




 文章探讨了磁盘的存储单位如扇区和块,强调数据读取的重要性。介绍了Linux磁盘的逻辑块、位图、I节点等概念,以及I/O操作的层次,包括块设备驱动、调度器层、通用块层和缓存机制。文章还提到了MINIX文件系统,并概述了CPU与存储设备交互的同步与异步方式,以及分层架构在解耦中的作用。
文章探讨了磁盘的存储单位如扇区和块,强调数据读取的重要性。介绍了Linux磁盘的逻辑块、位图、I节点等概念,以及I/O操作的层次,包括块设备驱动、调度器层、通用块层和缓存机制。文章还提到了MINIX文件系统,并概述了CPU与存储设备交互的同步与异步方式,以及分层架构在解耦中的作用。
现在有一块硬盘,我们需要将数据取出来。

为何将磁盘规划成如此结构?我们就需要分析一下。
数据存储不能只存进去,不取出来,那还不如直接丢掉。
所以如此排布只为了快速读取,那如何更快的取出数据就是应该讨论的问题。
磁盘结构:
扇区:磁盘的最小存储单位,每个扇区可存 512 字节。
块:操作系统读取硬盘的时候,不会一个个地扇区读取,效率太低,连续读多个扇区,多个扇区为块。最常见的是 4 KB,是一个文件的最小存储单位。
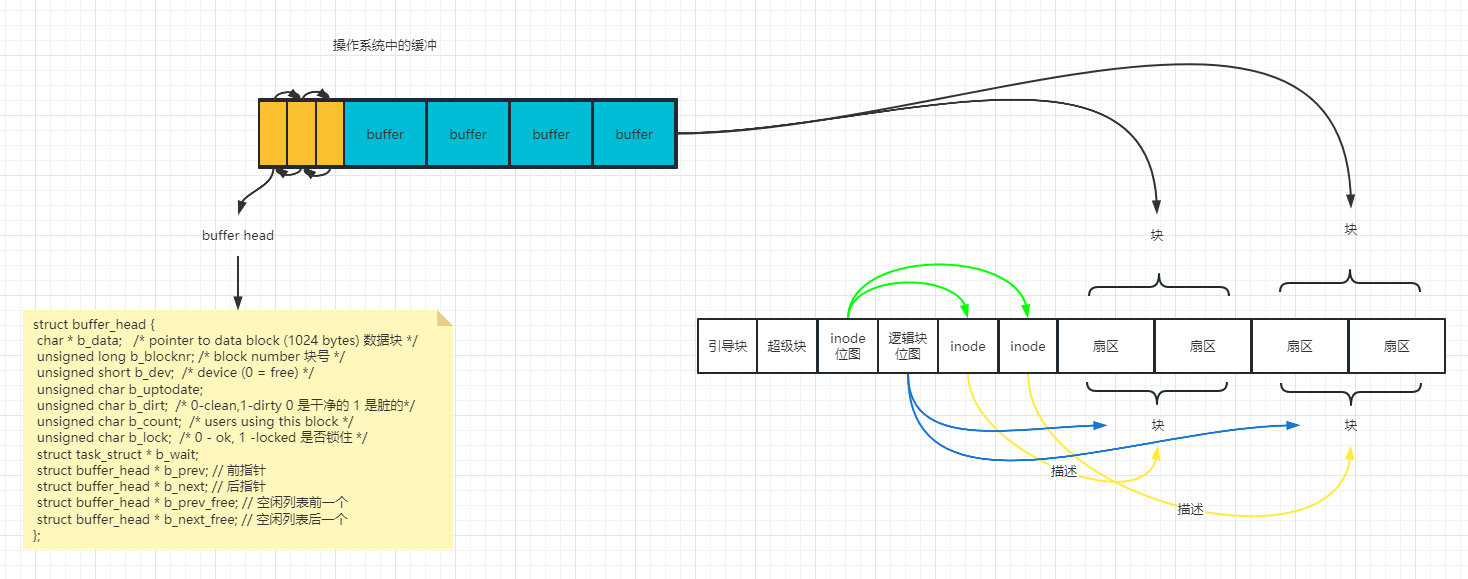
Inode (索引节点)
文件的数据都存储在块中,为了快速查询文件,需要一个元数据信息来描述文件,而这个描述这些元数据信息的被称为 Inode 索引。
Linux 磁盘结构:
逻辑块:将磁盘分割为具有相同单位的数据块,数据块的合集被称为逻辑块。
逻辑块位图:用于表示当前块是否被占用,占用即置位。
I 节点:当前存储时一切皆文件,文件所占用的逻辑块,以及文件的相关描述信息,也即索引。
I 节点位图:用于表示当前索引块是否被占用,占用即置位。
引导块:计算机加电时需要找到第一个应用程序约定的空间,如果不需要运行应用程序,则可以不加载
超级块:存放文件系统的元信息(描述信息)
block device driver 块设备驱动I/O:厂商生产的磁盘,需要被操作系统调用就需要实现该驱动,操作系统是一个协调者的身份,并不负责各个设备的实现。操作系统来统一管理
scheduler Layer I/O调度器层:何时写入磁盘,是可以影响计算机性能的,所以调度层就是用来,提高IO的吞吐量,和IO的响应时间。
generic block layer 通用块层:操作系统对查询到的磁盘数据进行缓存。
page/buffer cache 页面/缓冲区缓存:CPU有分页的功能,而操作系统为了避免去访问磁盘,而在操作系统内部自己维护一片内存。
vfs/file (DAX) system 文件系统:根据不同场景使用不同类型的文件系统。NTFS,ext 都是文件系统的实现。
MINIX 文件系统
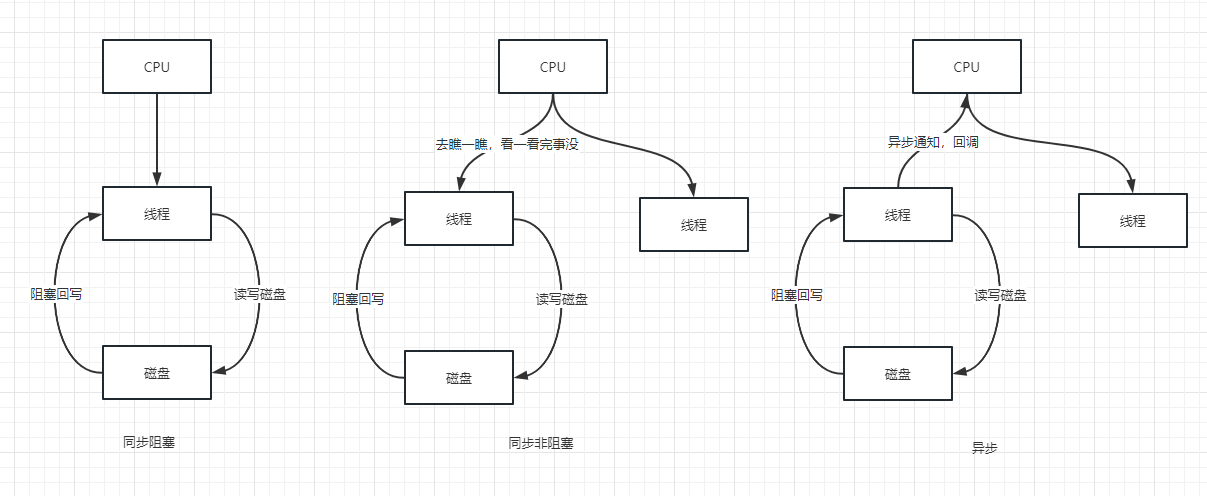
只要具有输入输出就都是I/O操作,CPU读取指令执行,写回是I/O,操作内存是I/O,操作磁盘是I/O,网络也是I/O
那么CPU与存储设备交互就有如下几种情况:
- 同步阻塞
- 同步非阻塞
- 异步
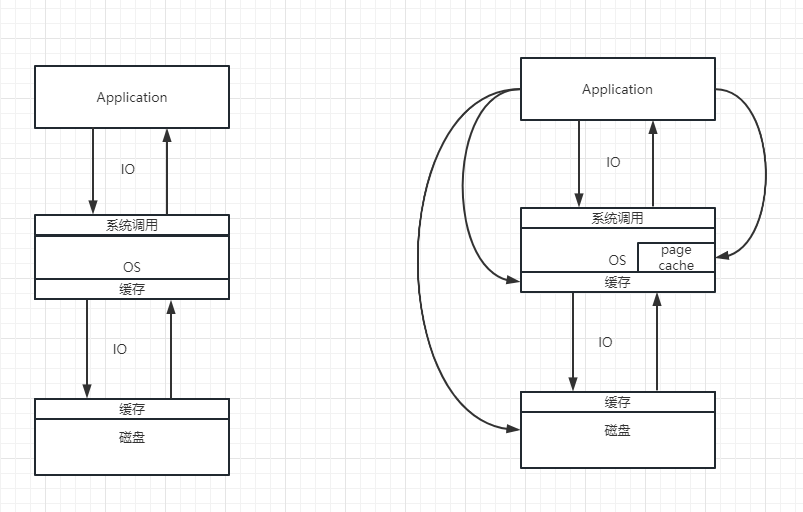
分层架构,使用接口解耦。
我暴露接口供上层使用,但是底层细节不需要你知道,上层只需要关注输入输出即可。

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









