 汇编语言与内存管理机制简介
汇编语言与内存管理机制简介




 文章详细阐述了汇编语言与机器语言的关系,以及CPU如何通过内存层次结构(磁盘、内存、寄存器)执行指令。讨论了栈和堆在数据存储中的作用,以及栈帧在函数调用中的使用,包括栈顶和栈底寄存器(SP和BP)的角色。还介绍了参数传递、返回值存储和字符串存储的一般方法,并举例说明了不同数量参数的函数调用在内存中的处理方式。
文章详细阐述了汇编语言与机器语言的关系,以及CPU如何通过内存层次结构(磁盘、内存、寄存器)执行指令。讨论了栈和堆在数据存储中的作用,以及栈帧在函数调用中的使用,包括栈顶和栈底寄存器(SP和BP)的角色。还介绍了参数传递、返回值存储和字符串存储的一般方法,并举例说明了不同数量参数的函数调用在内存中的处理方式。
在之前介绍了汇编语言是机器语言的封装。
那么汇编语言的功能是与机器语言的功能如出一辙。而机器语言就是操作CPU执行的。所以汇编语言也就具有相同的功能,去完成运算的功能。
而我们之前知道一条指令为
操作码 + 操作数
将ebx赋值给eax
Intel 的规则是 movl %ebx,%eax
AT&T的规则是 mov %eax,%ebx
介绍一下 : Intel 是从右到坐,AT&T则是从左到右。
就两个方向,再没有第三种方式。
运行一段代码我们就需要去规划它如何去执行。首先我们来想一想执行一段指令需要的条件,首先我们需要存放代码的地方,和存放数据的地方,数据又可以分为私有数据和公有数据,和静态分配的数据。代码需要持久化,并且在运行状态下是只读状态。所以代码应该存放在磁盘内,但是因为磁盘的访问速度比CPU的速度慢很多,那我们需要加速,这里就需要加入缓存,为了访问安全,如果运行时代码被修改,则会有意外情况出现,跳到了一个本不应该操作的地址,在内存中他需要收到保护。这里就需要将他放入主存中,但是因为主存的访问速度还是和CPU的访问速度依旧是有差距,最后这部分数据我么会将他放入寄存器中,而寄存器的造价高,所以他的存放的数据量小,但是速度快。就这样,CPU的去访问一段数据,需要从磁盘上拉取到内存中,再将内存中的数据拉取的寄存器中,只为了加快速度。这时,一段指令已经加载到了主存中,再开始运行指令的时,我们先来分析一下指令,一条指令他要执行,他就需要操作数据,而数据可以分为两种情况,第一种,写在指令之间固定的一开始就知道需要多少内存的数据,而第二种则是,未知的。正因为这样,就需要对数据进行规划。而这管理所有硬件的软件则是操作系统,但是操作系统也需要空间。则他的数据排布就变成了如下:
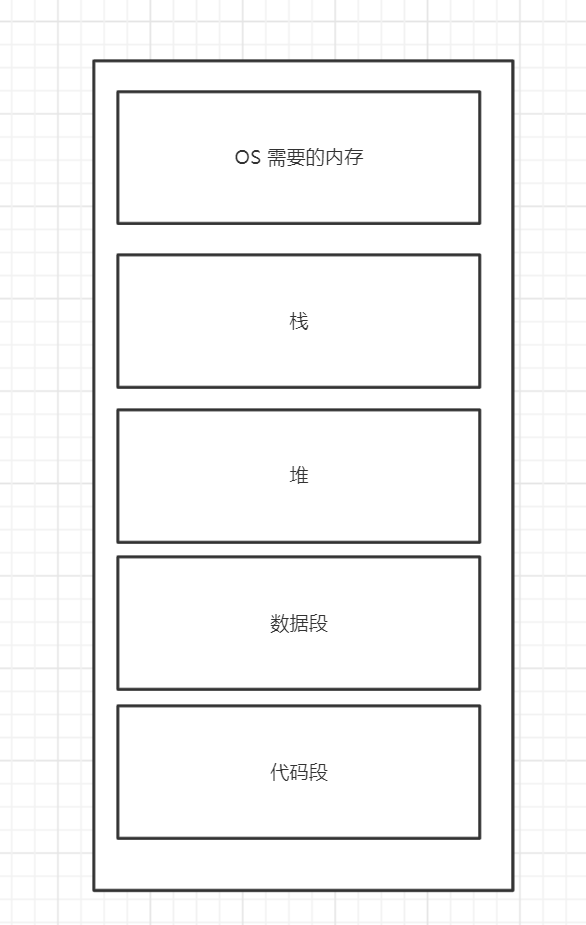
之前介绍了栈是保存了私有数据,堆是保存共享数据的,代码段存储的是指令和数据,而数据段则是存放数据的地方。
有了这些我们就来执行指令。
首先我们知道主存存放的数据有限,并不能将整个程序的代码都加载到内存中,而相对于寄存器更不可能,
这个时候,寄存器就只能分批从主存中获取数据。而主存则是由操作系统管理,将磁盘上的数据针对性的拉取到主存中。就有如下流程:
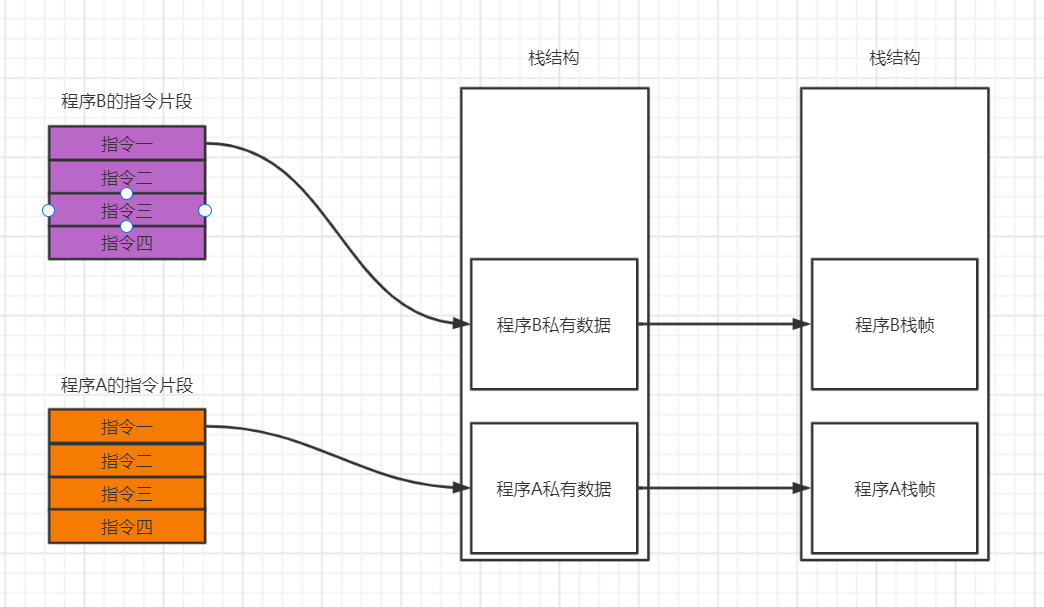
一个程序运行后,他会被分配一段内存,这个空间给当前程序分配的空间叫做栈帧。
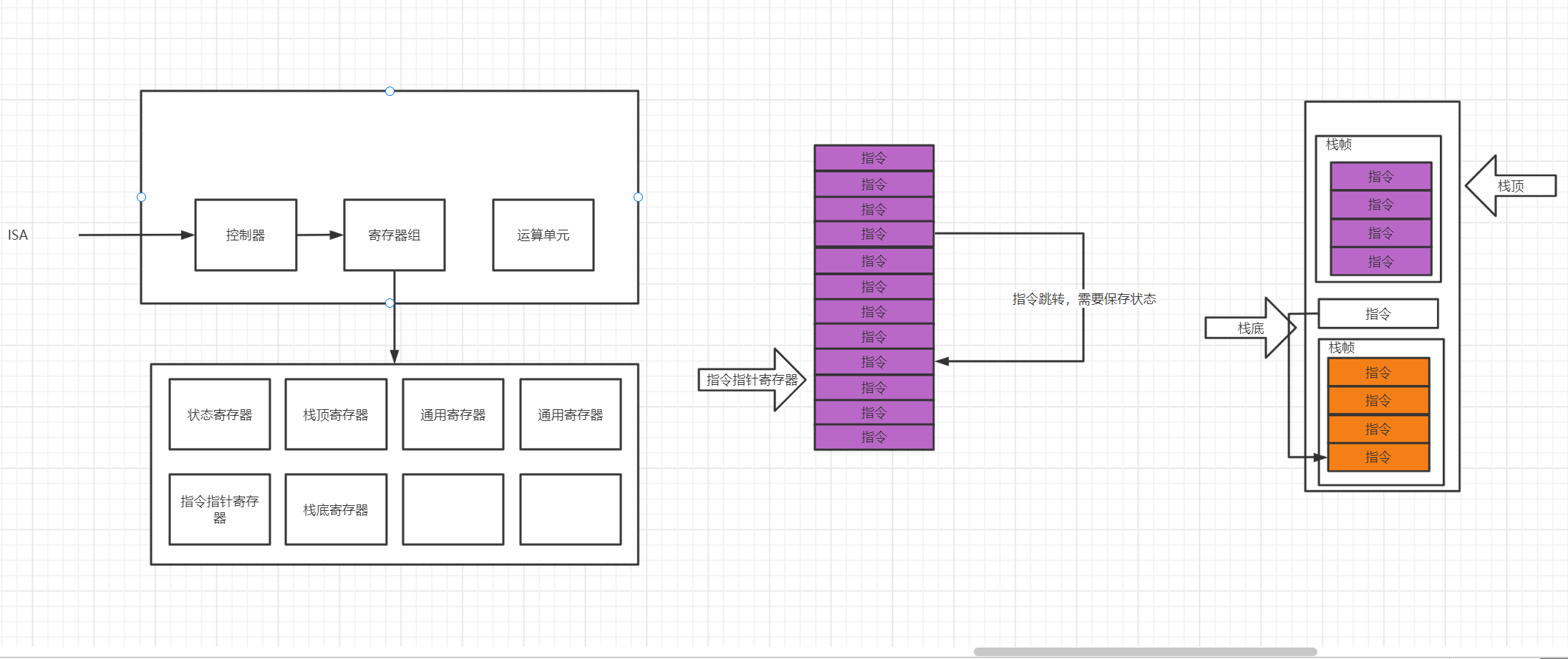
这个时候我们就开始执行指令。
如果当前有一条指令说,如果命中了当前条件,我将跳到指定的指令上。但是如果要实现当前的需求,我们就需要一个地方存一个状态,我这条指令执行后的结果就需要存储,来控制判断是不是需要跳转(状态机),还需要另一个指令来读取当前指令在何处,因为我一跳就不是顺序执行了。这个时候就有两个寄存器:状态寄存器,指令指针寄存器
而当出现两个指令集我们怎么实现这个栈结构呢?
当读到一段指令片段时,我将会给这段片段开辟一个栈帧,但是这个指令片段中有一条指令,使用 call 指令,这条指令将会将另一个指令片段加载进栈结构中,当我这指向的指令片段执行完成,我们就会将这个栈帧释放掉。
但是怎么回去呢?
这里就需要一个栈顶寄存器,和栈底寄存器。
栈顶寄存器保持的他的高姿态,一直想前扩张。当有一个条指定需要跳转,栈顶寄存器则向前移动,栈底寄存器这个时候就发挥了作用,他也跟着改变,变成当前跳转后的栈底。但是跳转之前它需要做一些准备工作,便于他的返回。首先他会将上一个栈帧的栈底开辟一个空间保存在两个栈帧之间,顺便将跳转时的指令也一起压入。当栈帧弹出栈的时候,栈顶指针就会回退到,预先保存的指令地址,而栈顶获取到这个地址,回到第一个栈帧的栈底,随后弹出,而指令指针寄存器则获取到 call 的那条之后的指令,继续向下执行,而栈顶指针寄存器,因为压在上面的栈帧弹出了,他也回到了第一个栈帧的栈顶。
- 状态寄存器寄存器:eflags

- 指令指针寄存器:IP 寄存器


- 栈顶寄存器:SP
- 栈底寄存器:BP
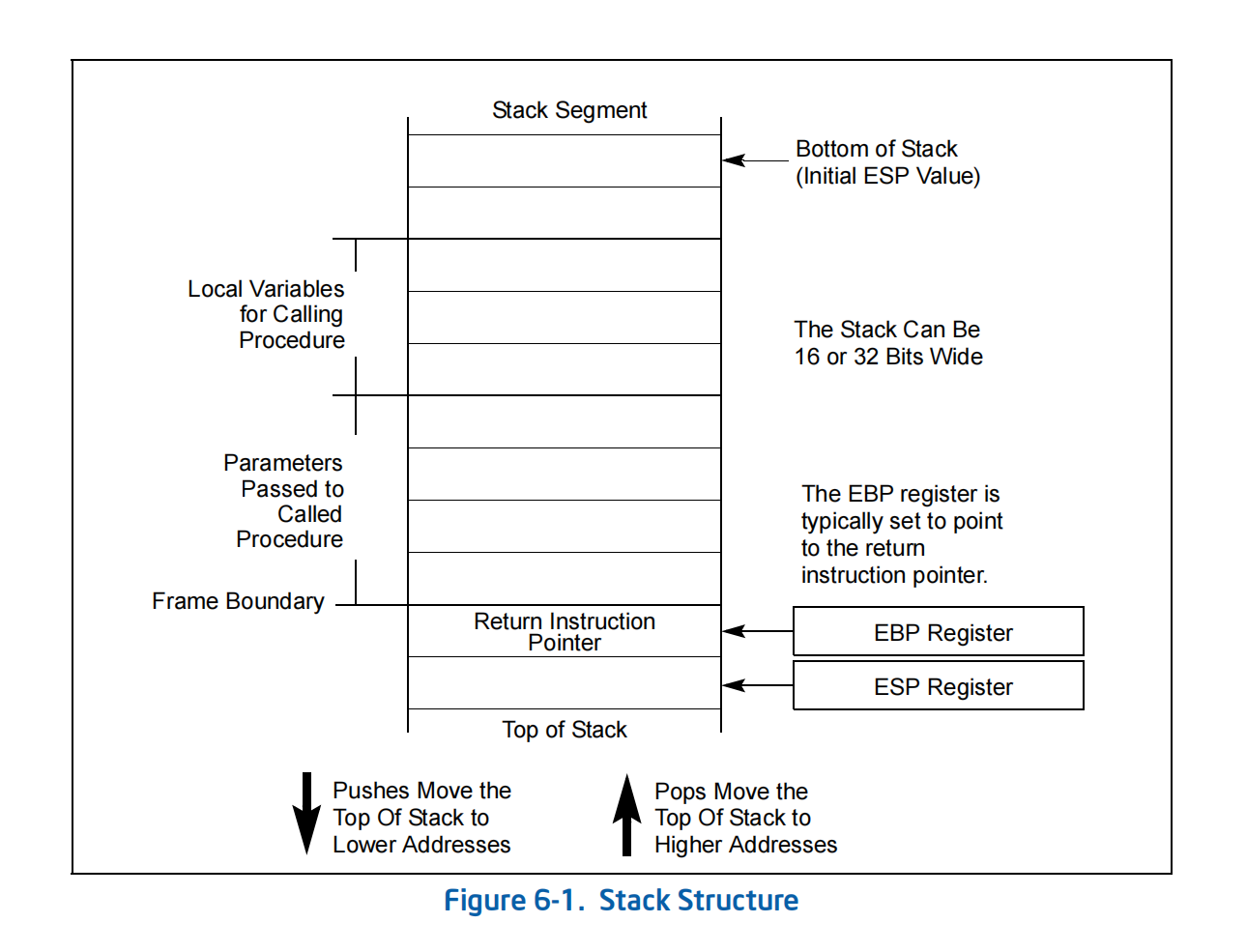
我们顺便验证一下
void func() {
printf("%d", 10);
}
int main() {
func();
return 1;
}
汇编代码如下:当时使用的命令是 gcc -S -m32 -fno-asynchronous-unwind-tables 在 32 位机的情况的代码
.file "test.c" .section .rodata .LC0: .string "%d" .text .globl func .type func, @function func: pushl %ebp movl %esp, %ebp subl $24, %esp movl $10, 4(%esp) movl $.LC0, (%esp) call printf leave ret .size func, .-func .globl main .type main, @function main: pushl %ebp movl %esp, %ebp andl $-16, %esp call func movl $1, %eax leave ret
我们看到了
pushl %ebp
movl %esp, %ebp
每个函数都有这两句代码,即可验证 sp 和 bp 这两个寄存器就是栈顶和栈底寄存器。
而在函数结束时,我们看到有两条指令 一条是 leave 另一条是 ret

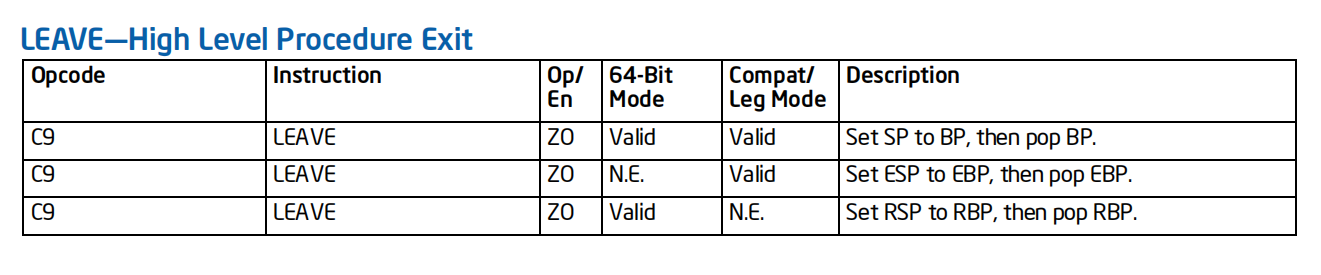
相当于
mov %esp,%ebp
pop %ebp
观察可得,leave 就是销毁栈帧。
机翻:
LEAVE指令没有任何操作数,它反转了上一条ENTER指令的操作。LEAVE指令将EBP寄存器的内容复制到ESP寄存器中,以释放分配给过程的所有堆栈空间。然后从堆栈中恢复EBP寄存器的旧值。同时将ESP寄存器恢复为其原始值。随后的RET指令可以删除任何参数和调用程序推送到堆栈上供过程使用的返回地址。
我们再来看 ret




机翻:
在分支到被调用过程的第一条指令之前,调用指令将地址推送到EIP中注册到当前堆栈。这个地址被称为返回指令指针,它指向在被调用过程返回后,调用过程的执行应恢复的指令。从被调用过程返回后,RET指令从堆栈中弹出返回指令指针进入EIP寄存器。然后继续执行调用过程。处理器不跟踪返回指令指针的位置。因此,这取决于程序员在发出RET指令之前,确保堆栈指针指向堆栈上的返回指令指针。将堆栈指针重置为返回指令指针的点的常用方法是移动内容将EBP寄存器转换为ESP寄存器。如果EBP寄存器加载有紧接其后的堆栈指针对于过程调用,它应该指向堆栈上的返回指令指针。
那我们现在假设一个种情况,如果两个栈想要传递数据怎么办?
那肯定需要一个地方去存储,现在有两个地方,一个是寄存器里,规定一块区域让下个程序去访问。
大家遵守这个规则,去获取数据。
int sum(int a, int b) {
return a + b;
};
int main() {
int b = sum(1, 3);
printf("%d", b);
return b;
}
.file "param.c" .text .globl sum .type sum, @function sum: pushl %ebp movl %esp, %ebp movl 12(%ebp), %eax movl 8(%ebp), %edx addl %edx, %eax popl %ebp ret .size sum, .-sum .section .rodata .LC0: .string "%d" .text .globl main .type main, @function main: pushl %ebp movl %esp, %ebp andl $-16, %esp subl $32, %esp movl $3, 4(%esp) movl $1, (%esp) call sum movl %eax, 28(%esp) movl 28(%esp), %eax movl %eax, 4(%esp) movl $.LC0, (%esp) call printf movl 28(%esp), %eax leave ret .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)" .section .note.GNU-stack,"",@progbits
这里看出如果参数少的话,我们可以使用寄存器来传递值,那如果说是参数比较多呢?
int sum(int a, int b, int c, int d, int e, int f, int g) {
return a + b + c + d + e + f + g;
}
int main() {
int result = sum(1, 2, 3, 4, 5, 6, 7);
return result;
}
.file "paramMore.c" .text .globl sum .type sum, @function sum: pushl %ebp movl %esp, %ebp movl 12(%ebp), %eax movl 8(%ebp), %edx addl %eax, %edx movl 16(%ebp), %eax addl %eax, %edx movl 20(%ebp), %eax addl %eax, %edx movl 24(%ebp), %eax addl %eax, %edx movl 28(%ebp), %eax addl %eax, %edx movl 32(%ebp), %eax addl %edx, %eax popl %ebp ret .size sum, .-sum .globl main .type main, @function main: pushl %ebp movl %esp, %ebp subl $44, %esp movl $7, 24(%esp) movl $6, 20(%esp) movl $5, 16(%esp) movl $4, 12(%esp) movl $3, 8(%esp) movl $2, 4(%esp) movl $1, (%esp) call sum movl %eax, -4(%ebp) movl -4(%ebp), %eax leave ret .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)" .section .note.GNU-stack,"",@progbits
我们观测到,如果是多个参数的话,只使用 ESP 寄存器,而我们之前得到结论说是 ESP就是栈顶寄存器,所以我们可以推断出结论,参数过多话,他就会使用栈结构进行数据传递,
经过这两段代码的编译,我们也发觉了,计算后的返回值我们也需要一个地方来存起来,供上一个栈帧进行访问。
那么 ret 的时候,我们就需要一个寄存器,约定一下,观察可得,这个寄存器就是 EAX
剩下两个寄存器:
SI:源变址寄存器
DI:目的变址寄存器
那我们顺便来看一下字符串是怎么存储的。
字符串的存储:字符串相当于连续的内存空间,只要是连续的内存空间都可以如下使用。
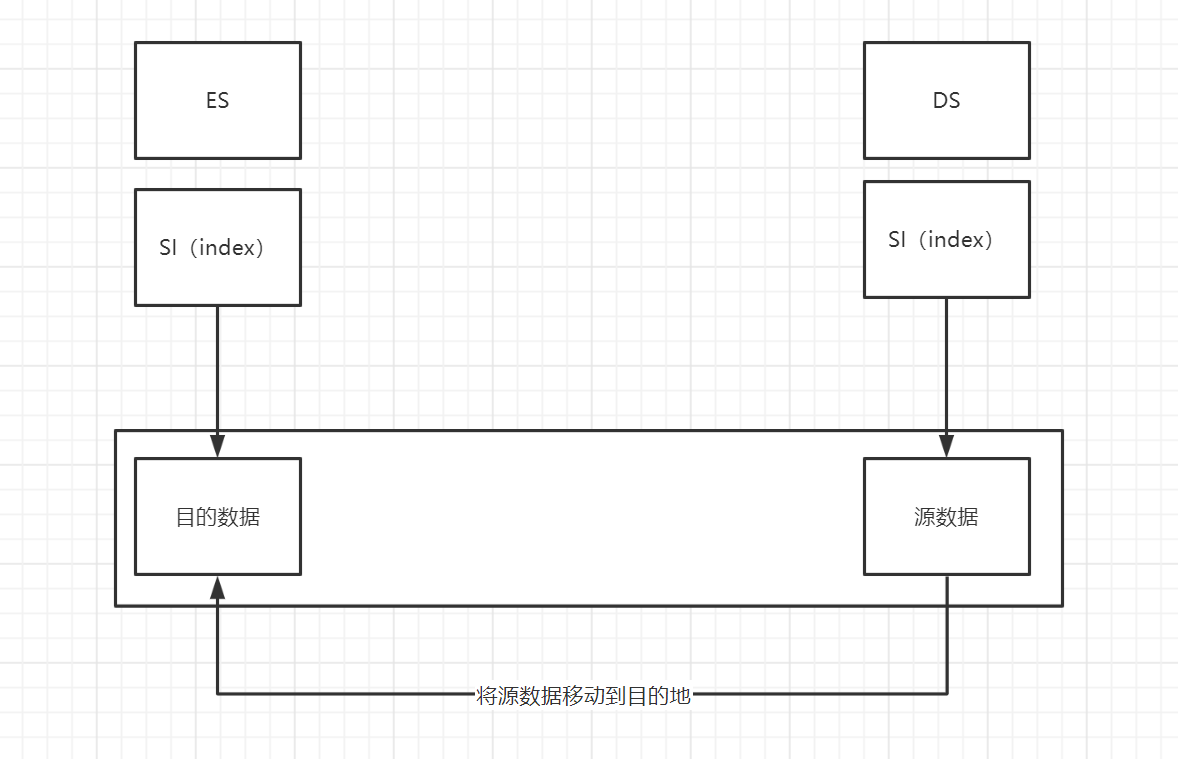
.globl begtext, begdata, begbss, endtext, enddata, endbss .text begtext: .data begdata: .bss begbss: .text SETUPLEN = 4 ! nr of setup-sectors BOOTSEG = 0x07c0 ! original address of boot-sector 引导扇区的原始地址 INITSEG = 0x9000 ! we move boot here - out of the way 将原始地址移动到当前地址 SETUPSEG = 0x9020 ! setup starts here SYSSEG = 0x1000 ! system loaded at 0x10000 (65536). ENDSEG = SYSSEG + SYSSIZE ! where to stop loading ! ROOT_DEV: 0x000 - same type of floppy as boot. ! 0x301 - first partition on first drive etc entry start start: mov ax,#BOOTSEG mov ds,ax mov ax,#INITSEG mov es,ax mov cx,#256 sub si,si sub di,di rep movw jmpi go,INITSEG go: mov ax,cs mov ds,ax mov es,ax ! put stack at 0x9ff00. mov ss,ax mov sp,#0xFF00 ! arbitrary value >>512 !因为Intel不允许立即数直接传入段寄存器,所以需要中转一下 start: mov ds,#BOOTSEG mov es,#INITSEG mov cx,#256 sub si,si sub di,di rep movw jmpi go,INITSEG go: mov ax,cs mov ds,ax mov es,ax ! put stack at 0x9ff00. mov ss,ax mov sp,#0xFF00 ! arbitrary value >>512
rep 重复指令,将重复执行 movw 代码 执行 256 mov 是移动指令 w 表示两个字节 所以这里移动了 2 * 256 = 512 字节,表明了初始扇区的大小为512字节。
cs 寄存器。计数
从注释中可以得出:
DS指向目的段, SI指向源的起始位置 -> 源
ES指向源地址段,DI指向目的段起始位置 -> 目的
如下是各个寄存器的特殊用途:

int main() {
printf("hello world");
return 1;
}
.file "demoStr.c" .section .rodata .LC0: .string "hello world" .text .globl main .type main, @function main: pushl %ebp movl %esp, %ebp andl $-16, %esp subl $16, %esp movl $.LC0, (%esp) call printf movl $1, %eax leave ret .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)" .section .note.GNU-stack,"",@progbits
注意一个细节:
如果 LC0 有个.
有. 是编译器生成的
而没有点是自己写的
例如: .LC0 当前含义表示第一行指令的地址
汇编代码:编写代码时需要定义一种规范,然后给 MASM 汇编器看。
.code: 代码段
.data:声明变量
.stack:运行时堆栈










参考文献:
intel 开发手册
《汇编语言:基于x86处理器》

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







