




关注🌟⌈GPUStack⌋ 💻
一起学习 AI、GPU 管理与大模型相关技术实践。
在昇腾 NPU 上部署超大规模模型,往往面临一个现实难题:目前主流的官方推理引擎 MindIE 的多机分布式推理虽然性能表现尚可,但配置流程异常复杂。从环境准备、配置初始化到参数细节调整,每一步都需要格外谨慎,否则极易因细节遗漏或配置错误而导致部署失败,问题定位也十分困难。
GPUStack 是一个100%开源的模型服务平台(MaaS,Model-as-a-Service),提供高性能推理与完善的模型服务管理能力,能够运行在 NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程、天数智芯、寒武纪、沐曦等多种 GPU 上,轻松构建异构 GPU 集群,支持 vLLM、MindIE、llama-box 等各种推理引擎。
为了降低部署门槛,GPUStack 提供了对 MindIE 分布式推理的完整封装和简化,用户只需少量 UI 配置,就能完成过去需要大量手动步骤、文档比对与重复调试的部署流程。相比原生方案,GPUStack 大幅简化了部署复杂度,减少了错误发生的可能性,使得在昇腾上运行大规模模型的过程更加高效、丝滑且稳定。
本文将带来一篇实践教程,演示如何通过 GPUStack 快速在昇腾上丝滑运行 MindIE 分布式推理,并部署以 DeepSeek R1 671B 为例的超大规模模型。
前提条件
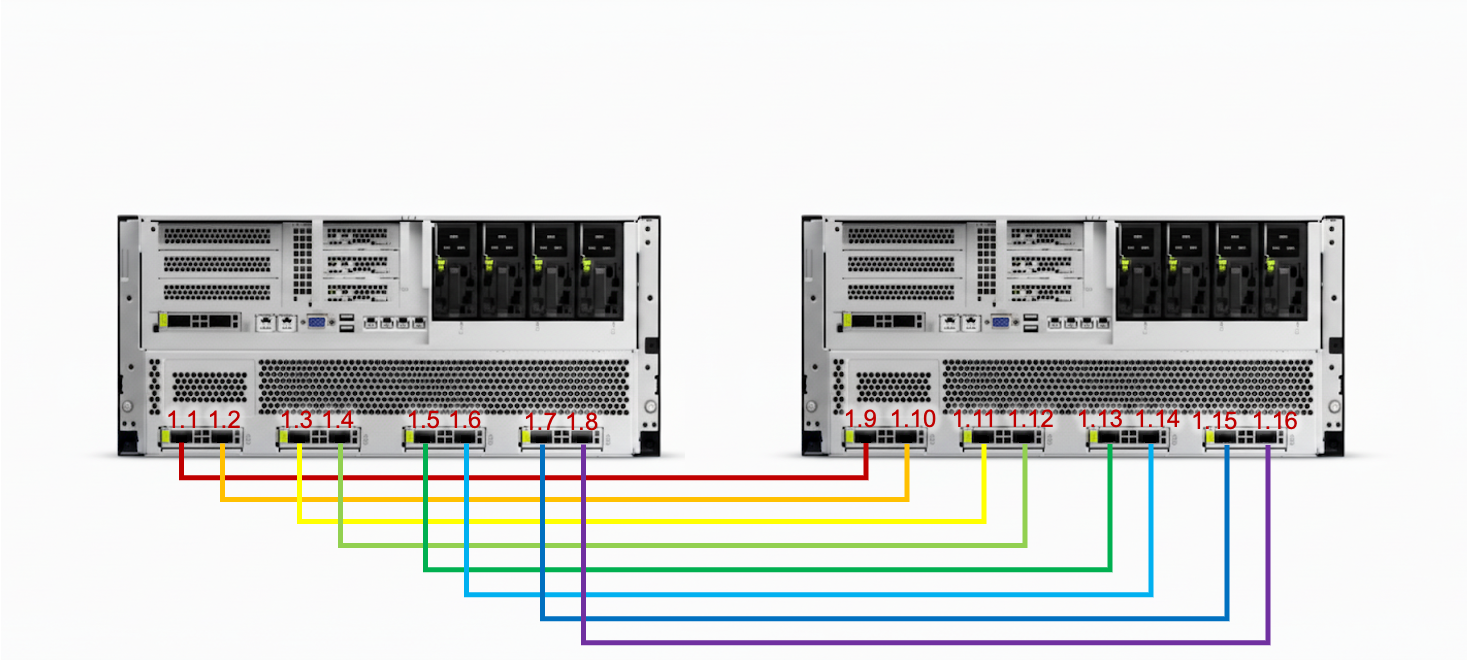
- 多台
Atlas 800T A2(8 卡 910B)服务器,通过 HCCN 实现多机 RoCE 组网
以双机场景为例,两台服务器的 NPU 之间通过 200 Gbps 光模块进行一对一光纤直连。当扩展到多机时,则需通过 RoCE 交换机实现 NPU 间的高速互联。
- 已安装 NPU 驱动和相应固件(https://www.hiascend.com/hardware/firmware-drivers/community?product=4&model=26&cann=8.2.RC1&driver=Ascend+HDK+25.2.0)
在 GPUStack v0.7.1 镜像中,内置的 CANN 版本为 8.2.RC1,该版本依赖 25.2 及以上驱动。用户可通过执行以下命令检查当前驱动版本:
npu-smi info
注意,在后续安装或升级时,应根据镜像中所包含的 CANN 版本,选择与之匹配的驱动版本,以确保功能正常。
- 通过
hccn_tool(/usr/local/Ascend/driver/tools/hccn_tool)配置:
- NPU 设备 RoCE 网卡的 IP
- 网关(按需,仅跨 L3 需要)
- 网络检测对象 IP(双机直连为对端 NPU 设备 IP,多机互联为任一对端节点 NPU IP,L3 则为网关 IP)
在每个节点上,通过以下命令检查并优化 RoCE 配置:
# 1.检查物理链接
for i in {
0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done
# 2.检查链接情况
for i in {
0..7}; do hccn_tool -i $i -link -g ; done
# 3.检查网络健康情况
for i in {
0..7}; do hccn_tool -i  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









