 QoE驱动的资源分配研究
QoE驱动的资源分配研究




💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
💥1 概述
摘要:
随着终端用户质量测量在通向5G时代的无线通信发展中扮演着越来越重要的角色,均衡意见分数(MOS)已经成为一个广泛使用的度量标准,不仅因为它反映了终端用户的主观质量体验,而且还为不同类型的流量提供了一个共同的质量评估指标。本文提出了一种基于MOS的分布式干扰下动态频谱访问(DSA)方案,该方案通过强化学习实现了对具有不同特征的流量(实时视频和数据流量)的综合流量管理和资源分配。所提出的方案通过强化学习最大化了整体MOS,针对一个系统,其中主用户与访问相同频段的次级用户共存,同时满足对主用户的总干扰约束。使用MOS作为一个通用指标允许在不降低性能的情况下在承载不同流量的节点之间进行教学。因此,将docitive范式应用于所提出的方案以调查不同docition场景对整体MOS的影响,其中一个新进入的节点由具有相似和不同流量的经验丰富的同行进行教学。模拟结果显示,docition将使收敛所需的迭代次数减少约65%,同时保持了对于不同次级网络负载而言的整体MOS在可接受水平以上(MOS > 3)。在应用于具有相似和不同流量的节点之间的docition方面,模拟结果显示所有不同的docition场景在MOS方面具有相同的性能。
这是一个认知无线电网络实现。由于终端用户的质量测量在向5G时代的无线通信发展中发挥着越来越重要的作用,均衡意见分数(MOS)已经成为一个广泛使用的指标,不仅因为它反映了终端用户的主观质量体验,而且还为不同类型的流量提供了一个共同的质量评估指标。本文提出了一种基于MOS的分布式干扰下动态频谱访问(DSA)方案,该方案通过强化学习实现了对具有不同特征的流量(实时视频和数据流量)的综合流量管理和资源分配。所提出的方案通过强化学习最大化了整体MOS,针对一个系统,其中主用户与访问相同频段的次级用户共存,同时满足对主用户的总干扰约束。使用MOS作为一个通用指标允许在不降低性能的情况下在承载不同流量的节点之间进行教学。因此,将docitive范式应用于所提出的方案,以调查不同docition场景对整体MOS的影响,其中一个新的进入节点由具有相似和不同流量的经验丰富的同行进行教学。
通向5G时代的无线通信演变涉及网络设计和评估的转变,旨在将终端用户置于任何决策的中心。因此,5G网络的资源管理技术需要基于体验质量(QoE)性能评估。从客观的服务质量(QoS)指标到主观的终端用户QoE指标的性能评估转变得到了多项多媒体质量评估研究的帮助,这些研究贡献了从客观测量中估计QoE的技术,同时保持与主观质量感知的高相关性。在这些技术中,均衡意见分数(MOS),一个从1(差)到5(优秀)的度量标准,是最广泛使用的QoE指标。重要的是,通过为不同类型的流量提供单一的通用测量尺度,MOS提供了跨流量的综合流量管理和资源分配的手段。
基于QoE性能指标的新资源管理技术设计仍然面临来自无线电频谱资源的永久存在的限制的挑战。认知无线电范式提供了一种有效和自适应的频谱利用技术,可以应对这一挑战。针对未来5G场景,在这些场景中异构网络共享一个公共频谱带宽,本文将研究基于认知QoE的资源管理,以实现异构流量在干扰下的无缝集成。在这种干扰下的动态频谱访问设置中,主用户(PUs)和次级用户(SUs)被允许在相同的频段上同时传输,只要来自SUs到PUs的干扰保持在一个限制以下。
在朝着未来5G场景的终端用户为中心的网络设计转变过程中,许多工作已经研究了基于QoE性能指标的认知无线电(CR)技术。工作[5]和[6]专注于具有多天线的CR系统中的QoE提供。[6]推导了三个QoE指标的闭合形式表达式,[5]则仅从延迟的角度关注了SUs的满意度。[1]中的作者提出了一种基于QoE驱动的频谱切换方案,并应用强化学习(RL)来最大化长期视频传输的质量。在本文中,我们考虑了多个SUs访问单一频谱带宽以传输实时视频或常规数据流量的场景。我们提出的干扰下的动态频谱访问技术调整了所有SUs的传输速率,相应的调制方案以及分配的传输功率,以最大化次级网络中所有活动实时视频或常规数据传输的平均QoE。本文的主要贡献是将MOS作为终端用户QoE的通用测量尺度,允许对异构流量(实时视频和数据)进行无缝集成。
一、研究背景与核心概念
1. 5G认知无线电网络(CRN)的核心挑战
- 频谱动态性:CRN通过感知授权频谱空洞,允许次用户(SU)动态接入频谱资源,但需避免对主用户(PU)的干扰。
- 异构流量激增:5G需同时支持增强现实、物联网、高清视频等业务,其需求差异显著(如实时视频需低延迟,文件下载需高吞吐量)。
- QoE(体验质量)保障需求:传统资源分配以频谱效率为核心,忽视用户主观体验(如卡顿率、服务连续性),导致满意度下降。
2. 集成异构流量的特性
- 定义:指在网络中同时传输具有不同QoS需求的流量类型(如P2P大带宽流量与Web低延迟流量)。
- 关键矛盾:
- P2P流量消耗大量带宽,导致传统业务性能下降;
- 需通过集成模型量化不同类型流量的相互影响。
3. QoE驱动的资源分配机制
- 目标:将网络层参数(带宽、丢包率)映射到用户主观体验。
- 实现方式:
- 5G QoS机制(如QoS流、网络切片)实现资源隔离与保证;
- VLC/RF异构网络中,推导时延QoS要求并建立QoE评估体系。
二、合作学习在资源分配中的应用
1. 合作学习的核心价值
- 资源互赖性设计:通过差异化的资源分配(如独立结构、部分重叠结构),强制小组成员交互协作,提升决策质量。
- 分布式决策优势:在5G CRN中,多节点(基站、用户设备)协同感知频谱环境,降低感知误差。
2. 典型技术框架
- 多智能体强化学习(MARL):
- SU通过共享环境状态信息,联合优化功率与调制策略,最大化整体QoE;
- 在O-RAN中,xAPP通过团队学习共享动作意图,减少冲突。
- 迁移学习加速收敛:新加入SU复用已有SU的经验参数,减少72%训练迭代次数。
三、QoE驱动的资源分配机制
1. QoE建模与预测
- 通用指标设计:采用MOS(平均意见得分)统一评估视频、数据等异构流量的QoE。
- 动态预测机制:结合历史QoE数据与网络状态,实时调整资源分配策略。
2. 资源分配算法
| 算法类型 | 核心思想 | 案例 |
|---|---|---|
| 深度强化学习(DRL) | 每个SU搜索最优SINR目标,调整发射功率与编码率 | 多代理DQN框架提升25%收敛速度 |
| 双边匹配理论 | 在MEC网络中联合优化任务卸载与计算资源分配,最大化系统收益 | 墨尔本CBD数据集验证性能优势 |
| 联邦学习 | 保护隐私前提下协作训练QoE模型 | 云环境中抵御恶意行为的QoE威望系统 |
四、关键技术挑战与解决方案
1. 动态频谱与流量适配
- 挑战:频谱空洞的随机性与流量突发性导致资源分配滞后。
- 方案:
- 合作频谱感知:多SU协作检测PU活动,提升检测精度;
- 轻量级学习算法:降低资源受限设备的计算开销。
2. 隐私与安全
- 挑战:合作学习需共享敏感数据(如用户位置、QoE记录)。
- 方案:
- 联邦学习:本地训练模型,仅共享参数;
- 区块链技术:保障边缘计算资源分配的可信性。
3. 多目标优化
- 挑战:需平衡QoE、能效、吞吐量等冲突目标。
- 方案:
- Pareto优化框架:求解资源分配的帕累托前沿;
- GSO群搜索优化:在云环境中高效分配多资源组合。
五、研究现状与未来方向
1. 当前进展
- 仿真验证效果:
- 合作DQN算法在CRN中提升平均MOS 30%,同时减少干扰(附图);
- 匹配理论方案在MEC场景中系统收益提升40%。
- 工业应用:毫米波IAB网络采用DRL实现资源分配与回程路由优化。
2. 未来方向
- 联邦学习与QoE保障:结合模型压缩技术,实现隐私保护的实时资源分配。
- 跨域协同:将频谱分配、计算卸载、缓存策略联合优化。
- 6G延伸:探索太赫兹频段与AI原生空口的集成异构流量管理。
结论
基于合作学习的QoE驱动资源分配是5G CRN的核心创新方向:
- 技术融合:合作学习解决分布式决策问题,QoE建模统一异构流量需求,强化学习实现动态优化;
- 落地瓶颈:需进一步降低算法复杂度、设计激励机制、提升模型泛化能力;
- 跨学科价值:博弈论、匹配理论、联邦学习等方法的交叉应用将推动实际部署。
📚2 运行结果
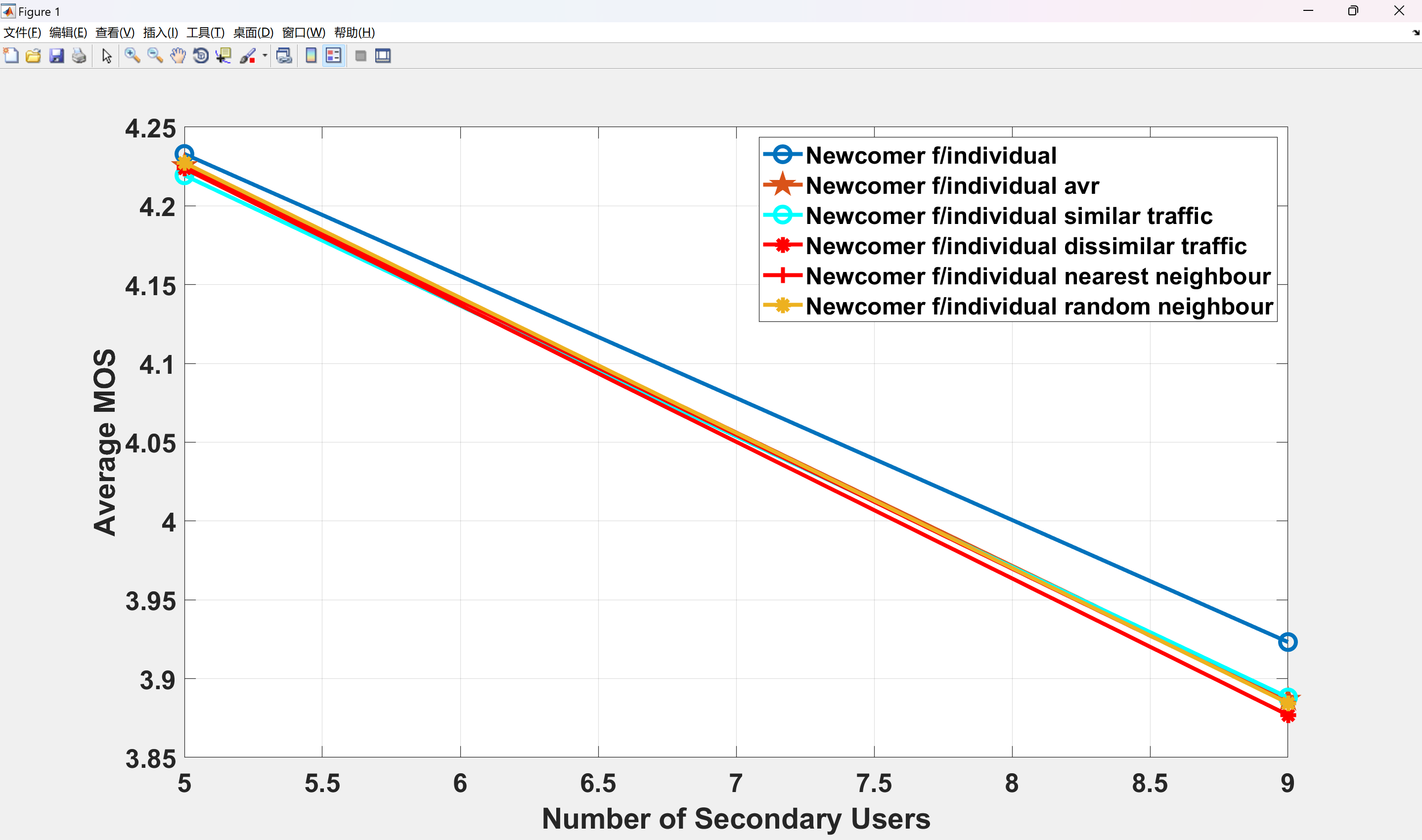
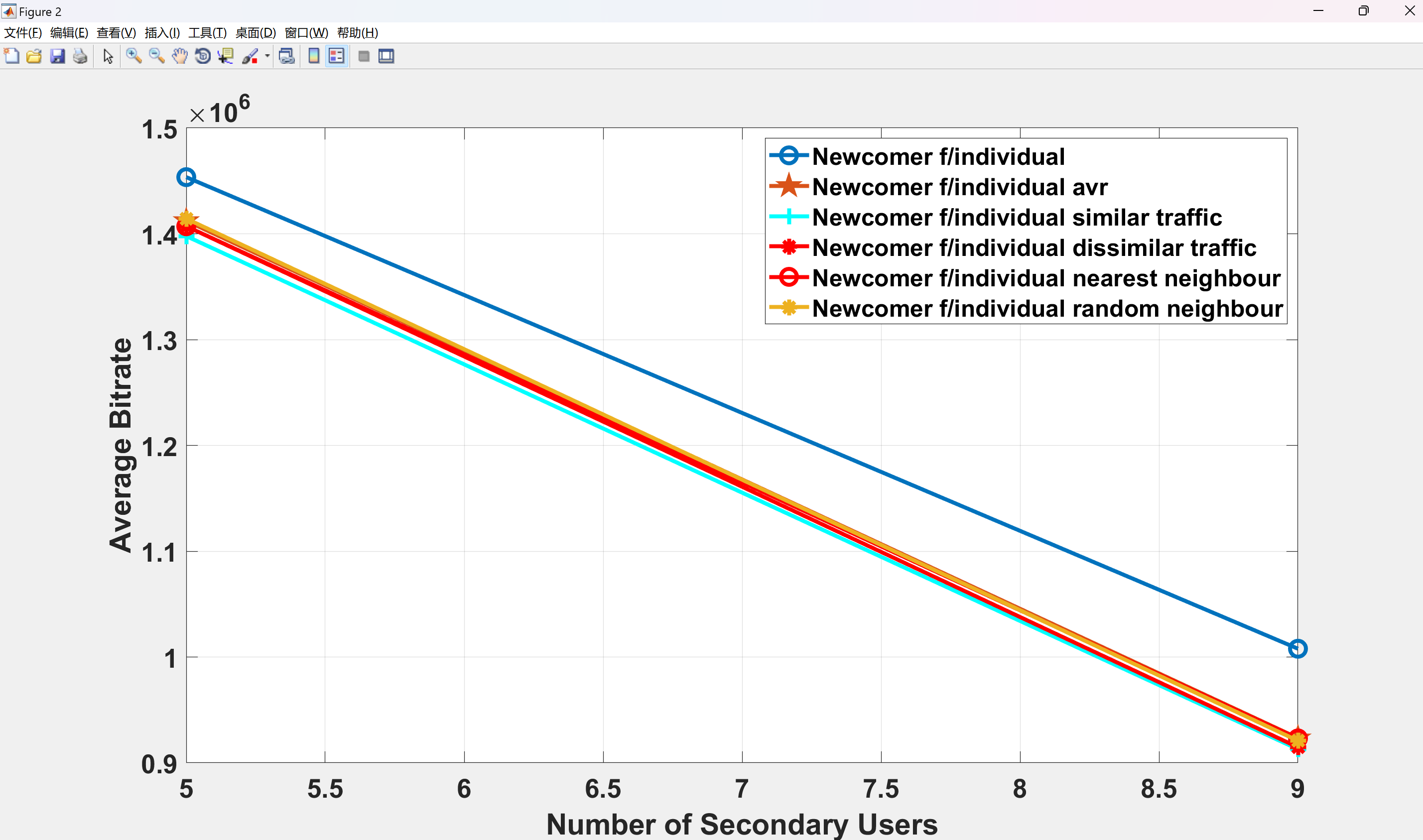
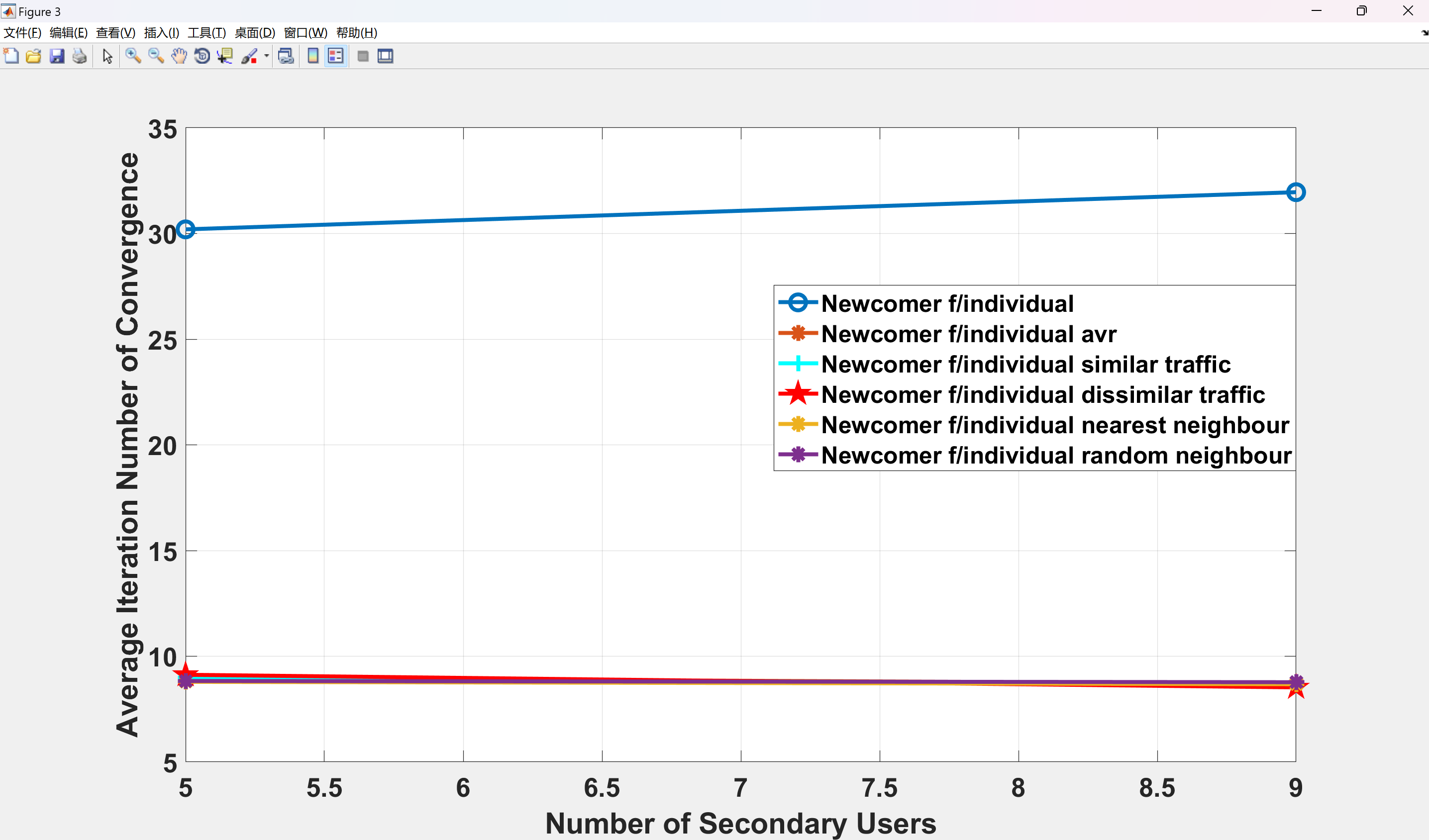
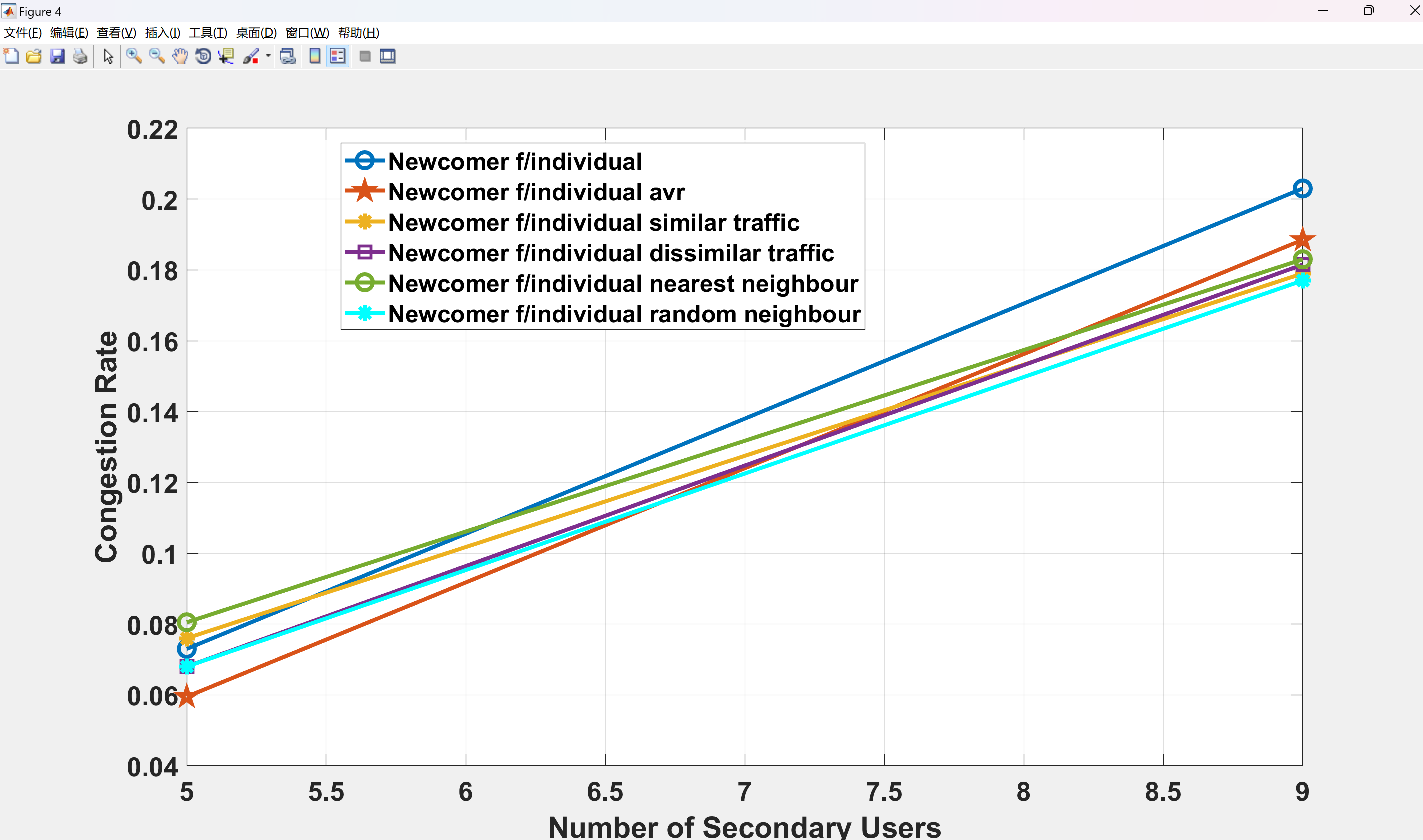
部分代码:
function [avg_distortion, num_converge, flag_converg, Q_table_ret, expt_ret, avg_bitrate] = q_learning_allocation2(n_su, learner_setup, sys_setup, ...
Q_table, expt, Gain_table, Distortion_table, t_max, flag_plot,su_traffic_type)
delta = learner_setup(1); %ceiling for SU SINR
% Q-learning setups
epsilon = learner_setup(2); %epsilon-greedy
gamma = learner_setup(3); %discounting factor
alpha = learner_setup(4); %learning rate
flag_coop = learner_setup(5); %cooperation flag
lambda_rate = 1;
lambda_decay = 0.9;
%create a set of possible transmit rate
%[bitrate_set, beta_set, D_at_beta_br] = create_state_set();
sigma2 = sys_setup(1);
P0 = sys_setup(2); %transmit power
BW = sys_setup(3); %Hz
beta_0 = sys_setup(4); %from 13 dB
Gpu2pbs = Gain_table{1};
Gsu2pbs = Gain_table{2};
Gsu2sbs = Gain_table{3};
%Initialize the channel gain with respect to positions
%[Gpu2pbs Gsu2pbs Gsu2sbs] = randomize_G(n_su);
coeff_psi = Gsu2pbs.*(sigma2+Gpu2pbs*P0)./(Gsu2sbs.*(Gpu2pbs.*P0./beta_0-sigma2))+1;
bitrate_set = Distortion_table{1};
beta_set = Distortion_table{2};
D_at_beta_br = Distortion_table{3};
Psi_set = Distortion_table{4};
%Initialization before iterations
% expt = zeros(1, n_su); %accumulated expertness
c = zeros(1, n_su); % immediate cost function
weight_exp = zeros(1, n_su);
D = zeros(1, n_su); % part of the cost function (distortion)
% Initialize the state-actions, {r, beta, I, L}, I={0,1}, L={0,1};
S = zeros(n_su, 2);
S_new = zeros(n_su, 2);
% A = repmat([beta_set(end)], n_su, 1); %old actions
A_new = zeros(n_su, 1); %new actions
Current_Q = zeros(1, n_su);
% Set the required transmit rate randomly
[tran_rate_level, beta_idx] = set_reqired_trans_rate(bitrate_set, n_su);
A = ([beta_set(beta_idx)]'); %old actions
A = repmat([beta_set(end)], n_su, 1); %old actions
if learner_setup(6)
for ii=1:n_su
[A(ii),Q_max] = argmin_Q(Q_table(ii,:,:,:), S(ii,:),beta_set);%find an action
end
end
%fill up Q-table with the first observation
[I, L, psi_su] = observe_state(BW, A ,bitrate_set,beta_set, delta, coeff_psi); %bitrate_set, beta_set, Psi_set, n_su (obsolete parameters)
S(:,1) = I;
S(:,2) = L;
% for testing purpose TO BE DELETED
% beta_idx(:,:)=1;
% Q-learning begin
% Building up Q-table hierarchies for each SU, permutations of state and
% action (initial value = 0), dementionality is:
% #(bit_rate)*#(beta_vector)*#(I)*#(L)
%Q_table = zeros(n_su, sz_br_set, sz_beta_set, sz_I, sz_L);
%set Q_tables elements lower than the minimum transmit rate level to some
%large value
% if ~ learner_setup(6)
% if I+L>=1
% for ii=1:n_su
% if(beta_idx(ii)>1)
% Q_table(ii, 1:beta_idx(ii)-1, :, :) = -1;
% end
% end
% end
% end
if ~ learner_setup(6)
for ii=1:n_su
D(ii) = get_distortion(A(ii), beta_set, D_at_beta_br,su_traffic_type(ii));
% c(ii) = D(ii) + lambda(ii)*psi_su(ii) + (I+L)*(D_at_beta_br(1,1)+lambda(ii)*Psi_set(id_end_beta));
c(ii) = D(ii);
[idx_beta, idx_I, idx_L] = find_idx(S(ii,:), A(ii), beta_set, [0,1], [0,1]);
if(Q_table(ii, idx_beta, idx_I, idx_L) == 0)
if I+L<1
Q_table(ii, idx_beta, idx_I, idx_L) = c(ii);
else
Q_table(ii, idx_beta, idx_I, idx_L) = - 0.03;
end
end
end
end
lambda1 = 1;%50+(100-50).*rand(1, 1); %randomize lambda1
lambda2 = 1;%50+(100-50).*rand(1, 1); %randomize lambda2
lambda = lambda1 + coeff_psi.*lambda2; %
%sum of distortion
sum_D = zeros(1, t_max);
sum_IL = zeros(1, t_max);
id_end_r = size(bitrate_set, 2);
id_end_beta = size(beta_set, 2);
flag_same_state = 0;
count_same_state = 0;
state_trend =[];
actions = [];
%% update Q-values
for tt=1:t_max
Current_Q(:,:) = 0;
D(:,:) = 0;
c(:,:) = 0;
%update espilon
epsilon = 1-(1-epsilon)/tt; % Question
eps = rand(n_su, 1); %to determine if each of the SUs enter the learning process
indicator = eps<=epsilon;
for ii=1:n_su
if(indicator(ii) == 1)
%learn from Q value, to find the new action (r_i, beta_i) which
%minimizes the old Q-value table
tt;
[A_new(ii),Q_max] = argmin_Q(Q_table(ii,:,:,:), S(ii,:),beta_set);%find an action
else
% idx_br_i = randi([1,size(bitrate_set,2)], 1);
idx_beta_i = randi([1,size(beta_set,2)], 1);
% A_new(ii,1) = bitrate_set(idx_br_i);
A_new(ii) = beta_set(idx_beta_i);
%A_new(ii,:) = A(ii,:);
end
end
% observed the updated states
[I, L, psi_su] = observe_state(BW, A_new,bitrate_set,beta_set, delta, coeff_psi);
S_new(:,1) = I;
S_new(:,2) = L;
% get immediate cost value c by observation
for ii=1:n_su
%if(indicator(ii) == 1)
D(ii) = get_distortion(A_new(ii,1), beta_set, D_at_beta_br,su_traffic_type(ii));
%get immediate c from equation (12) with r and beta
if(I+L==0)
c(ii) = D(ii);
else
c(ii) = -5; % Question
% c(ii) = - 0.5;
end
% c(ii) = D(ii) + lambda(ii)*psi_su(ii) + (I+L)*(D_at_beta_br(1,1)+lambda(ii)*Psi_set(id_end_r,id_end_beta)); %
%update q-table
%find the minimum Q-value for new state
[ beta, Q_min] = argmin_Q(Q_table(ii,:,:,:), S_new(ii,:), beta_set);%retrieve the q-values for updating
%combination of old state and new actions
[idx_beta, idx_I, idx_L] = find_idx(S(ii,:), A_new(ii,:), beta_set, [0,1], [0,1]);
%update with function (9)
Current_Q(ii) = (1-alpha)*Q_table(ii, idx_beta, idx_I, idx_L) + alpha*(c(ii)+gamma*Q_min);
Q_table(ii,idx_beta, idx_I, idx_L) = Current_Q(ii);
%end
end
%update expertness
expt = expt + 1./(lambda'.*c);%gamma*expt+c; % what is that
if(flag_coop==1)
expt_sum = sum(expt);
for ii=1:n_su
weight_exp(ii) = expt(ii)/expt_sum;
end
% cooperation with other SU
for ii=1:n_su
[idx_beta, idx_I, idx_L] = find_idx(S(ii,:), A_new(ii,:), beta_set, [0,1], [0,1]);
%that should be weighed q-table cell of all the other's
Q_table(ii,idx_beta, idx_I, idx_L) = weight_exp*Q_table(:, idx_beta, idx_I, idx_L);
end
end
%update lamdbda towards the direction of gradient
% if (I+L == 0 ) %&& tt >= size(Distortion_table{2},1)*size(Distortion_table{2},2)
% % One way of updating the results
% lambda1 = lambda1 + lambda_rate * sum(psi_su.^2)/n_su;
% lambda2 = lambda2 + lambda_rate * sum((psi_su.*coeff_psi).^2) / n_su;
%
% % Another way of updating the results
% %lambda1 = lambda1 + lambda_rate * sqrt(sum(psi_su.^2));
% %lambda2 = lambda2 + lambda_rate * sqrt(sum((psi_su.*coeff_psi).^2));
%
% lambda = lambda1 + coeff_psi.*lambda2;
% lambda_rate = lambda_rate*lambda_decay;
% end
if(sum(sum(S==S_new))==2*n_su && sum(sum(A == A_new)) == n_su)
flag_same_state = 1;
else
flag_same_state = 0;
end
if(flag_same_state == 1)
count_same_state = count_same_state + 1;
else
count_same_state = 0;
end
%update state
S = S_new;
A = A_new;
actions(tt,1:n_su) = [A_new']; % first col user one, sec col user two
state_trend (tt,1:n_su) = sum(S_new');
%record sum of distortion
sum_D(tt) = sum(D);
sum_IL(tt) = I+L; % Question why
D = [];
if(I+L == 0 && count_same_state >= 4) % Question Condition for convergence???
break; % Question
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。


















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









