



Datawhale分享
最新:Claude Sonnet 4.5,编译:机器之心
昨天,DeepSeek 开源新模型 V3.2-Exp,深夜 Anthropic 也不甘人后,重磅发布 Claude Sonnet 4.5。

作为编程领域的王者,Claude 新模型依然强势,自称为世界上最好的编码模型。
我们都知道,GPT-5 Codex 曾自称能独立运行超过 7 小时。但这次,Claude Sonnet 4.5 把自主编码时长提到了 30 多个小时。
此外,Claude 还称它为构建复杂智能体的最强模型,也是使用计算机( computer use)的最佳模型,在推理和数学方面显示出巨大的进步。
Claude Sonnet 4.5 使这一切成为可能。Anthropic 将它与一系列产品重大升级一同发布:
在 Claude Code 方面,Anthropic 添加了检查点功能 —— 这是用户需求最高的功能之一 —— 它能保存你的进度,并让你即时回滚到之前的状态。
Anthropic 更新了终端界面,并推出了原生的 VS Code 扩展。他们为 Claude API 增添了新的上下文编辑功能和记忆工具,让智能体能够运行更长时间,并处理更高复杂度的任务。
在 Claude 应用程序中,他们将代码执行和文件创建(电子表格、幻灯片和文档)功能直接融入对话之中。
此外,他们还为上个月加入候补名单的 Max 用户提供了 Claude for Chrome 扩展。
Anthropic 还为开发者提供了他们自己用于打造 Claude Code 的基础工具。他们将其称为 Claude Agent SDK。
Anthropic 表示,这是他们发布过的最符合对齐要求的前沿模型,与之前的 Claude 模型相比,在多个对齐领域都有显著改进。
Claude Sonnet 4.5 版本今日已全面上线。如果你是开发者,只需通过 Claude API 使用 claude-sonnet-4-5 即可。定价与 Claude Sonnet 4 版本保持一致,每百万 token 输入 / 输出分别为 3 美元 / 15 美元。
以下是官方博客。
前沿智能
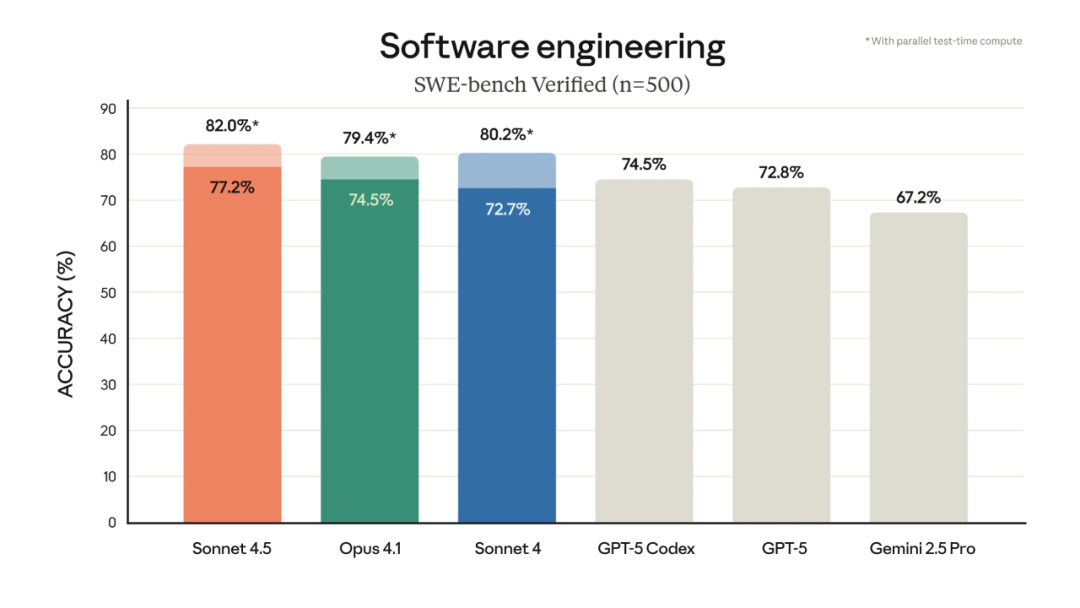
Claude Sonnet 4.5 在 SWE-bench 验证评估中处于 SOTA 水平,该评估衡量的是现实世界中的软件编码能力。实际上,Anthropic 观察到它在复杂的多步骤任务上能够保持专注超过 30 小时。
Claude Sonnet 4.5 代表了 computer use 方面的重大飞跃。在 OSWorld(一个在现实世界计算机任务中测试人工智能模型的基准测试平台)上,Sonnet 4.5 现在以 61.4% 的成绩领先。就在四个月前,Sonnet 4 以 42.2% 的成绩领先。Claude for Chrome 扩展将这些升级后的功能加以利用。在下面的演示中,他们展示了 Claude 直接在浏览器中工作,浏览网站、填写电子表格并完成任务。
该模型在包括推理和数学在内的广泛评估中也展现出了更强的能力:
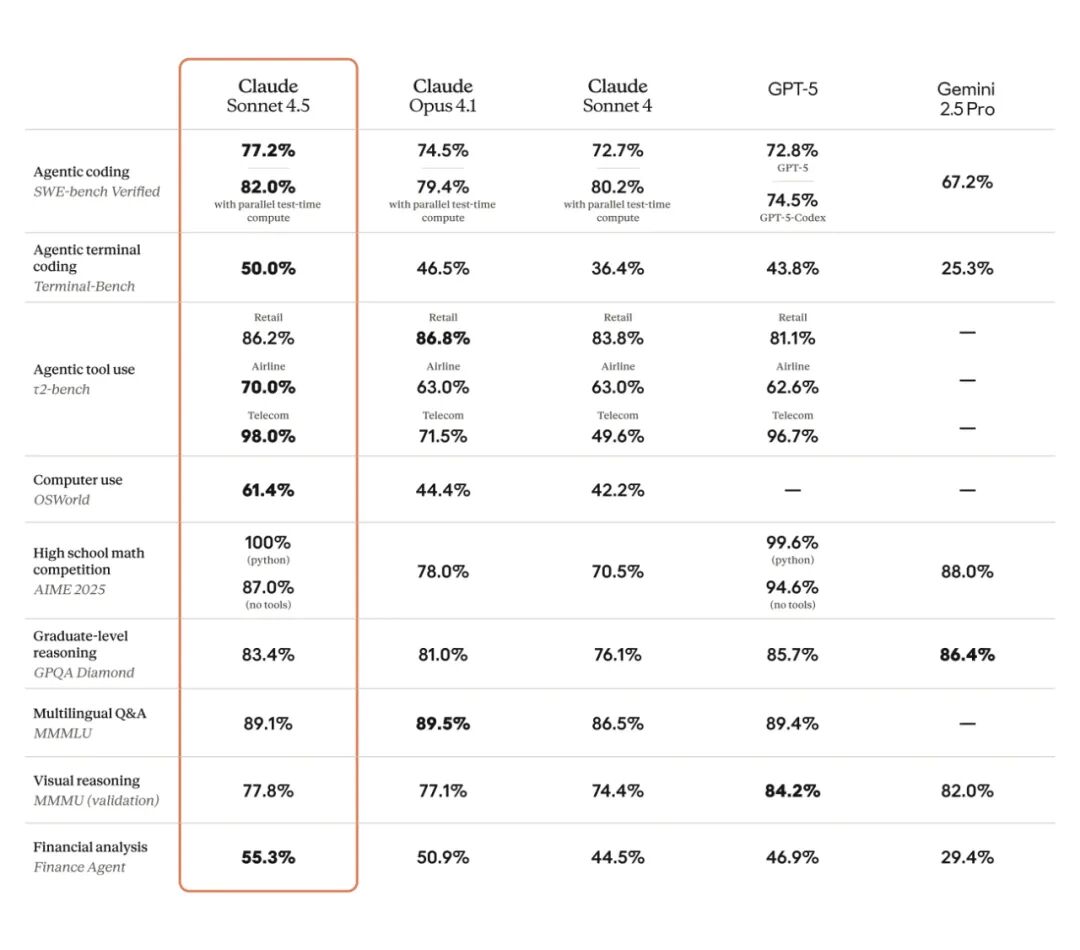
金融、法律、医学和理工科(STEM)领域的专家发现,与包括 Opus 4.1 在内的旧模型相比,Sonnet 4.5 在特定领域知识和推理方面表现得明显更好。
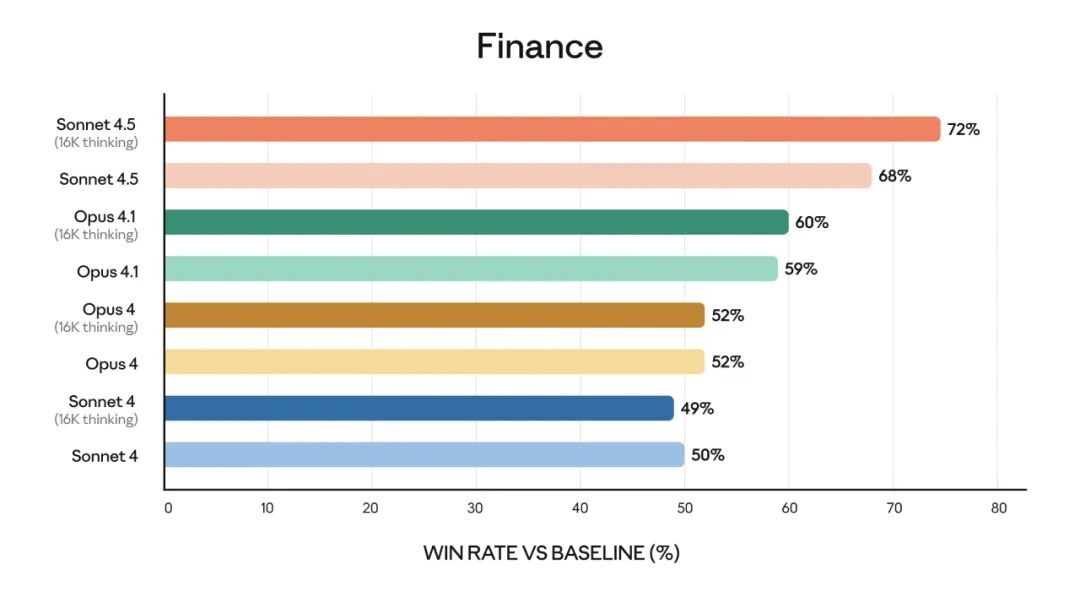
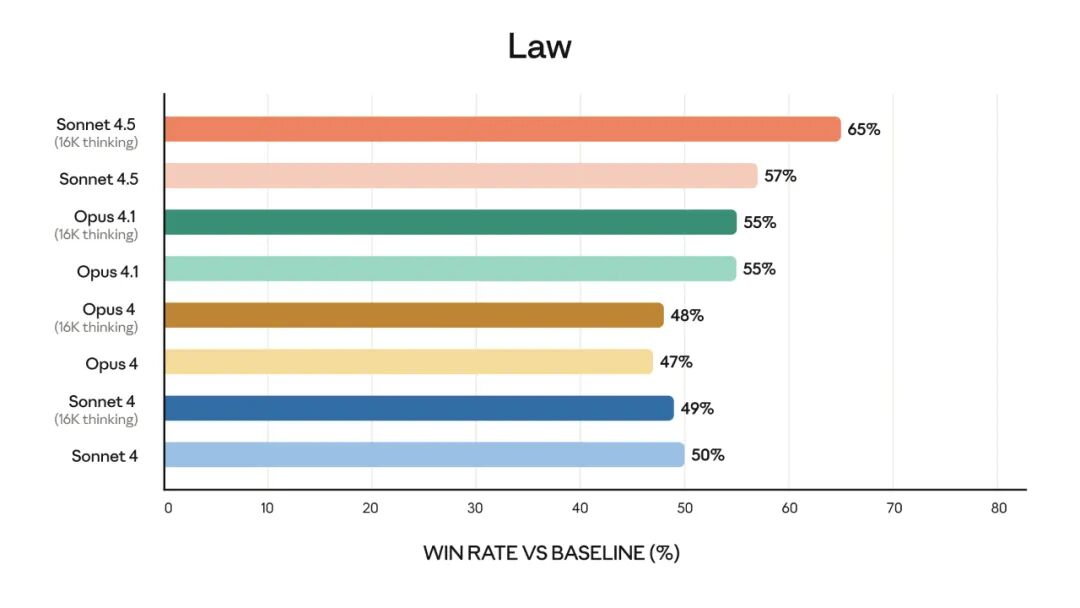
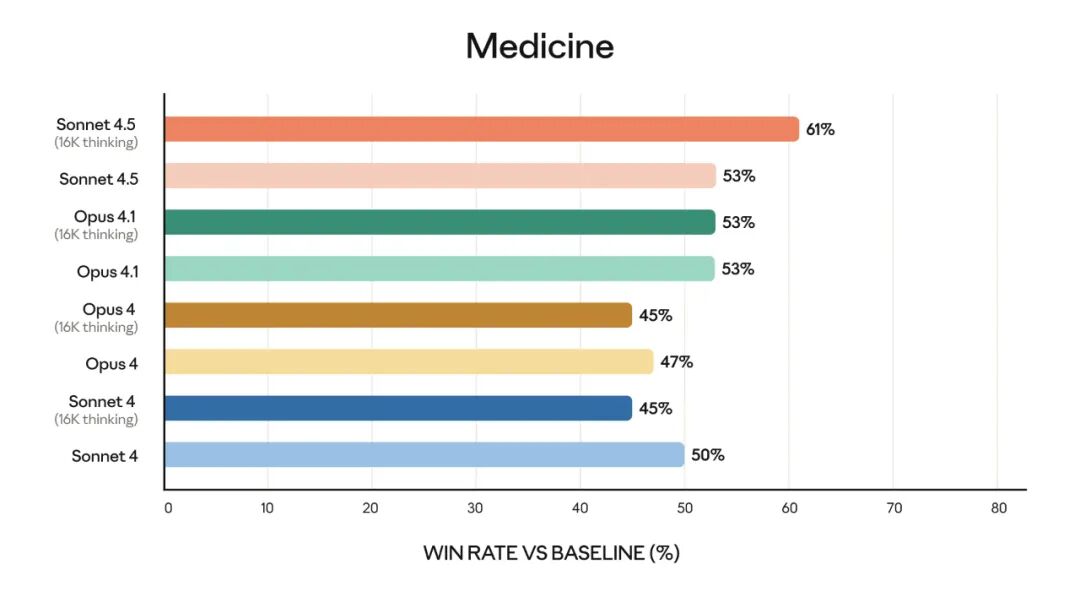
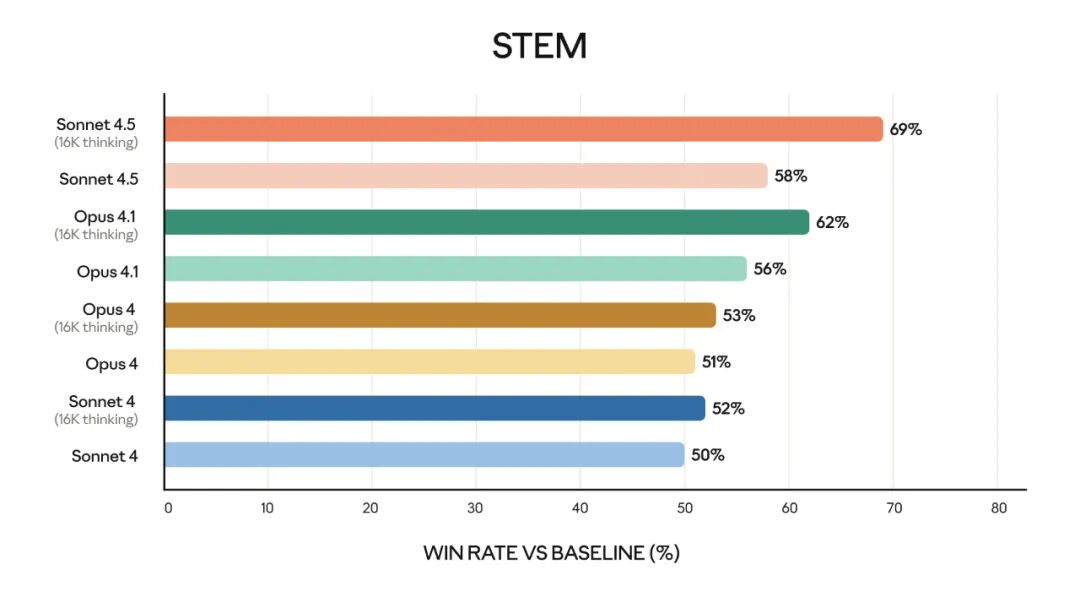
该模型的能力也体现在早期客户的体验中:


Anthropic 迄今为止对齐最好的模型
Anthropic 表示,Claude Sonnet 4.5 不仅是他们性能最强的模型,也是目前与人类价值观一致性最高的前沿模型。Claude 提升的能力以及 Anthropic 广泛的安全训练,让他们能够大幅改善模型的表现,减少诸如谄媚、欺骗、争取主导权(power-seeking)以及鼓励妄想性思维等令人担忧的行为。对于模型的智能体和计算机使用能力,Anthropic 在抵御提示注入攻击方面也取得了显著进展,这是使用这些能力的用户面临的最严重风险之一。
你可以在 Claude Sonnet 4.5 系统卡片中阅读一套详细的安全性和一致性评估,其中首次包括使用「机制可解释性技术」进行的测试。

系统卡地址:https://assets.anthropic.com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf
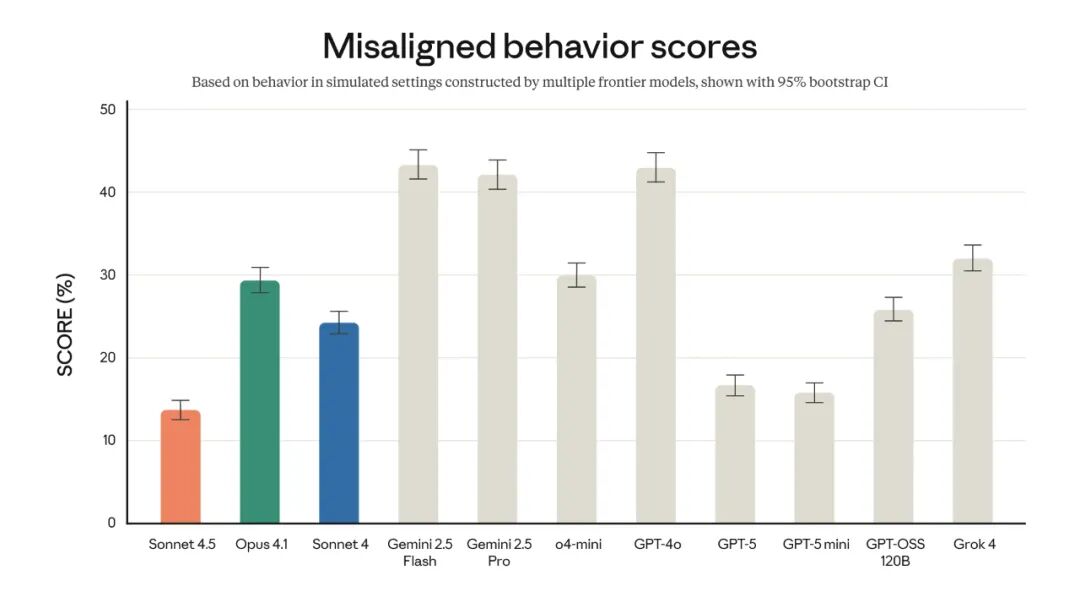
Claude Sonnet 4.5 版本将在 Anthropic 的 AI 安全等级 3(ASL-3)保护措施下发布,这是按照他们将模型能力与适当保障措施相匹配的框架进行的。这些保障措施包括名为分类器的过滤器,其旨在检测潜在危险的输入和输出,特别是那些与化学、生物、放射性等相关的内容。
这些分类器有时可能会无意中标记正常内容。Anthropic 已为用户提供便利,让他们能够继续与 Sonnet 4 进行任何中断的对话,该模型带来的化学、生物、放射性风险较低。Anthropic 在减少这些误报方面已经取得了显著进展。
Claude Agent SDK
Claude 称他们花了六个多月的时间更新 Claude Code 的能力,因此自己知道如何构建和设计 AI 智能体。过程中他们解决了许多难题:包括智能体如何在长时间运行的任务中管理内存,如何处理平衡自主性和用户控制性的权限系统,以及如何协调子智能体朝着共同目标努力。
今天的发布就是以上努力的成果,也就是 Claude Agent SDK。它 Claude Code 的基础架构相同,但它不仅在编码领域,还在各种任务中展现出令人印象深刻的优势。从今天起,用户可以使用它来构建自己的智能体。
最后,Claude 还发布了一个临时研究的预览版,叫 Imagine with Claude.
在这个实验中,Claude 可以即时生成软件,且前提是不预先设定任何功能,也不预先编写任何代码。我们所看到的是 Claude 实时创建、响应并适应请求,并与用户交互互动。
以上视频就是该实验的有趣演示,展示了 Claude Sonnet 4.5 的功能 —— 它可以让您了解将强大的模型与合适的基础架构相结合所能实现的潜力。
“Imagine with Claude” 将在未来五天内面向 Max 订阅用户开放。
参考地址:
1. https://www.anthropic.com/news/claude-sonnet-4-5


















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









