




导读
在 LLM 蓬勃发展的今天,数据工程已成为支持大规模 AI 模型训练的基石。DataOps 作为数据工程的重要方法论,通过优化数据集成、转换和自动化运维,加速数据到模型的闭环流程。本文聚焦新一代数据 & AI 集成工具- Apache SeaTunnel 在 DataOps 中的核心作用,并介绍其如何满足 AI 对向量数据及实时处理的需求。文章还分享了白鲸开源在信创环境中的创新实践,并展望数据工程与 DataOps 推动 AI 发展的未来趋势。
主要包括以下四个部分:
- DataOps for LLM 数据工程架构
- 白鲸开源的工程实践
- 案例介绍
- 数据工程的未来
分享嘉宾|代立冬 白鲸开源科技 联合创始人 & CTO
编辑整理|Neil
内容校对|李瑶
出品社区|DataFun
01 DataOps for LLM 数据工程架构
1. 海外独角兽企业打造数据工程平台
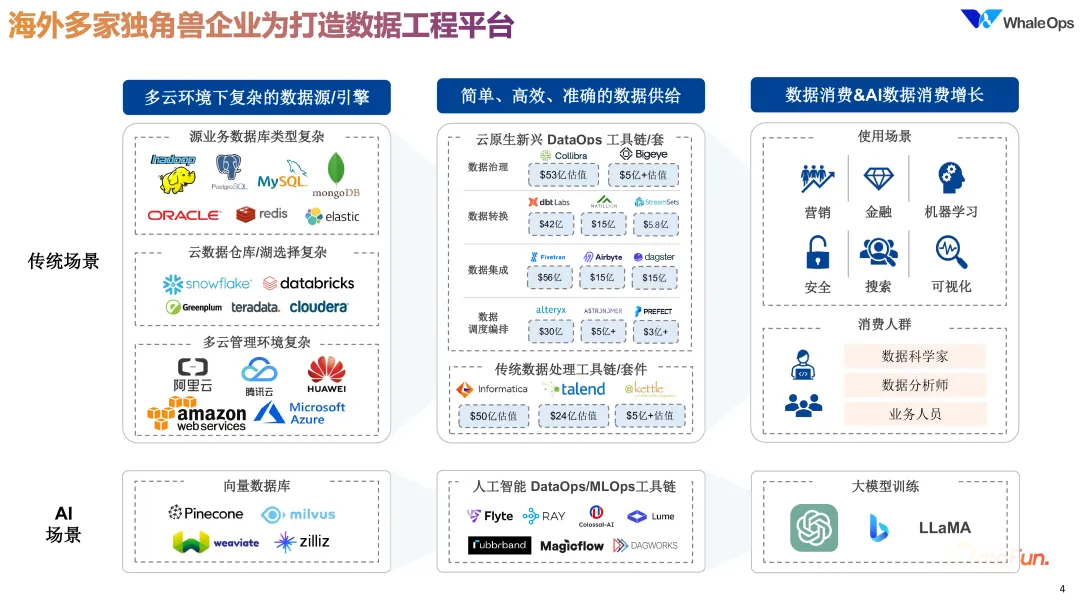
近年来,全球数据工程架构在 AI 应用的推动下发生了巨大变化,尤其是一些海外独角兽企业在技术上持续创新。以往的数据架构主要依赖传统数据库和大数据平台,如 Oracle、Hadoop、MySQL 和 MongoDB,但现在这些数据库纷纷增加了向量支持,适应 AI 对向量数据处理的需求,如 MongoDB、Elasticsearch 和 Redis 等。
2. 数据工程与大模型
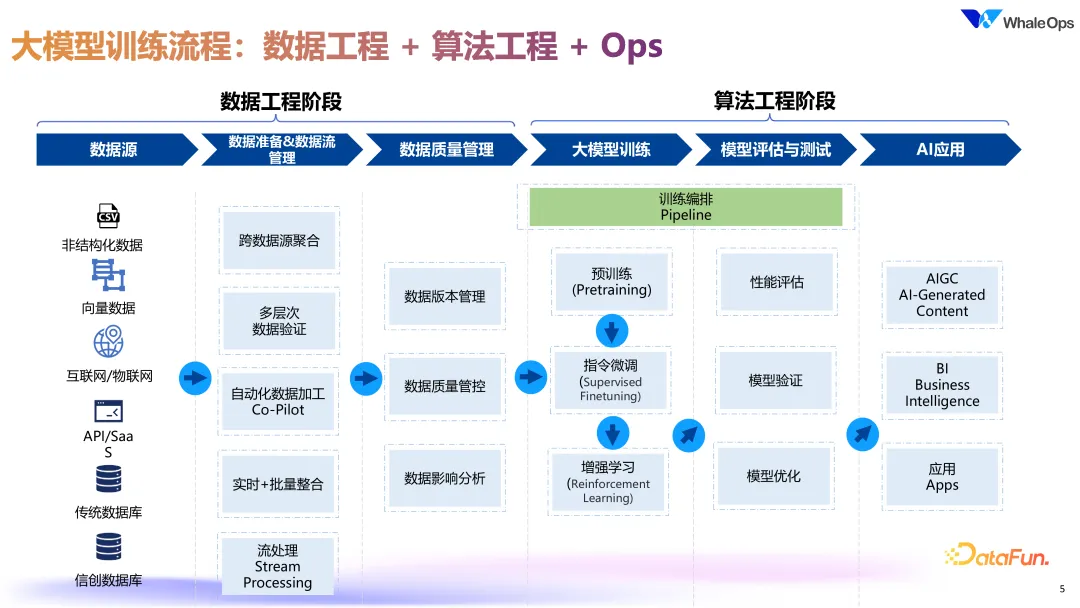 关于大模型的训练,数据工程不仅需要整合多种数据源(包括结构化、非结构化以及向量数据),还要实现跨源数据聚合和多层次的数据验证。
关于大模型的训练,数据工程不仅需要整合多种数据源(包括结构化、非结构化以及向量数据),还要实现跨源数据聚合和多层次的数据验证。
3. SeaTunnel 的诞生-企业面临的数据挑战
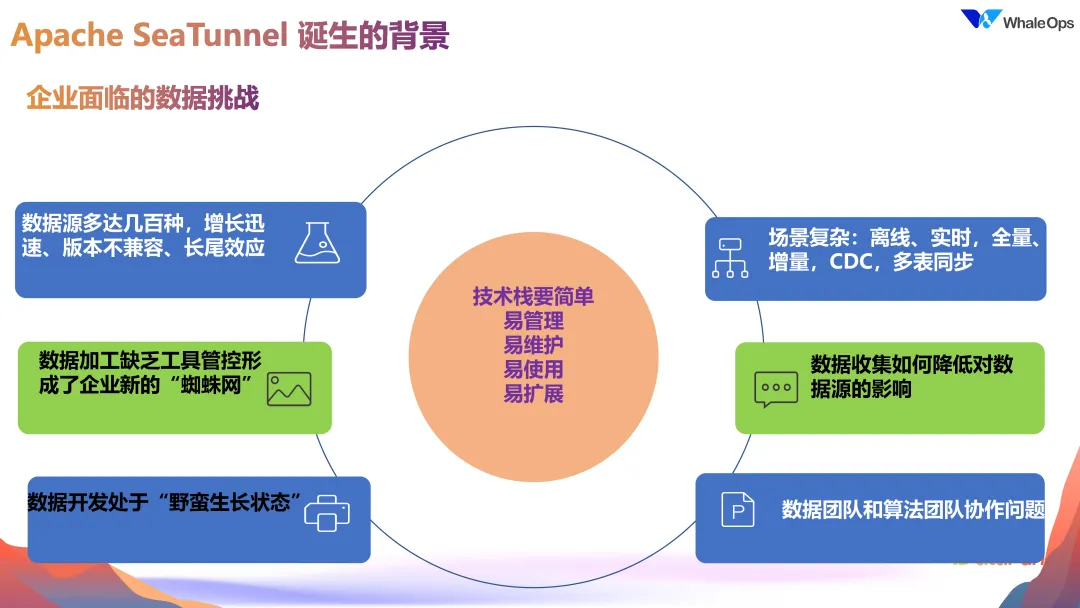
在企业构建数据平台,特别是应用于 LLaMA 等大模型的过程中,数据工程团队往往面临多重挑战。
4. 新技术挑战下的 EtLT 架构
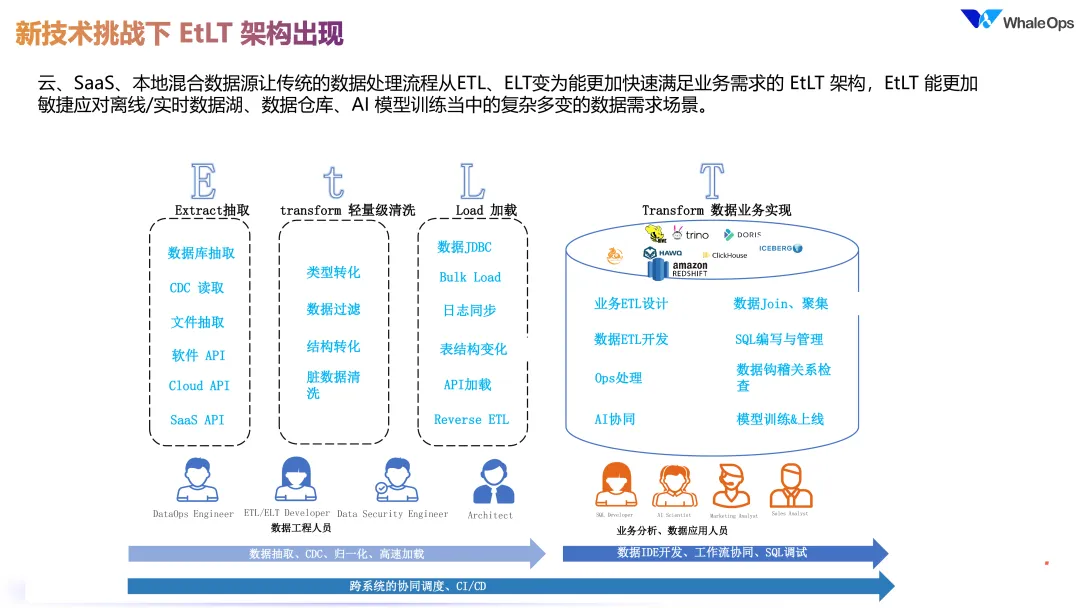
随着业务场景和技术挑战的增多,数据工程逐步从传统的 ETL 架构演进到更为灵活的 EtLT 架构。这一演变不是简单的位置转变,而是为了适应云 SaaS、混合数据源以及实时数据湖和数据仓库的需求。EtLT 架构的出现使数据处理更加敏捷,尤其是在云计算和数据引擎能力增强的背景下,这种架构更好地支持了 AI 模型训练过程中复杂多变的数据需求。例如,ClickHouse 如今可以在单机模式下实现对数百亿数据的秒级查询,这在传统数仓引擎中是难以实现的,反映了现代数据引擎在大数据处理和查询速度上的显著提升。
EtLT 架构中数据抽取的要求也更高,不仅需要实时抽取,还必须处理如 binlog 的变更以及 DDL 更新等复杂场景。例如,当上游数据表字段增减时,下游数据库或数据湖也需实时同步更新字段。这种高效的数据抽取方法在传统 ETL 流程中无法实现。此外,随着 SaaS API 的对接愈加复杂,数据抽取环节必须能够灵活适应业务变化。 在此基础上,EtLT 架构中增加的小“t”处理为数据加工提供了关键支持。数据在抽取过程中可以经过类型转换和字段过滤等处理,避免无用字段占用存储空间和计算资源。例如,若源表包含 300 个字段,而目标表只需 50 个,则通过过滤只同步必要数据,降低资源浪费。同时,脏数据的清洗和结构转换也在同步过程中完成,从而进一步提升数据质量和利用效率。
各类数据引擎在加载数据时的方式也因架构变革而多样化。例如,Doris 需要 stream load 模式,Redshift 则采用 co
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











