




01 问题复现
在DolphinScheduler中有如下一个Shell任务:
current_timestamp() {
date +"%Y-%m-%d %H:%M:%S"
}
TIMESTAMP=$(current_timestamp)
echo $TIMESTAMP
sleep 60在DolphinScheduler将工作流执行策略设置为并行:
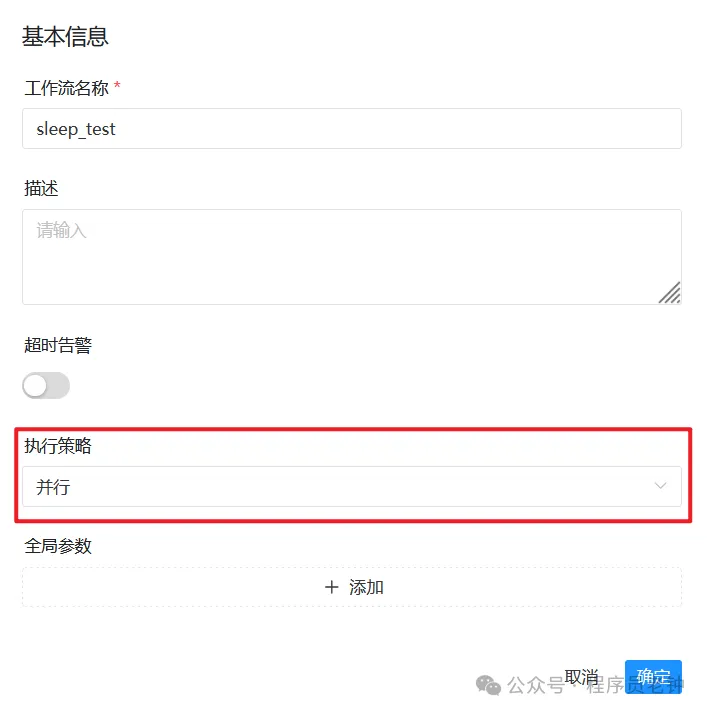
定时周期调度设置为10秒一次:

将定时调度上线后,会调度执行任务,此时一切正常:

此时将Master节点给kill掉,模拟宕机:
$ jps
1979710 AlertServer
1979626 WorkerServer
1979546 MasterServer
1979794 ApiApplicationServer
1980483 Jps
$ kill -9 1979546去到DolphinScheduler中查看,发现Master已经不存在了:

此时观察DolphinScheduler工作流执行,发现其不会继续调度任务执行了,并且所有的任务则会一直执行下去,直到报错。
当过了一段时间后(模拟发现了宕机问题),此时重启DolphinScheduler:
sh bin/stop-all.sh
sh bin/start-all.sh重启完成后,就会将之前没有执行成功的任务,包括没有执行的调度任务,全部都执行一次:

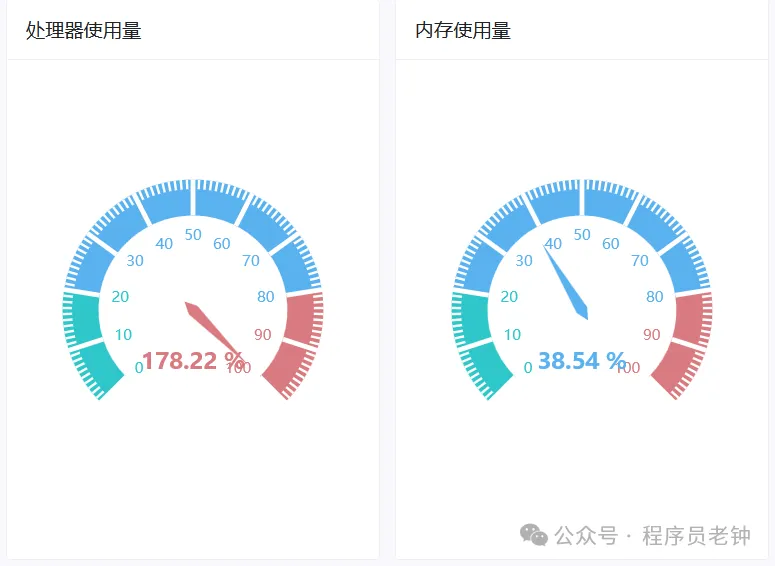
这就有一个致命的问题:如果都是高性能任务的话,就会导致CPU、内存被打满,从而让服务器整个宕机!!!
02 多场景测试
- Master宕机后,重启整个DS:会产生上述问题。
- Master宕机后,重启相应的Master:会产生上述问题。——有缺陷,官方没有单独的Master后台启动,只有前台启动的脚本,但可以重复执行start-all.sh。
- Worker宕机后,重启整个DS:不会产生上述问题。——因为Master会持续的调度任务,而Worker宕机后的结果就是调度任务直接失败。
- Worker宕机后,重启相应的Worker:不会产生上述问题。——有缺陷,官方没有单独的Worker后台启动,只有前台启动的脚本,但可以重复执行start-all.sh。
- DS整个宕机后,重启整个DS:会产生上述问题。
- DS使用stop-all.sh停止后,重启整个DS:会产生上述问题。
其核心就是在于Master,只要配置了周期任务,无论Master是宕机还是调用脚本关闭的,其都会产生上述问题。
03 原理分析
DolphinScheduler核心角色:
- MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。
- WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
- ApiServer主要负责处理前端UI层的请求。
大致的任务运行流程如下:
在API-Server中创建任务,并将元数据持久化到DB中。
通过手动点击或定时执行生成一个触发工作流执行的Command写入DB。
Master消费DB中的Command,开始执行工作流,并将工作流中的任务分发给Worker执行。
当整个工作流执行结束之后,Master结束工作流的执行。

参考官网,上述的DolphinScheduler核心任务执行流程可以细化为如下:

鉴于任务调度的复杂性,一个大的流程可以划分为小的流程,在主线流程之外还附加了支线流程,下面对执行调度流程拆分进行分析一下,这样更容易理解:

在本次问题中,主要关注的就是Command分发流程。其Command分发流程是一个异步分布式生产消费模式。
i. 首先是生产者api-server,会将用户的运行工作流http请求封装成command数据,insert到t_ds_command表中,如下是一个启动工作流实例的command样例(老版本):
{
"commandType": "START_PROCESS",
"processDefinitionCode": 14285512555584,
"executorId": 1,
"commandParam": "{}",
"taskDependType": "TASK_POST",
"failureStrategy": "CONTINUE",
"warningType": "NONE",
"startTime": 1723444881372,
"processInstancePriority": "MEDIUM",
"updateTime": 1723444881372,
"workerGroup": "default",
"tenantCode": "default",
"environmentCode": -1,
"dryRun": 0,
"processInstanceId": 0,
"processDefinitionVersion": 1,
"testFlag": 0
}ii.其次是消费者,master server中的MasterSchedulerBootstrap loop程序, MasterSchedulerBootstrap使用ZK分配到自己的slot,从t_ds_command表中select属于slot的command列表处理,其查询语句是:
<select id="queryCommandPageBySlot" resultType="org.apache.dolphinscheduler.dao.entity.Command">
select *
from t_ds_command
where id % #{masterCount} = #{thisMasterSlot}
order by process_instance_priority, id asc
limit #{limit}
</select>iii.MasterSchedulerBootstrap loop轮训查到待处理的command任务,将command任务和master host生成ProcessInstance,将ProcessInstance对象插入到t_ds_process_instance表中, 同时生成包含运行所需要的上下文信息的可执行任务workflowExecuteRunnable。 将workflowExecuteRunnablecache到本地cache processInstanceExecCacheManager,同时生产将ProcessInstance的WorkflowEventType.START_WORKFLOW生产到workflowEventQueue队列中。
上面的步骤是用户在Web页面点击启动任务后的流程,而本次的问题是Master周期调度的问题。经过查阅资料,周期调度任务则是MasterServer将其封装为命令数据并插入t_ds_process_instance表中,后续步骤如上,大致流程如下:
命令分发:以用户提交的工作流请求为触发,MasterServer将其封装为命令数据并插入数据库中。
任务分配:MasterServer循环查询待处理的命令,依照负载情况将任务分配到对应的ProcessInstance中。
任务执行:根据DAG的依赖关系,WorkerServer会优先执行无依赖的任务,然后根据优先级逐步执行其他任务。
状态反馈:任务执行过程中,WorkerServer会定期回调MasterServer,通知任务的进展和执行状态。
所以,上述的问题就在这,当Master从停止到启动时,t_ds_command中会产生大量的任务数据。
在DolphinScheduler3.2.1中,其t_ds_command数据样例为:
id |command_type|process_definition_code|process_definition_version|process_instance_id|command_par 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















 到【灌水乐园】发言
到【灌水乐园】发言










