 清华登顶2025 CS Rankings榜首
清华登顶2025 CS Rankings榜首




Datawhale干货
排名:CS Rankings 2025大学排名
CSRankings 2025再次更新!
全世界计算机科学机构的排名有了大变动!
CSRankings整体排名
在此次更新的榜单上,清华大学首次摘得全球第一!清华大学、上海交通大学、浙江大学、北京大学分列第1、3、4、5位,直接占据了TOP 5中的4个名额。传统霸主卡内基梅隆大学(CMU)退居第2,但依然保持着美国高校的最高排位。亚洲势力整体上扬:新加坡国立大学、韩国科学技术院(KAIST)、香港科技大学等悉数闯入前20。爱丁堡大学成英国赛区黑马,超越牛津、剑桥,成为英国第一。
以下是完整的前20榜单
人工智能等细分方向排名
除了整体排名,CSRankings对众多热门细分方向也进行了排名。我们整理了人工智能、人机交互、机器人、软件工程等同学们较为关注和喜欢的专业方向。
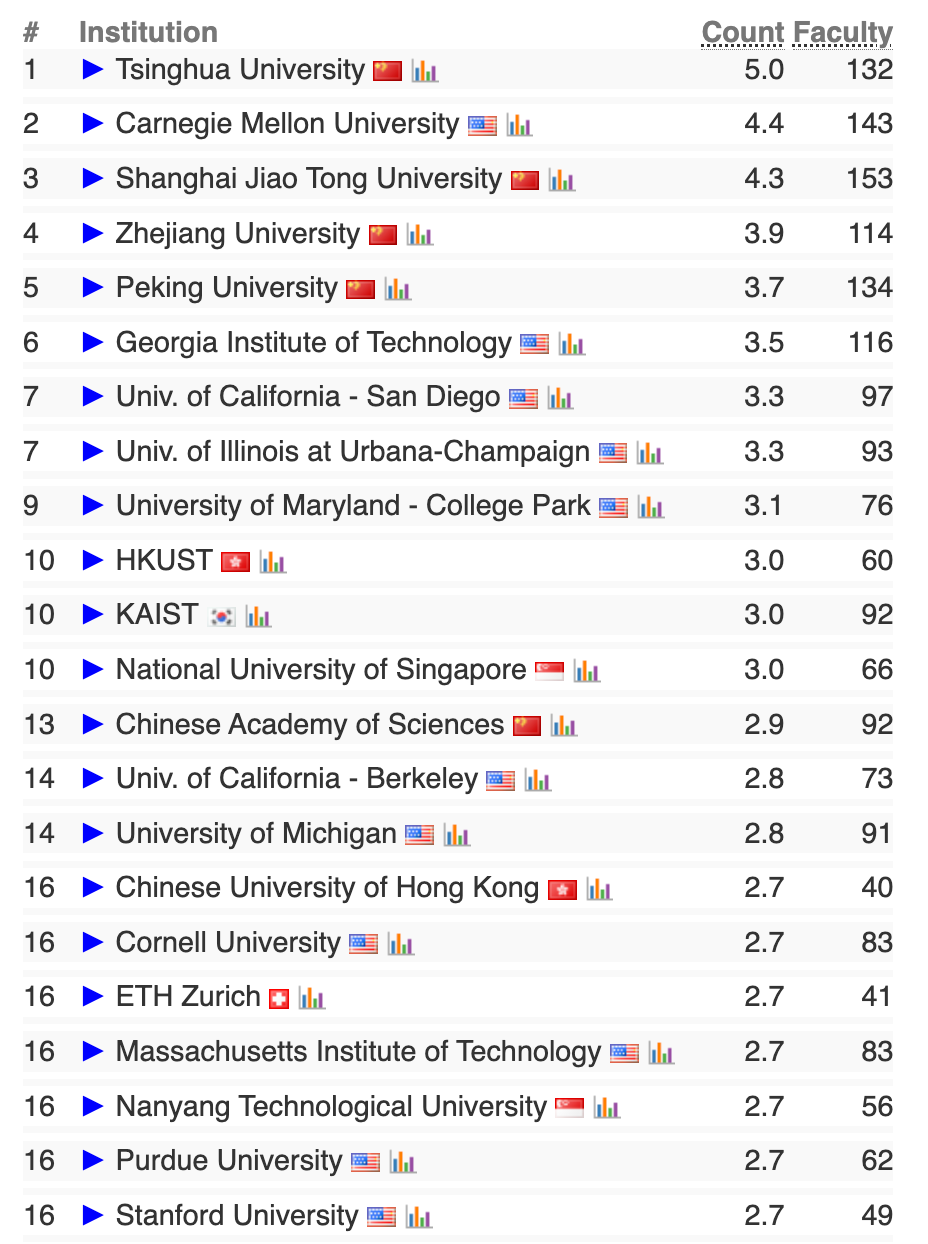
AI大类人工智能方向前20榜单
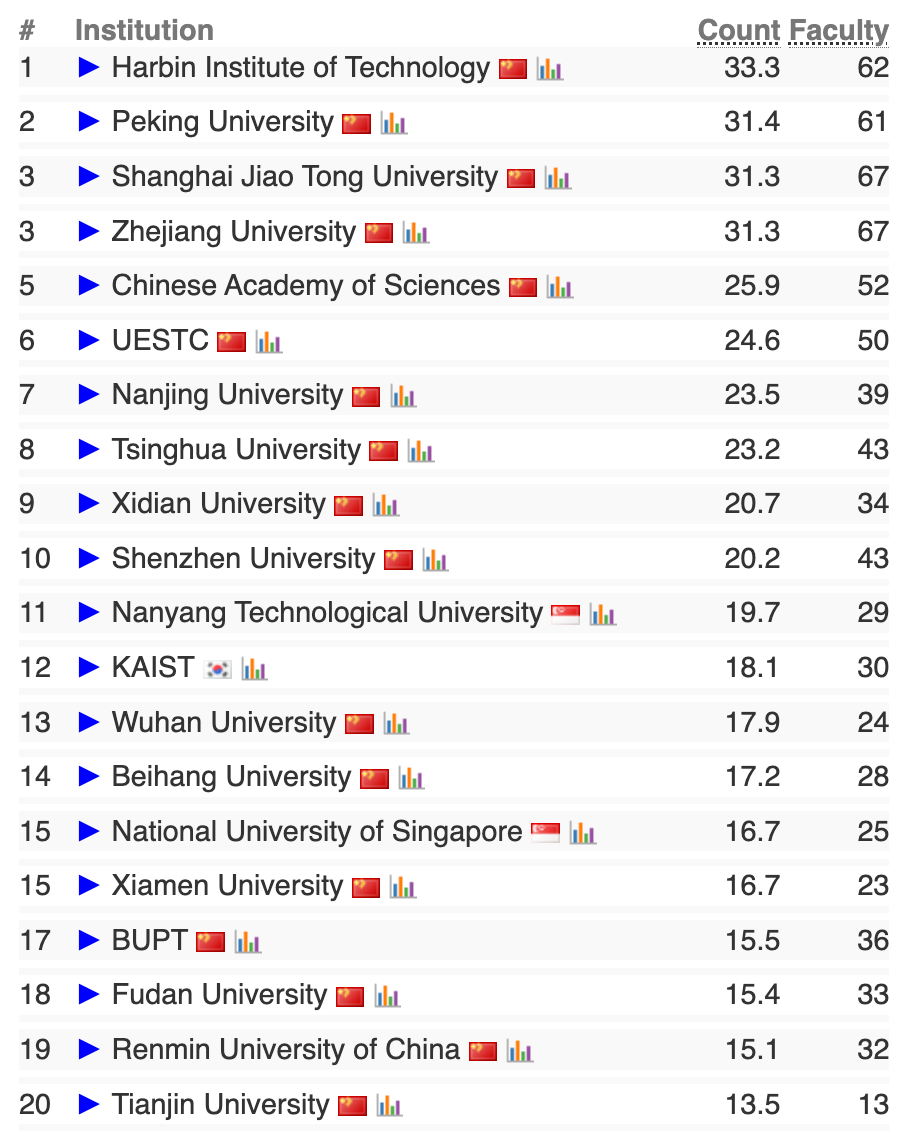
AI大类计算机视觉方向前20榜单
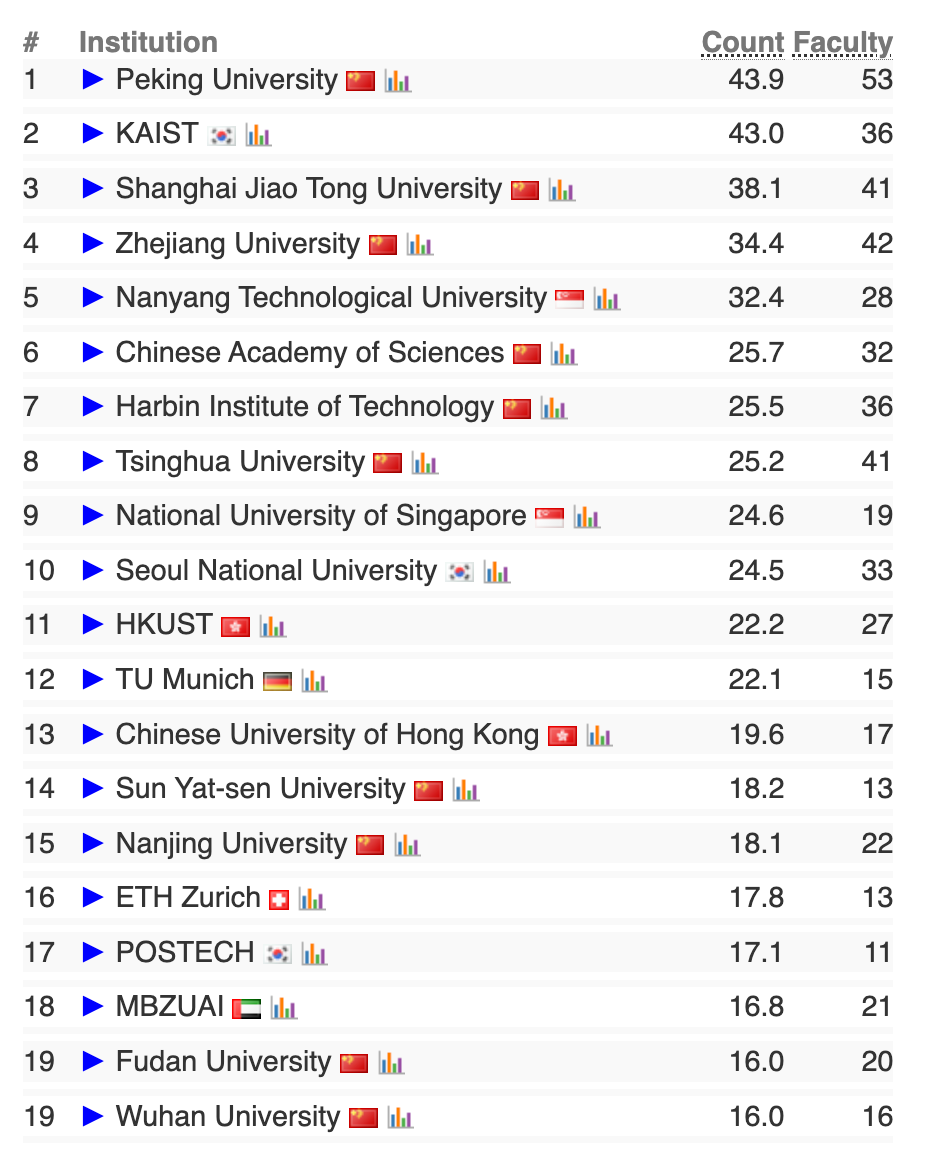
AI大类机器学习方向前20榜单
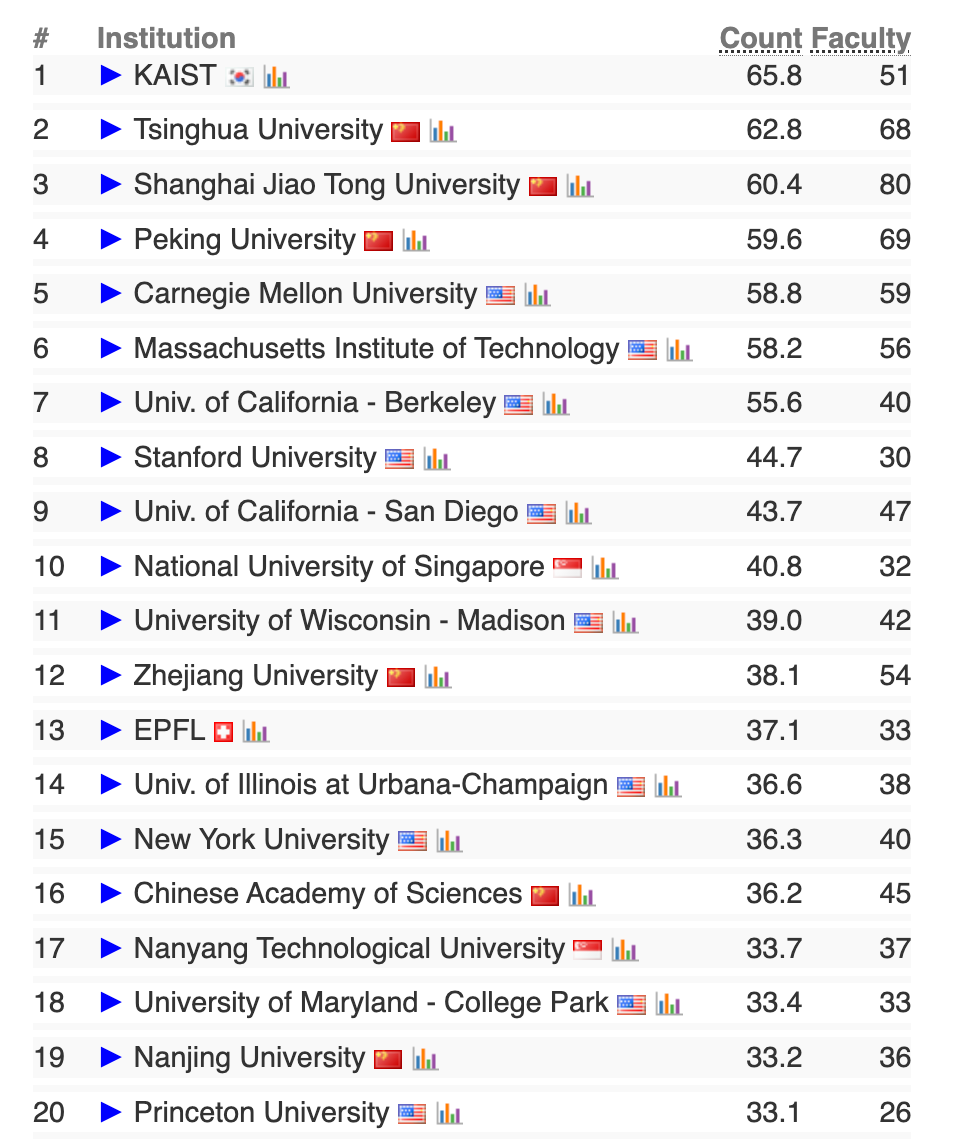
AI大类自然语言处理方向前20榜单
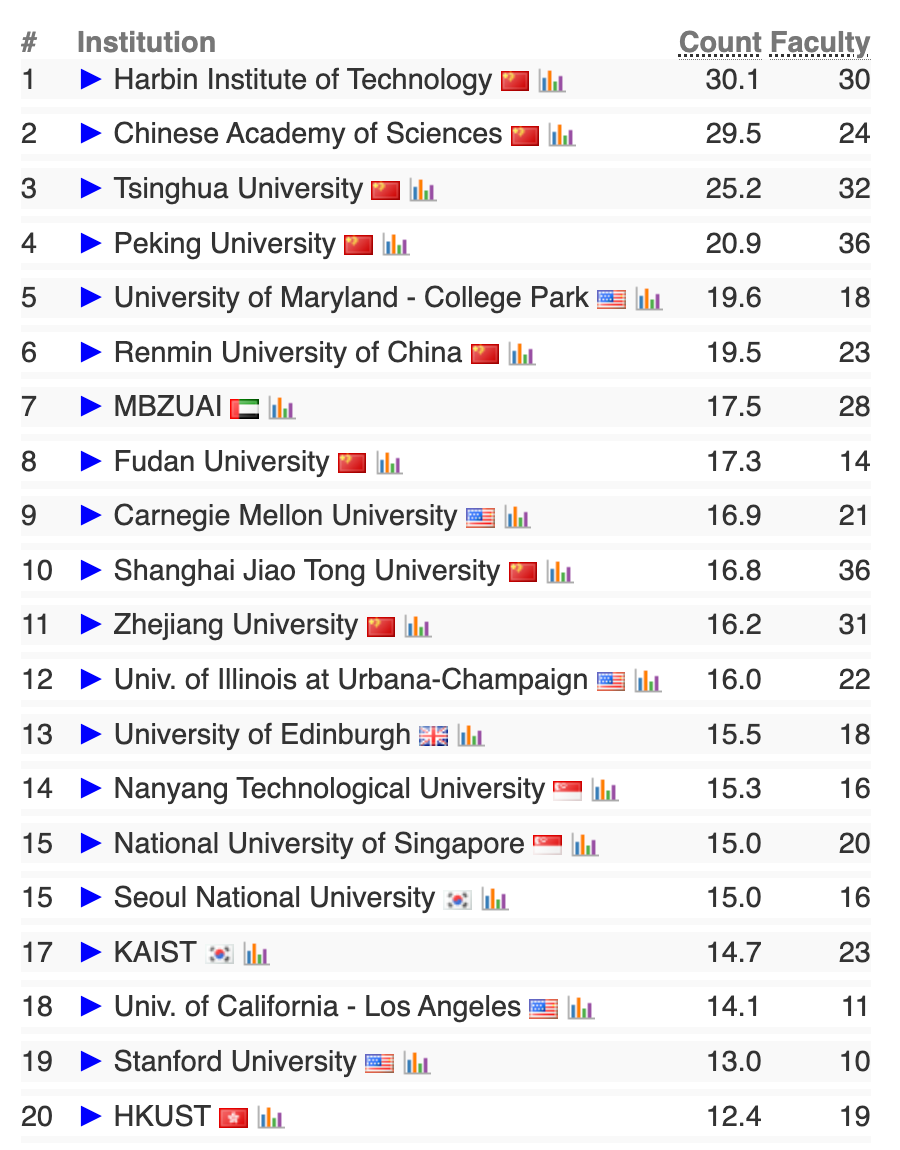
人机交互方向前20榜单
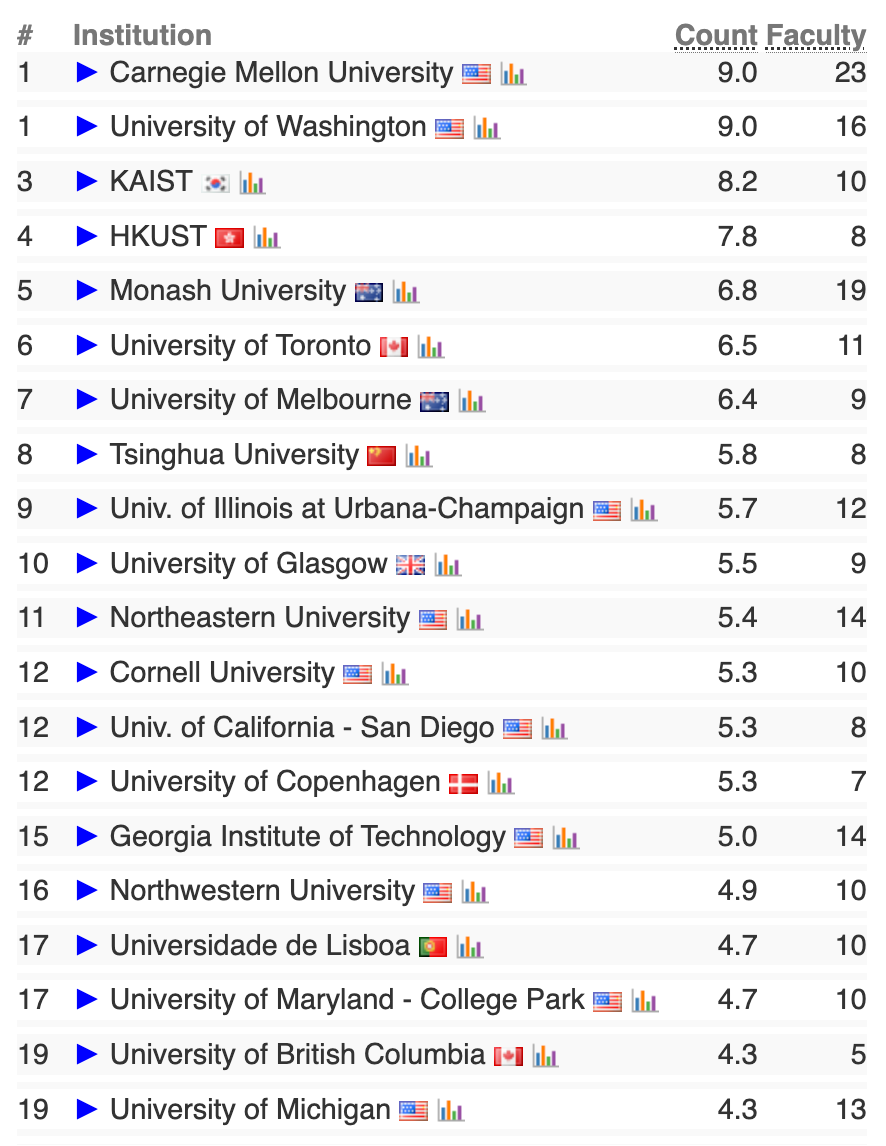
机器人方向前20榜单
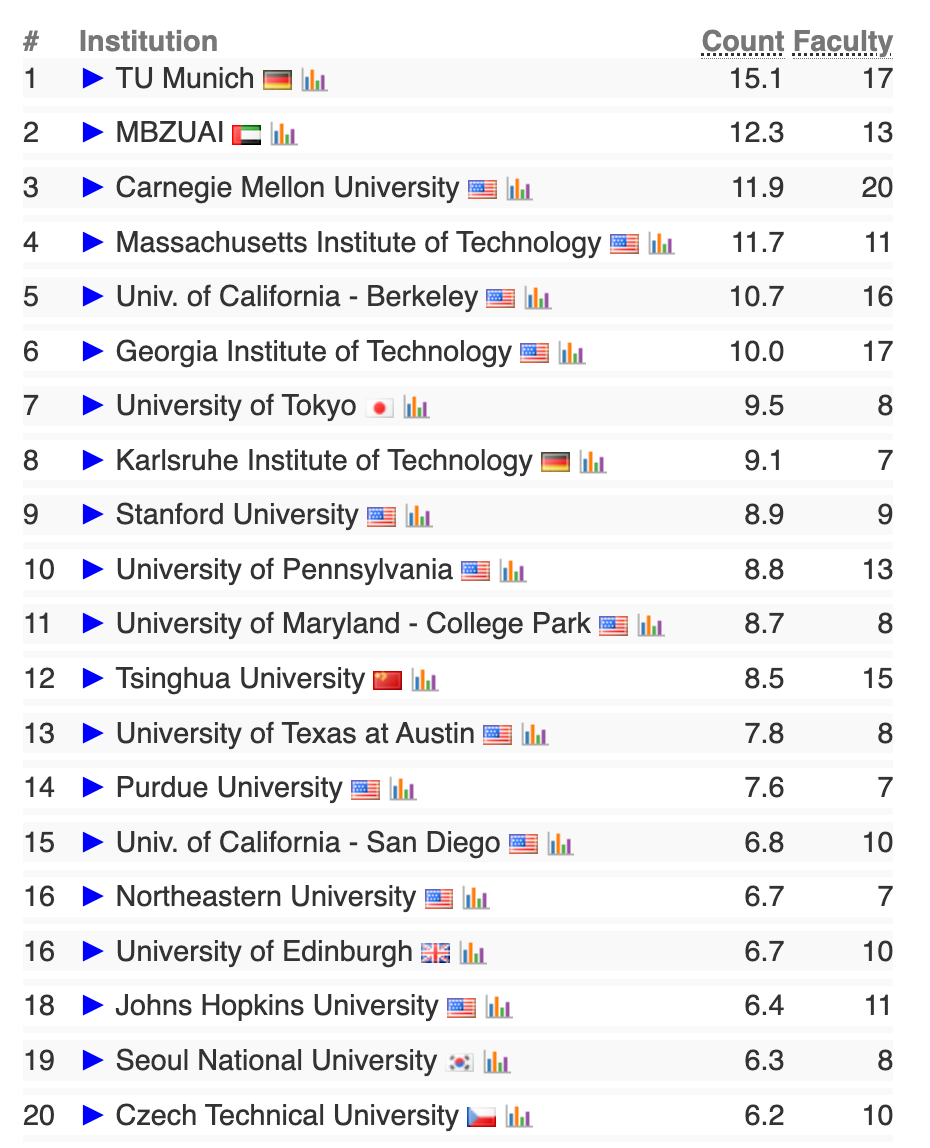
软件工程方向前20榜单
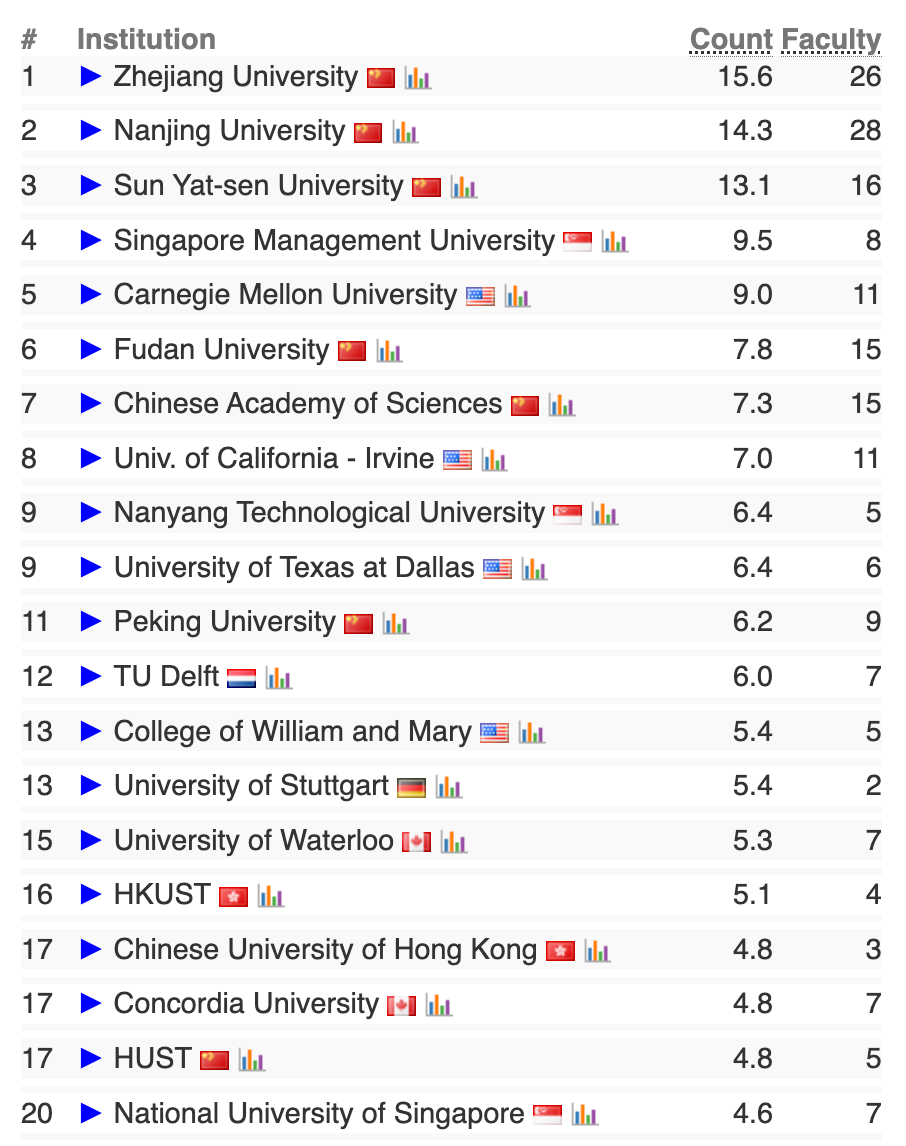

最新排名,点赞在看↓

















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









