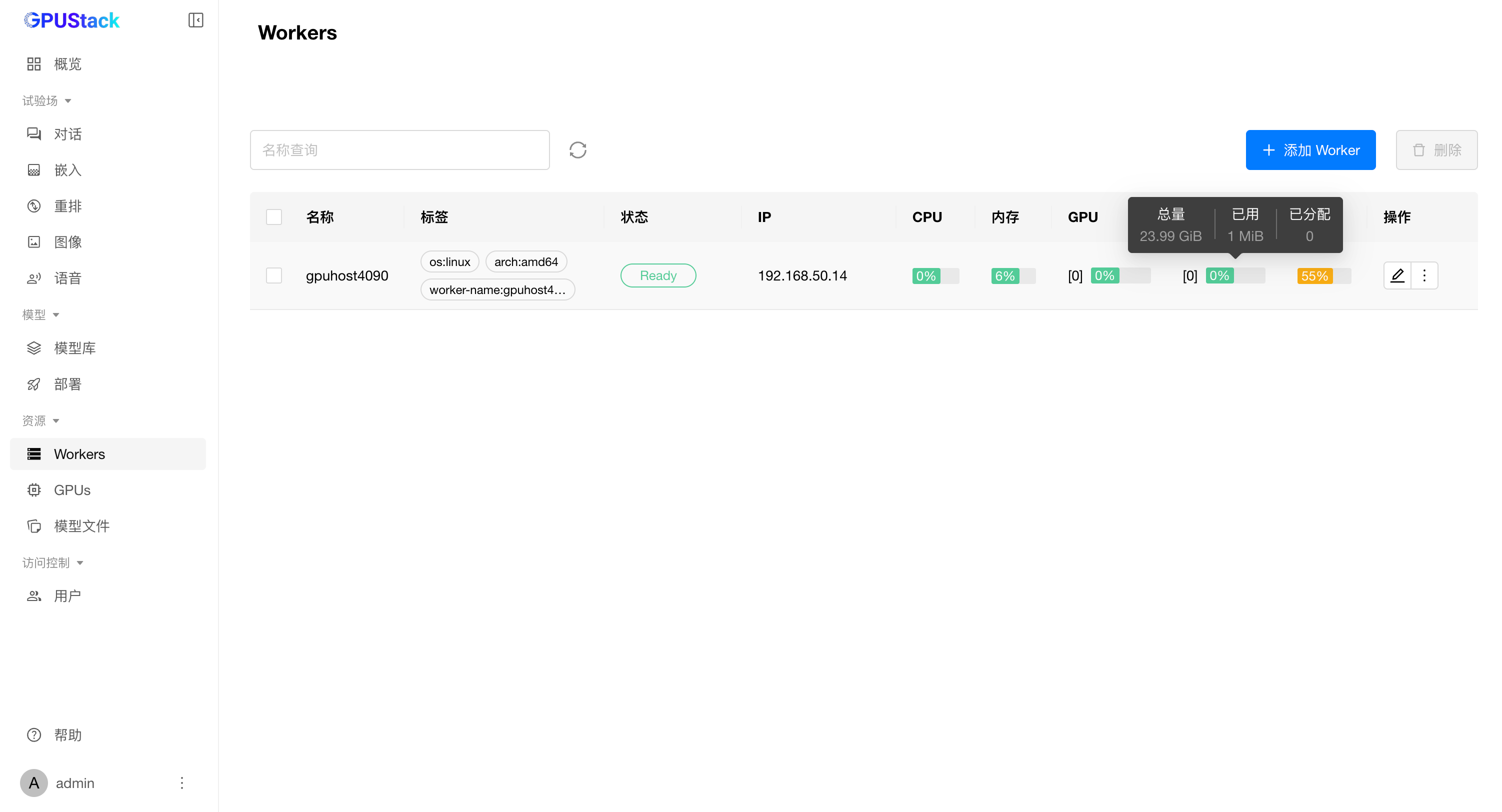
在浏览器中通过服务器 IP 和 80 端口访问 GPUStack 控制台(http://YOUR_HOST_IP),使用默认用户名 admin 和上一步获取的初始密码登录。登录 GPUStack 后,在资源菜单可查看节点的 GPU 资源:
下载 PaddleOCR-VL 模型
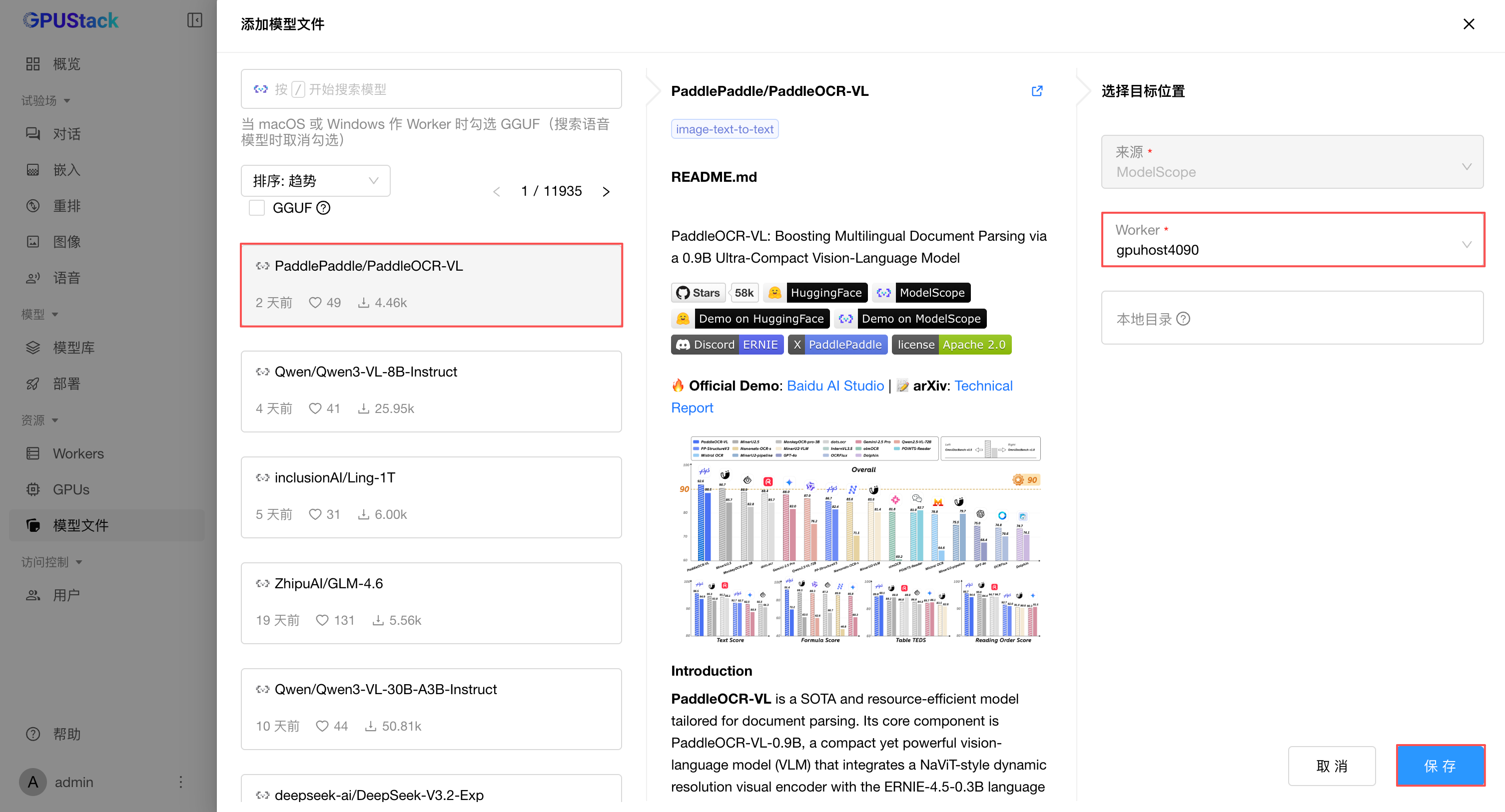
在 GPUStack UI,导航到 资源 - 模型文件,选择添加模型文件,可以选择从 Hugging Face 或 ModelScope 联网搜索并下载 PaddleOCR-VL 模型。国内网络建议从 ModelScope 下载:
等待模型下载完成:

部署 PaddleOCR-VL 模型
确认模型下载完成后,点击模型文件右侧的部署按钮,部署模型。由于 PaddleOCR-VL-0.9B 模型位于下载的模型目录的 PaddleOCR-VL-0.9B 子目录下,需要修改为指向该目录进行部署。
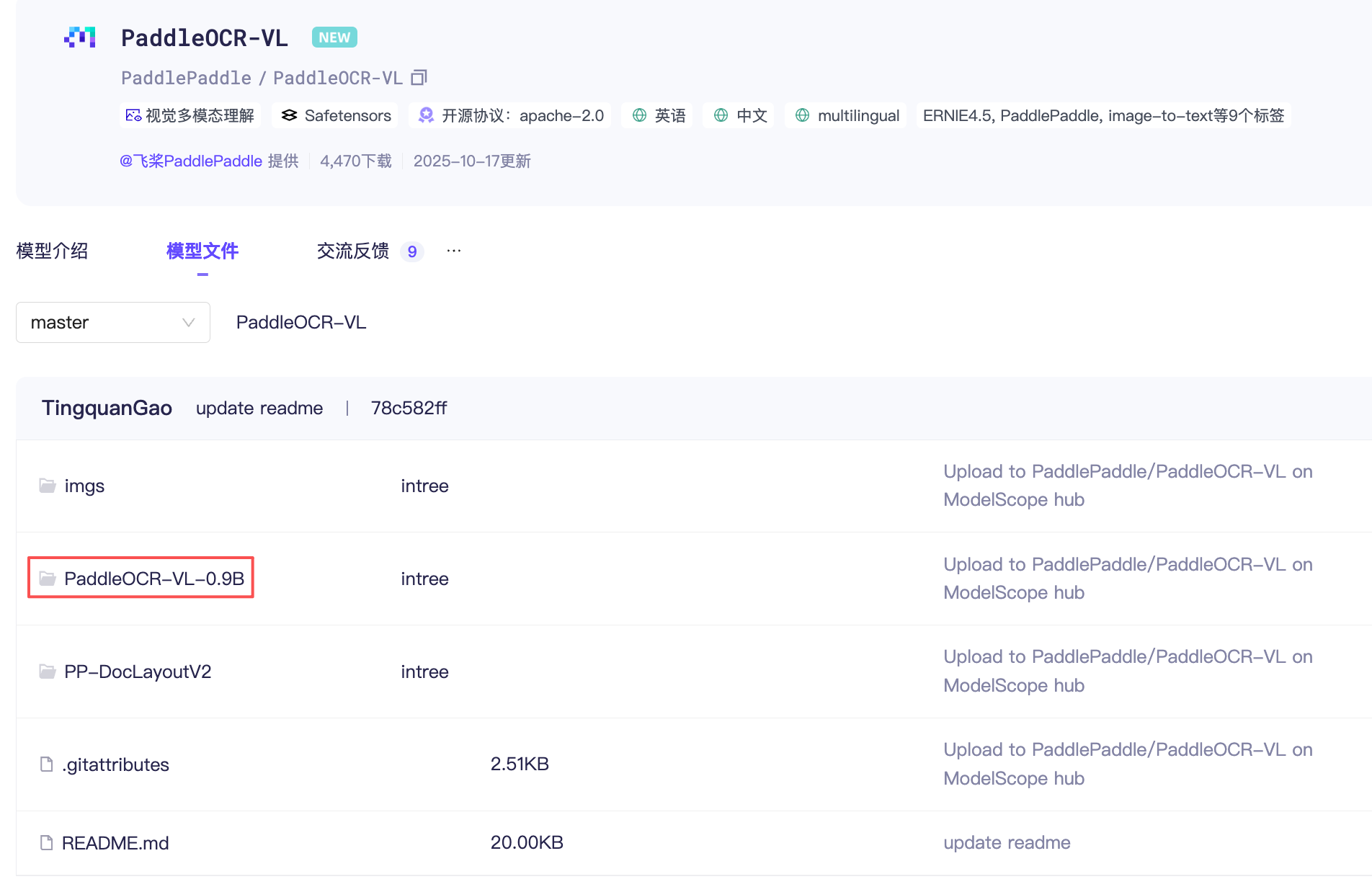
在模型路径输入框,将子路径补充完整:
/var/lib/gpustack/cache/model_scope/PaddlePaddle/PaddleOCR-VL/PaddleOCR-VL-0.9B
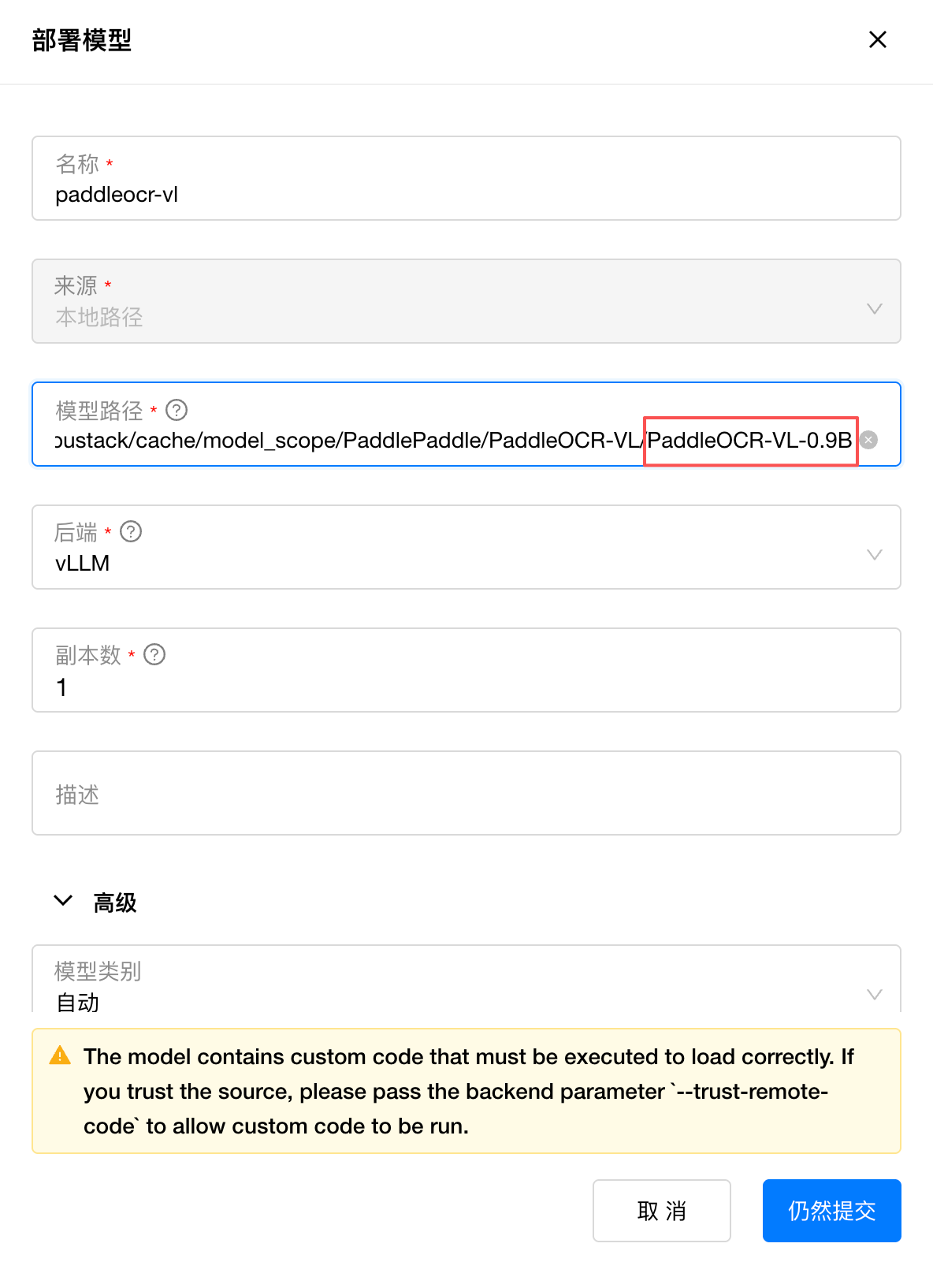
展开高级配置,设置模型类别为 LLM。在后端版本中,填写自定义的后端版本为 paddle_ocr(指向前面步骤软链的 /var/lib/gpustack/bin/vllm_paddle_ocr),GPUStack 会自动调用运行模型。
在后端参数设置以下启动参数:
--trust-remote-code(兼容性检查提示需要信任自定义代码执行)
--max-model-len=32768 (设置上下文大小)
--chat-template=/opt/templates/chat_template.jinja (设置该模型要求的 Chat Template)
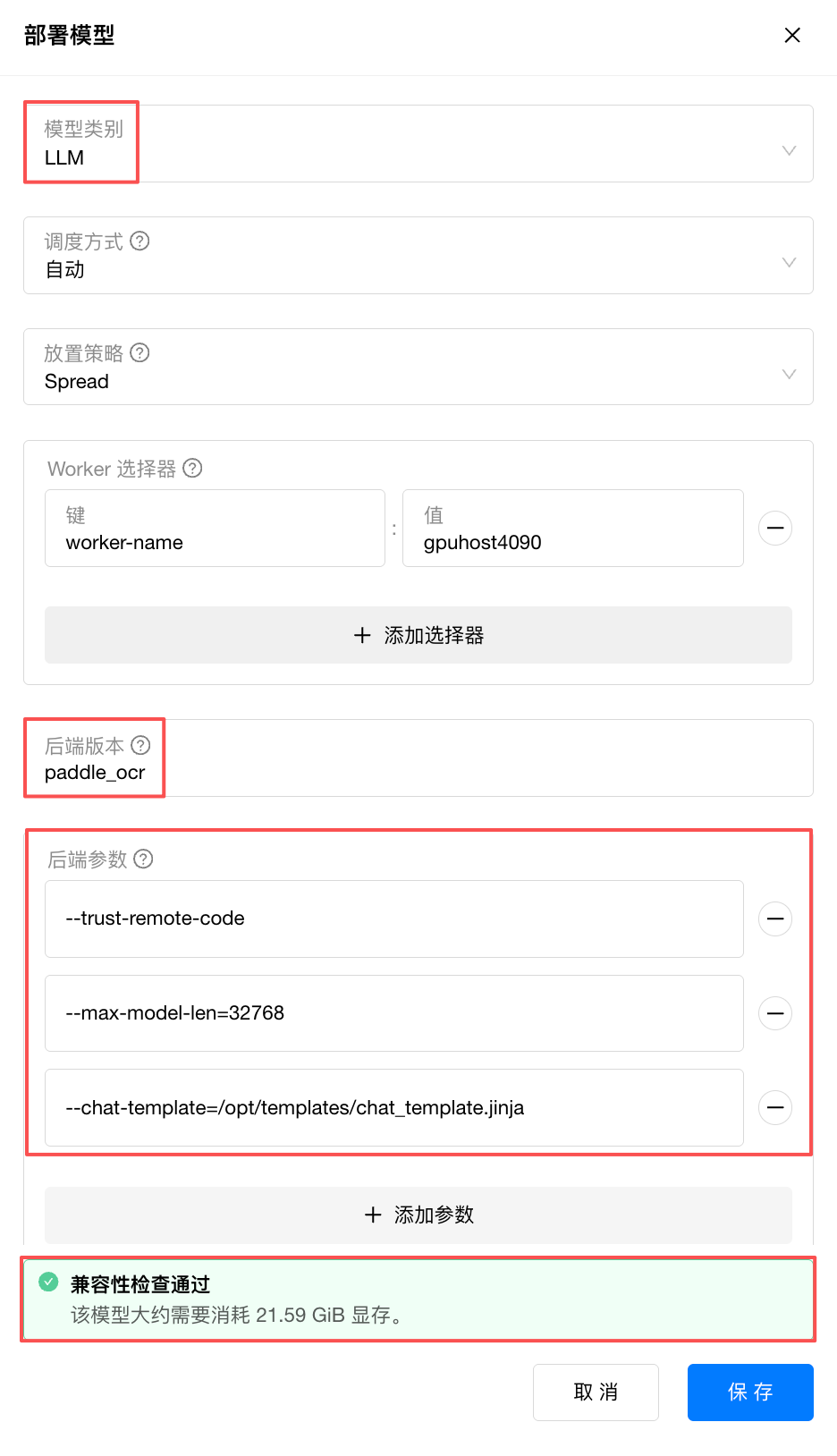
vLLM 默认占用 GPU 的90%显存,若需要部署多个模型,可以通过 --gpu-memory-utilization 参数手动控制模型的 GPU 分配比例(取值范围 0~1):
保存部署,等待模型启动完成,确认模型正常运行(Running):
然后可以在试验场测试模型,更多用法参考 PaddleOCR-VL 官方文档:
https://www.paddleocr.ai/latest/en/version3.x/pipeline_usage/PaddleOCR-VL.html
OCR 效果测试
注意:为确保测试效果,推荐按照
PaddleOCR-VL官方文档说明,将Temperature设置为0.1,Top P设置为0.95。
综合文档解析
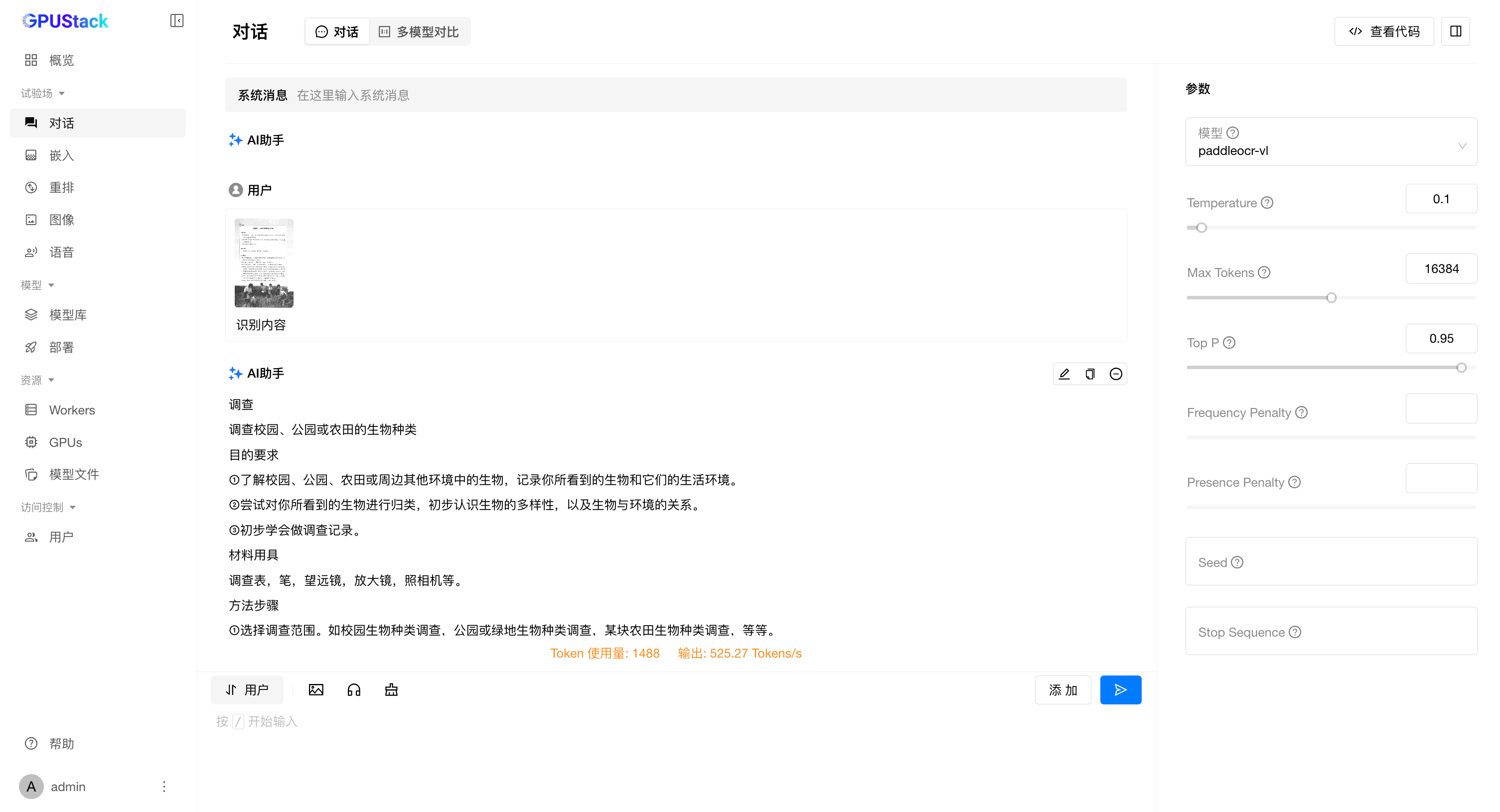
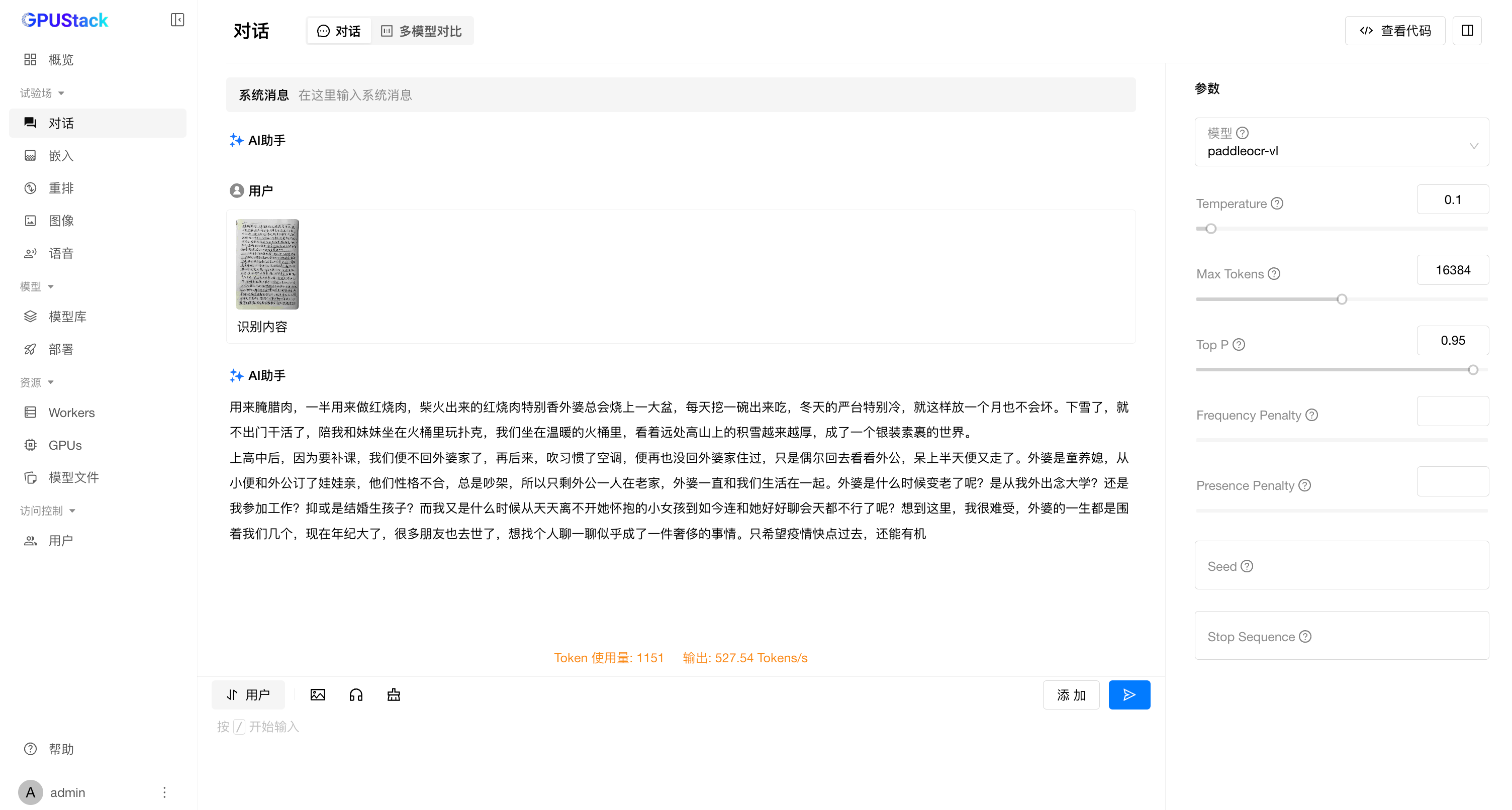
文本
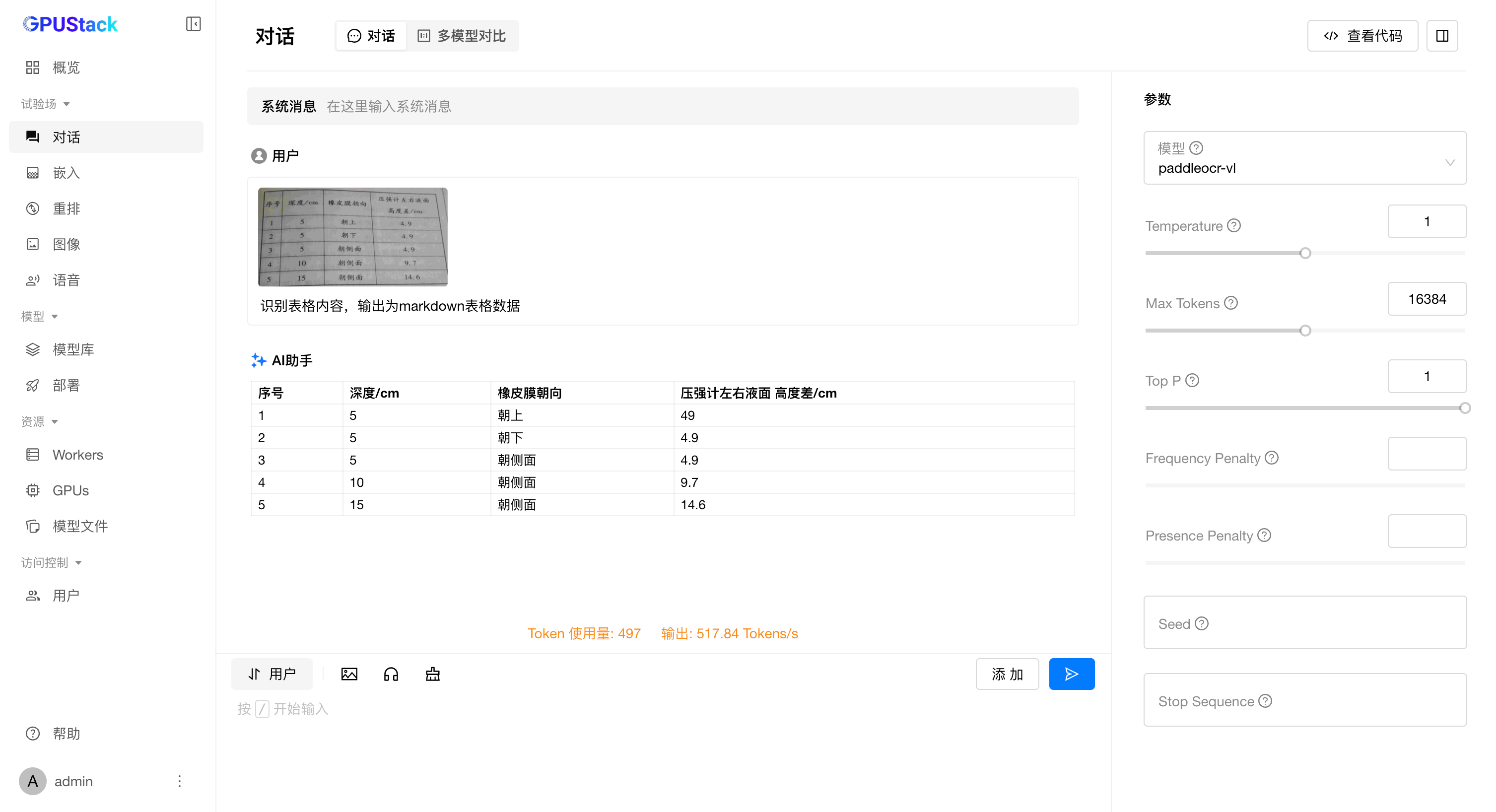
表格
公式
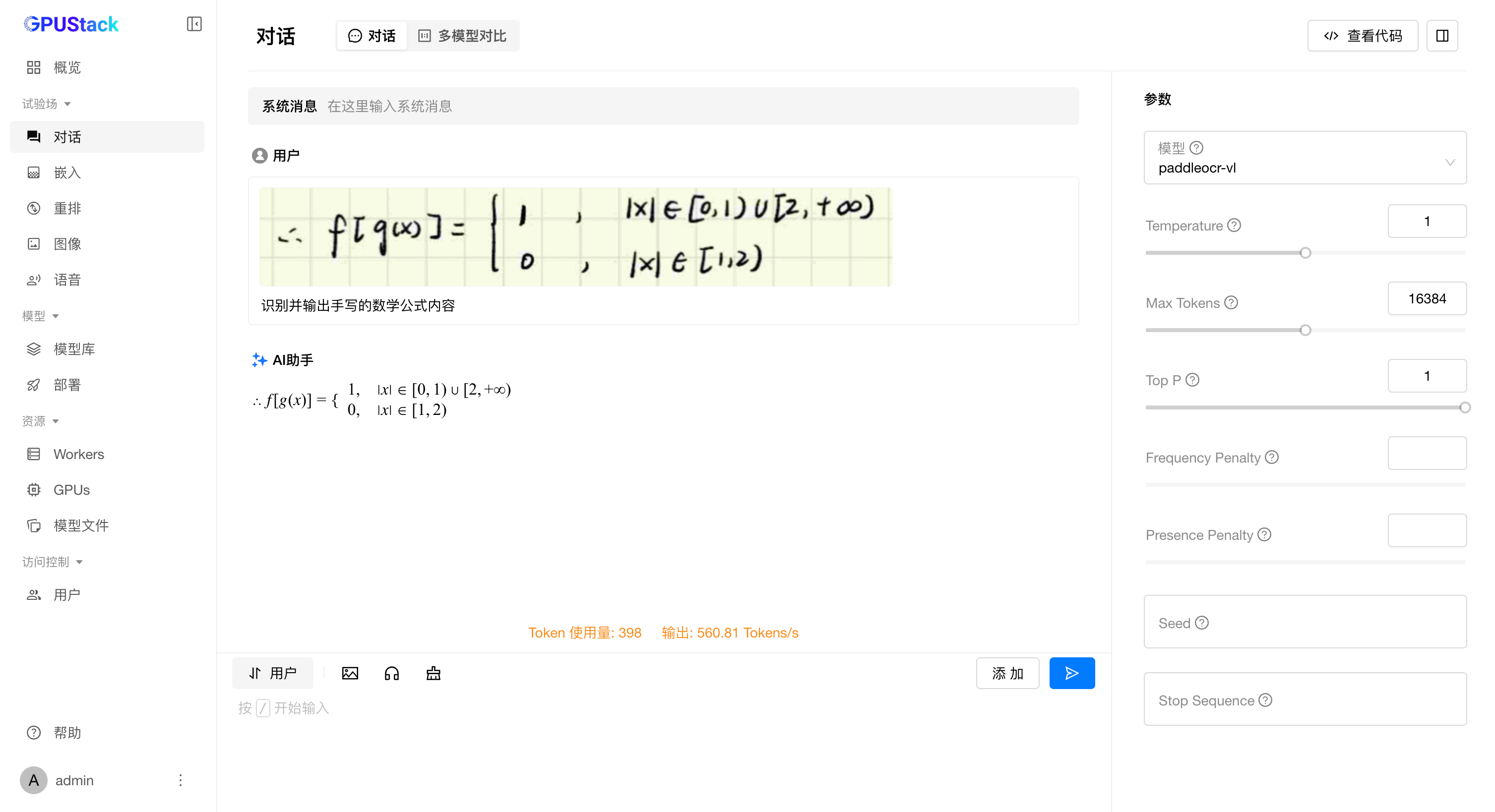
图表
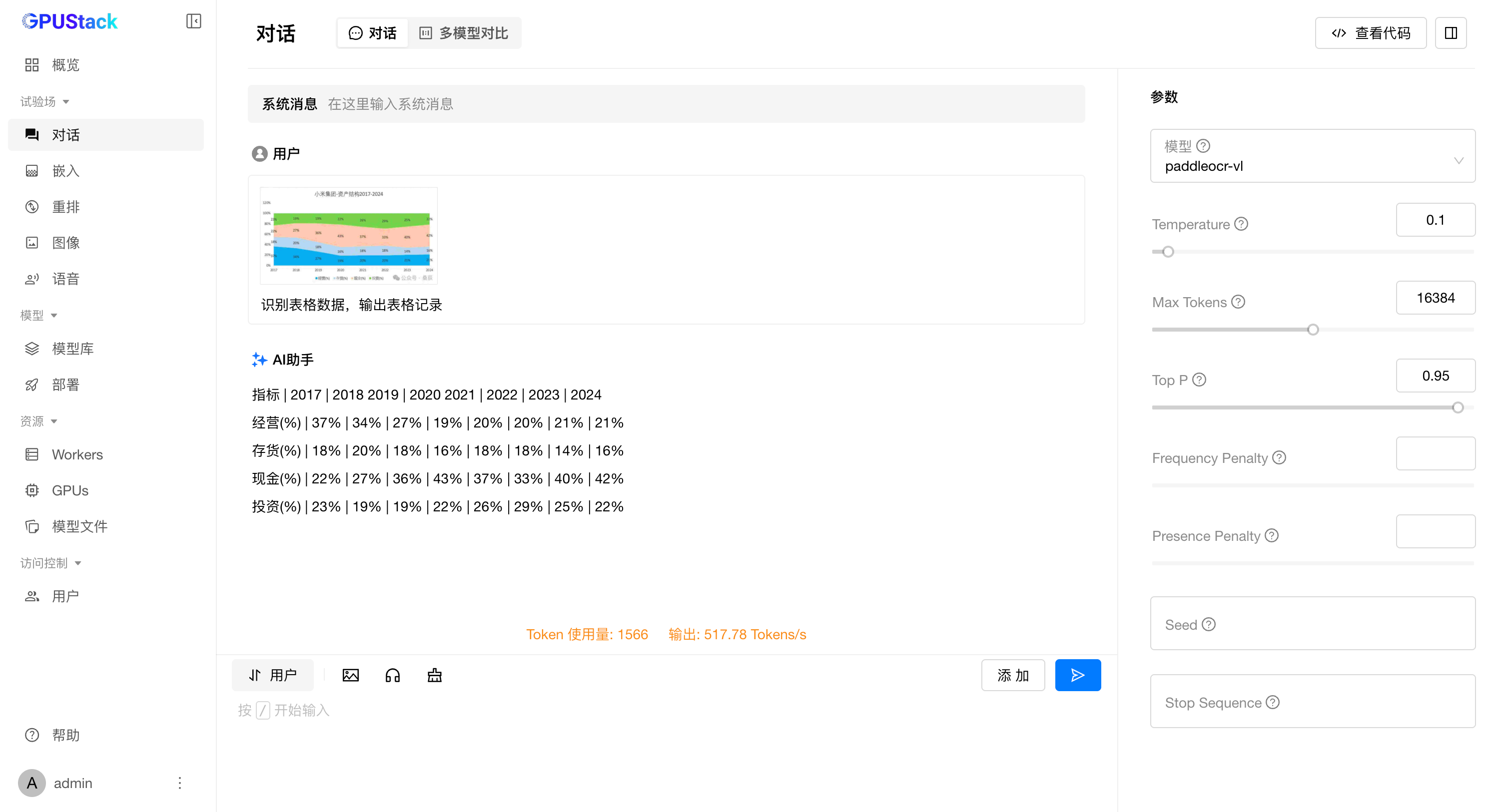
在大模型与推理技术高速演进的浪潮中,新模型层出不穷,推理框架和技术路线也愈加多元。不同模型往往需要特定的后端、配置或依赖,如何在不牺牲灵活性和性能的前提下快速接入并高效运行,已经成为构建 AI 基础设施的关键课题。
在此背景下,GPUStack 正在加速迭代。下一个版本,我们将引入可插拔后端机制与通用 API 代理 —— 让用户能够自由定制任意的推理引擎与运行配置,像搭积木一样灵活打造 MaaS 平台。无论是前沿大模型,还是传统机器学习模型,都能在同一平台上被快速加载、无缝调用。
让每一个开发者、每一家企业,都能更轻松地跟上大模型技术的快速更迭,将创新更快地落地到真实场景中。我们共同见证 GPUStack 的下一次蜕变!

















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









