



1. GPU
1.1 GPU简介
GPU,即图形处理单元,是专为图形渲染而设计的处理器。其独特的并行计算能力使得它在处理大规模数据和复杂图形时表现出色。GPU不仅在游戏和虚拟现实领域发挥着关键作用,还广泛应用于深度学习、物理模拟和通用计算等领域。通过数以千计的核心,GPU能够同时处理多个任务,大幅提升计算效率。随着技术的不断进步,GPU的性能持续增强,成为推动科技发展的重要力量之一。无论是在科学研究还是工业应用中,GPU都展现出了其强大的计算能力和广泛的应用前景。
1.2 GPU相较于CPU的优点
GPU相较于CPU,优势显著。首先,GPU凭借强大的并行处理能力,能够同时处理大量数据单元,极大提升了计算效率,尤其在处理图形渲染、深度学习等大规模任务时表现出色。其次,GPU在浮点运算上性能卓越,适用于高精度计算需求。再者,GPU拥有高带宽内存,能迅速读写大量数据,满足数据处理和存储需求。最后,GPU在能效比上亦优于CPU,提供高效能的同时保持较低功耗。这些优势使得GPU在科学计算、图像处理、深度学习等领域发挥重要作用。
1.3 什么是GPU
经常打游戏的朋友都知道,在玩大型游戏的时候对电脑显卡要求尤为明显,否者会造成游戏画面卡顿或者成像质量较差。其实我们的电脑显卡就是GPU。
2. 搭配GPU环境
2.1 查询cuda和pytorch对应的版本
电脑本身安装的Cuda版本查询教学blogCUDA学习(一)——如何查看自己CUDA版本?_cuda version-优快云博客
为了安装对应的pytorch版本,我们打开pytorch官网Previous PyTorch Versions | PyTorch,打开后其官方会给出cuda的GPU模式版本和pytorch版本对应的关系,我查询到下载的CUDA的版本为12.1,对应的pytorch版本为2.3.0。
其搭配GPU版本的下载命令为
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=12.1 -c pytorch -c nvidia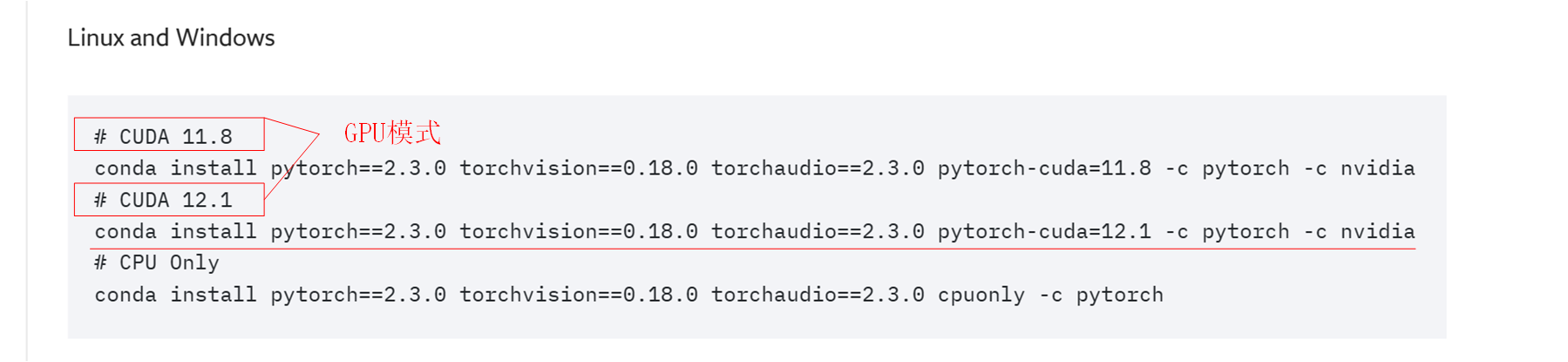
2.2 YOLOv8终端输入命令搭建GPU模块
在 2.1 中,我们详细介绍了如何根据Cuda版本选择相应的pytorch版本,之后我们将cuda下载命令输入终端即可,下载时间较长,请耐心等待。
2.3 测试GPU环境是否搭配成功
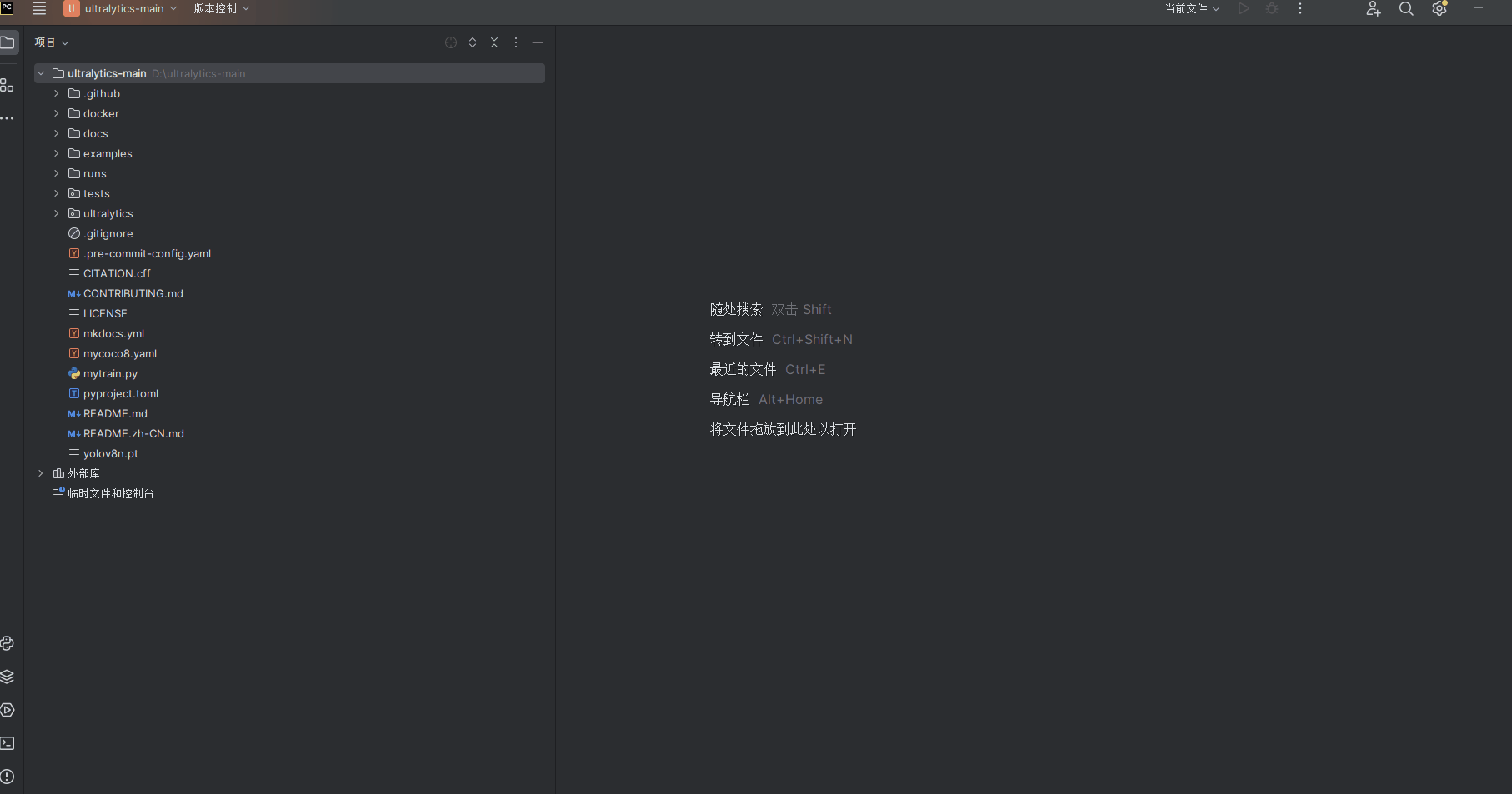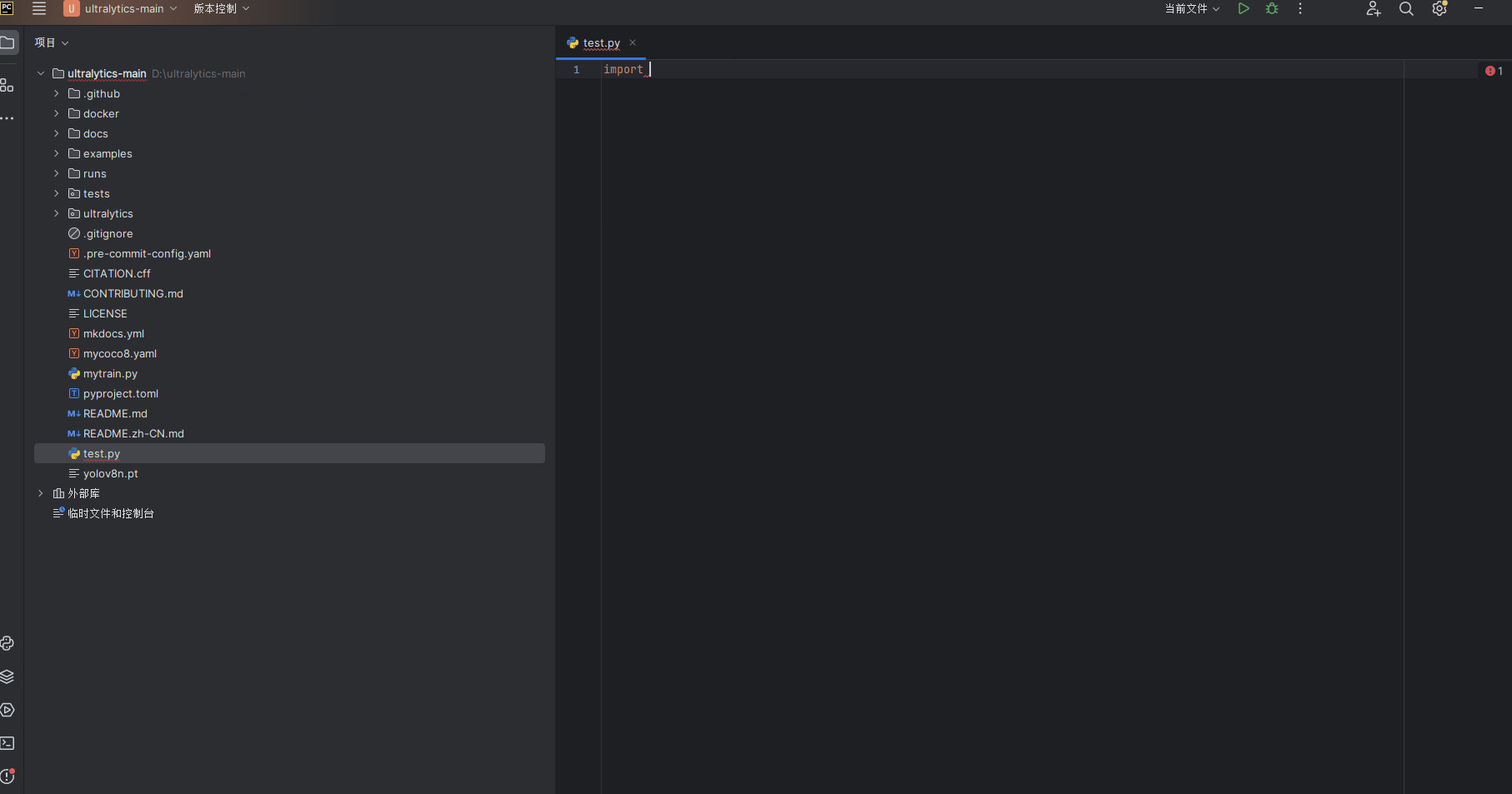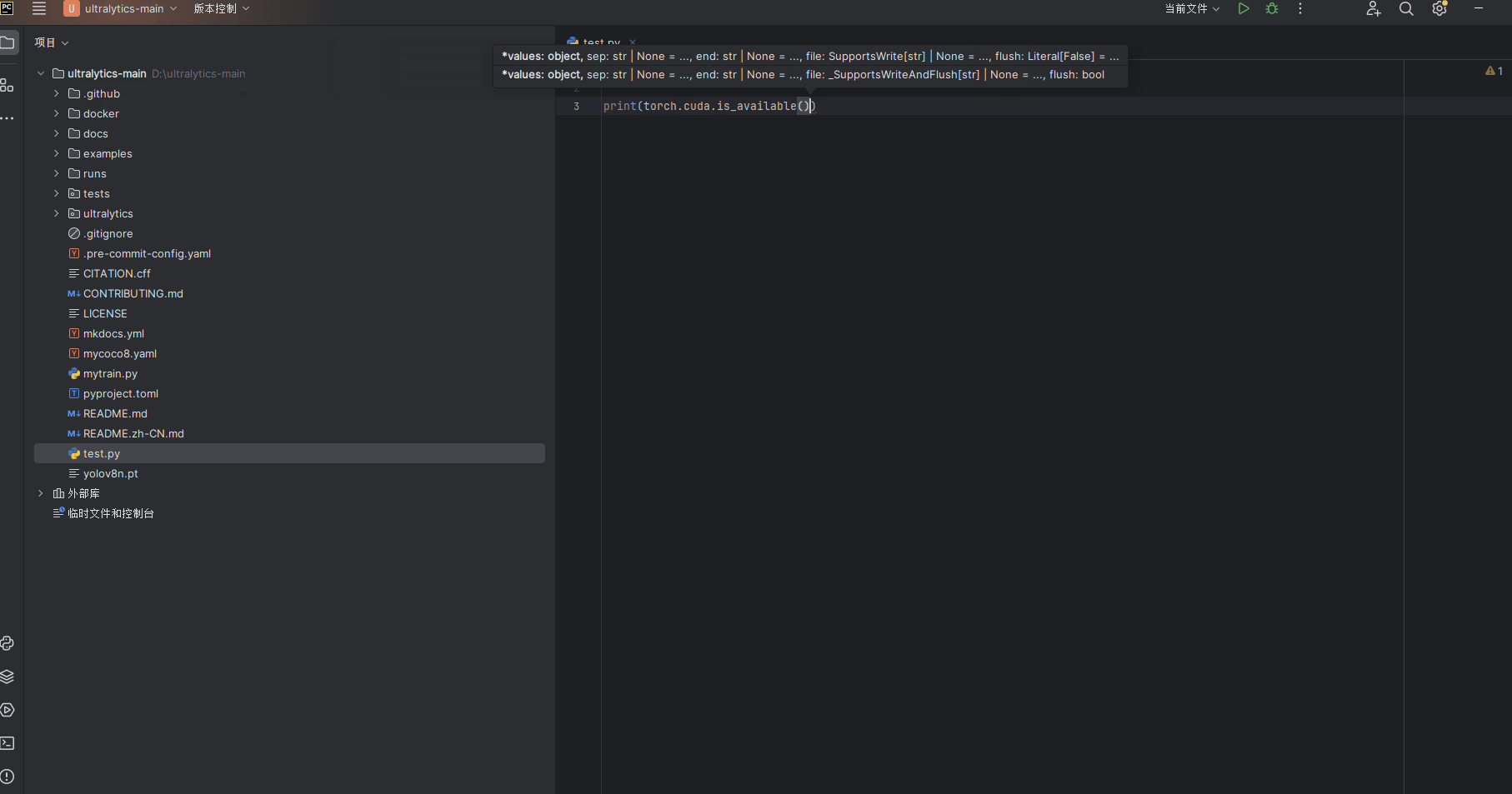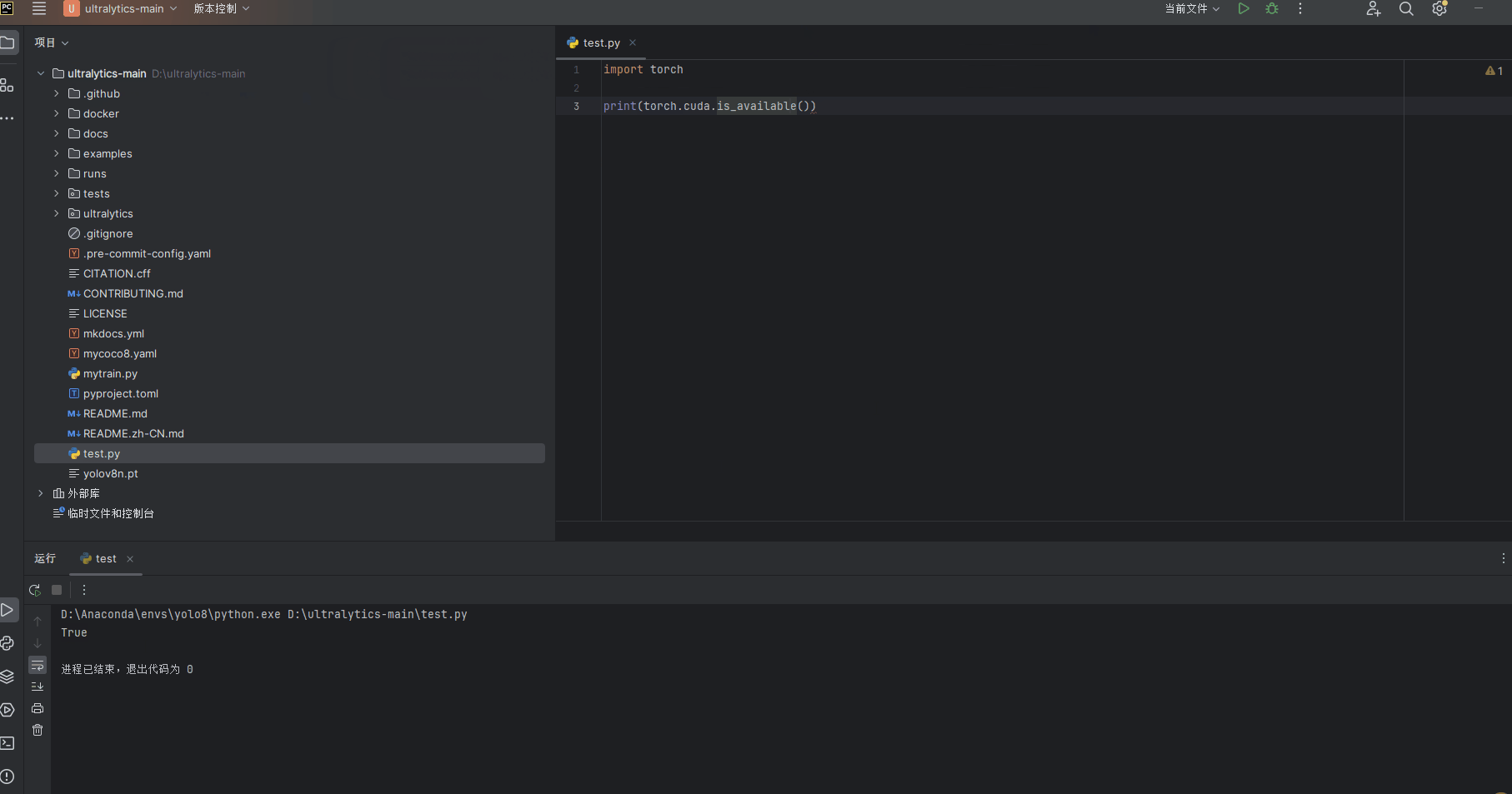
在完成GPU环境的搭建后,我们需要测试GPU是否安装成功。为此我们新建一个test.py的文件,输入以下命令,并且运行当前文件,test.py文件代码如下
import torch
print(torch.cuda.is_available())test.py文件运行结果如下,返回值为ture表明GPU安装成功
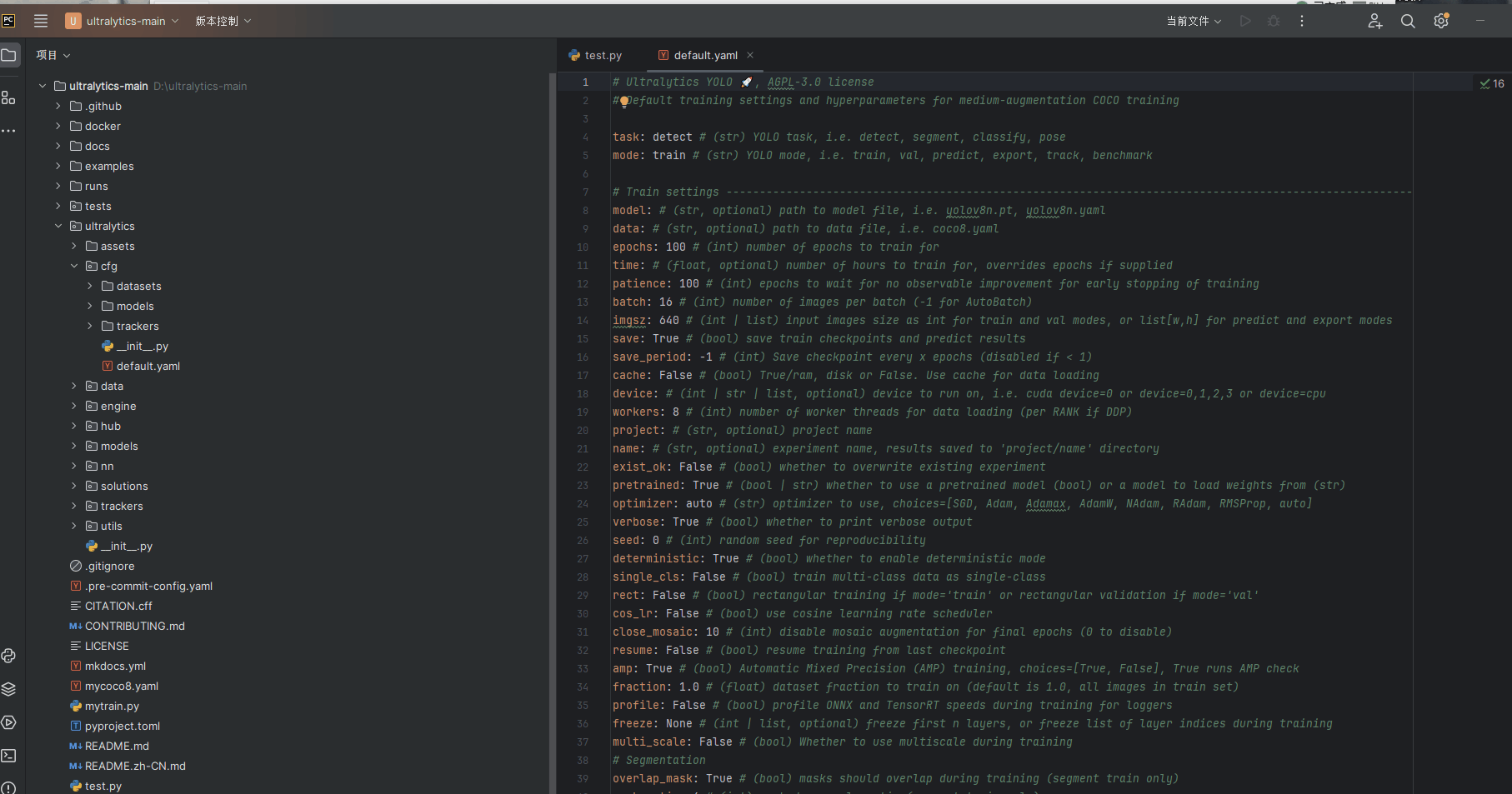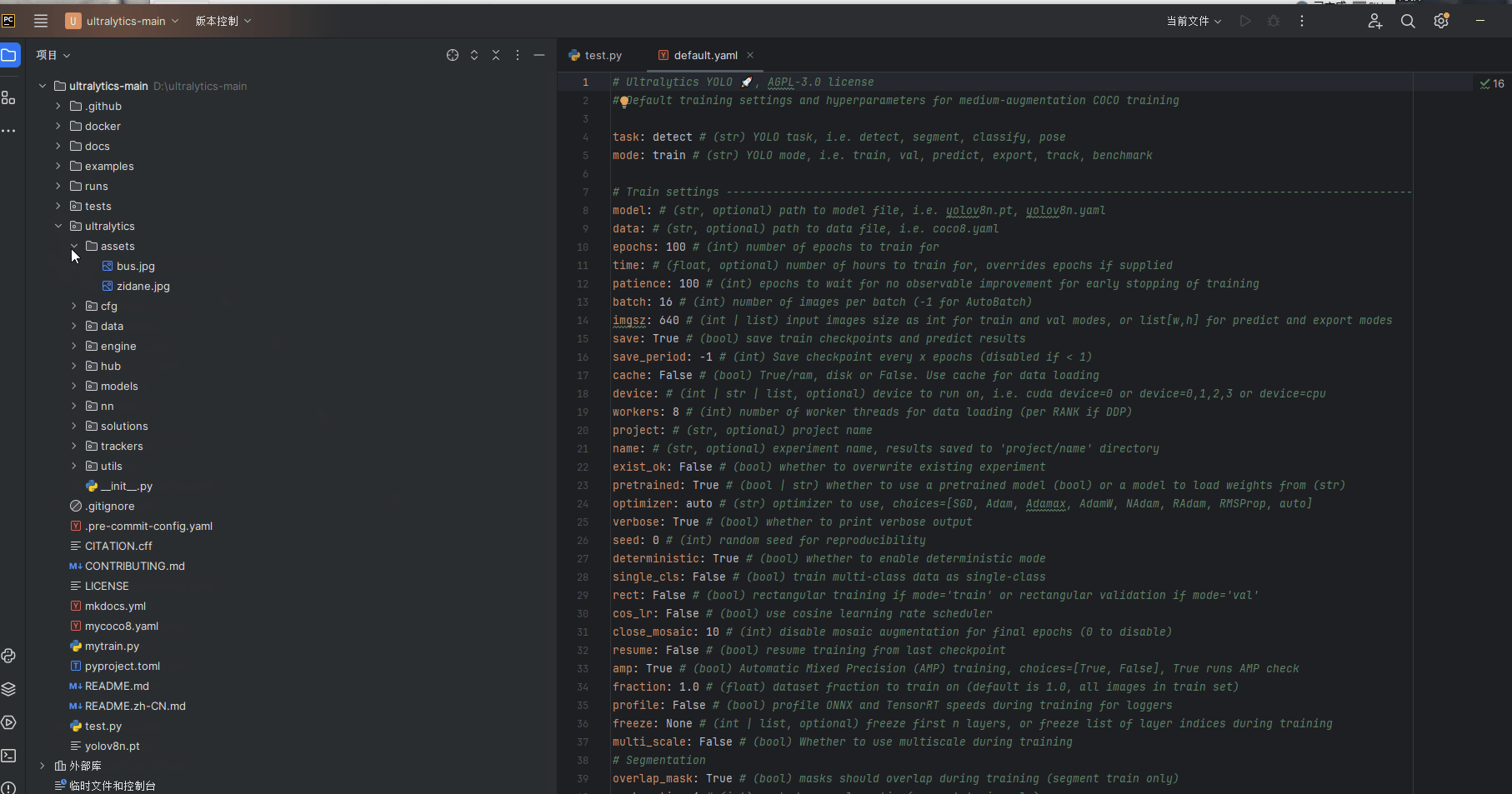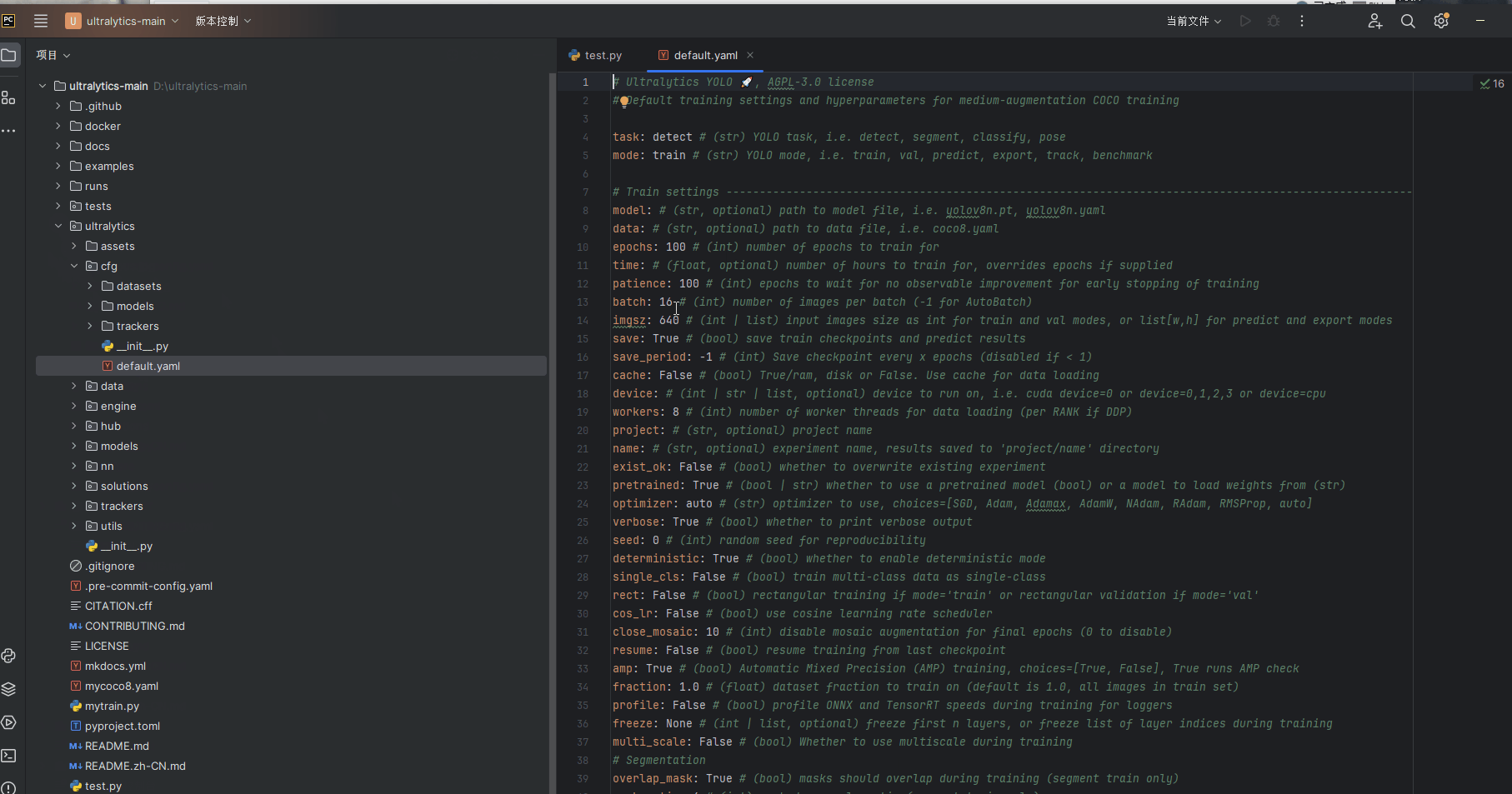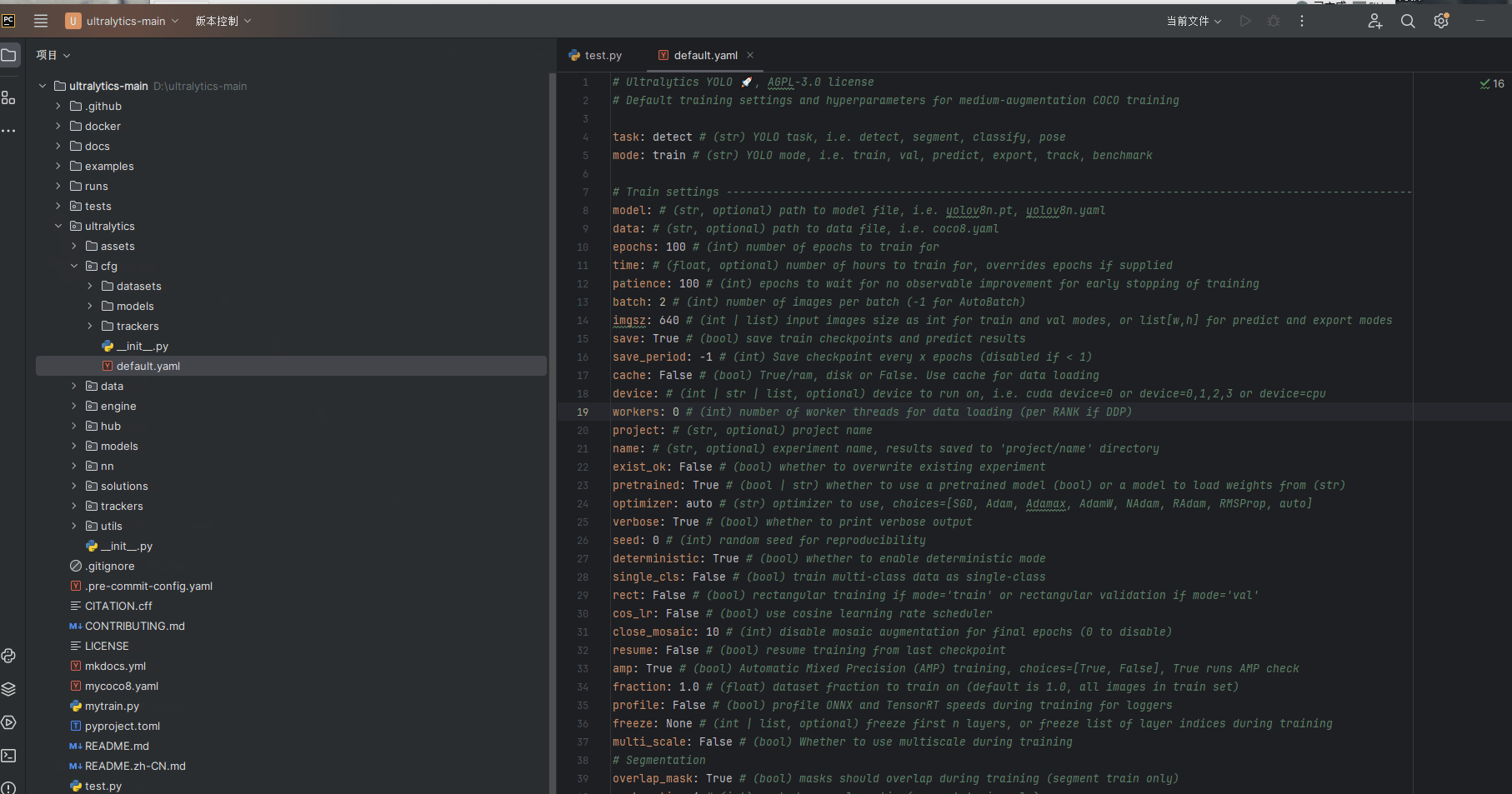
2.4 更改default.yaml文件的代码(不然GPU使用时会报错)
由于GPU是并行运行处理图片,但是我们电脑的内存可能会承受不住,因此需要yolov8的默认default.yaml文件 配置将batch 改为2 ,works 改为0
3. 测试
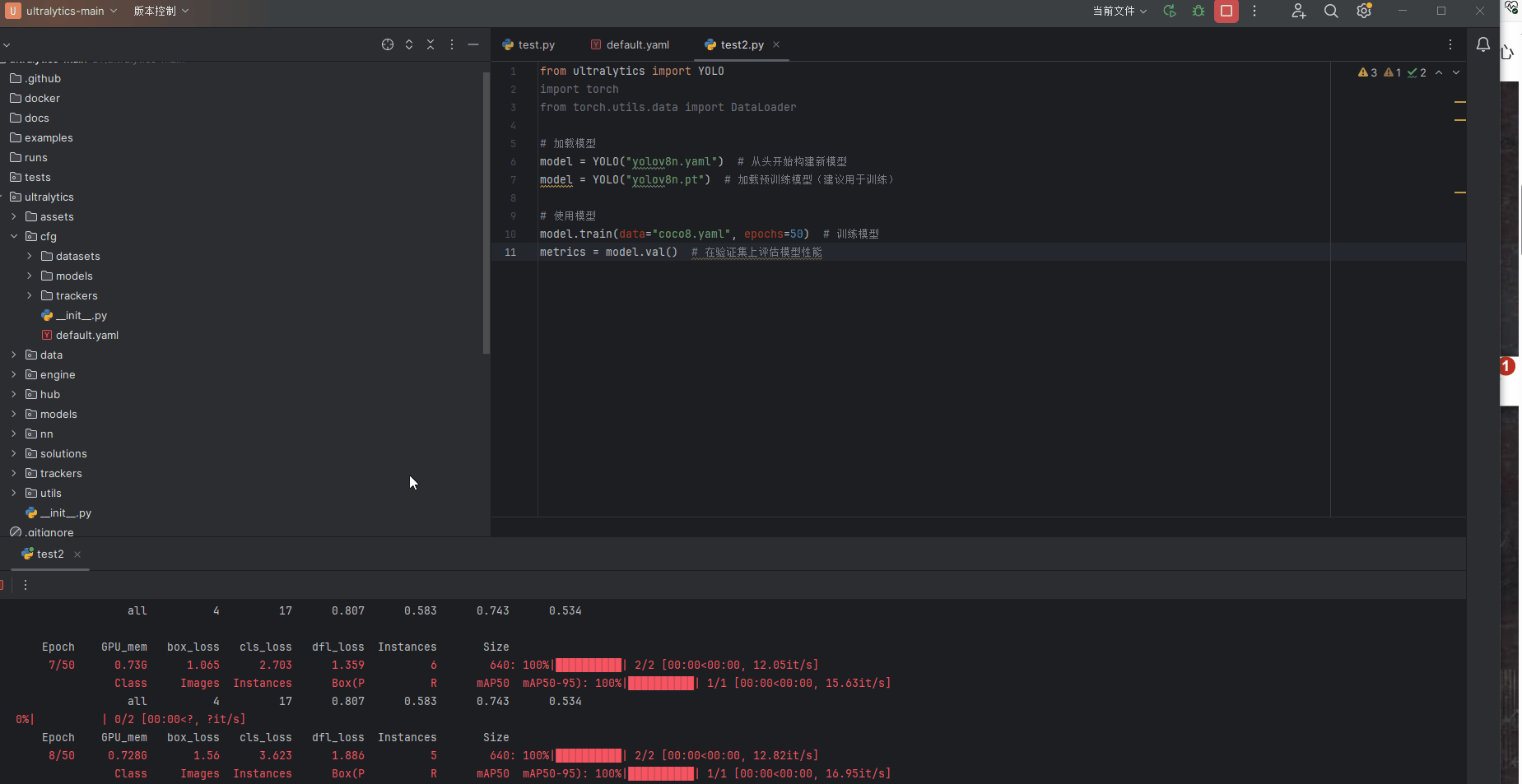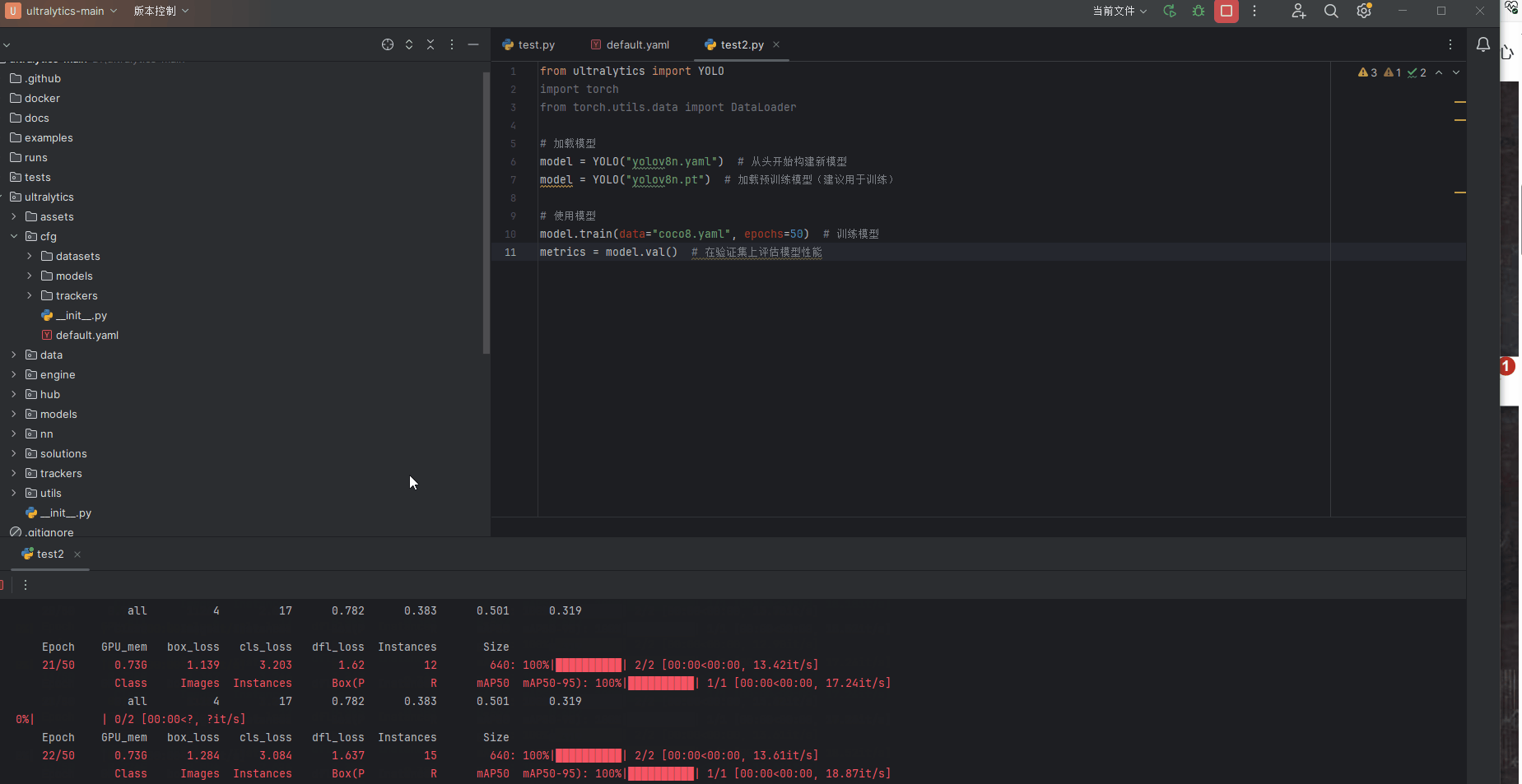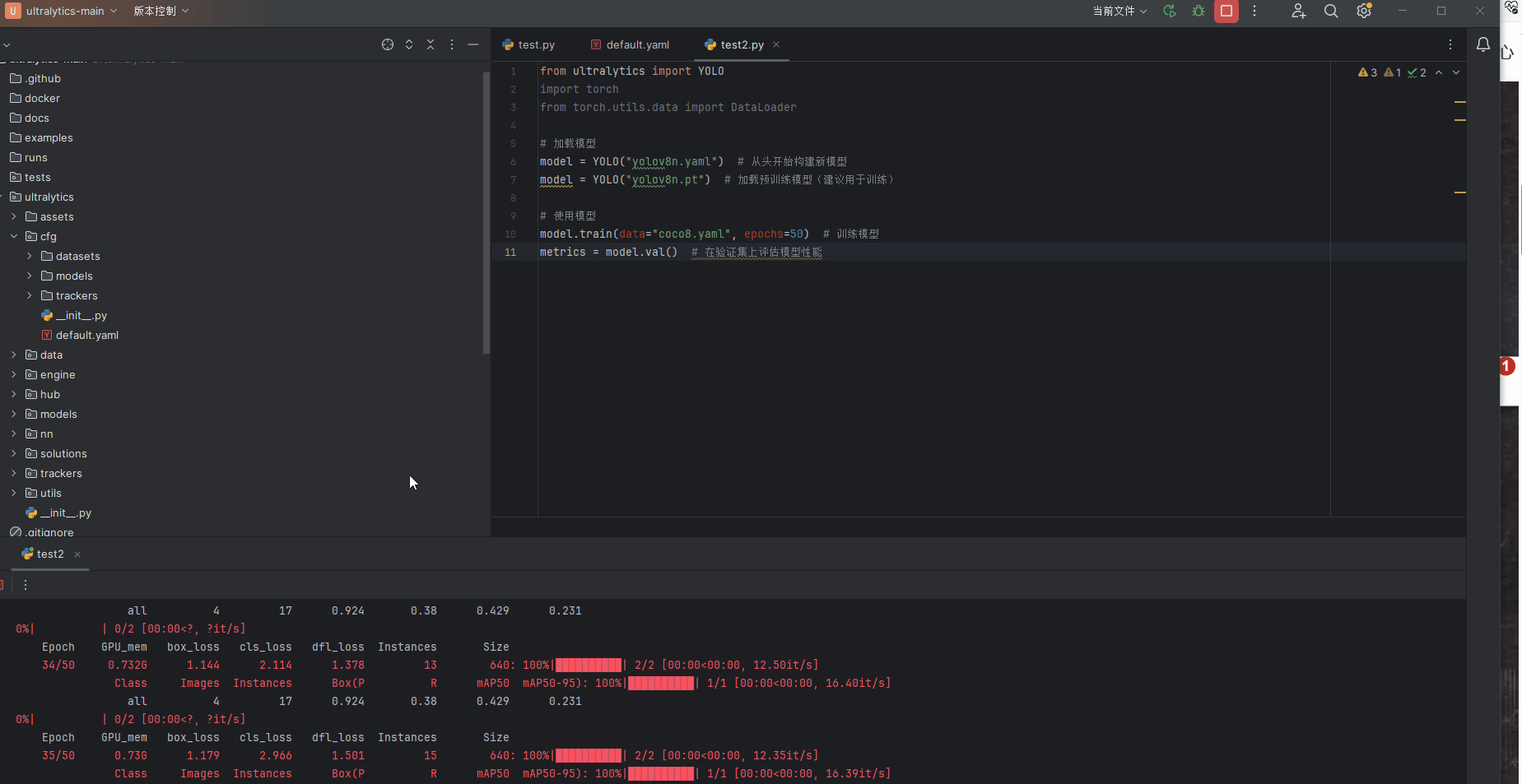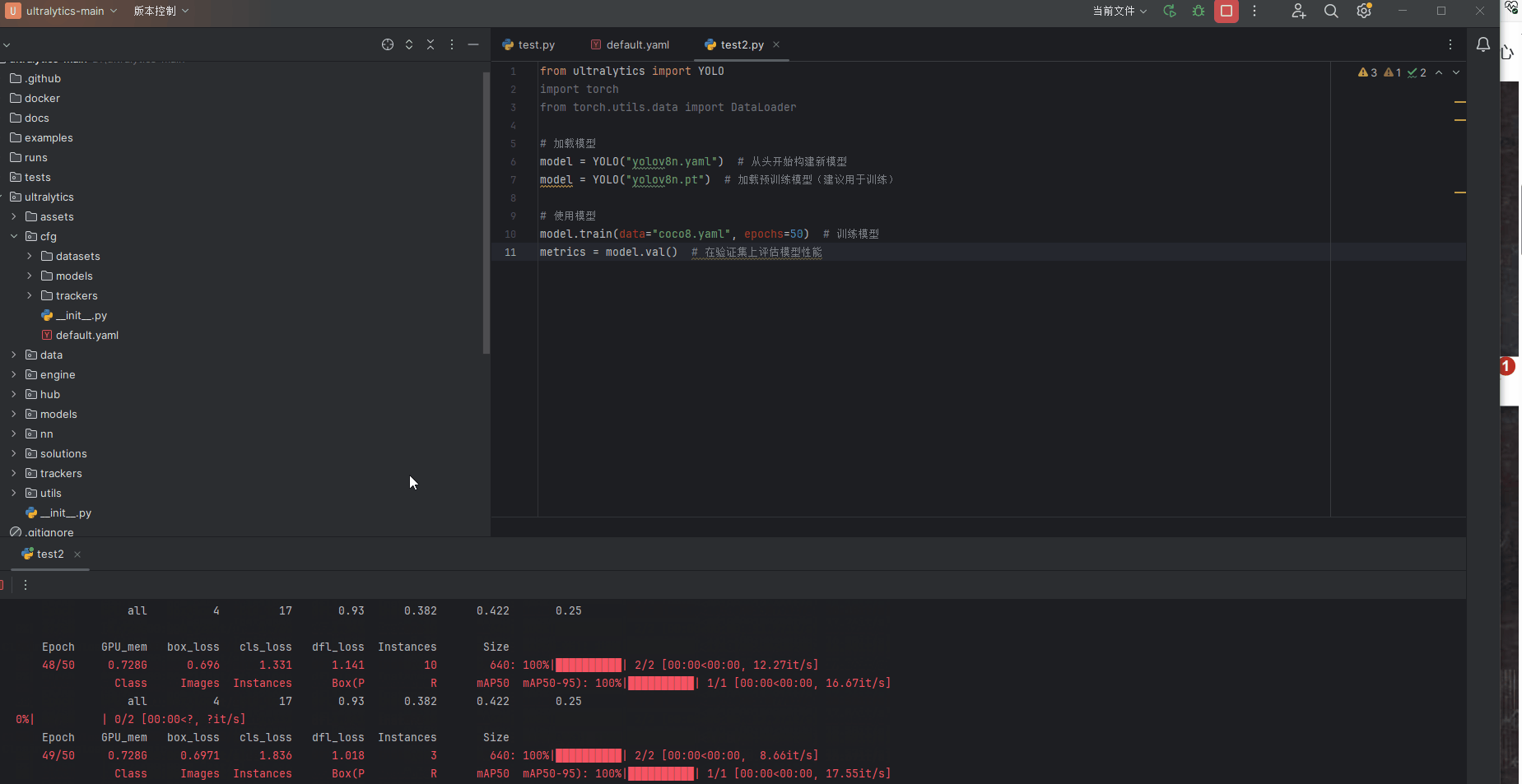
本人的笔记本GPU显卡是3060,为测试GPU,新建test2.py文件,输入以下代码
from ultralytics import YOLO
import torch
from torch.utils.data import DataLoader
# 加载模型
model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
model.train(data="coco8.yaml", epochs=50) # 训练模型
metrics = model.val() # 在验证集上评估模型性能演示结果,不到1分钟就训练50遍数据集,GPU较为快速。至此我们GPU环境完美搭建结束


















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









