



Datawhale干货
作者:筱可,Datawhale成员
节前最后一天,智谱家也来卷了。
下午三点,智谱发布了新旗舰模型 GLM-4.6。
根据官方的发布推文,这次的 GLM-4.6 的更新主要体现在以下四点:
国内已知的最好的Coding模型:在基准测试中,GLM-4.6 在涵盖数学、编程、逻辑推理的 8 大权威基准中,综合表现稳居国产模型首位;在真实任务中,研发团队在 Claude Code 环境下设置了 74 个真实编程任务进行实测,GLM-4.6 的实际表现超过了 Claude Sonnet 4。
智能体能力升级:上下文窗口从 128K → 200K,显著增强对长代码文件和复杂智能体任务的处理能力;同时,GLM-4.6 增强了搜索智能体和工具调用功能,在智能体框架中表现更出色。
推理效率提升,成本下降:除了性能提升,GLM-4.6 在资源利用上也有优化。在完成相同任务时,其平均消耗的 Token 数量比前代 GLM-4.5 减少了 30% 以上,这被认为是目前同类模型中最低的,意味着用户的使用成本有望降低。
首创国产芯片高效部署方案:GLM-4.6 实现了与国产芯片的深度适配。在寒武纪芯片上,首次实现了 FP8+Int4 混合量化的投产部署方案,在几乎不损失精度的前提下,大幅降低了推理成本。同时,基于 vLLM 推理框架,也能在摩尔线程新一代 GPU 上基于原生 FP8 精度稳定运行。
模型已经上线智谱 MaaS 平台,并在 Hugging Face 和 ModelScope 开源。
开源地址:https://huggingface.co/zai-org/GLM-4.6-FP8
Datawale 第一时间实测了一波。
当然,普通的测试意义不大,这也并不是大家想要的真正的测评。所以,我们不会选择一些自由度非常高的题目,比如写一个小游戏,或者可视化一个简单的东西或者概念,因为这些不是我们开发者所刚需的内容。
真正刚需的是指挥模型去帮助自己编辑代码,并实现一个功能的能力,这才是我们真实所需要的。
下面来看详细测评。
基础能力表现实测
任务:ToDo List高级版
这是一道关于前端开发的题。
这道题主要是想要自定义一个属于自己的专属 TODO List,相信学过前端的小伙伴大多都接触过一个入门的前端开发任务吧,也就是实现一个 TODO List。不过大多时候只是实现一个简单的 TODO List,比如简单的添加,删除,勾选,仅此而已。
我们这里想要实现的 TODO List 是想要实现一个能够达到入门级的产品级 TODO List,测试 GLM-4.6 从需求描述到可交付产品的端到端能力,所以我需要让这个 TODO List 支持以下的一些功能:
支持两种任务展示方式,比如列表和四象限展示的方式,其中四象限需要有分成“重要且紧急”、“重要但不紧急”、“紧急但不重要”、“不重要不紧急”四个部分,为什么这样分也是有一些道理的,在一本时间管理的书里面提到过这个概念,感兴趣的可以搜一下。
TODO List 需要支持子任务支持,且任务需要支持添加开始时间,结束时间,进度显示。
展示的时候还需要支持使用时间进行一定的过滤功能支持。
最后还需要支持多种的排序方式,比如按照截止时间、开始时间、结束时间分别进行排序。
先说结论
在本次的 ToDo List 任务上的表现,能明显可以看出智谱的 GLM-4.6 表现的非常好,在满分 5 分的情况下已经可以拿到非常接近满分的 4.8 分了,表现已经非常棒了,和 Claude Sonnet 4 不相上下。
对比其他的国内模型来说有很明显的差距,比如 KiMi K2 没有完成一个可以有效进行交互的前端界面,Deepseek-V3.2-Exp 的展示表现差一些,功能完成度上还是能和 GLM-4.6 打一打的。
与国外的模型对比也不落下风,比如 Gemini 2.5 Pro 完成的 TODO List 就没法创建任务,gpt-5-codex 创建的 TODO List 排版古怪。所以可以说是 Coding 能力创国产模型新高啦,放到国外对比也十分能打。
下面是使用的提示词:
请你扮演一位经验丰富的前端开发专家,擅长使用原生 JavaScript 构建复杂的单页面应用。我需要你帮我构建一个功能完善的、单页面的任务管理网页应用 (Advanced To-Do List)。这个应用的核心是任务的层级管理和时间约束。请严格按照以下功能需求来实现:
核心功能模块
1. 任务与子任务系统任务 (Task):用户可以创建主任务。每个任务包含:标题详细描述内容(一个可以输入多行文本的区域)开始时间截止时间子任务 (Sub-task):每个主任务下面可以添加零个或多个子任务。子任务只有标题,没有详细描述。子任务也有自己的开始和截止时间。核心约束:创建或编辑子任务时,其选择的时间范围必须在其父任务的起止时间之内。例如,父任务是 9:00-12:00,子任务只能在这个区间内设置时间,如 9:30-10:00。2. 动态信息展示任务卡片需要显示:当前任务下有多少个子任务(例如 3个子任务)。子任务的完成进度(例如 进度: 2/3),并最好有一个可视化的进度条。距离该任务截止时间的倒计时(例如 剩余: 2天5小时)。子任务需要显示:距离该子任务截止时间的倒计时。3. 两种视图布局应用需要提供切换按钮,支持以下两种布局模式:列表视图 (List View):最标准的上下排列方式,清晰地展示所有任务及其子任务。四象限视图 (Four-Quadrant View):将任务区域划分为四个象限,分别是“重要且紧急”、“重要但不紧急”、“紧急但不重要”、“不重要不紧急”。用户应该可以将任务拖拽或分配到不同的象限中。4. 排序与过滤功能排序 (Sorting):提供下拉菜单或按钮,支持对主任务列表进行排序。按截止时间(从早到晚)。按创建时间(从新到旧)。按剩余时间(从少到多)。过滤 (Filtering):提供一个日期范围选择器,用户选择一个时间段后,只显示与该时间段有交集的任务(即任务的开始或结束时间落在该范围内)。
技术与设计要求
交付物:请将所有的 HTML, CSS 和 JavaScript 代码全部内联在一个 index.html 文件中。技术栈:请使用原生 JavaScript (Vanilla JS) 实现所有功能,不要使用任何外部库(如 jQuery, React 等)。数据持久化:使用浏览器的 localStorage 来保存用户的任务数据,这样刷新页面后内容不会丢失。界面设计:界面要求简洁、直观、响应式。操作逻辑要清晰,例如添加按钮、切换视图的按钮、排序和过滤控件等要放置在合理的位置。
请确保代码结构清晰、注释充足,并直接生成完整的代码。智谱 GLM-4.6 非全栈模式:4.8分
输出结果来看,稍微比全栈模式输出的样式排版差一些,但从具体的交互结果来看,输出结果是非常完整,大部分是能够按照我们预期的内容结果生成的。
比如我们要求的任务列表,任务象限,开始时间、截止时间设置,进度条支持,子任务设置,子任务时间设置范围限制在任务范围内,删除按钮和编辑按钮的大小也都还合适,过滤功能,排序功能也都支持的很好。
总体来说也算相当不错了,稍微扣点第一印象分,满分 5 分,可以给 4.8 分。
智谱 GLM-4.6 全栈模式:2.5分
从输出的结果来看,第一眼看上去挺惊艳的,不过经过实际测试发现还是有不少的问题的。
比如我要求是每个任务是有子任务可以继续配置的,方便进行进度条显示。他很明显没有完成要求,子任务直接就被遗忘了。
还有一个问题是他点击创建任务的时候没有立即提供给我一个反馈,导致我重复点击了多次按钮,从而造成了重复添加了多个任务,而且他还没有配置很明显的删除按钮给我,我是很后面才发现这个删除按钮的,也就是说明他的按钮大小设计的也是有待改进。
当然,这次任务做的好的一面是排版做的非常棒,视觉观感非常像是一个产品,新建任务,以及四象限等等都能够完成,而且样式都比较符合我的前端审美。
满分 5 分,我只能给 2.5 分吧,因为没有一次性完成我的预期完整要求,而且还有很多的交互问题存在,虽然界面样式不错,但是功能完整性差太多了,即使第一印象很好我也没法给他打高分。
这时候,有的人可能会对智谱的全栈模式和非全栈模式做出来的效果得分觉得奇怪,毕竟全栈模式似乎应该会更强呀,为啥得分要低于非全栈模式?
这里可以从前后端构建对比纯前端构建的难度来思考。
因为全栈模式的意思是前后端同时构建,而非全栈模式构建的仅仅就是一个前端而已了。
那么我们可以想到全栈模式的条件下,他需要进行任务分配,也就导致对记忆的依赖更重一些,而且还需要协同修改前后端的内容,而在这个过程中所需要的规划,管理的能力就非常重要,在全栈模式的条件下虽然没能完整实现任务,但是在样式的排版,选择方面做的是非常好的。
KiMi K2:1 分
上面是 KiMi-K2 的输出结果,很明显虽然输出了任务管理系统的页面,但是整个页面能够进行交互的元素是极其少的,只有时间过滤的设置部分是可以进行调整的,新建任务,视图切换,时间排序都是无法使用的。
总体来看也是完全不可用的状态,满分5分只能给 1 分吧。
Deepseek-V3.2-exp:3分
上面的结果来自Deepseek 昨晚发布的最新模型,整体来看各个环节实现的都还是不错的,我们的任务,子任务设置,排序,过滤,列表和四象限展示方式,都做的还行,基本需要实现的要求都能够实现,不过有一个很奇怪的点是子任务居然是使用 prompt 实现,显得很怪异,还有就是排版也稍微有一点怪添加任务的部分占据空间太多,导致刚开始不能看到任务内容,或者四象限的任务列表展示不全,所以扣分了,不过整体的样式看起来其实是很不错的。所以满分 5 分就给 3 分了。
Gemini 2.5 Pro:1.5分
上面的结果来自我最喜欢的 Gemini 2.5 Pro模型,很遗憾,居然没有完整实现一个TODO List,看起来,我们的任务确实是有点难度的,连 Gemini 2.5 Pro 都没能完成这个任务。不过也完成了一些内容,比如排版看起来还是不错的,排序,过滤,列表和四象限两种展示方式也能实现,有两个问题是第一个是他居然没法创建任务,第二个是四象限排版居然是横向的排版而不是两两作为一排,直接扣大分。满分5分只能给 1.5 分了,主要是看着似乎完成的还挺好的样子。
GPT-5-Codex:2.5分
上面的结果来自GPT5,整体的任务完成度是很高的,但是排版布局做的太差了,创建任务,子任务,任务进度,任务排序,过滤,列表、四象限两种展示方式也能实现,主要是排版实在是太奇怪了,样式其实颜色还行,所以只能满分 5 分条件下给 2.5 分了。
Claude Sonnet 4:4.8分
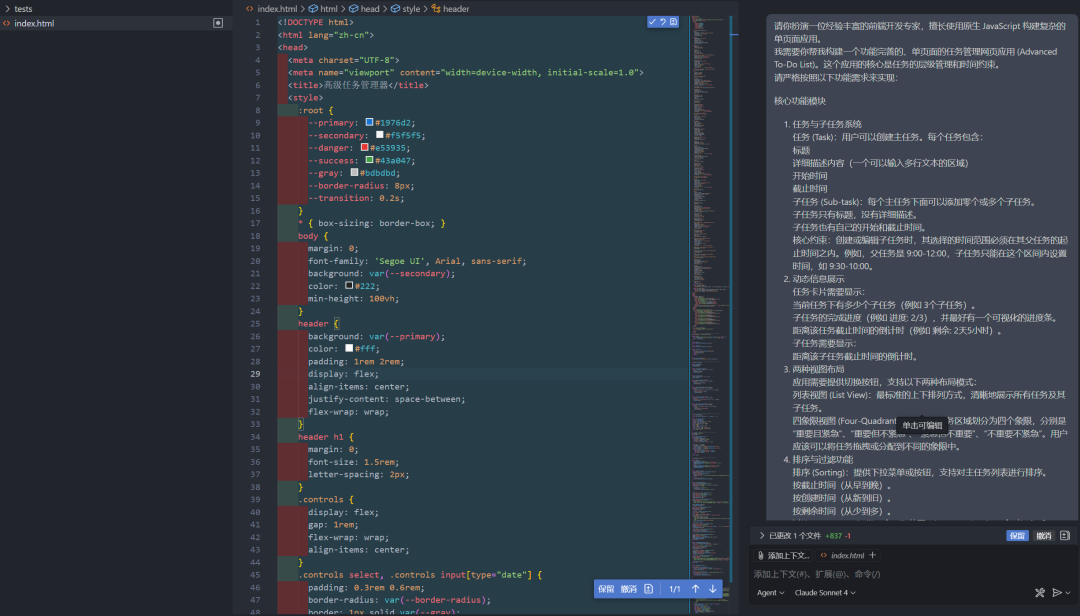
上面的结果来自 Claude sonnet 4,从结果来看,我觉得是非常赞的,无论从第一印象来看还是实际效果来看,我觉得基本上能达到我预期的效果,而且样式排版都非常不错,交互的逻辑也是感觉做的比较优秀的,从布局来看主要的控制按钮放到上方,部分按钮放到任务本身上面,而且时间显示做的也很棒,单纯从直观的使用方面,以及观看体验都是非常赞的,字体的设置大小也比较适合,功能基本都完全按照我们之前设置的内容完成。满分 5 分的情况下,我觉得能非常接近 5 分了,和 GLM-4.6 不相上下。
Agentic Coding表现实测
接入 Claude Code 保姆教程
之前我们就开源了 Claude Code 环境接入外部模型的保姆级脚本:每月仅需20元,无限量使用编程神器Claude Code教程!。
其他步骤都保持一致,只有在第 3 步选择模型处,选择自定义(手动输入模型),然后输入 “glm-4.6” 就可以使用了(注意全小写)。
到这里,我们就配置好了 Claude Code 上的 GLM-4.6 模型。
给想要接入的伙伴们画个重点。智谱的 GLM Coding Plan 也全面升级了:可以用 1/7 的价格,获得 Claude Code 3 倍的用量,90% 的智商。
GLM Coding Plan获取地址:bigmodel.cn
下面我们就正式开始测试。
任务:支持公式的微信公众号编辑器
这道题主要是为了测试模型是否能实现其中的一个公式复制到微信公众号编辑器上面,并能保持原来的样式,一般来说,为了能够让自己的微信公众号的文章排版能够更好看,会使用一些专门的编辑器进行专门的排版,并转换成 html 的内容结构,再嵌入一些内敛的样式,从而实现一个更好的阅读观感,有的人为了文章能够变得更酷炫也会加入 svg 到文章里面,其中很多的公众号编辑器就是通过 svg 实现的微信公众号公式渲染,也有部分是基于图片的方式实现渲染,我们这里的任务就是想要让模型使用基于 svg 的方式实现公式在微信公众号上面进行渲染。
这道题的具体难点就在于如何处理公式的 svg 化,并将这部分 svg 的内容在复制到微信公众号上的时候能保持公式的样式。
为了更直观的对比,我们是先测试了一下在官网上的模型表现,接着才使用claude code 接入GLM-4.6进行本地的开发体验。
本次题目使用的测试提示词:
请您以一个网页开发者的身份,帮我构建一个微信公众号编辑器。这个编辑器需要满足以下功能: 1. 主要输入区域支持 **Markdown 语法**,用户可以在这里编辑内容。 2. 编辑器需要实时渲染 Markdown 内容,并生成最终的预览样式。 3. 渲染后的内容能够直接**复制**到微信公众号的后台编辑器中,并且**样式保持不变**。 4. 必须支持 **LaTeX 公式**的渲染,无论是行内公式还是块级公式,都应该正确显示。例如,行内公式为 $E=mc^2$ ,块级公式为: $$ \frac{d}{dx} \int_{a}^{x} f(t) dt = f(x) $$ 5. 编辑器除了支持 Markdown 以外,还需要能够处理**富文本内容**,比如改变字体颜色、大小,添加下划线等。 6. 最终的网页设计要简洁,用户界面友好,方便操作。 在开发过程中,请注意微信公众号平台对 HTML 和 CSS 的兼容性要求,确保渲染出的样式能够被微信编辑器正确解析和显示。GLM-4.6全栈模式:3分
下面是智谱 GLM-4.6 的全栈开发实现的微信公众号编辑器。

整体的排版是非常好看的,也很符合我的前端品味,不过有一个问题,就是他的公式复制到公众号编辑器上面是失败的。但是其他的部分内容渲染做的还是不错的,比如标题和公式渲染做的都还不错。
所以复制的内容是没法在微信公众号上面用的状态。满分5分就给3分吧。本来是想给2.5分的,多出来的 0.5 是因为写的界面挺好看的,确实不错了。因为这个排版后面可以省去调整的时间,而复制按钮优化下就能解决这里的问题。
GLM-4.6 非全栈模式:2分
下面是智谱 GLM-4.6 非全栈开发模式实现的微信公众号编辑器。
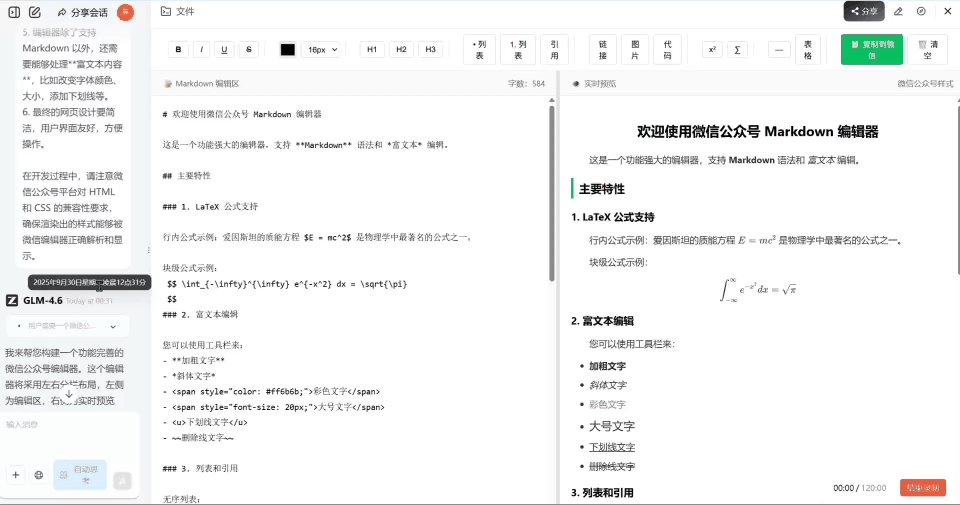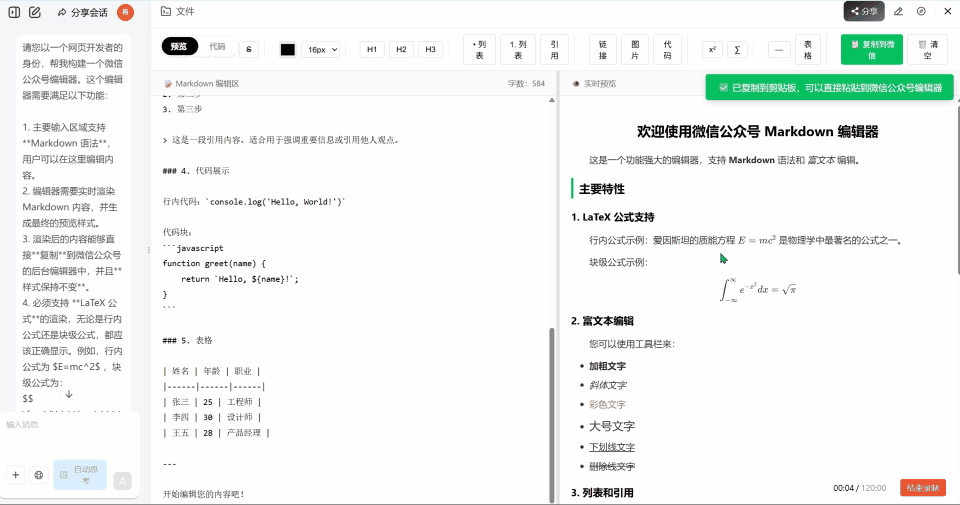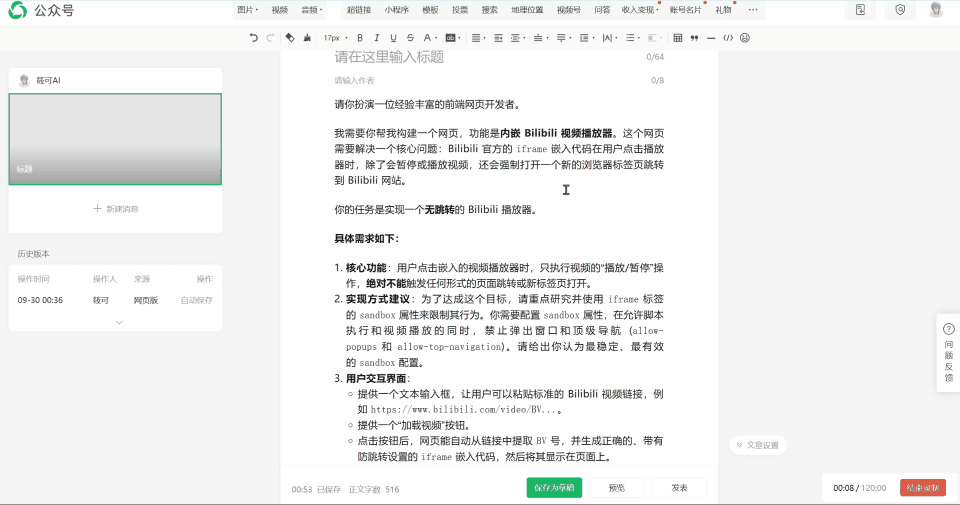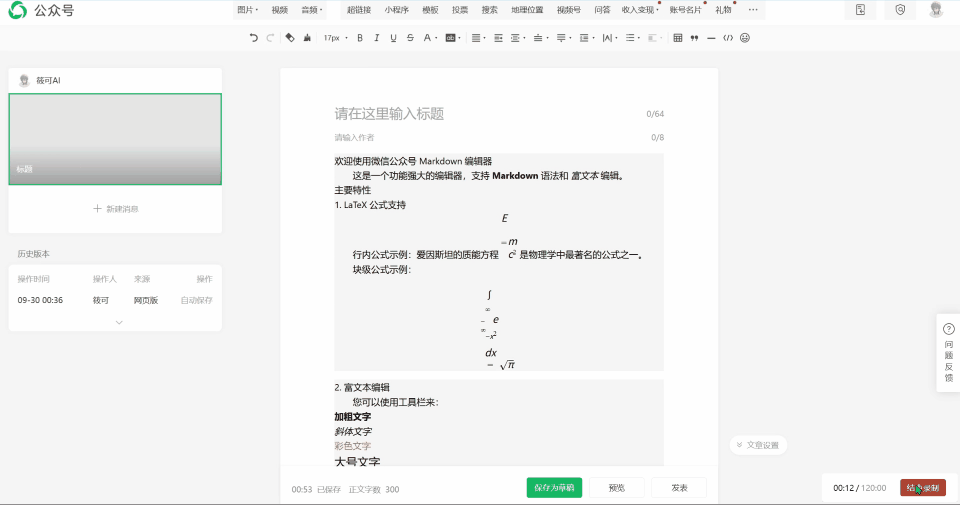
这里也同样实现了一个界面看起来还不错的前端,虽然比全栈模式做出来的界面稍微差了一点,不过有一个优势,就是他实现了公式复制到微信公众号的编辑器上面。
虽然能支持复制到微信公众号编辑器上面,但是公式渲染有些问题,而且标题的渲染也是失败的,很明显的,连标题都不能渲染。满分 5 分我只能给 2 分。
Claude Sonnet 4:2分
使用同样的提示词给到 Claude Sonnet 4,下面是输出的结果。
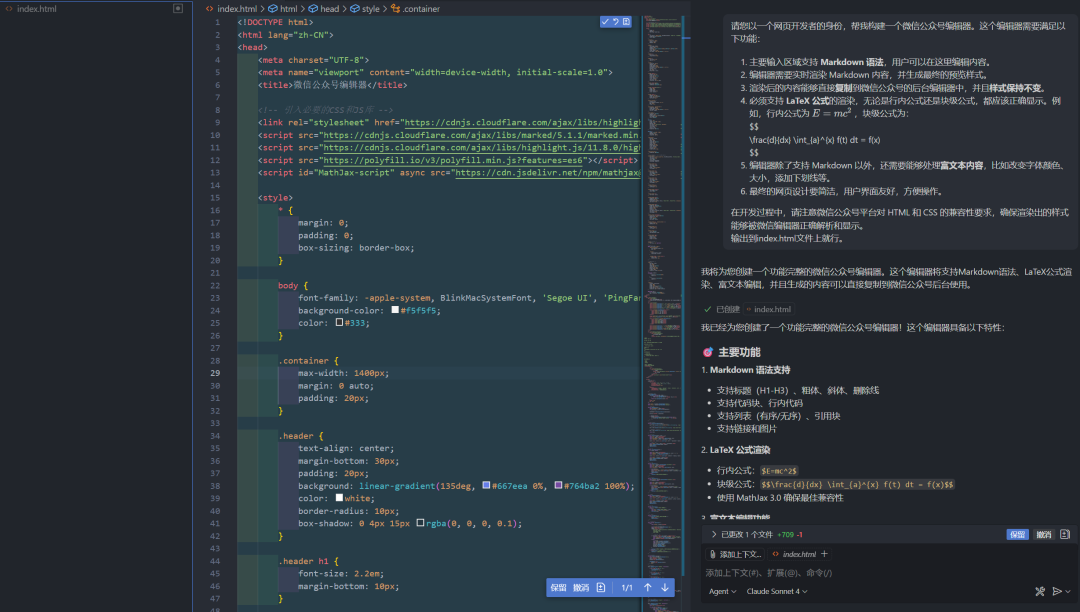
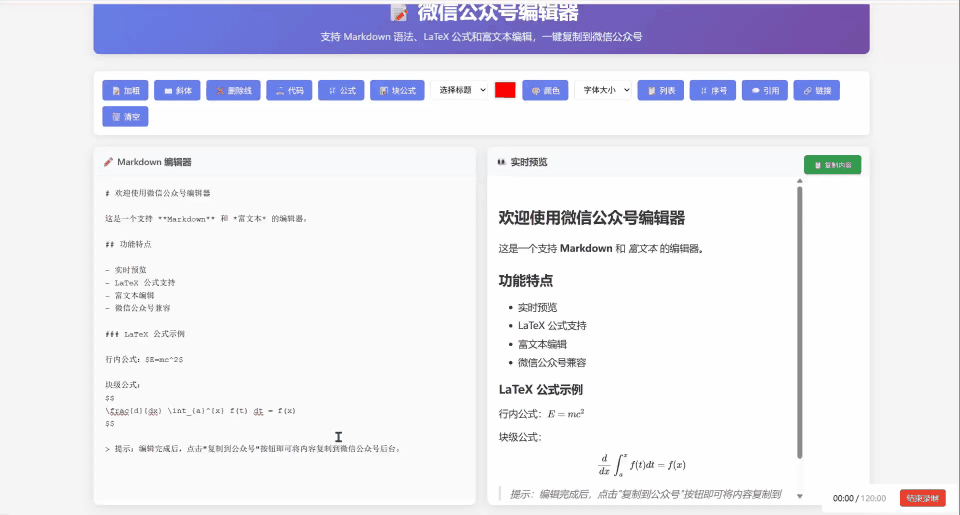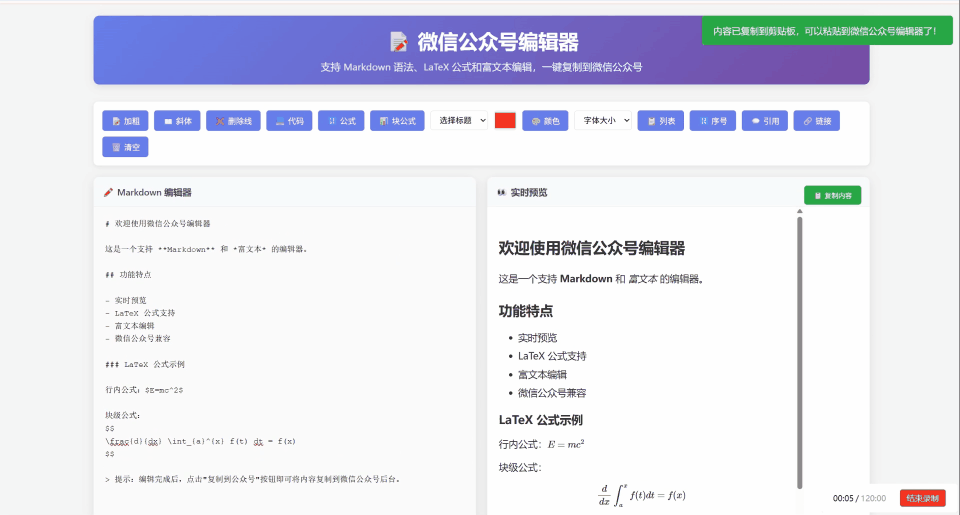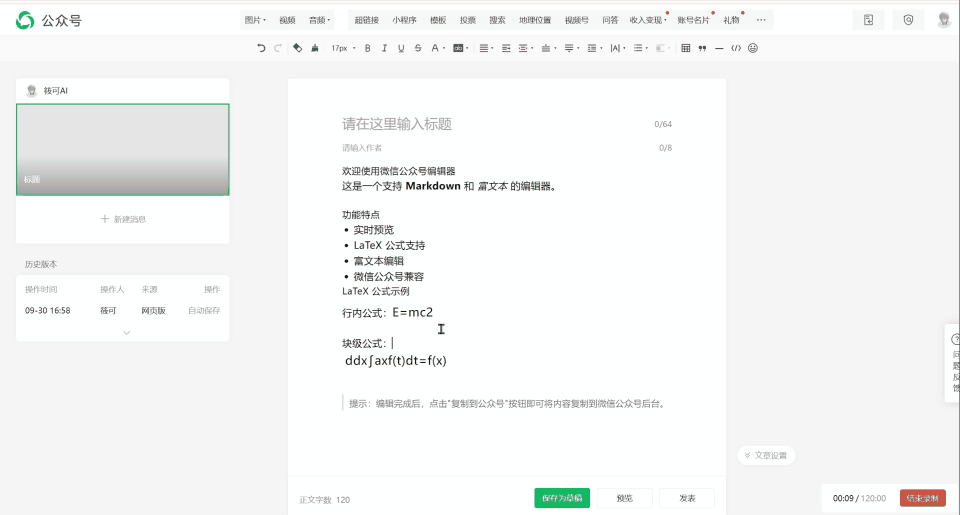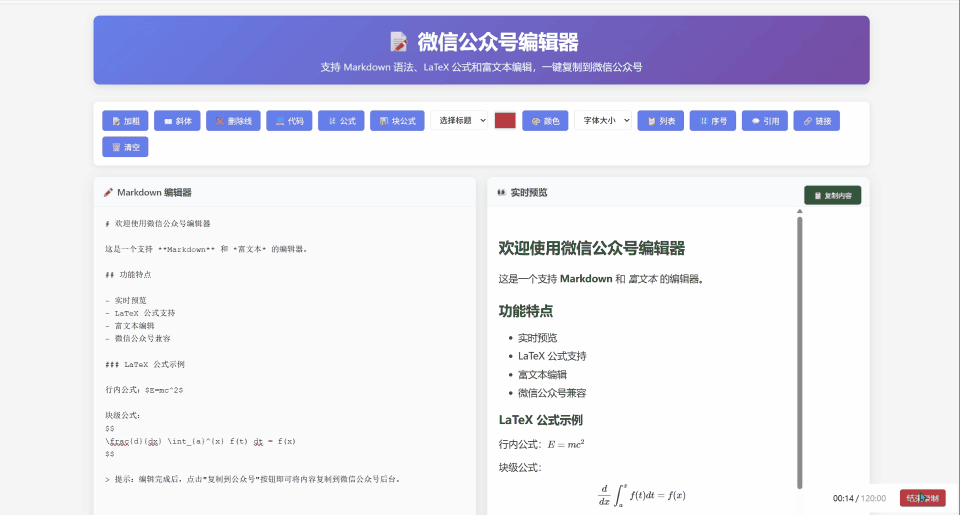
单纯从这里的页面来看其实还是看着不错的,标题还有公式的渲染做的都挺全,但是复制到微信公众号上的编辑器,公式也是一样无法正常显示,所以我觉得大概也只能在满分 5 分的条件下是 2 分。主要是看使用的编辑页面上能渲染,然后也能提供一些编辑的功能。
KiMi K2:2分
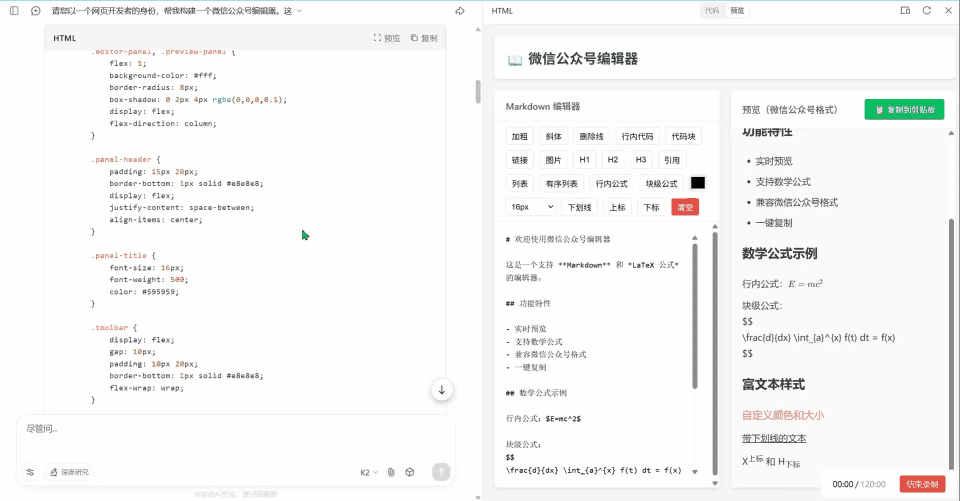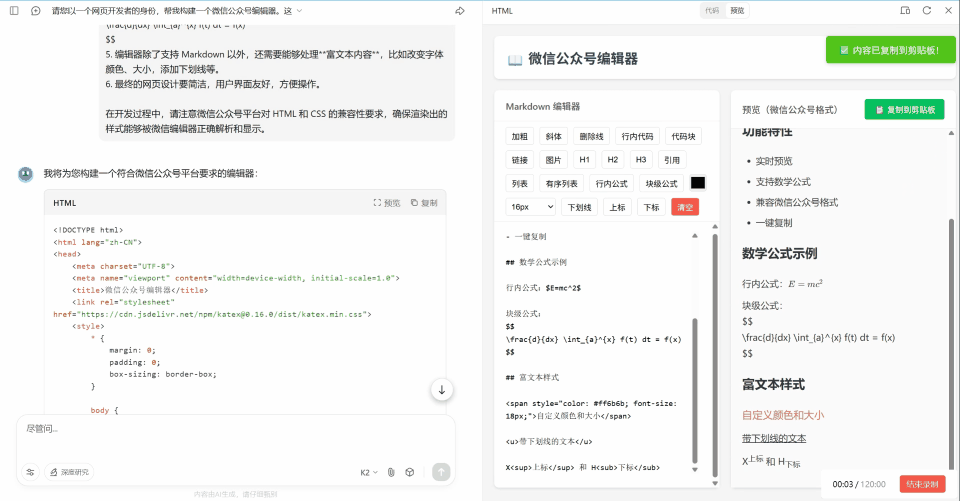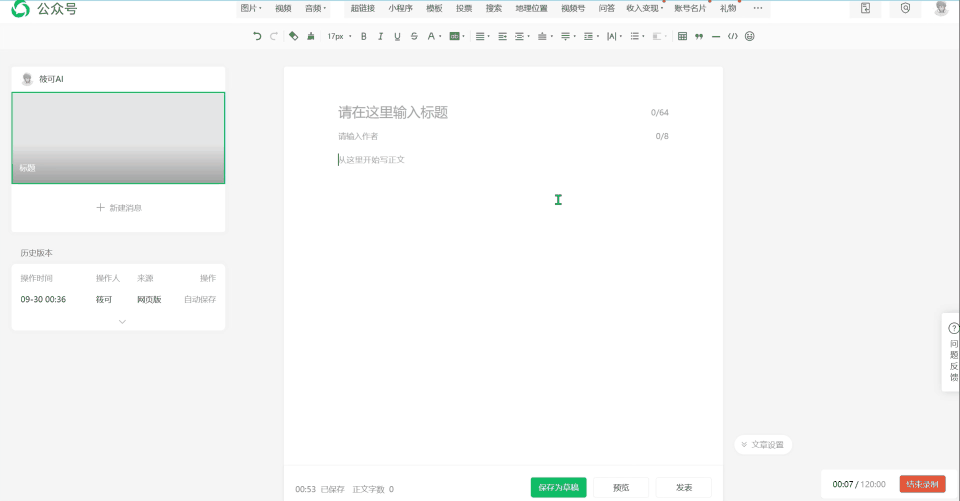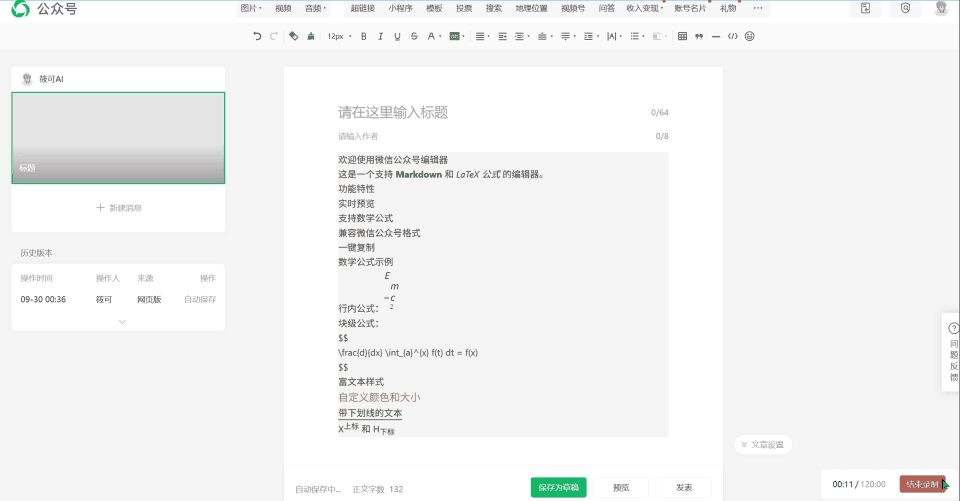
界面看起来还行,虽然没有 GLM-4.6 全栈模式构建出来的好看,但是至少一眼看过来还是可以的,至少结构清晰,编辑、预览一个不漏,完成的算是目前来说还凑合。公式也能渲染到微信公众号上面,不过标题样式没法复制到微信公众号编辑器上,公式也是存在部分的问题。也是不可用的状态。满分 5 分,就给个 2 分吧。
Deepseek-V3.2-Exp:1分
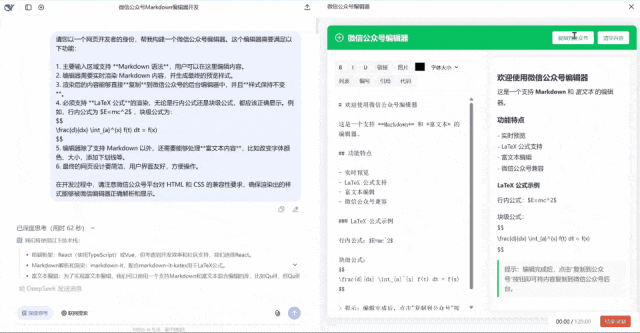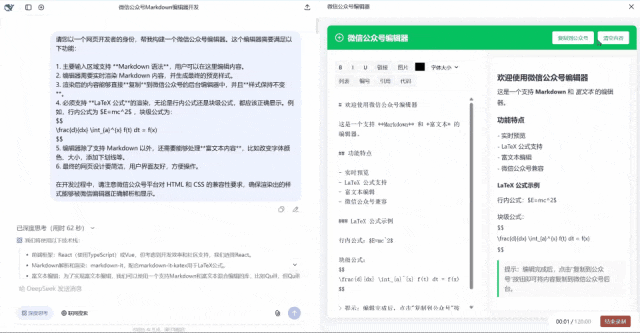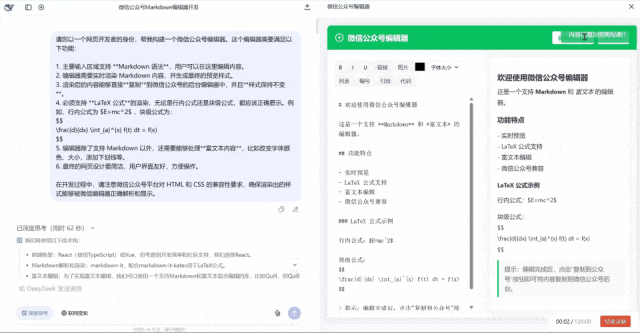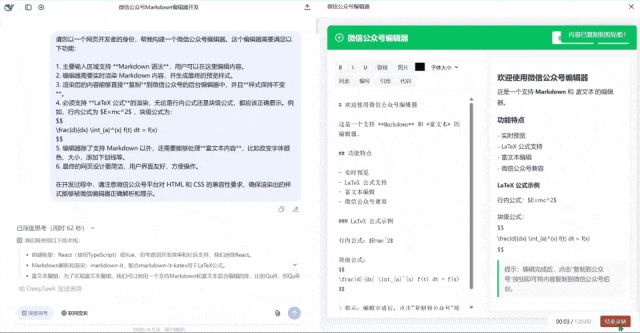
第一眼看过去似乎界面还行,但是我点击复制的时候他没有反应,点击清空内容的时候也没有反应。完全不能用的状态。满分5分,只能给1分,毕竟页面也做出来了。
Claude Code环境下,GLM-4.6 对比 GLM-4.5
因为支持公式渲染的微信公众号 markdown 编辑器这道题本身是有一些难度的,所以我重新放到了 Claude Code 里面对我们的 GLM-4.6 进行了 Agentic Coding 实战测试,同时也是为了测试下对比 GLM-4.6 和上次测试的 GLM-4.5 在 Claude Code 上的编程体验如何。
测试花费了 20 多块的巨款,希望大家看得开心(doge)。
下面的图就是我使用基于 GLM4.6 的 Claude Code 实现的公众号编辑器。整体总共消耗 1 小时左右,过程中基于人类(我的)反馈,从而实现对部分内容进行修复。
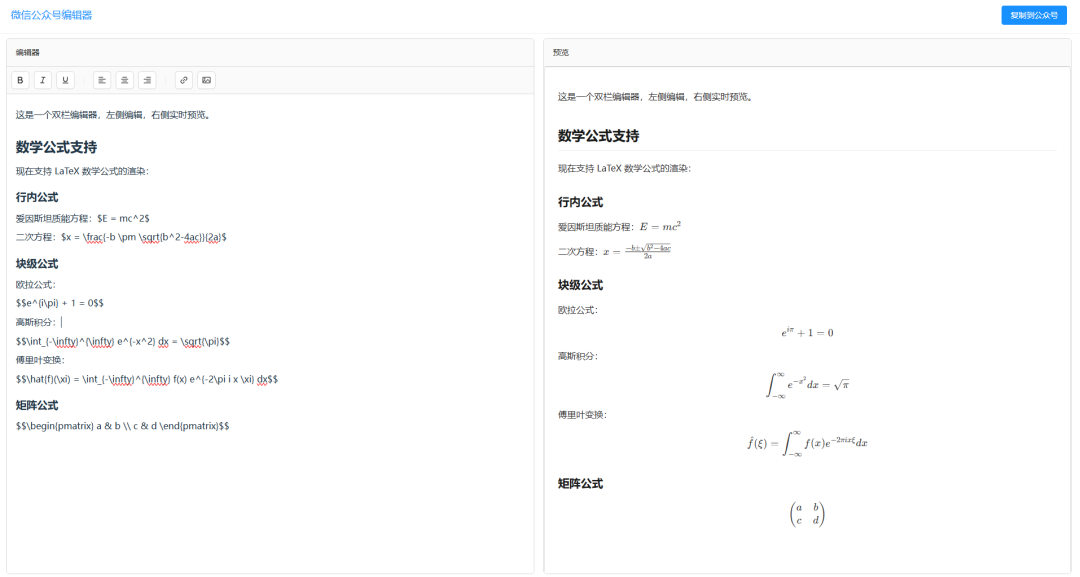
实现的内容还是上面的任务:基于 markdown-it 及其公式插件实现公式的渲染,从而实现一个能够支持渲染公式的 markdown 微信公众号编辑器。总体上来看,比较清爽实用,在我给出一个解决方案学习后,也成功实现了复制到公众号中,而且还能携带背景复制到微信公众号上面,甚至是代码块的颜色也可以。
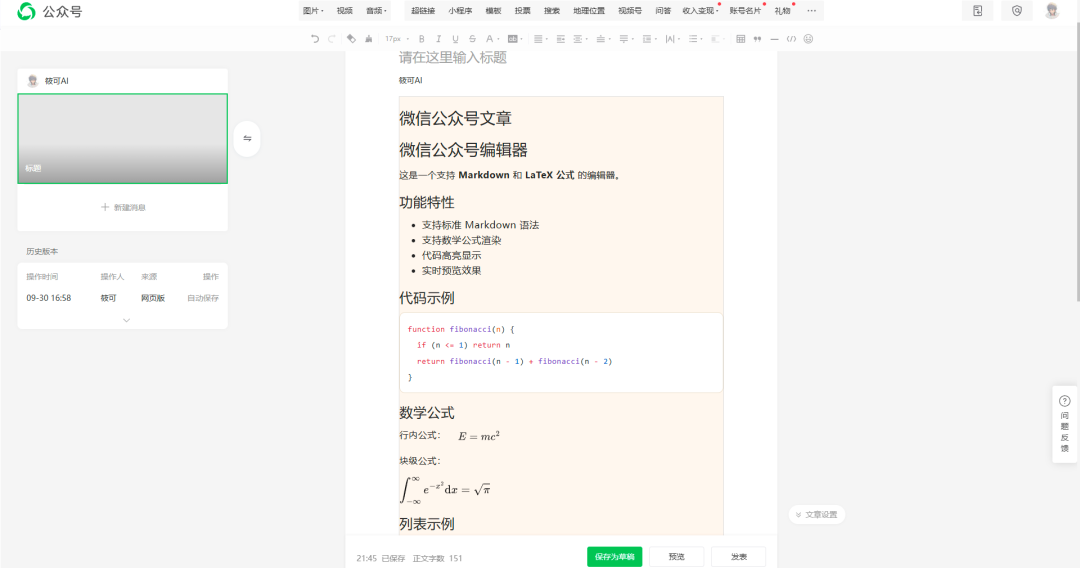
下面是我的使用流程,对整个视频进行了加速处理。
第一次我想要让他直接使用 nextjs 一把实现,但是没有成功,
之后重新使用我熟悉的 react + ant design 开始,第一次也做的不好,后面我重新开了一个react + ant design 的项目,最后成功实现了。
复制带有 Latex 语法的公式的 markdown 格式到微信公众号上面还是有一些各种的特殊情况需要处理的,真正要做好其实是需要做不少的脏活。
下面是之前 GLM-4.5 接入 Claude Code 的实战视频。
对比前后的两代模型,可以看到 GLM-4.6 的 Agentic Coding 能力确实有不小的改进,由 200K 超长上下文窗口带来的一系列优势也使得模型的整体能力得到全面优化。
因为上下文更长了,我们也不需要反复强调之前被遗忘的部分内容,节省了部分重复的交流提示词,进一步减少了 Token 的消耗,兼具了性能与成本效益。
而从具体的体验上来看,GLM-4.6 的代码编辑/代码搜索的比值会更高。
所谓比例更高,是指在相同的对话次数中,搜索代码的次数会少一些,而直接进入代码编辑的次数增多。
我从上下文记忆的角度思考,觉得背后的原因在于是由于上下文记忆的增强让 GLM-4.6 能够保留更多的代码内容,不再需要反复搜索之前已经查询过的内容,直接进行代码编辑,从而减少了搜索的次数。减少了搜索的次数也就意味着减少了 Token的消耗。
总体来说,GLM-4.6 不仅代码能力提升了,还有着更长的上下文支持,两者的加持下,Agentic Coding 能力得到了跃升。卷编程,智谱是认真的。
写在最后
这次对智谱 GLM-4.6 的实测,整体体验下来是相当不错的。
在前端“高级待办事项”这个相对复杂的任务上,GLM-4.6 的表现确实很突出,它的代码完成度很高,我们要求的核心功能基本都实现了,最终的效果可以和 Claude Sonnet 4 这样的国际模型放在同一个水平线上。对比国内其他的模型,它的优势就会很明显。
当然,我们也看到了,在需要前后端协同的“全栈模式”下,模型会出现遗忘需求、交互设计不佳的问题。这其实也反映出,当任务的复杂度提升,需要更长的记忆和规划能力时,即便是最前沿的模型也还有进步的空间。
这次测试的另一个重点是 GLM-4.6 在 Agentic Coding 环境下的表现。通过和上一代模型的对比,我们能感觉到它实实在在的进步。
官方提到的 200K 长上下文窗口确实带来了很大帮助,模型能够记住更多的代码细节,减少了不必要的代码搜索动作,更多地直接进行代码编辑。这不仅提升了开发效率,也间接降低了 Token 消耗。
这一次,智谱在提升模型代码能力这件事上确实是下了功夫的。今天的 GLM-4.6,无论是在直接生成复杂代码的“硬实力”上,还是在长上下文辅助开发的“软实力”上,都展现了很强的竞争力。
智谱开放平台地址:bigmodel.cn
GLM-4.6体验地址:chat.z.ai
 一起“点赞”三连↓
一起“点赞”三连↓

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









