



大家好,我叫高楚枫,来自阿里云 EMR 团队的开发工程师,同时也是 Apache DolphinScheduler 的 PMC 成员之一。

今天非常高兴能在这里和大家分享关于跨工作流复杂依赖的功能详解。
引言
在现代的数据处理和调度过程中,工作流的依赖管理变得越来越复杂,尤其是当涉及多个工作流的依赖关系时。Apache DolphinScheduler 为此提供了强大的跨工作流依赖功能,帮助开发者更高效地管理和调度复杂任务。
今天的分享会从以下五个方面进行讲解:
- Apache DolphinScheduler 和 Airflow 中的跨工作流依赖的体现方式
- 跨工作流依赖场景的复杂性
- 跨工作流依赖执行流程详解
- 跨工作流的补数场景
- 常见问题及案例分析
接下来,我将为大家逐一讲解这些内容。
DS的跨工作流依赖
首先,给大家介绍一下 Apache DolphinScheduler 中跨工作流依赖的实现方式,大家可以看下面这个截图,主要通过一个名为 dependent task 的任务插件来实现。
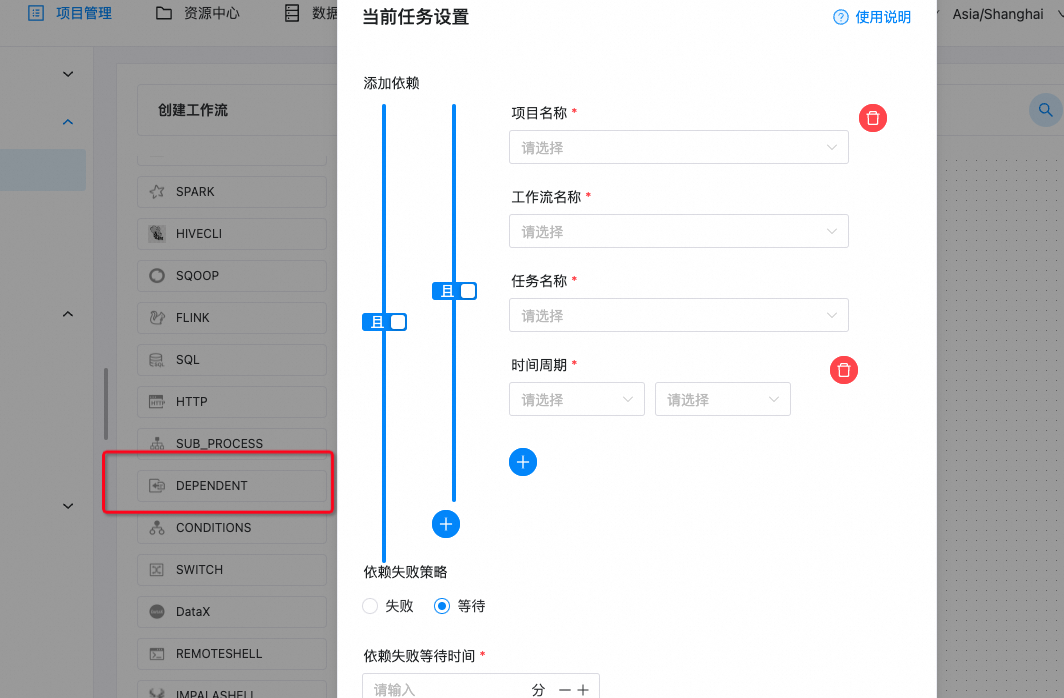
对于那些熟悉 Apache DolphinScheduler 的朋友来说,可能会觉得奇怪,因为它看起来像是一个普通的任务插件。
那么,这其中有什么特别之处?为什么跨工作流依赖功能显得复杂呢?实际上,这背后有以下三个关键点:
两种插件形式
在 Apache DolphinScheduler 中,插件有两种形式:
- Worker task:例如运行 shell 脚本、Spark 作业、Flink 作业等,它们都在 worker 上执行。这类插件具有极强的扩展性,且可以方便地进行插拔。
- Master 上的 logic task:
dependent task则是运行在 master 上的逻辑任务,和工作流调度的核心逻辑存在强耦合性。在涉及复杂的依赖关系时,这种逻辑任务会产生更多的组合情况,从而显著增加任务调度的复杂度。
依赖的定义
大家可以看看下面这张图片,当你在 DolphinScheduler 中创建一个 dependent task 后,你可以选择项目名称、工作流名称和任务名称,从而指定跨工作流的任务依赖。甚至在跨项目的工作流中,也可以通过这种方式进行配置。
有些人可能会问:为什么我们不在同一个工作流里解决依赖关系?
这是因为,在像 Apache DolphinScheduler 或 Airflow 这样的开源调度工具中,调度的属性是在工作流级别上定义的,而不是任务本身。
如果两个任务之间存在依赖关系,但它们的调度周期不同,就需要通过跨工作流依赖来解决。
这里已经涉及到了一些概念,任务的调度周期、依赖的周期以及依赖失败的处理策略都是非常重要的概念。这些将在后续部分中跟大家详细讲解。
跨工作流依赖的存储方式
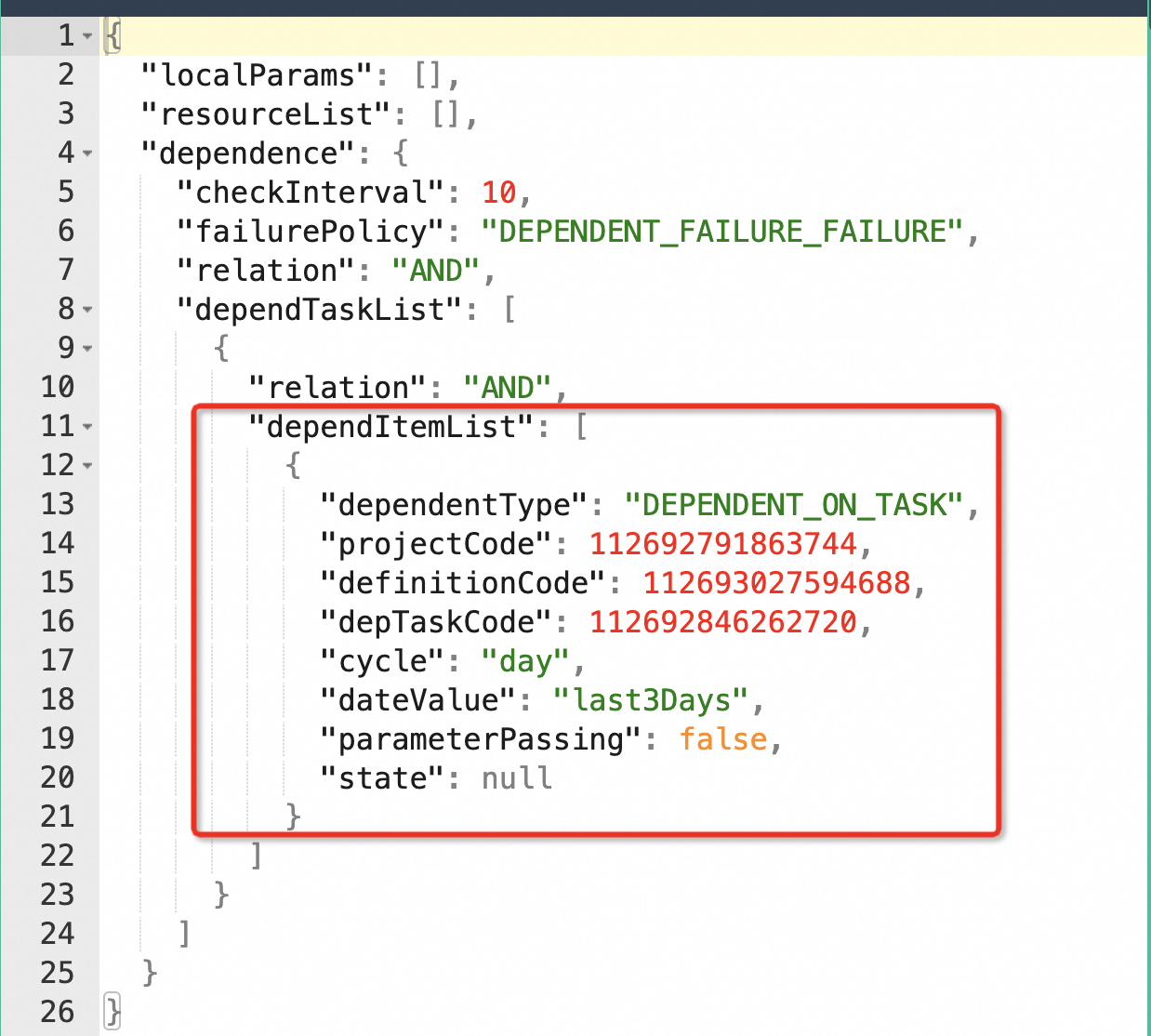
在 Apache DolphinScheduler 中,dependent task 作为任务插件被存储在数据库中。在数据库的 task parameters 中,会有相应的刚才在上图看到的对应的项,保存了与依赖任务相关的配置参数。
例如,dependent type 可以指定为 dependent on task,表示依赖于跨工作流中的具体任务。还有另一种形式是 all task,即依赖于整个工作流的执行结果。
当前 DolphinScheduler 中的跨工作流依赖管理还存在一些复杂性。这边详细去讲的话,又会有其他的情况。
比如在生产环境中,某些用户希望判断工作流实例中每个任务的成功与否,这需要通过手动组合多个依赖项来实现。虽然目前还没有一键依赖所有任务的功能,但通过 dependent task 中的逻辑组合按钮,我们可以实现复杂依赖关系的配置。
技术细节
在跨工作流依赖的实现中,Apache DolphinScheduler 通过多个唯一标识符来管理项目、工作流和任务。
这些标识符包括 project code、definition code 和 task code,它们分别对应项目名称、工作流名称和任务名称。这些唯一标识符是由后台自动生成的,用于识别跨工作流的依赖关系,确保各项任务之间的依赖能够准确生效。
Airflow的跨工作流依赖
除了 Apache DolphinScheduler,Apache Airflow 中也可以通过Sensor来实现跨工作流依赖实现。

其中一个常见的配置是 ExternalTaskSensor,用于监控外部工作流的任务状态。和 DolphinScheduler 的 task code 类似,Airflow 的 external_task_id 和 external_dag_id 提供了对应的任务和工作流标识符,帮助不同的工作流之间建立依赖关系。
Airflow 的 Sensor 通常会占用 worker 的 slot,在早期版本中,这可能会导致资源浪费,因为当依赖的外部任务还未完成时,Sensor 会持续等待占用资源。
不过,Airflow 在较新版本中引入了一个名为 Trigger 的机制,优化了这一流程。
它允许异步检查依赖状态。一旦依赖条件达成,Trigger 会重新唤醒任务,从而避免占用过多的 worker slot,实现更高效的资源利用。
其他处理技巧
当然,无论是在 Airflow 还是 Dolphin 中也有一些技巧可以用来处理跨工作流依赖的场景。
例如,Airflow中有个 TriggerDagRunOperator。这个operator可以触发另一个外部工作流中的任务运行。
DolphinScheduler也支持使用子工作流的方式来实现跨工作流依赖。这种方法是将子工作流嵌入到主工作流中,并通过主工作流触发其他外部任务。
虽然这种方式在处理简单场景时效果良好,但它并不适用于复杂场景。特别是在上游和下游工作流具有不同周期,或存在依赖周期需求的情况下,这种方法会有很多局限性:

所在这里不建议使用子工作流的方式处理跨工作流依赖,大家可以看到它存在以下缺陷:
无法应对复杂场景: 当上游工作流和下游工作流的周期不一致,或者存在复杂的依赖关系时,子工作流的方式显得力不从心。
强耦合问题: 子工作流会使得上游和下游工作流紧密耦合,导致当需要修改依赖关系时,不得不去修改上游工作流中的节点。这不仅增加了维护的复杂度,也降低了灵活性。
因此,虽然子工作流在某些简单场景下可以使用,但对于依赖关系复杂、调度周期不一致的场景,不推荐使用这种方法。接下来,我将深入讲解为什么跨工作流依赖会变得如此复杂,以及背后的挑战。
跨工作流依赖的复杂性
在 Apache DolphinScheduler 中,dependent task 是一个相对复杂的功能模块。
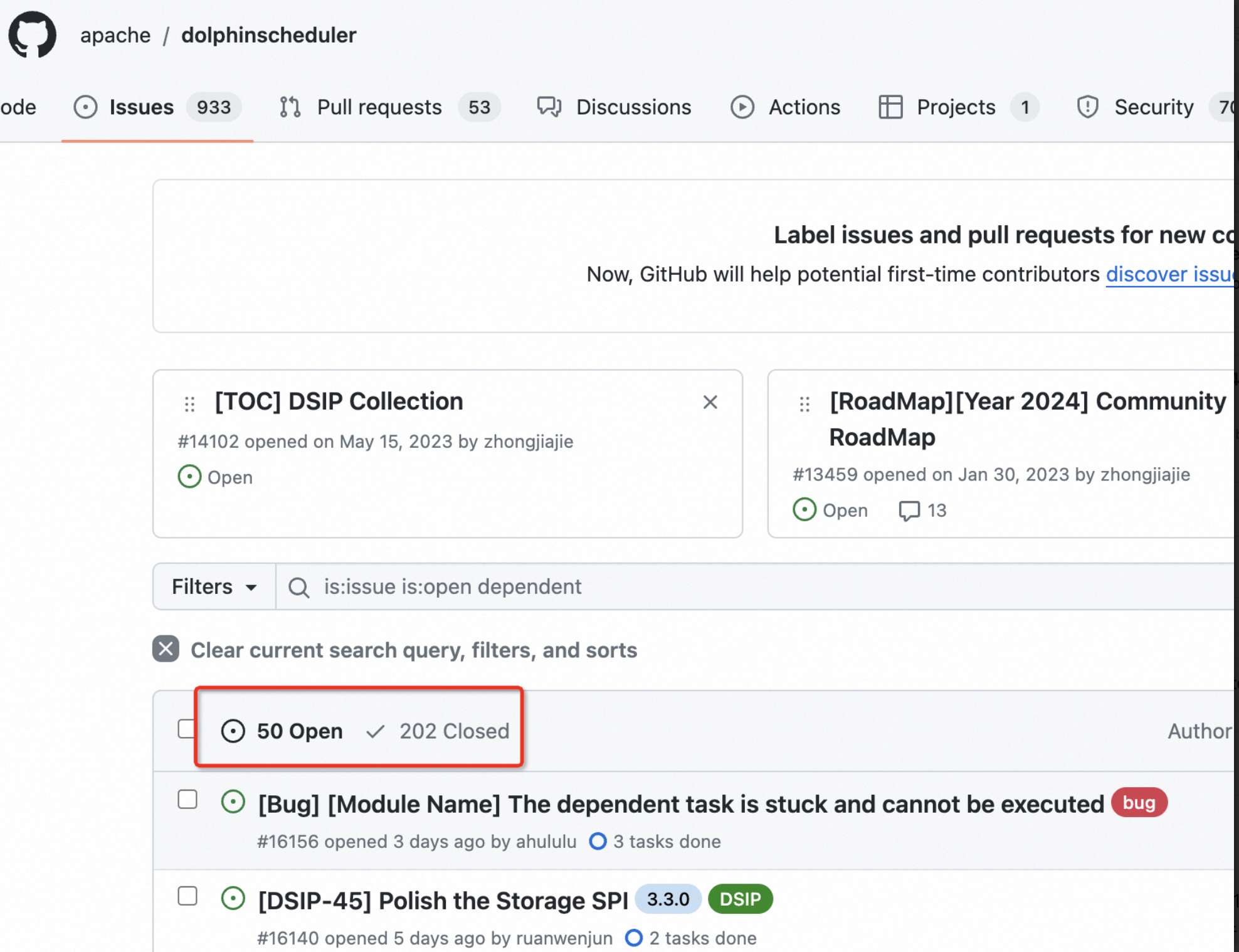
事实上,如果大家在 GitHub 的 Apache DolphinScheduler 仓库中搜索 dependent task,可以找到大量与之相关的 issue 和 PR,可能有上百个。
生产环境中,用户反馈的问题中,大约有 20%-30% 都与 dependent task 相关。那么,为什么这个功能会引发如此多的问题呢?
判定逻辑的复杂性
首先,dependent task 的判定逻辑本身就非常复杂,不仅在代码实现上有相当多的逻辑分支,而且在语言层面和功能的理解上,用户往往也会遇到困难。
它涉及到不同任务之间的依赖关系、调度逻辑,以及依赖满足与否的多种判断情况。
工作流之间周期不一致且依赖周期复杂
不同的工作流可能有着不同的执行频率和周期,而在跨工作流依赖的场景中,调度周期和依赖周期如何匹配,以及如何协调这些周期之间的关系,都是容易让人感到困惑的地方。
跨工作流联动补数
另外一个复杂场景是 补数(Backfill),这是指在历史数据的场景下,重新运行某个实例以补充之前执行失败的任务。在这种情况下,依赖关系可能非常复杂,涉及多层次的任务和工作流依赖,还包括对同周期工作流的重新部署,很多用户对此理解有误,容易混淆。
特殊的失败策略
此外,dependent task 还支持不同的失败策略,每个依赖任务可以配置专门的失败处理逻辑。这种灵活性带来了更多的复杂情况,不同的失败策略会导致任务在执行时表现出不同的行为。
跨工作流依赖执行流程详解-提交
为了更好地理解 dependent task 的执行逻辑,我们需要通过它的端到端流程来分析。在 Apache DolphinScheduler 中,dependent task 的提交与执行流程和其他任务插件类似,但在判定任务是否成功的过程中有其不同的操作。
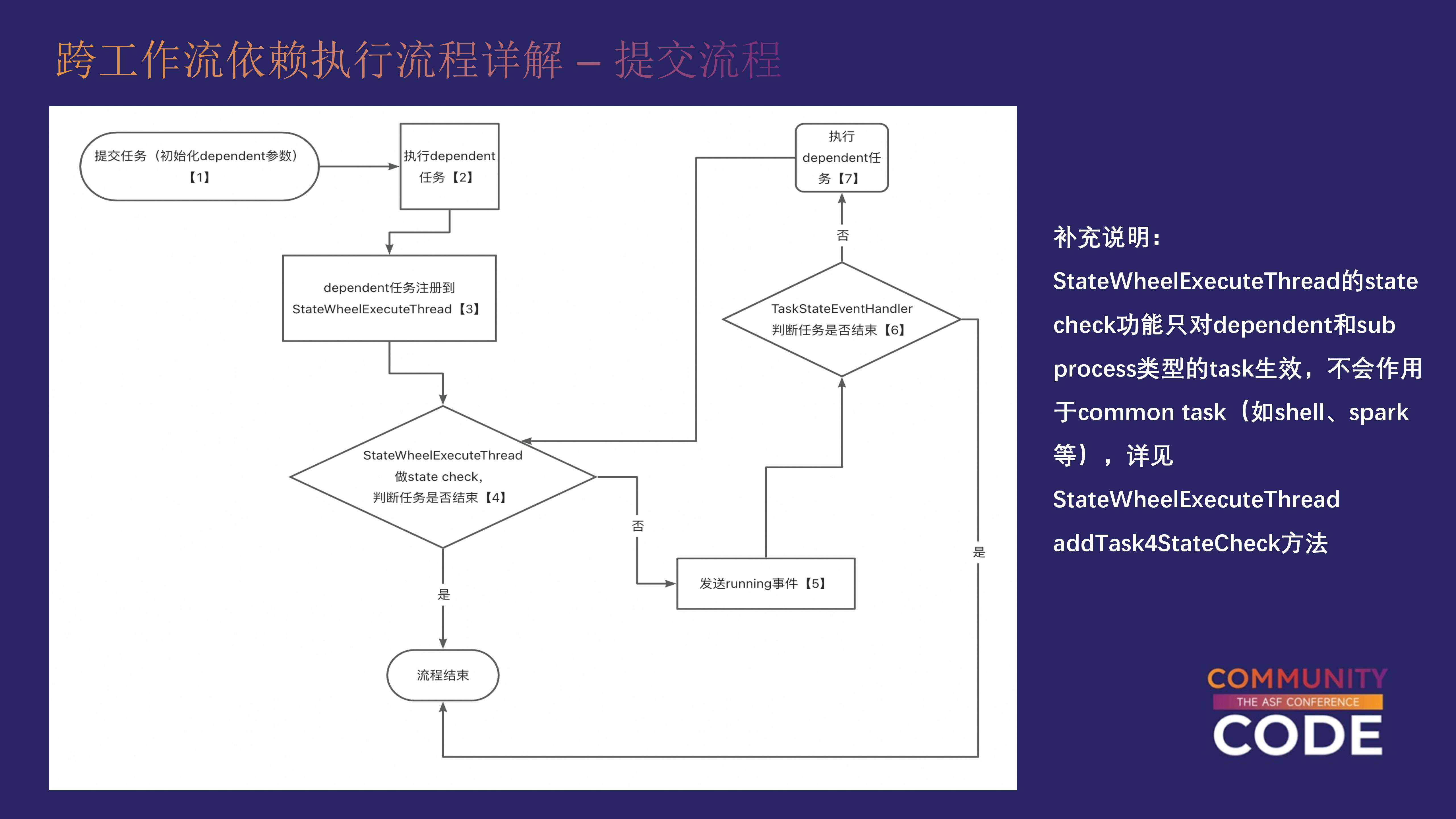
1.提交任务实例
当提交一个 dependent task 时,首先会进行实例化。系统会从数据库中提取任务的配置参数,生成一个任务实例,并将其提交到 dependent task 的执行流程中。
2.注册到 StateWheelExecuteThread
在任务提交后,它会被注册到一个名为 StateWheelExecuteThread 的线程中。该线程会定期轮询,监控任务状态的变化。如果依赖的上游任务还没有完成,它会保持任务的 running 状态,并等待上游任务的依赖条件满足。
3. 事件驱动的执行逻辑
Apache DolphinScheduler 的核心是基于事件驱动的工作流调度系统。当 dependent task 接收到任务状态变化的事件时,才会触发下一步的判断。通过这种事件驱动的方式,可以在不占用多余资源的情况下实现等待依赖完成的目的。
4. 判断依赖是否满足
dependent task 的执行流程中有一个 TaskStateEventHandler,负责对依赖任务的状态进行判定。如果依赖任务满足条件,dependent task 会结束执行;如果依赖未满足,则会继续轮询,直到依赖完成。
下面标注了相应的代码,通过查看源码,可以更清晰地理解 dependent task 的执行逻辑。
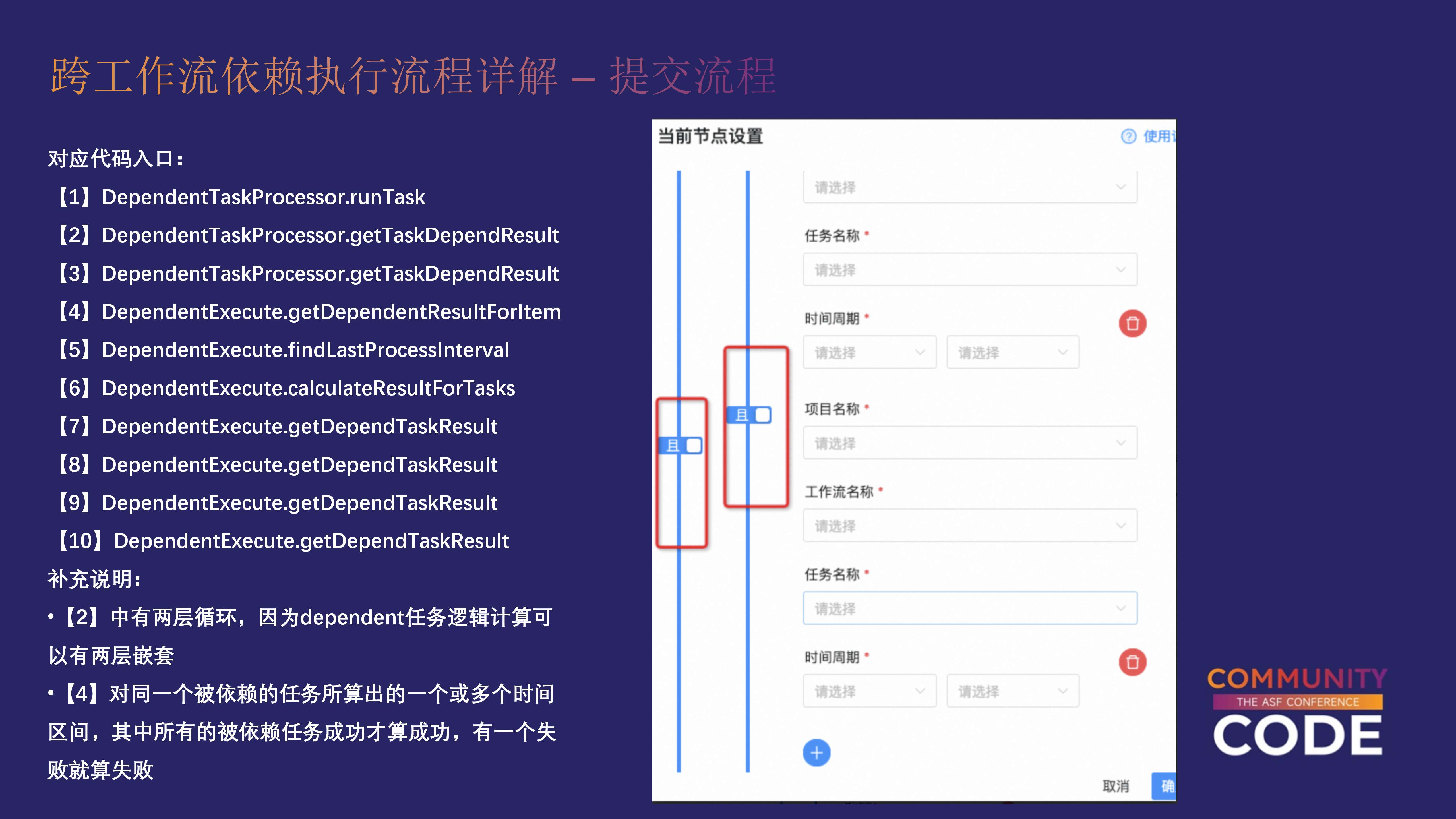
DependentTaskProcessor.runTask DependentTaskProcessor.getTaskDependResult DependentTaskProcessor.getTaskDependResult DependentExecute.getDependentResultForItem DependentExecute.findLastProcessInterval DependentExecute.calculateResultForTasks DependentExecute.getDependTaskResult DependentExecute.getDependTaskResult DependentExecute.getDependTaskResult DependentExecute.getDependTaskResult
需要注意的是,本次分享的内容和 PPT 主要基于 3.2.0 之前的版本(即 3.0.X 到 3.1.X 版本)。这些版本中的依赖功能基本一致,核心逻辑没有发生较大变化。
然而,在 3.2.0 版本中,DolphinScheduler 对依赖功能进行了较大的重构,可能从代码结构上看会有所不同。尽管如此,其核心思想和主要实现方式仍然保持一致,差异主要体现在细节上。
跨工作流依赖执行流程详解-状态判断逻辑
依赖任务的判断逻辑相对复杂,涉及多个步骤和条件的处理。
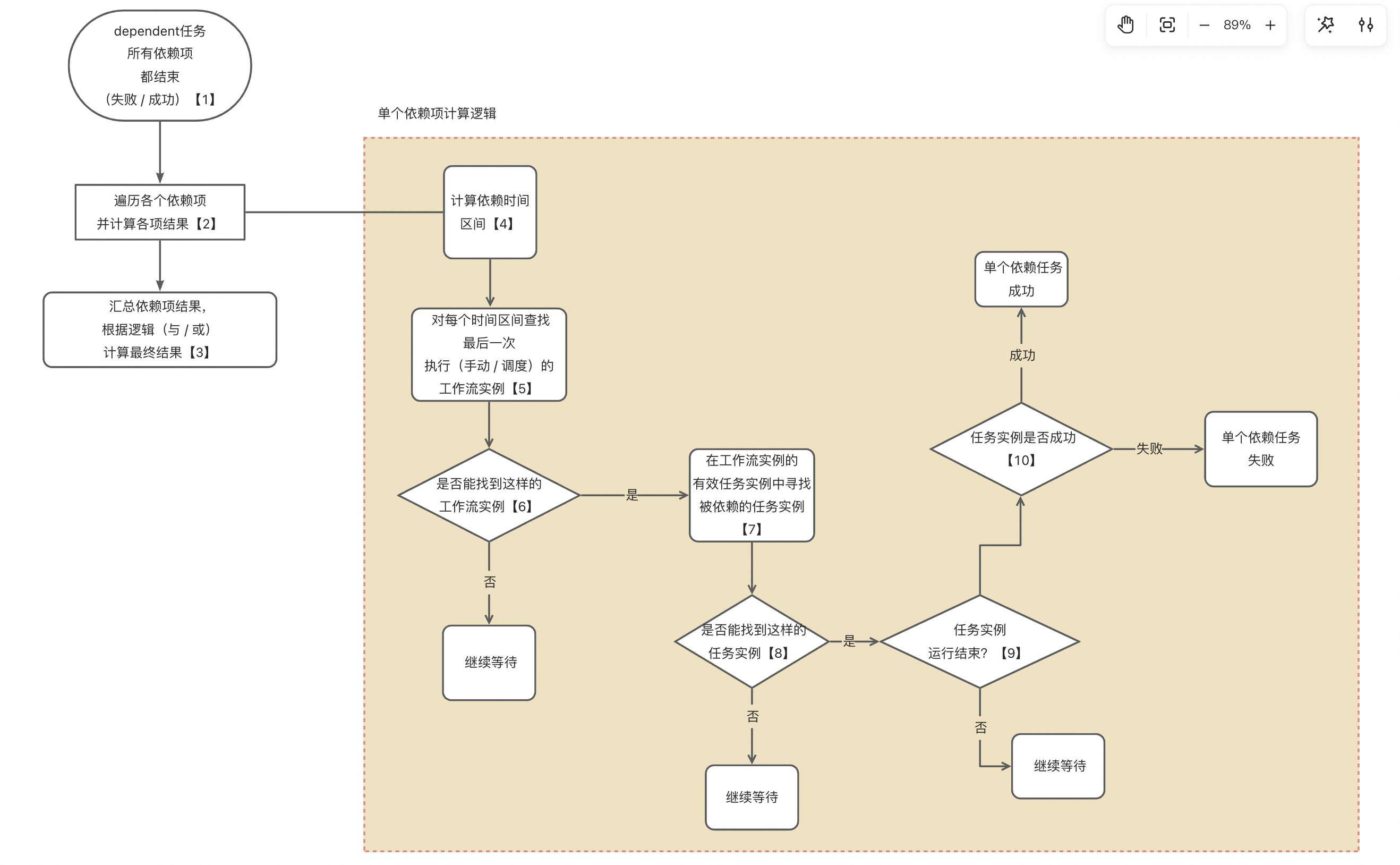
以下是该判断过程的详细解释:
依赖项的结束条件
首先,一个依赖任务可能依赖多个其他任务或工作流。这些依赖项必须全部结束,依赖任务才会继续往下执行。如果有任何一个依赖项尚未结束,依赖任务将会被阻塞,继续等待。
遍历依赖项
当所有依赖项结束时,系统会对每个依赖项进行遍历。这是一个循环过程,依赖任务会逐一检查每个依赖项的状态,确保其执行结果满足预期。
依赖周期的处理
在遍历依赖项的过程中,另一个复杂的因素是依赖周期。依赖周期是指任务的执行周期区间,它决定了任务在不同时间周期内的依赖状态。在处理依赖周期时,系统会再次进行循环检查,遍历每一个周期区间,判断其是否满足依赖任务的期望条件。
依赖周期是跨工作流依赖中的一个核心概念。不同的任务可能具有不同的周期性调度,因此需要系统在每个周期内计算依赖的满足情况。
简单来说,每个任务都可能在不同的时间段有不同的依赖关系,因此需要遍历多个时间周期,并逐一判断依赖条件是否满足。
跨工作流依赖执行流程详解-依赖周期
在依赖任务的执行过程中,时间区间的判定是一个关键点。
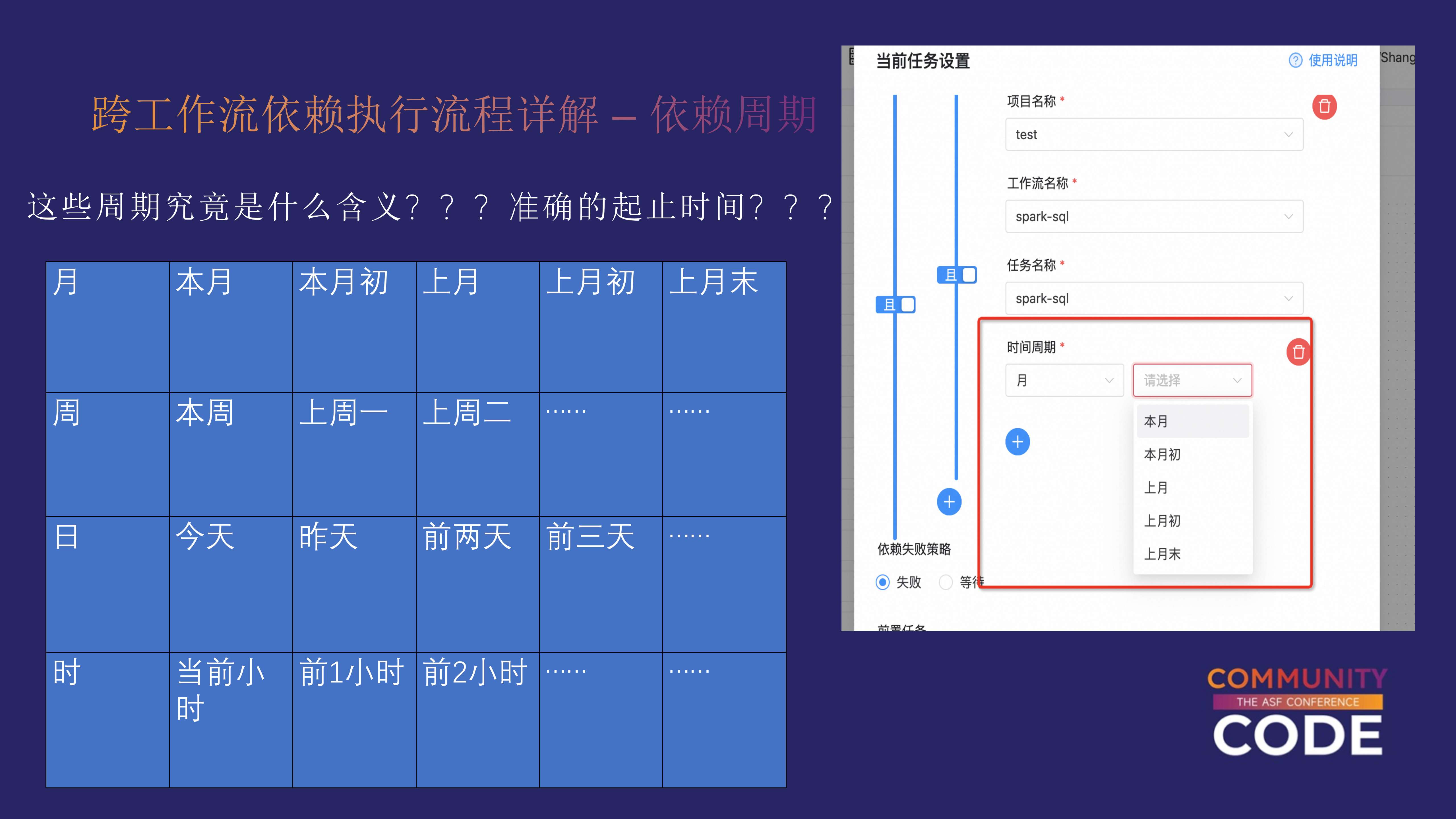
每个依赖任务需要查找最后一次执行的工作流实例,并根据时间区间判断是否满足依赖条件。
要理解这个过程,我们需要从三个时间相关的参数入手:
- Start Time(开始时间)
- Schedule Time(调度时间)
- End Time(结束时间)
其中,Schedule Time 是预先已知的,因为它代表了工作流的计划调度时间。但是,Start Time 和 End Time 并不能在任务启动之前确定,它们会根据实际的任务执行情况动态生成。
手动触发与周期调度的区别
对于 Schedule Time,由不同触发方式所产生的工作流实例情况有所不同:
手动触发:手动触发的工作流实例没有
Schedule Time这个属性周期调度:周期调度的工作流实例则会有明确的
Schedule Time。
依赖任务在判定时,主要依据的是 Start Time(实际调起的时间)。如果 Start Time 落在依赖的时间区间内,任务才会进入下一步的逻辑。如果没有找到符合条件的实例,任务将继续等待。
依赖的两种类型
依赖任务可以分为两种情况: 依赖整个工作流:在这种情况下,系统会检查整个工作流是否成功执行。如果工作流成功,则依赖任务也会成功;如果工作流失败,则依赖任务也会失败。如果工作流还在执行中,任务将继续等待,不会立即做出结论。
依赖具体的 Task 实例:系统需要先判断指定的 Task 实例是否存在。如果工作流实例已生成,但尚未执行到该 Task,任务同样会继续等待,直到找到相应的 Task 实例,并根据 Task 实例的执行结果来判定依赖是否满足。
单个依赖项的逻辑
对于每个依赖项,依赖任务会判断其最终执行结果。如果依赖项成功,则任务依赖满足;如果失败,则任务依赖失败。但整个依赖任务的执行逻辑不仅仅是基于单个依赖项,还包括时间区间的判定。每个时间区间内,所有依赖项都必须成功,才能认为任务依赖成功。
在 dependent task 中,用户可以通过配置逻辑表达式来处理多个依赖项。
系统提供了“且”(AND)和“或”(OR)两种逻辑操作符,用于组合多个依赖项。如果你有多个跨工作流的依赖任务,通过这些逻辑表达式,可以将它们组合起来,形成复杂的依赖关系。
最终,系统会根据你设置的逻辑表达式计算依赖项的整体状态。只有在所有组合条件满足的情况下,任务依赖才会被认为成功。
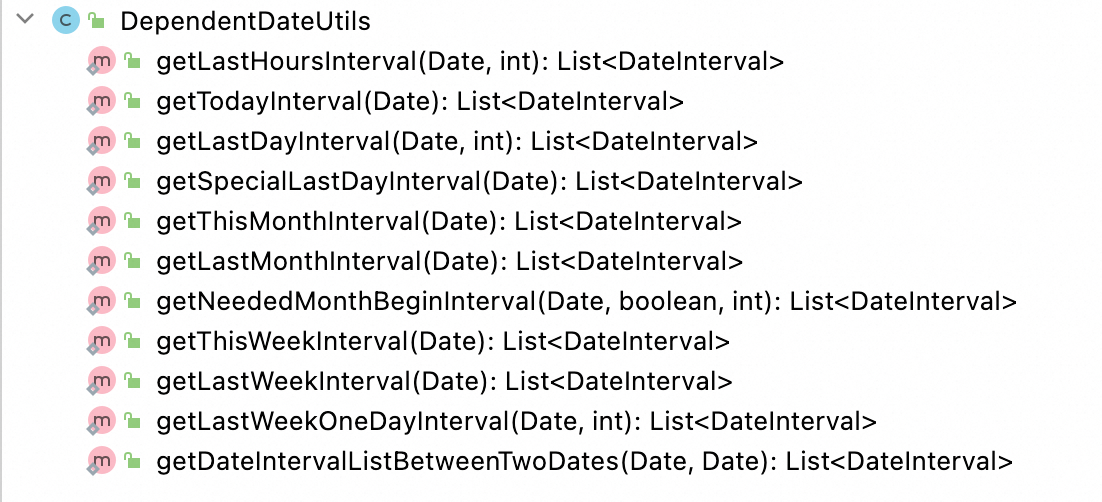
这张图的是代码入口,如果大家想去看具体的实现,或者是想要去推敲细节的话,可以去根据这个代码入口去看。
依赖周期是另一个关键概念。它是相对于调度周期而言的,是用来判定依赖任务是否在特定的时间段内满足条件的。调度周期是指任务的定时调度(例如每日凌晨0点,或每小时一次),而依赖周期则是跨工作流依赖中用于检查依赖任务是否完成的时间区间。
示例:依赖周期的判定
假设有一个子工作流在每月内需要检查父工作流的执行情况。那么,系统会在子工作流执行时,检查父工作流是否在本月内生成并完成。如果发现父工作流实例满足条件,则任务依赖成功。
对于依赖周期的判定,系统的逻辑是根据具体的时间周期来进行检查的,而不是基于绝对时间。
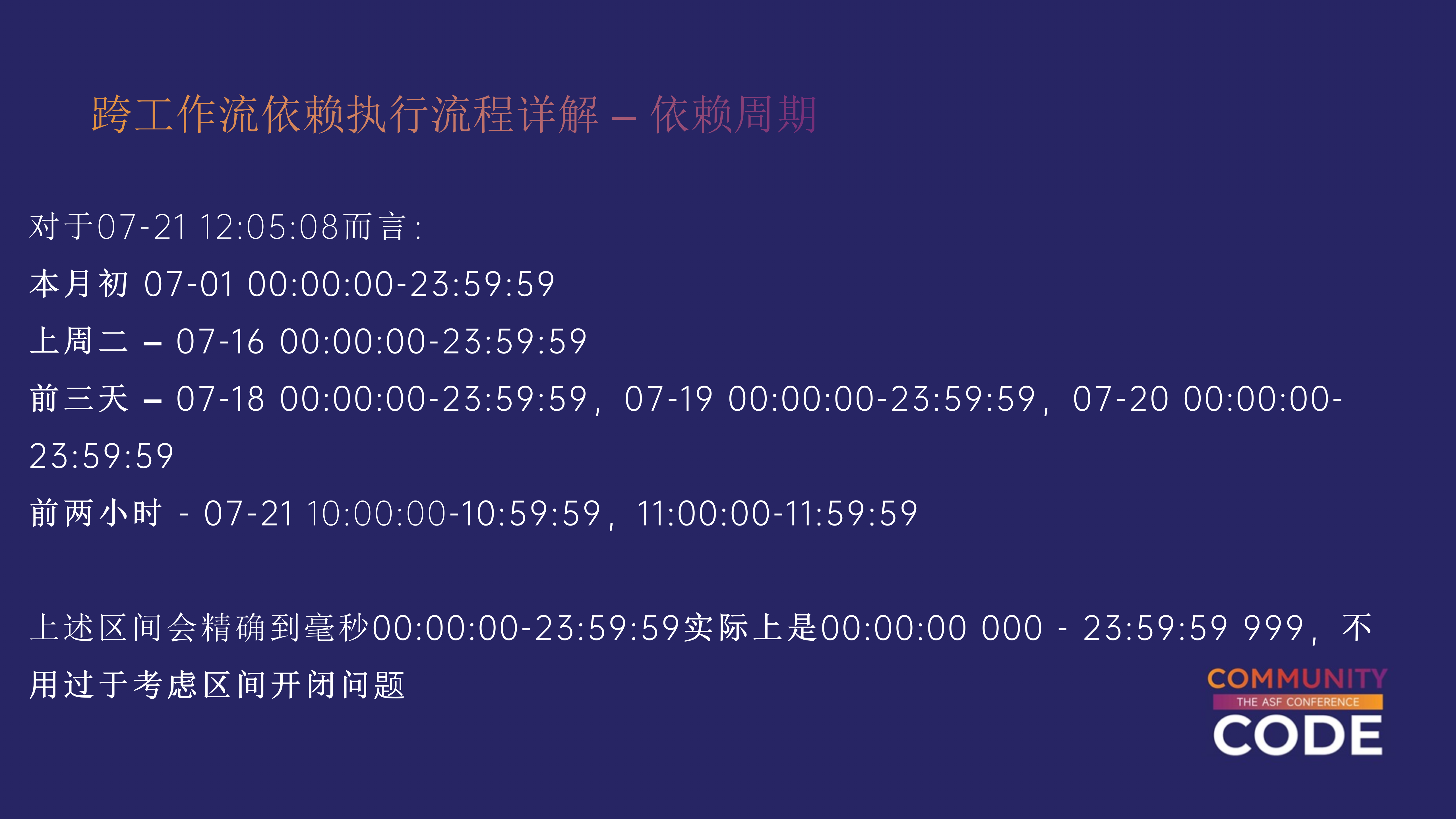
例如:
- 如果依赖周期是“本月”,系统会从本月的1号到月底(如7月1日到7月31日)来判定依赖是否满足。
- 如果依赖周期是“每小时”,那么系统会从整点开始(如从4:00到5:00)检查期间的实例执行情况。
在生产环境中,用户常常会遇到时间区间的歧义。
例如:
- 前两天:如果今天是7月28日,依赖任务可能需要检查7月26日和7月27日的实例。但实际上,系统会根据两个完整的时间段来判定,即7月26日0点到24点,以及7月27日0点到24点。如果这两个时间段中的实例都满足条件,依赖才会被认为成功。
这种时间区间的处理方式容易让用户产生误解,尤其是在处理更短的周期(如小时)时。
如果当前时间是4:10,依赖周期是1小时,用户可能会困惑应该从4:00到5:00计算,还是从3:10到4:10计算。
实际上,系统是从整点开始计算周期的,即从4:00到5:00。
复杂依赖周期的计算
在代码中,所有这些复杂的依赖周期都是通过一个特定的函数进行计算的。如果用户对这些时间周期的判定还感到困惑,可以参考代码中相关函数的实现,了解依赖周期的详细计算逻辑。
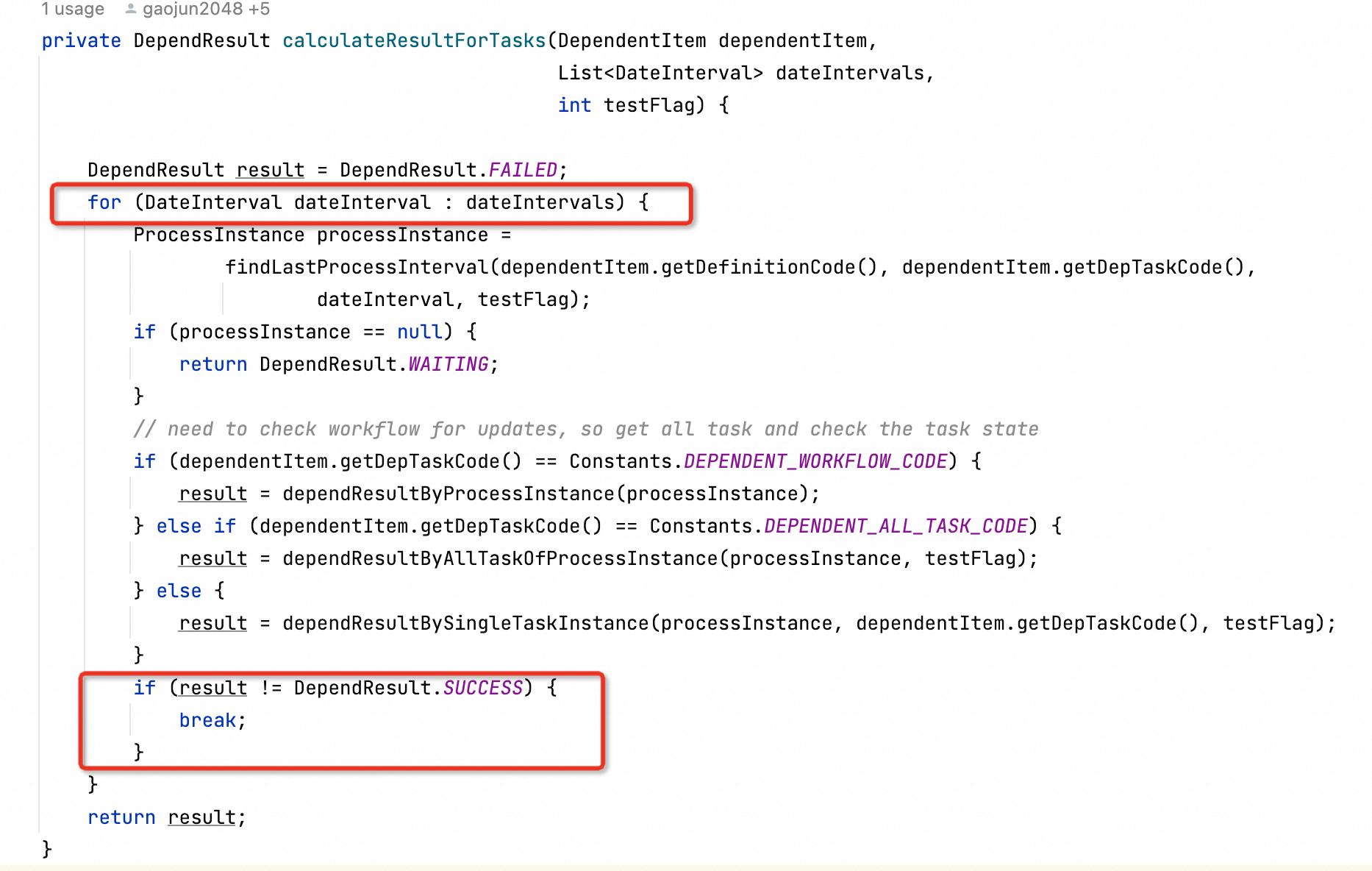
这里直接给大家贴了代码,通过查看该函数的实现,可以更明确地理解如何处理跨工作流的依赖周期,避免产生误解。
跨工作流的依赖在实际生产环境中是非常常见的需求,但其复杂的时间判定和依赖周期的处理逻辑使其难以掌握。
通过理解 dependent task 的执行流程、时间区间判定和依赖周期的概念,用户可以更好地掌握如何在 Apache DolphinScheduler 中处理复杂依赖场景。
如果有更深入的需求,可以通过查看源码中的相关函数来进一步理解这些逻辑的实现。
跨工作流补数
在之前的介绍中,我们已经了解到跨工作流依赖的复杂性。
然而,补数(backfill)操作进一步增加了复杂度,尤其是在生产环境中处理多层级的工作流依赖时,如果不加以仔细规划,很容易导致生产问题。
接下来我们讨论一下在补数操作中,跨工作流依赖会带来哪些挑战,并通过具体例子进行说明。
补数中的跨工作流依赖层级
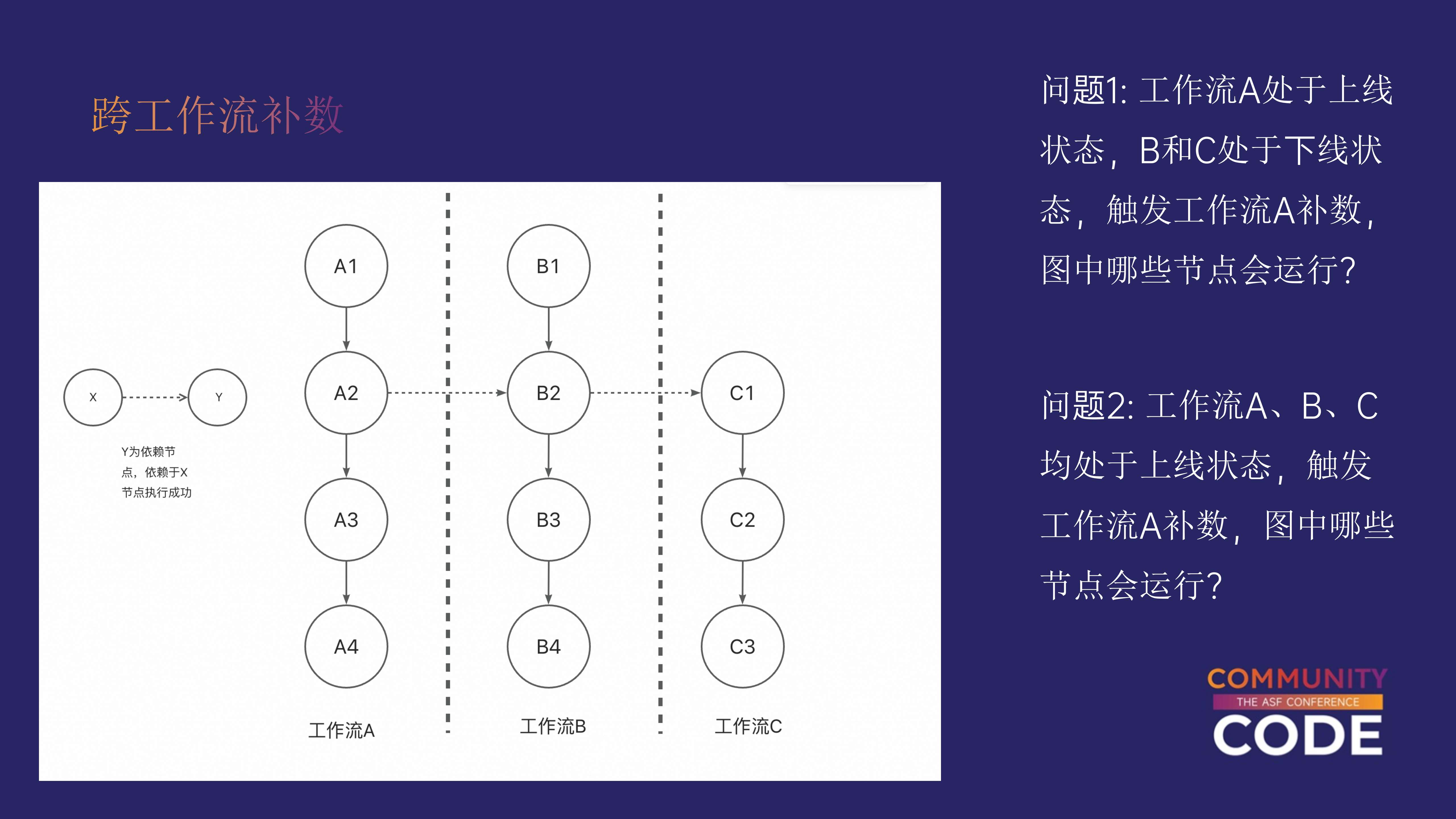
跨工作流的依赖可能涉及多个层级。
一个典型场景是有三个工作流:
A、B 和 C,每个工作流中包含多个任务。各个任务之间存在跨工作流的依赖关系。例如,任务 B2 依赖于 A 中的任务 A2,而 C1 依赖于 B2。这个层级关系在实际场景中可能会更加复杂,甚至可能涉及三到四个层级的工作流。
在补数操作中,我们要考虑的问题是:当上游工作流开始补数时,下游工作流将会如何受到影响?
部分工作流处于上线状态
假设当前有三个工作流,A、B 和 C,A 正处于上线状态,而 B 和 C 处于下线状态。
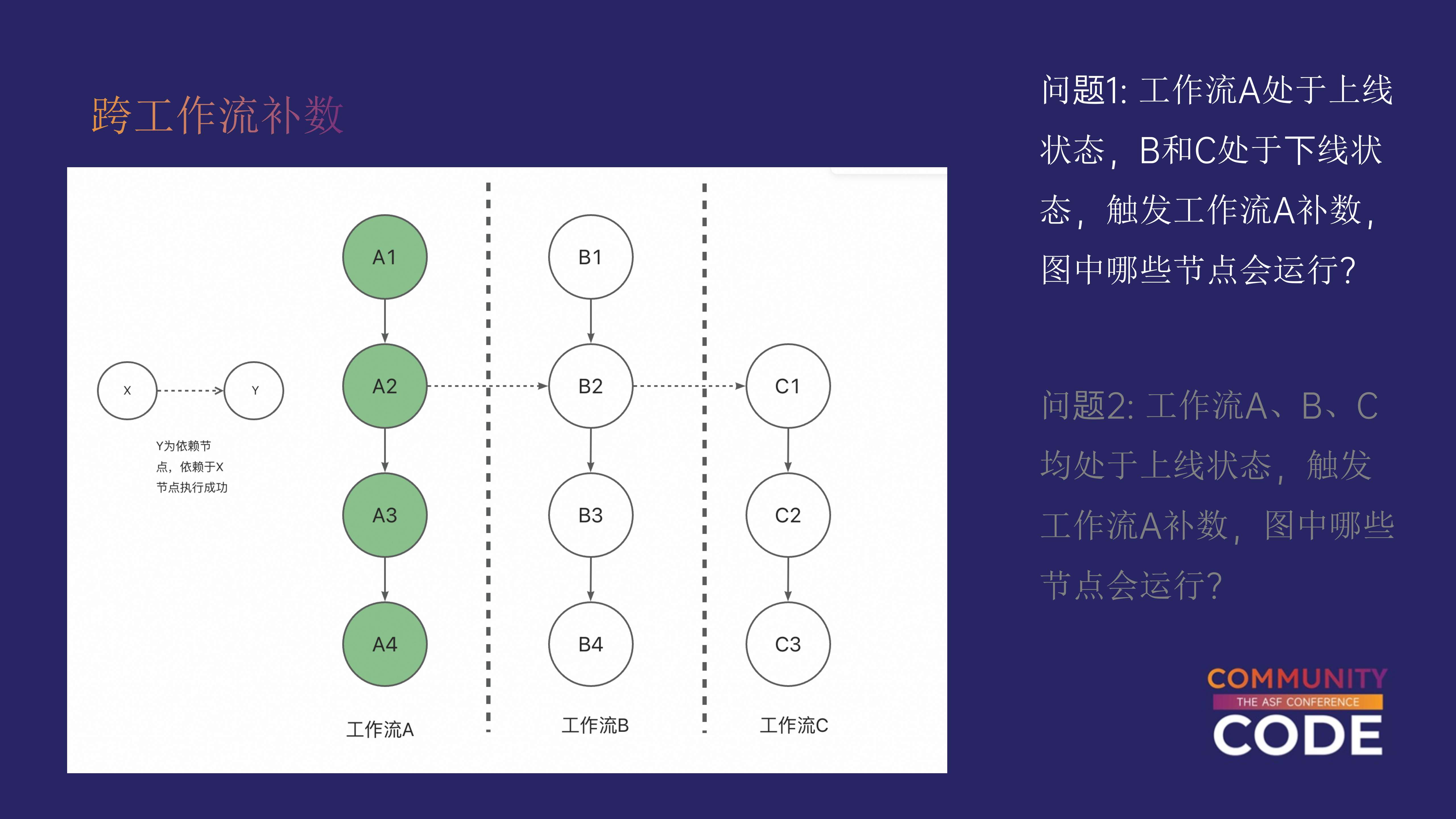
在这种情况下,如果我们触发工作流 A 的补数操作,哪些工作流和任务会受到影响?
根据补数的执行逻辑,只有工作流 A 中的任务会受到影响。系统在补数时会检查下游工作流的状态。
如果下游工作流未上线或未被挂起,那么它们将不会受到补数操作的影响。因此,在这个场景下,补数操作只会影响工作流 A。
所有工作流均处于上线状态
假设现在工作流 A、B 和 C 都处于上线状态,如果我们触发工作流 A 的补数操作,那么哪些任务会受到影响?
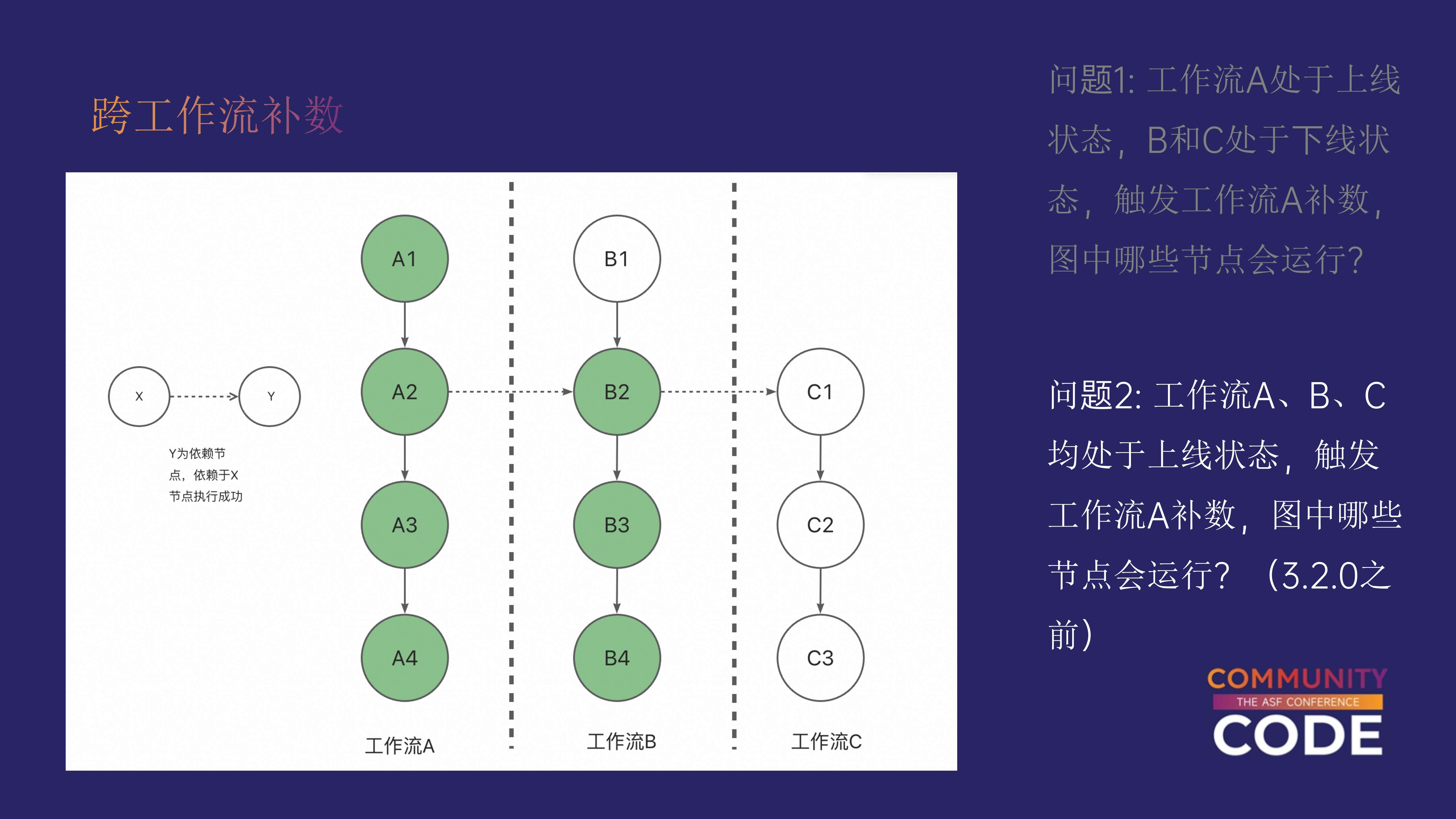
这个问题的答案取决于使用的 DolphinScheduler 版本:
- 3.2.0 之前的版本:补数操作只会影响直接的下游任务。也就是说,补数将影响工作流 A 的任务 A1、A2、A3、A4 以及工作流 B 的任务 B2、B3、B4。工作流 C 的任务 C1 不会受到影响,因为在 3.2.0 之前的版本中,补数不会递归检查下游的子工作流。
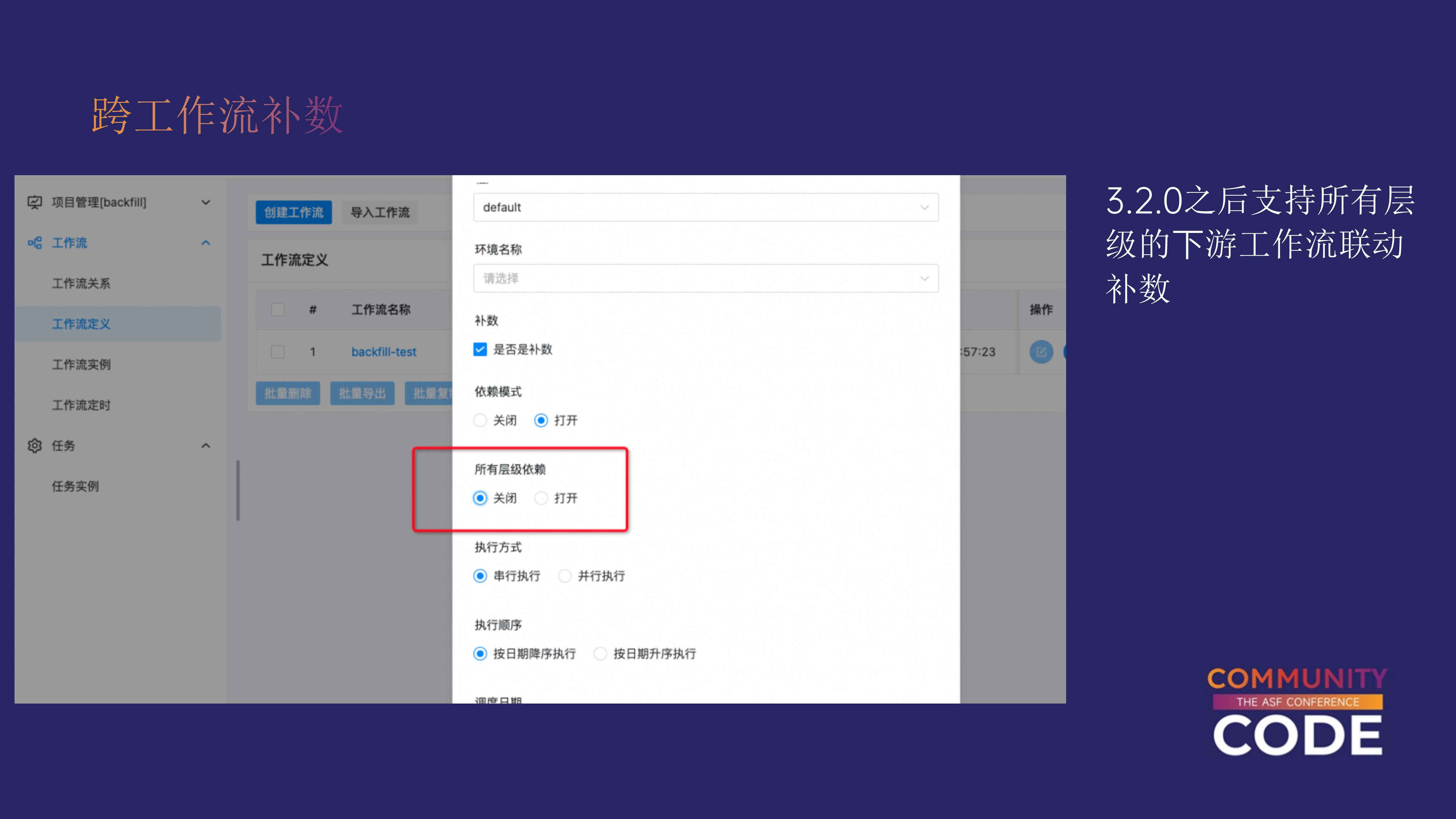
- 3.2.0 及之后的版本:从 3.2.0 版本开始,DolphinScheduler 增加了一个参数,允许用户选择是否递归检查下游的所有子工作流。通过启用该参数,补数操作不仅会影响直接的下游工作流,还会递归影响所有相关的子工作流。因此,C1 也将会受到影响。
调度周期不一致的补数场景
在某些情况下,工作流 A 和工作流 B 的调度周期不一致。
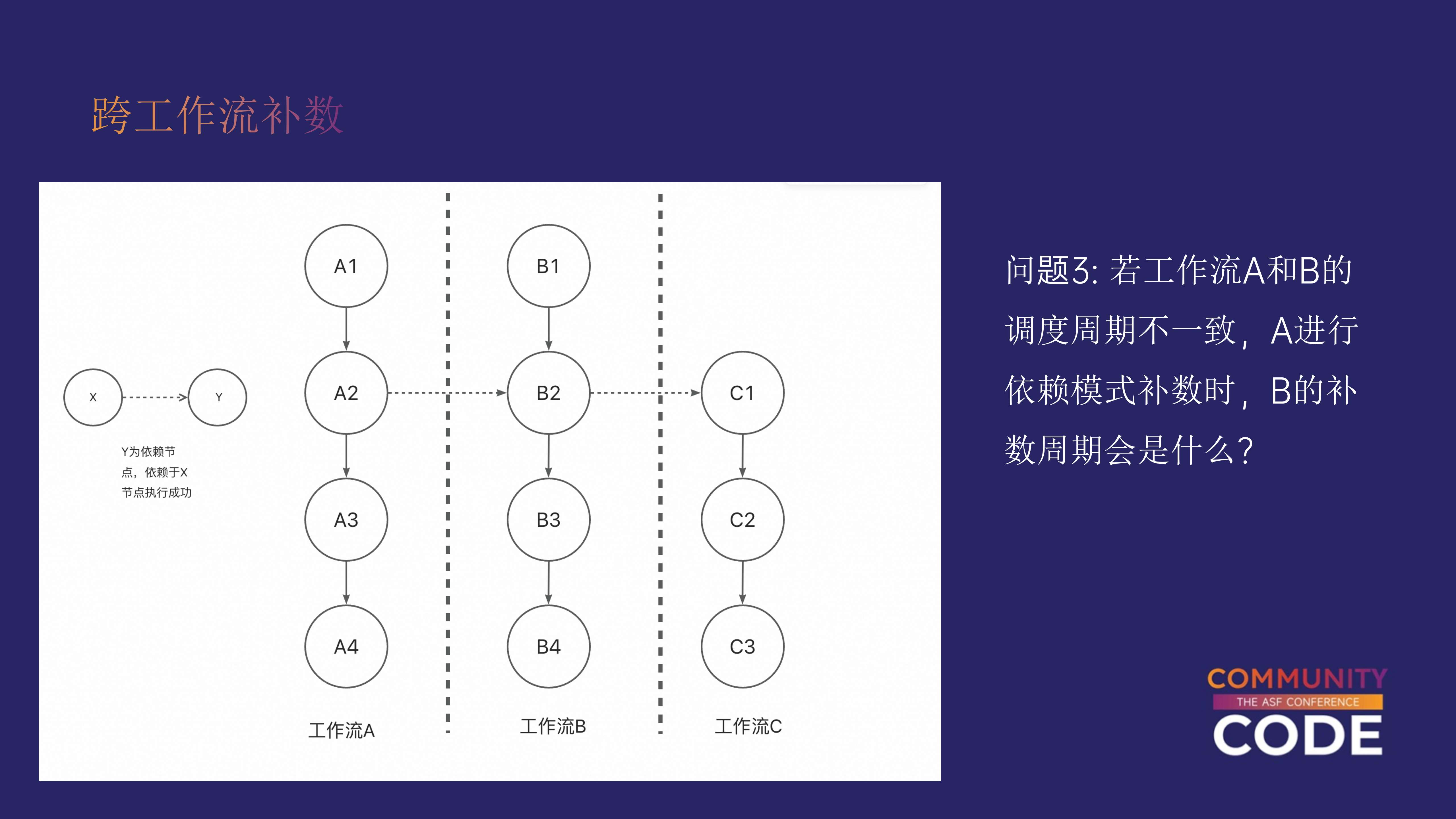
比如,工作流 A 每天执行一次,而工作流 B 每小时执行一次。那么,当我们对工作流 A 进行补数操作时,B 的调度周期如何处理?是按照 A 的周期,还是 B 的周期来执行?
答案是:以父工作流的周期为准。
在补数操作的底层逻辑中,系统会根据父工作流的周期生成实例。在生成补数实例时,DolphinScheduler 会向数据库中插入相应的指令(command),该指令的周期属性是基于父工作流的调度周期。
因此,在这种场景下,补数的周期将以工作流 A 的调度周期为准。
常见问题解析
在跨工作流依赖的实际使用过程中,用户经常会遇到一些问题,很多问题涉及概念上的模糊理解。

这些问题虽然看似常见,但往往会导致实际的调度问题。我们不一一详细讲解每个问题,而是挑选了一些典型的例子进行说明。
配置依赖和失败等待策略
一个常见的问题是用户配置了依赖失败等待策略后,发现并没有触发所期望的行为。比如,用户希望当子工作流执行时,如果父工作流没有在规定的依赖时间区间内执行,系统能宽限几分钟。用户会在依赖失败等待中配置 5 分钟或 10 分钟的延迟,但最终发现时间到了依然没有触发。这是为什么?
依赖失败的概念是这样的:只有当父工作流在依赖的时间周期内被执行且执行失败,才算依赖失败。
如果父工作流在该周期内没有被触发,依赖等待时间设置是无效的。即使你设置了10分钟延迟,系统会在延迟后检查原本的依赖区间,看看父工作流是否有实例被调起。
没有实例的情况下,它不会被认为是失败的依赖,这与用户的直观感受不同,因此容易产生误解。
2. 依赖周期与节点卡在运行中
另一个常见的问题是,用户将依赖周期配置为“月”或“小时”后,发现依赖节点一直卡在运行状态。
这通常是因为用户对依赖周期的理解存在偏差。很多用户会误认为“月”是指绝对的30天,而不是从当月的开始到月底。
因此,用户在理解依赖周期时,可能会混淆其实际含义,从而导致依赖节点无法正常工作。
串联多个依赖节点的误区
有些用户尝试将两个依赖节点串联在同一个工作流中,他们通过创建多个 dependent task,并将这些任务串联起来。
这种做法很容易引发未知问题,且是不被推荐的。dependent task 本质上是一个逻辑节点,和复杂的调度逻辑紧密相关。
更推荐的做法是:在一个 dependent task 中,通过逻辑操作符(AND/OR)来配置多个依赖项,而不是通过串联多个 dependent task 来实现。
这种方法不仅可以避免不必要的警告信息,还可以确保系统行为更加稳定。虽然一些相关问题已经陆续修复,但为了避免潜在问题,建议不要使用这种串联方式。
结语
以上是今天分享的全部内容。特别感谢 Apache DolphinScheduler 社区的支持,社区一直以来对贡献者都保持着开放和友好的环境。
我今天穿的这件衣服就是在第一次参加 Apache DolphinScheduler Meetup 社区送的,每次参加 ApacheCon Asia 时我都会穿它。
如果大家有任何问题,欢迎随时交流讨论。
本文由 白鲸开源科技 提供发布支持!


















 105
105






 到【灌水乐园】发言
到【灌水乐园】发言









