




场景
多电池
“用lstm去预测电池老化 怎么使用多块电池的数据去做训练呢 直接串在一起吗。但是这种时序数据 在两块电池连接的地方会有大跳跃呀 就是一个电池寿命快完了 下一个数据又是下一块电池的初始寿命这种情况。”
使用lstm预测电池老化怎么用多块电池的数据作为训练集呢_人工智能-优快云问答![]() https://ask.youkuaiyun.com/questions/7722125用lstm去预测电池老化 怎么使用多块电池的数据去做训练呢? - 知乎 (zhihu.com)
https://ask.youkuaiyun.com/questions/7722125用lstm去预测电池老化 怎么使用多块电池的数据去做训练呢? - 知乎 (zhihu.com)![]() https://www.zhihu.com/question/533505254
https://www.zhihu.com/question/533505254
回答一
每个电池为1个样本,或是以将若干个输入的电池同一初始点为起始样本,同步进行所有电池寿命的后移
回答二
- 如果认为不同电池是符合同一内在老化规律的,不同电池的老化曲线差异来自于随机噪声,想利用模型拟合这种型号电池的内在老化规律,可以建立一个预测模型,将不同电池的数据混合在一起做训练集,混合方法不是在时序上串联不同电池的数据,而是从每块电池内部按一定策略裁剪出多段context_length+prediction_length长度的子序列后在batch维度拼接并送给LSTM模型训练,这样可以对训练集外的新电池做预测
- 如果认为不同电池间存在一些相似老化规律,但又存在一些内在差异,想让模型同时学到这种相似规律和个体差异,可以在上一条中的特征基础上拼接上标识个体差异的特征作为新特征后用类似上一条的方式建模,比如拼接上电池ID/电池型号ID的one hot编码(通常会在one hot编码后加上embedding层)特征,具体实现可以参考Gluon TS文档。
one-hot 编码用于将离散的分类标签转换为二进制向量。
- 离散的分类:
假设我们要做一个分类任务,总共有3个类别,分别是猫、狗、人。
那这三个类别就是一种离散的分类:它们之间互相独立,不存在谁比谁大、谁比谁先、谁比谁后的关系。
- 二进制向量:里面的数字都是二进制的一维数组,比如[0, 1, 0, 0]。
分类标签一个重要的作用,就是要计算预测标签与真实标签之间的相似性,从而计算 loss 值。loss值越小,说明预测标签与真实标签之间越接近。相似性其实就是两个标签之间的距离。
错误标签示例:猫和狗之间距离为 1, 狗和人之间距离为 1, 而猫和人之间距离为 2。
猫:0
狗:1
人:2
这在参与损失计算的时候是完全不能接受的:互相独立的标签之间,竟然出现了不对等的情况。因此,需要用到one-hot(独热编码),将互相独立的标签表示为互相独立的数字,并且数字之间的距离也相等:
竖着看,如果一个标签是猫,那么猫对应的位置就是1,狗和人对应的位置就是0,得到一个编码[1, 0, 0]。
正确标签示例:之间距离相等,解决了上面说的独立的标签之间,表示方法不对等的情况。
猫:[1, 0, 0](黄色)
狗:[0, 1, 0](浅绿色)
人:[0, 0, 1](粉色)
多轨迹
方法
使用LSTM模型或者其他支持处理序列数据的模型
多组数据训练时间序列预测模型? - 知乎 (zhihu.com)![]() https://www.zhihu.com/question/636768935
https://www.zhihu.com/question/636768935

步骤一:数据标准化
标准化需要对70组的每组数据分开进行标准化处理。因为每组数据都是独立的,我们希望标准化之后的每组数据还是独立的,不要互相污染。
一个例子就是,在模型训练的阶段,我们只会针对训练集做标准化,然后用训练集的标准化scaler放在测试集上用来测试模型性能。我们不会对整个(训练集+测试集)进行标准化,因为我们希望训练的时候不要有任何测试集的信息被容纳。
那么在这里分开标准化的原因也是类似的,我们希望每组数据的信息在标准化后还是他本身,不包括他过去和未来数据的信息。

步骤二:数据重塑,创建你的训练集数据
从时间序列数据中创建输入和输出数据,我们需要将时间序列转换为多个样本,其中每个样本具有固定的时间步长作为输入和一个或多个输出时间步长。我们可以使用Sliding Window来实现这个操作。
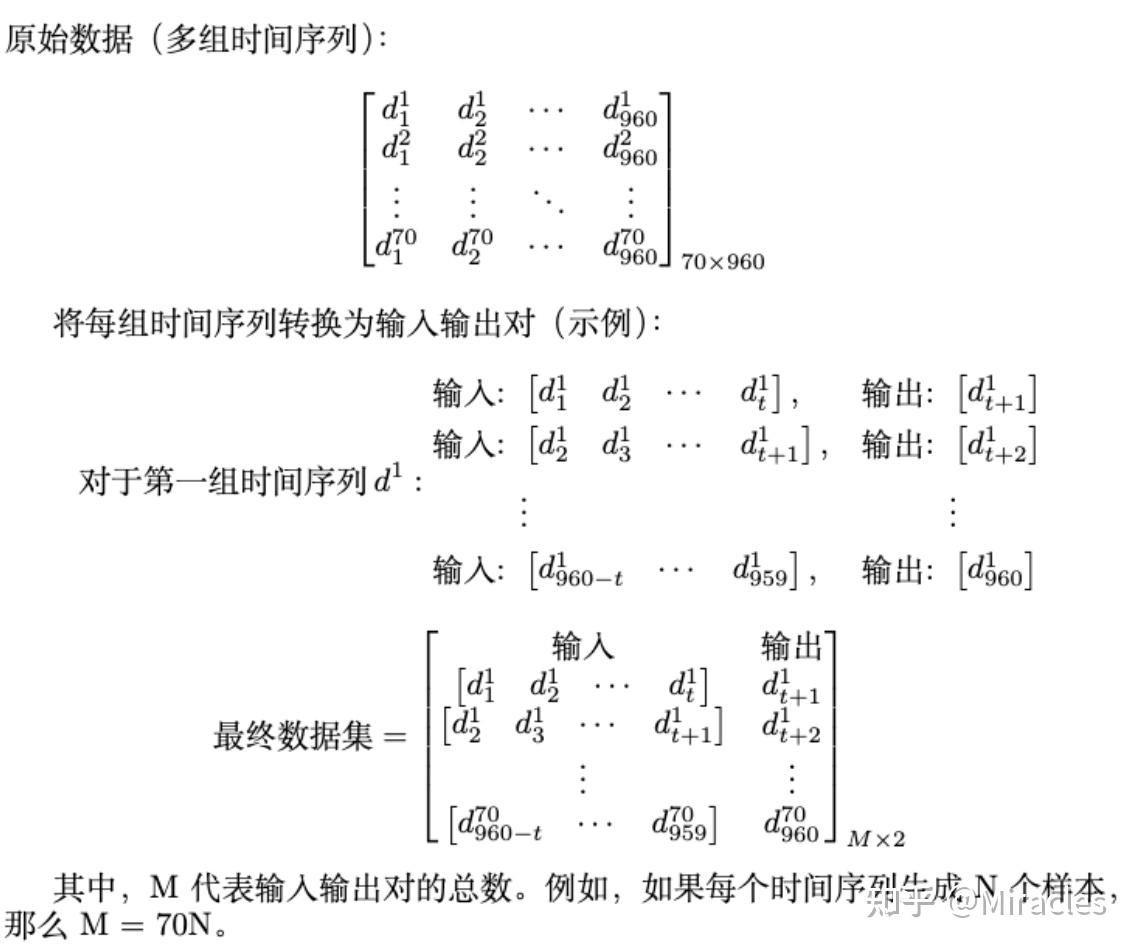
1.与文中的70*960的样本相对的,如果时间序列样本之间长度不相等要怎么考虑呢?
答:在类似RNN的神经网络里,时间序列样本长度不相等的时候,我们一般用padding把输入样本变成同一形状。例如你可以用0-padding,假如你的样本不一样长,最长的样本是1x1000的形状,你可以选择最长的那个样本的长度1000,将所有的样本的末尾填充0,直到每个样本都是1000的长度。当然还有很多padding的方法,就不一一赘述了,你可以都尝试一下,选择最适合你的。
2.如果一组时间序列样本是二维的,即每个时间下存在多个特征。此时有多组这样的特征,请问应该怎么执行标准化,是对每个样本标准化还是对每个特征标准化。
答:对于标准化的话,我们的原则就是在不影响数据集本身的信息(information)的情况下使数据的区间变成相同的0到1。如果特征在不同样本间有直接的可比性,通常对每个特征标准化会更好。
并且也补充一下,如果你的数据集够大,其实你可以先试试不标准化也没事,LSTM类似的神经网络如果数据够多理论上也是可以学习到没有标准化的数据结构的。
3.将多组样本(样本间没有时间先后关系)的所有时间步首尾相接后喂入batch size中,是否对batch size大小有要求;模型input的形状是(顺序号,步长,特征),是否需要在顺序号的维度里进行shuffle打乱顺序?
答:batch size习惯是在(32,64,128...)区间里超参数调优选一个。关于顺序号,既然你的样本间没有先后关系,那么shuffle的确没有坏处,还可以提升模型generalization的能力,可以打乱顺序。
标签差异的数据集
作者解读ICML接收论文:如何使用不止一个数据集训练神经网络模型? (qq.com)![]() https://mp.weixin.qq.com/s/aZmuSy3r_9KuhDN4-PIKbQ
https://mp.weixin.qq.com/s/aZmuSy3r_9KuhDN4-PIKbQ
传统的两类处理工作:
- 直接融合:直接在标签空间进行,这要求标签的一致性,这通常可以通过伪标签的方式进行;
- 间接融合:它可以抽象为通过共享的隐藏向量空间进行数据集融合,相应的算法框架涉及迁移学习、领域自适应等。
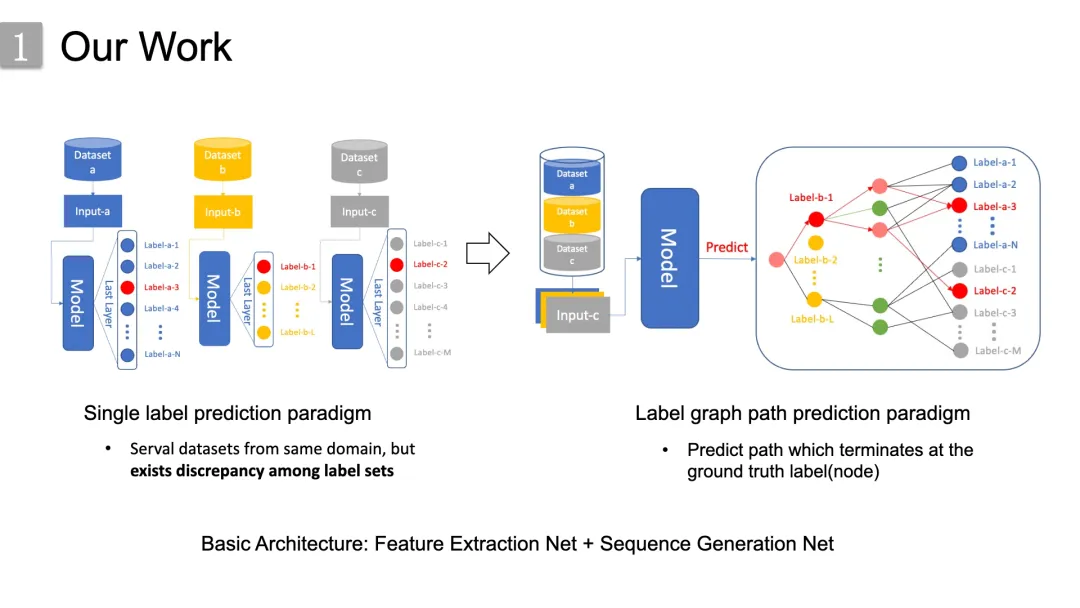
而作者的思路是从数据集的语义信息角度出发, 由于具有相似目的的数据集其标签在领域知识是具有的语义关联,所以作者就通过构造一个统一的知识驱动的标签图来在标签空间中直接进行数据集融合。在通过标签集之间的语义关系建立标签图之后,多个数据集成功地连接起来,被组合成一个单一的数据集。

















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









