



继续来更新LeetCode的学习,本Part对应左神视频036-041。学习的过程比较慢,最近事情也多了,随缘更新。
一、二叉树高频题目
主要是不含动态规划的二叉树高频题,题目数量很多。
1.二叉树层序遍历
之前提到过二叉树的前中后序遍历,这次的层序遍历就是每次将一层的二叉树放入一个数组,最终将所有层的结果合并成一个大的数组。比如下图的层序遍历就是[[1],[2,3],[4,5,6,7],[8,9]]。
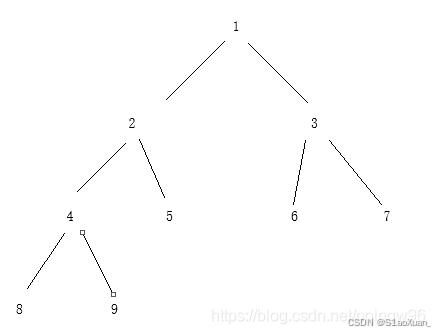
有两种思路,第一种:准备一个队列和字典,字典的key是该节点的值,value是该节点所在的层数。首先将1,放入队列,在map中记录该值在第一层,之后弹出1,有左节点加入左节点右右节点加入右节点并记录节点的所在的层,此时队列里以此加入2,3,再弹出2(队列先进先出),再重复之前的操作,我们将在同一层的放在一个数组中,最后都加入到大数组即可。但是这样子不好的地方就是一次只能弹出一个数,还得有个字典记录所在的层。
第二种思路:用数组实现队列,初始的L,R指针都是0,用size记录队列的长度,加入的时候放在R位置,R++,移除的时候放在L位置L++。首先加入1,此时size是1,弹出1,有左加左有右加右,此时队列中size为2,有2,3,重复size=2遍,弹出L位置,L++和有左加左有右加右,我一次就把一层的都弹出了,又加入了所有的下一层,size就表示当前层有多少数据。
代码只实现了第二种,因为第一种后续的题目仍会使用。
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if root==None:
return []
l=r=0
deque = [root]
r +=1
result = []
while l<r:
size = r-l
temp = []
for i in range(size):
cur = deque[l]
l+=1
if cur.left!=None:
deque.append(cur.left)
r+=1
if cur.right!=None:
deque.append(cur.right)
r+=1
temp.append(cur.val)
result.append(temp)
return result 2.二叉树的锯齿形层序遍历
也很好理解,就是第一题我的遍历方向每层换一下。我加入时分为L~R-1和R-1~L两种即可。
# self.right = right
class Solution:
def zigzagLevelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if root == None :
return []
l=r=0
deque = [root]
r+=1
reverse = False #从左向右
result = []
while l<r:
size = r-l
temp = []
for i in range(size):
cur = deque[l]
l+=1
if cur.left!=None:
deque.append(cur.left)
r+=1
if cur.right!=None:
deque.append(cur.right)
r+=1
if not reverse:
temp.append(cur.val)
else:
temp.insert(0,cur.val)
reverse = not reverse
result.append(temp)
return result3.求二叉树最大特殊宽度
计算每层最左边不空的节点到最右边不空节点的宽度,中间有空节点也要计算,就是把最左最右的中间空节点也当成有节点,数每一层最多的节点数量,返回最多的。
首先这个也是层序遍历的一种,所以还是用第一题的思路,不过我们需要加一步,对于任何一个节点编号为i我们都可以计算其左右节点的编号,左:2*i+1,右2*i+2。我们在第一题的第一个思路时不是也有一个表来记录编号嘛,一样的思路。不过是用第二个思路,加一个数组记录节点的编码,记录每层的编号差最后取最大差值即可。
class Solution:
def widthOfBinaryTree(self, root: Optional[TreeNode]) -> int:
l=r=0
deque = [root]
r+=1
number_list = [1]
max_width = 0
while l<r:
size = r-l
max_width = max(max_width,number_list[r-1]-number_list[l]+1)
for i in range(size):
cur = deque[l]
index = number_list[l]
l+=1
if cur.left!=None:
deque.append(cur.left)
number_list.append(2*index+1)
r+=1
if cur.right!=None:
deque.append(cur.right)
number_list.append(2*index+2)
r+=1
return max_width4.求二叉树最大深度、求二叉树最小深度
最大深度很好求嘛,在当前节点,我问问左节点你这边还有多深,问问右节点你这边还有多深,如果空了就返回0,之后左右比个大小就行了,取更深的那个值,就可以递归下去了。
public static int maxDepth(TreeNode root) {
return root == null ? 0 : Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}最小深度也是要计算到叶节点,不过我们要每一步比最小,我们用递归实现。我到一个节点i,我依然问左边节点有多深,右边节点有多深,前提是左边得存在节点,右边存在节点,如果当前节点为空了,返回0,如果当前节点没有左右节点了说明到根节点了,返回1.有个trick,我们首先定义一个ldeep和rdeep为比较大的值,为啥呢?比如我这个节点i,没有左节点了,但是右边还有,那是不是这个节点是没有ldeep的,如果ldeep是一个比较小的值,有可能会误把ldeep当成深度小的往上传。
class Solution:
def minDepth(self, root: Optional[TreeNode]) -> int:
if root==None:
return 0
if root.left==None and root.right==None:
return 1
ldeep = 100000
rdeep = 100000
if root.left !=None:
ldeep = self.minDepth(root.left)
if root.right !=None:
rdeep = self.minDepth(root.right)
return min(ldeep,rdeep)+15.二叉树序列化和反序列化
首先我们得知道什么是序列化和反序列化。比如下面的树我们可以先序遍历生成一个字符串,我们将空节点定义为# -> 'a,b,#,#,c,d,#,#,#',之后我们知道了这个序列又知道他是先序产生的,就可以再解码出这个树。跟破译密码一样。
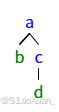
对于先序遍历的序列化和反序列化 ,我们在序列化的时候利用递归实现,如果遇到空就给字符串加个#。那么反序列化也用递归不过是反过来。
class Codec:
def __init__(self):
self.str_result = ''
self.cnt = 0
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
self.f(root)
return self.str_result
def f(self,root):
if root==None:
self.str_result += '#,'
else:
self.str_result += str(root.val)+','
self.f(root.left)
self.f(root.right)
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
self.cnt = 0
str_decoder = data.split(',')
return self.g(str_decoder)
def g(self,str_decoder):
cur = str_decoder[self.cnt]
self.cnt +=1
if cur == "#" or cur == '':
return None
else:
head = TreeNode(int(cur))
head.left = self.g(str_decoder)
head.right = self.g(str_decoder)
return head 层序遍历的序列化和序列化
序列化过程可以参考第一题的第一个思路,采用队列一次弹出一个元素到字符串,然后同时队列和字符串压入左右节点的值没有就在字符串里添加一个#。
反序列化也是一样,将给的字符串往队列里压入,弹出,如过遇到#就跳过,保证队列里只有有效的节点。
class Codec:
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
if root==None:
return ""
str_restule = ""
l=r=0
deque = [root]
r+=1
str_restule +=str(root.val)+","
while l<r:
cur = deque[l]
# str_restule +=str(cur.val)+","
l+=1
if cur.left:
str_restule +=str(cur.left.val)+","
deque.append(cur.left)
r+=1
else:
str_restule+="#,"
if cur.right:
str_restule +=str(cur.right.val)+","
deque.append(cur.right)
r+=1
else:
str_restule+="#,"
return str_restule
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
if len(data) ==0:
return None
data = data.split(",")
root = TreeNode(data[0])
l =0
deque=[root]
r =1
index = 1
while l<r:
cur = deque[l]
l+=1
cur.left = TreeNode(data[index]) if data[index] != "#" and data[index] != "" else None
index+=1
cur.right = TreeNode(data[index]) if data[index] != "#" and data[index] != "" else None
index+=1
if cur.left != None:
deque.append(cur.left)
r+=1
if cur.right != None:
deque.append(cur.right)
r+=1
return root因为中序遍历是无法序列化和反序列化的,中序遍历会出现不同的树结构对应一个字符串的情况。比如下图两种的中序遍历都是'1,1,#,1,#,#,#'。但是中序遍历与先序遍历结合是可以实现的。
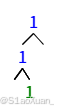
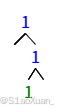
以下图的树为例,先序遍历是 a,b,d,c,e,中序遍历是,b,d,a,e,c。有个一点是可以确认的,先序的第一个元素一定是根节点,中序的最中间元素也一定是根节点,我们可以用一个map保存中序的节点与对应的位置关系方便查询。那么我们可以递归先序的最左边一定是中序的最中间,中序从最中间向最左边的元素,也可以在先序中找到对应长度的序列。 f(先,l,r,中,l,r),此时先序的l一定是子树的头节点,如果l==r了,说明我找到了最下层子树的头节点,左右节点分别往下递归寻找他的左子树和右子树即可。
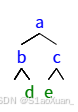
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
if preorder[0] == -1 or inorder[0] ==-1 or len(preorder)!= len(inorder):
return TreeNode(-1)
inorder_map = {}
for i in range(len(inorder)):
inorder_map[inorder[i]] = i
l1 = 0
r1 = len(preorder)-1
l2 = 0
r2 = len(inorder) -1
return self.f(preorder,l1,r1,inorder,l2,r2,inorder_map)
def f(self,preorder,l1,r1,inorder,l2,r2,map):
if l1 >r1:
return None
head = TreeNode(preorder[l1])
if l1==r1:
return head
k = map[preorder[l1]]
head.left = self.f(preorder,l1+1,l1+k-l2,inorder,l2,k-1,map)
head.right = self.f(preorder,l1+k-l2+1,r1,inorder,k+1,r2,map)
return head6.验证完全二叉树
完全二叉树是指,所有层都满了,或者某层不满时从左向右依次是有节点的,不能有跳过。
那其实我们和层序遍历一样,我们一个节点一个节点遍历,有两个条件去判断,1)这个节点不能有右节点但是没有左节点,存在这种情况直接判断不是完全二叉树。2)一旦发现改节点有左节点没有右节点,那么这个节点之后的所有节点都必须是叶子节点,否则直接判断不是完全二叉树。
class Solution:
def isCompleteTree(self, root: Optional[TreeNode]) -> bool:
if root ==None:
return True
l=r=0
deque=[root]
r+=1
leaf_node_sign = False
while l<r:
cur = deque[l]
l+=1
if cur.left!= None and cur.right!=None:
if leaf_node_sign:
return False
deque.append(cur.left)
r+=1
deque.append(cur.right)
r+=1
elif cur.left !=None and cur.right==None:
if leaf_node_sign:
return False
deque.append(cur.left)
r+=1
leaf_node_sign =True
elif cur.left==None and cur.right!=None:
return False
else:
leaf_node_sign =True
return True7.求完全二叉树的节点个数
我们根据完全二叉树的特性可以得出两个结论,当我的树高为h时,如果沿根节点的右节点向下统计子树的高度,如果子树也能到h层,说明这棵树从根节点看左子树是满的,否则这棵树从根节点看右子树的h-1层是满的。根据这个我们可以设计递归,对于任意子树都可以去看我的子树根节点的右树是不是可以到第h层,到了说明左边满了,继续右边递归,没到说明右边到h-1层满了,继续掉左树的递归。base case就是 到最后一层了,返回1即可。
class Solution:
def countNodes(self, root: Optional[TreeNode]) -> int:
if root == None:
return 0
return self.f(root,1,self.mostLeft(root,1))
def f(self,head,level,h):
if level==h:
return 1
if self.mostLeft(head.right, level+1) ==h: #level是head节点在的层数,所以right就是下一层
return (1<<(h-level)) + self.f(head.right,level+1,h)
else:
return (1<<(h-level-1)) + self.f(head.left,level+1,h)
def mostLeft(self,head,level):
while head:
head = head.left
level+=1
return level-18.普通二叉树上寻找两个节点的最近公共祖先
公共祖先有两种,一种两个节点存在包含关系,那么更上层的那个节点就是最近公共祖先,第第二种就是不存包含关系,此时两个节点属于不同的子树。直接对着代码解释,我们的递归条件就是,如果p为q的祖先那么只有p节点会向上返回,如果不是包含关系,我们沿着左边遍历,只有遇到了p或者q才会有返回值,沿着右边同理,那么对于返回值来说,如果不包含那么pq一一定会沿着某条路返回到同一个节点,该节点就是最近公共祖先,如果我最后只返回了一个不空的节点,说明一定是包含关系,返回不空的节点即可。
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if root == None or root == p or root ==q:
return root
l = self.lowestCommonAncestor(root.left,p,q)
r = self.lowestCommonAncestor(root.right,p,q)
if l and r:
return root
if l==None and r == None:
return None
return l if l else r9.二叉搜索树的最近公共祖先
二叉搜索树是指对于任意子树,其左半部分的最大值一定小于根节点的指,其右半部分的最小值一定大于根节点自己:左边所有值<自己的值<右边所有值
我们依次判断以下条件:
1)如果搜到p或者q,直接返回该节点
2)如果当前节点值小于min(p,q),那么pq,一定在右树上且不是当前节点
3)如果当前节点值大于max(p,q),那么pq,一定在左树上且不是当前节点
4)如果当前节点值满足 min(p,q) < cur.val<max(p,q),那么返回该节点
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
# while root.val!=p.val and root.val!=q.val:
# if min(p.val, q.val) < root.val and root.val < max(p.val, q.val):
# break
# root = root.right if root.val<min(p.val, q.val) else root.left
# return root
if root.val == p.val or root.val == q.val:
return root
if min(p.val, q.val) < root.val and root.val < max(p.val, q.val):
return root
if root.val<min(p.val, q.val):
return self.lowestCommonAncestor(root.right,p,q)
if root.val>max(p.val, q.val):
return self.lowestCommonAncestor(root.left,p,q)10.收集累加和等于aim的所有路径
重点是在回溯的时候要恢复现场,因为在该节点向左或者向右递归完成后,我希望下一此递归到此处状态不变。
我们定义了path变量用来收集路径,我就递归嘛,计算左边够不够目标,右边够不够目标,当到达叶子节点时,就该统计了,如果满足了,就把path加入到最终答案,但是如果不满足,我们要将path还原到其根节点的状态在向另一半递归,如果不还原,path就会记录所有去过的节点。
class Solution:
def __init__(self):
self.ans = []
self.temp_result =[]
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
temp_sum = 0
if root!=None:
self.f(root,targetSum,0)
return self.ans
def f(self,cur,targetSum,temp_sum):
if cur.left==None and cur.right==None:
if cur.val+temp_sum==targetSum:
self.temp_result.append(cur.val)
self.ans.append(self.temp_result[:]) ##很重要 拷贝副本
self.temp_result.pop()
else:
self.temp_result.append(cur.val)
if cur.left:
self.f(cur.left,targetSum,temp_sum+cur.val)
if cur.right:
self.f(cur.right,targetSum,temp_sum+cur.val)
self.temp_result.pop()11.验证平衡二叉树
平衡二叉树就是对每个节点,左树的高度与右树的高度差<=1。
那就是分别递归计算左树的高度,右树的高度,base case就是到空节点了返回0,如果发现不平衡了就把标志位记成fasle。当我已经发现不平衡了,树的高度就无所谓了,让递归结束就行。
class Solution:
def __init__(self):
self.balance = True
def isBalanced(self, root: Optional[TreeNode]) -> bool:
self.height(root)
return self.balance
def height(self,cur):
if not self.balance or cur==None:
return 0
lh = self.height(cur.left)
rh = self.height(cur.right)
if abs(lh-rh)>1:
self.balance=False
return max(lh,rh)+112.验证搜索二叉树
如果用非递归的方法很简单,直接中序遍历,保证最后的结果严格递增即可。
用递归的方法:我在节点i,我只用去看左边的节点的最大最小值是多少,右边节点的最大最小值是多少,节点i满足搜素二叉树吗,我的左树满足搜索二叉树吗,我的右树满足搜索二叉树吗
class Solution:
# 中序遍历 保证完全递增 非递归
# def isValidBST(self, root: Optional[TreeNode]) -> bool:
# pre = None
# while root:
# stack = []
# while len(stack)!=0 or root:
# if root:
# stack.append(root)
# root = root.left
# else:
# root = stack.pop()
# if pre and pre.val >= root.val:
# return False
# pre = root
# root = root.right
# return True
def __init__(self):
self.min = -2**31
self.max = 2**31-1
def isValidBST(self, root: Optional[TreeNode]) -> bool:
if root== None:
self.min = 2**31
self.max = -2**32
return True
lok = self.isValidBST(root.left)
lmin = self.min
lmax = self.max
rok = self.isValidBST(root.right)
rmin = self.min
rmax = self.max
self.min = min(min(lmin,rmin),root.val)
self.max = max(max(lmax,rmax),root.val)
return lok and rok and lmax<root.val<rmin13. 修建搜索二叉树
我要将一颗搜索二叉树修剪成[min,max]范围,不在这个范围的去掉。
如果我当前节点值比min还小,那我就应该去右边寻找,否则去左边。我的左节点就是满足条件的左边,右节点就是满足条件的右边。
class Solution:
def trimBST(self, root: Optional[TreeNode], low: int, high: int) -> Optional[TreeNode]:
if root==None:
return None
if root.val<low:
return self.trimBST(root.right,low,high)
if root.val>high:
return self.trimBST(root.left,low,high)
root.left = self.trimBST(root.left,low,high)
root.right = self.trimBST(root.right,low,high)
return root14.二叉树打家劫舍
小偷不能偷二叉树的相邻节点,如何偷取累计最大值。
我们定义全局变量yes和no,yes表示如果偷取了当前节点遍历子树之后能偷到的最大值,no表示不偷取当前节点遍历子树之后能偷到的最大值。那么对于该节点的上层节点就有两种选择,我们假设a是根节点,bc分别为左右节点,ayes = a.val + bno+cno,ano=max(bno,byes)+max(cno,cyes),更新此时的yes和no,最后比较yes和no哪个大即可。
class Solution:
def __init__(self):
self.yes=0
self.no=0
def rob(self, root: Optional[TreeNode]) -> int:
self.f(root)
return max(self.yes,self.no)
def f(self,root):
if root==None:
self.yes = 0
self.no = 0
else:
y = root.val
n =0
self.f(root.left)
y+=self.no
n+=max(self.yes,self.no)
self.f(root.right)
y+=self.no
n+=max(self.yes,self.no)
self.yes = y
self. no = n二、常见递归过程解析
递归属于那种看代码觉得十分简单,仔细推理觉得十分巧妙,自己去想觉得十分烧脑的一种,我最近看B站发现一个图可以非常好的帮助我们去理解递归,去构思递归。我们下面的所有题目都可以通过这个图的思路去拆解题目。
比较迷惑的是这个超级操作和微操作,就是我们将递归分为两个大步,比如f(n) = f(n) + f(n-1)那么这个就是超级操作,具体f(n)实现了什么就是微操作

1.子集 II
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
这个题目如果是数组有序,那么就可以用递归的思想去做。比如有一个数组排序完成之后是[1,1,1,1,2,2,2,3,3,4,4,4],那么我们从整体的眼光看,对于数字1,就是包含几个1的问题,不论包含几个1子问题都是从下标4开始出发,因为2!=1了,开始新的整体了。那么此时超级操作就是这一步应该有几个1和其余部分有什么组合。基础情况就是到数组的最后一个元素了将该步的答案保存到整体答案中。
class Solution:
def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
nums.sort()
path=[0]*len(nums)
self.ans=[]
self.f(nums,0,path,0)
return self.ans
def f(self,arr,i,path,size):
if i == len(arr):
self.ans.append(path[:size])
else:
j = i+1
while j<len(arr) and arr[i] ==arr[j]:
j+=1
self.f(arr,j,path,size)
while i<j:
path[size] = arr[i]
size +=1
self.f(arr,j,path,size)
i+=12.全排列
[1,2,3] -> [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,2,1],[3,1,2]] 所有的排列组合
对于任意长度的数组,对于i位置,我和从我这个位置开始所有后面的数字一一交换位置,之后我再去统计交换后从i+1位置开始有哪些排列组合就行了。按照这个逻辑,我前面的数字肯定已经和我交换过了。并且我交换完统计完之后,我必须再次回到i位置,不然数组的顺序就乱了。如果i位置已经到最后数组最后了,说明此时数组已经排列完了,将此时数组的压入到答案数组中,开始向上返回。
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
ans=[]
self.f(nums,0,ans)
return ans
def f(self,nums,i,ans):
if i == len(nums):
ans.append(nums[:])
else:
for j in range(i,len(nums)):
self.swap(nums,i,j)
self.f(nums,i+1,ans)
self.swap(nums,i,j)
def swap(self,num,i,j):
temp = num[i]
num[i] = num[j]
num[j] = temp3.全排列 II
跟上一个题的区别就是数组中有重复的数字了。按照上一题的逻辑就会出问题了,因为和自己相同的数字交换是没有意义的,出来的组合会重复。所以我们在交换时判定一下,只有数字不相同才会交换,我们可以用一个hashset来存储交换过的数字
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
ans=[]
self.f(nums,0,ans)
return ans
def f(self,nums,i,ans):
if i == len(nums):
ans.append(nums[:])
else:
temp_set = set()
for j in range(i,len(nums)):
if not nums[j] in temp_set:
temp_set.add(nums[j])
self.swap(nums,i,j)
self.f(nums,i+1,ans)
self.swap(nums,i,j)
def swap(self,num,i,j):
temp = num[i]
num[i] = num[j]
num[j] = temp4.用递归逆序一个栈
首先我们先实现一个功能就是把一个栈最底下的元素取出来并且不改变其余元素的相对位置,也不申请新的空间。类似于[c,b,a] ->取出c 栈变成[b,a]。思路就是我把最上面的数弹出,看看是不是到底了, 没到就继续弹出,到了就记录这个数字,让上一层的数再压入栈就行了。
def bottomup(self, stack):
ans = stack.pop()
if len(stack) == 0:
return ans
else:
last = self.bottomup(stack)
stack.append(ans)
return last有个这个函数就很简单了,对于一个栈,我们一直利用这个函数取出最底部的元素,当栈空了再返回并压入当前的数。
def reverse(self,stack):
if len(stack) ==0:
return
num = self.bottomup(stack)
self.reverse(stack)
stack.append(num)
return stack5.用递归排序一个栈
我们要完成多个操作
1)用递归统计栈的深度。一直弹出直到栈空了,返回0,返回上一层压入当前层的值并depth+1,返回该层的深度
2)用递归统计深度为d时,最大值是多少。其实和统计深度一样,一直弹出到栈空了,返回一个很大的负值,之后对每一层比较取较大的数值返回到上一层,并且将该层的值压入到栈。
3)用递归统计深度为d,最大值为max时,有几个max值。也和统计深度一样,多一个判断该层的值是否为max,是了话计数+1不是就计数+0,在返回计数值给上一层。
4)用递归将深度为d时,将出现t次的max值压入到栈的最底部并且其他数字保持不变。一直弹出直到空了,此时直接压入t个max值,然后返回上一层并且只有当前层的值不是max时再压入到栈中。
最后就是对于这个栈,我先统计所有长度下将最大值放入最底下,之后将长度变成没排序的部分继续即可。
class SortStackWithRecursive():
def sortstack(self,stack):
depth = self.deep(stack)
while depth>0:
max = self.stack_max(stack,depth)
times = self.times(stack,depth,max)
self.down(stack,depth,max,times)
depth -=1
def deep(self, stack):
if len(stack) == 0:
return 0
num = stack.pop()
depth = self.deep(stack) + 1
stack.append(num)
return depth
def stack_max(self, stack, depth):
if depth == 0:
return -2 ** 32
num = stack.pop()
rest_max = max(num, self.stack_max(stack, depth - 1))
stack.append(num)
return rest_max
def times(self, stack, depth, max_num):
if depth == 0:
return 0
num = stack.pop()
resttime = self.times(stack, depth - 1, max_num)
if num == max_num:
resttime += 1
stack.append(num)
return resttime
def down(self,stack,depth,max_num,times):
if depth==0:
for i in range(times):
stack.append(max_num)
else:
num = stack.pop()
self.down(stack,depth-1,max_num,times)
if num!=max_num:
stack.append(num)6.汉诺塔打印问题
这个问题也算是递归最经典的问题了,对于一个汉诺塔我们的超级操作就是将除了最后一层的全部碟子移动到辅助柱子,将最下面的碟子移动到目标柱子,再把其余所有的碟子从辅助柱子移动到目标柱子,递归过程中如果只剩一个碟子了,那就直接从碟子在的位置移动到目标位置就行,完事。
class TowerOfHanoi():
def hanoi(self,n):
if n>0:
self.f(n,'左','中','右')
def f(self,n,now,to,other):
if n==1:
print('将第'+str(n)+'号圆盘从'+now+'移动到'+to)
else:
self.f(n-1,now,other,to)
print('将第' + str(n) + '号圆盘从' + now + '移动到' + to)
self.f(n-1,other,to,now)三、嵌套类问题
大概过程:
1)定义全局变量 int where
2)递归函数f(i) : s[i..],从i位置出发开始解析,遇到 字符串终止 或 嵌套条件终止 就返回
3)返回值是f(i)负责这一段的结果
4)f(i)在返回前更新全局变量where,让上级函数通过where知道解析到了什么位置,进而继续
执行细节:
1)如果f(i)遇到 嵌套条件开始,就调用下级递归去处理嵌套,下级会负责嵌套部分的计算结果
2)f(i)下级处理完成后,f(i)可以根据下级更新的全局变量where,知道该从什么位置继续解析
什么是嵌套类问题直接看题就能理解。
1.含有嵌套的字符串解码
比如对于"3[a]2[bc]"->aaabcbc,就是这样解码
那我们用上面的过程来套公式,对于"ab2[ac3[b]ef]kt",初始where=0,path=ab,cur=2(提示后面部分应该重复几次),遇到"["了,where更新为4,进入下一层递归,path1=ac,cur=3遇到了"[",更新where = 8,进行下一层递归 path2=b 此时遇到了"]",该返回了 path1更新为acbbbef,又遇到了']",返回上一层,path更新为abacbbbefacbbbefkt结束。
class Solution:
def decodeString(self, s: str) -> str:
self.where = 0
list_str = list(s)
result_list = self.f(list_str,0)
return ''.join(result_list)
def f(self,s,i):
path = []
cur = 0
while i<len(s) and s[i] !=']':
if 'a'<=s[i]<='z' :
path.append(s[i])
i+=1
elif '0'<=s[i]<='9':
cur=10*cur + int(s[i])
i+=1
elif s[i] == '[':
temp = self.f(s,i+1)
path.append(''.join(temp) * cur)
cur=0
i = self.where+1
self.where = i
return path2.含嵌套的分子式求原子数量
比如说Mg(OH)2->{'H': 2, 'Mg': 1, 'O': 2},按照字典序返回
那么在整个分子式中只会出现大写,小写,左右括号和数字这五种字符串,并且小写一定是跟在大写后面的,所有我们主要关注大写字母和左括号,遇到这两个符号说明目前的部分要结算了,并且要开始递归了。
旧的部分包括两个name对应原子的名称,cnt对应有几个该原子,并且建立一个map其中key是name,value是cnt,方便后续增加,每个旧的部分都会有这些,最终每个部分的表会加入到一个总表返回,并且注意,没有数字意味着1.其余整体逻辑和上一题差不多。
class Solution:
def countOfAtoms(self, formula: str) -> str:
self.where = 0
list_formula = list(formula)
result_map = self.f(list_formula,0)
sorted_keys = sorted(result_map)
result = ''
for key in sorted_keys:
result += str(key) + (str(result_map[key]) if result_map[key]>1 else "")
return result
def f(self,list,i):
name = ''
map_result = {}
map_temp ={}
cnt = 0
while i<len(list) and list[i]!=')':
if 'A'<=list[i]<='Z' or list[i]=='(':
self.fill(map_result,name,map_temp,cnt)
map_temp = {}
name=''
cnt=0
if 'A'<=list[i]<='Z':
name += list[i]
i+=1
else:
map_temp = self.f(list,i+1)
i = self.where+1
elif 'a'<=list[i]<='z':
name+=list[i]
i+=1
elif '0'<=list[i]<='9':
cnt = 10*cnt + int(list[i])
i+=1
self.fill(map_result,name,map_temp,cnt)
self.where = i
return map_result
def fill(self,map_result,name,map_temp,cnt):
if len(name) >0 or map_temp:
cnt = 1 if cnt==0 else cnt
if len(name) > 0:
key = name
if key in map_result:
map_result[key] = map_result[key]+cnt
else:
map_result[key] =cnt
else:
for key in map_temp:
if key in map_result:
map_result[key] = map_result[key]+map_temp[key]*cnt
else:
map_result[key] =map_temp[key]*cnt四、N皇后问题
对于一个N*N的格子,放下N个皇后有几种方法,并且使皇后彼此之间不能相互攻击,皇后可以攻击同一列同一行和左右对角线的皇后。
1)用数组实现:
我定义一个长度为n的数组a,a[0]就表示在第一行皇后放在了哪一列,我去判断下一行此时能有哪些位置满足条件(对角线上不能放的条件是 |当前行-之前行|==|当前列-之前列|),然后递归到下一行,最终到最后一行了就返回1,说明存在一种可能的摆放。如果到不了最后一行只能返回0了,说明此时无解。
2)用位运算实现:
数组过于占用空间,我们也可以用一个n位的数字col来表示,0-n-1位,表示第几列放了皇后,我们其实并不在意具体是怎么放的,我们只在意有几种方法,当我这个n位都是1时说明找到了一种方法。列的信息用位信息限制,对角线的限制可以用移位操作来实现,比如下图1代表皇后位置,此时col = 0b00100,那么对于左下下一行不能放的位置就是col<<1位代表的位置,对于右下对角线就是col>>1位代表的位置,并且大于n位的数字不用考虑,小于0位的位置位操作自动忽略。
0 1 2 3 4
0 1
1 * *
2 * *
列和对角线的共同限制就是(col||left||right),那么~(col||left||right)就是下一行能放皇后的位置,我们一直取右边的1(a&(-a)),递归实现。
class Solution:
def totalNQueens(self, n: int) -> int:
if n<1:
return 0
limit = (1<<n)-1
return self.f(limit,0,0,0)
def f(self,limit,col,left,right):
if col==limit:
return 1
prob_postion = (~(col|left|right))&limit
ans = 0
while prob_postion !=0:
place = prob_postion&(-prob_postion)
prob_postion ^=place
ans += self.f(limit,col|place,(left|place)>>1,(right|place)<<1)
return ans
















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









