




Apache DolphinScheduler 是一个分布式、易扩展的可视化数据工作流任务调度系统,广泛应用于数据调度和处理领域。
在大规模数据工程项目中,数据质量的管理至关重要,而 DolphinScheduler 也提供了数据质量检查的计算能力。本文将对 Apache DolphinScheduler 的数据质量模块进行源码分析,帮助开发者深入理解其背后的实现原理与设计理念。
数据质量规则
Apache Dolphinscheduler 数据质量模块支持多种常用的数据质量规则,如下图所示。
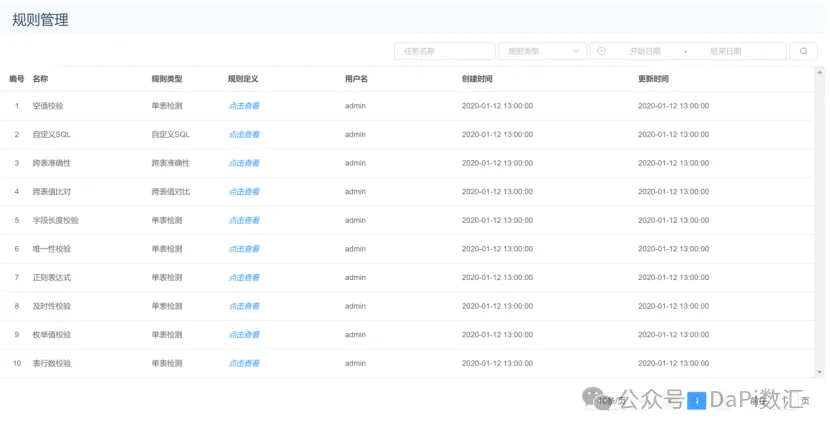
数据质量规则主要包括空值校验、自定义SQL、跨表准确性、跨表值比、字段长度校验、唯一性校验、及时性检查、枚举值校验、表行数校验等。
数据质量工作流程
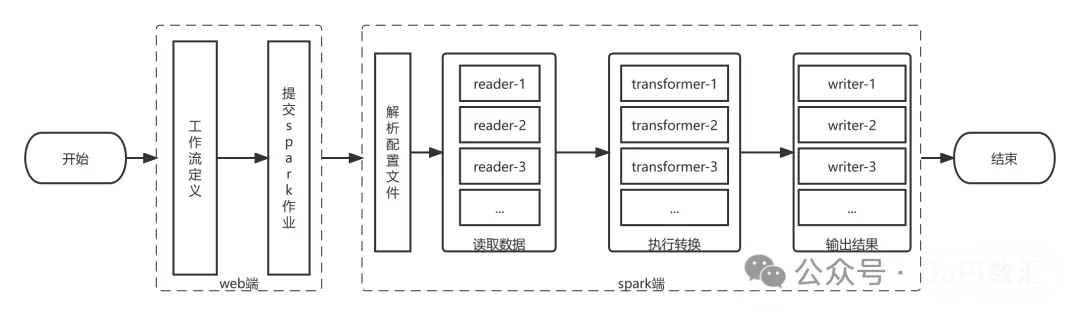
数据质量运行流程分为2个部分:
(1)在Web端进行数据质量检测的流程定义,通过DolphinScheduer进行调度,提交到Spark计算引擎;
(2)Spark端负责解析数据质量模型的参数,通过读取数据、执行转换、输出三个步骤,完成数据质量检测任务,工作流程如下图所示。
在Web端进行定义
数据质量定义如下图所示,这里只定义了一个节点。
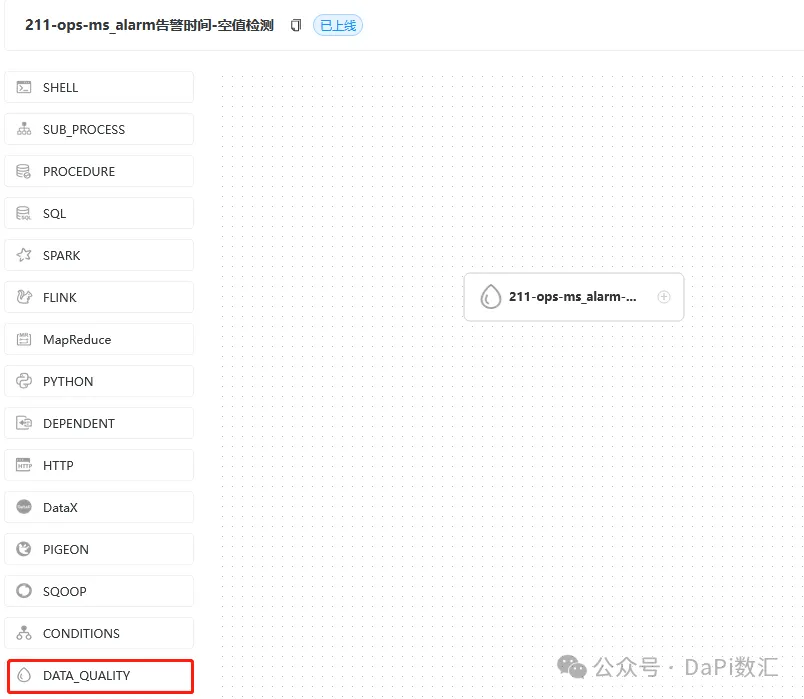
以一个空值检测的输入参数为例,在界面完成配置后,会生产一个JSON文件。
这个JSON文件会以字符串参数形式提交给Spark集群,进行调度和计算。
JSON文件如下所示。
{
"name": "$t(null_check)",
"env": {
"type": "batch",
"config": null
},
"readers": [
{
"type": "JDBC",
"config": {
"database": "ops",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"output_table": "ops_ms_alarm",
"table": "ms_alarm",
"url": "jdbc:mysql://192.168.3.211:3306/ops?allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
}
}
],
"transformers": [
{
"type": "sql",
"config": {
"index": 1,
"output_table": "total_count",
"sql": "SELECT COUNT(*) AS total FROM ops_ms_alarm"
}
},
{
"type": "sql",
"config": {
"index": 2,
"output_table": "null_items",
"sql": "SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = '') "
}
},
{
"type": "sql",
"config": {
"index": 3,
"output_table": "null_count",
"sql": "SELECT COUNT(*) AS nulls FROM null_items"
}
}
],
"writers": [
{
"type": "JDBC",
"config": {
"database": "dolphinscheduler3",
"password": "***",
"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
"table": "t_ds_dq_execute_result",
"url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLoc 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











