



Datawhale干货
作者:筱可,Datawhale成员
一、概要
这篇文章主要面向对人工智能和大型语言模型感兴趣的初学者。
我们将一起看看,如何在一个已经很厉害的通用大模型基础上,通过一些方法,把它训练成一个特定领域(比如金融、医疗)的专业模型。
我们会聊到两种主要的技术路线,以及在这个过程中会遇到的一个大问题,灾难性遗忘,和一些应对这个问题的办法。
同时,我们也会具体看看不同技术路线在硬件、时间和数据投入上的巨大差异,并帮你建立一个直观的概念,比如一个亿的token到底代表了多大的数据量。
目录
📜 概要
🙋 前言
💰 从零开始:一条高投入高回报的路
🔧 持续预训练,更经济的再教育之路
⚖️ 不同路线的资源投入对比
🔢 一个亿的Token是什么概念?
🧠 训练中的一个大问题,灾难性遗忘
🛠️ 给重要参数上保护锁
弹性权重巩固 (EWC)
更高效的层级正则化
🔭 其他应对遗忘的思路
📚 课程学习与数据筛选
🔬 一个具体的例子:FinPythia的训练过程
💧 数据集的构建与处理
⚙️ 硬件与训练技巧
🧮 背后的一些关键公式
🧮 FinPythia模型评估结果
✅ 总结
📚 参考文献
📚 往期精选
二、前言
现在的大型语言模型,像GPT系列,已经具备了非常广泛的通用知识和语言能力。
但是,如果我们想让模型在一个非常专业的领域里工作,比如帮助医生分析医疗报告,或者辅助金融分析师处理财报,通用的知识可能就不够用了。
这时候,我们就需要一个在特定垂直领域表现更出色的模型。
要得到这样的模型,通常有两条路可以走。
一条是像BloombergGPT那样,不计成本地从零开始,用海量的专业数据重新训练一个全新的大模型。
另一条路则显得更经济一些:我们能不能在一个现成的、已经很强大的通用模型基础上,对它进行再教育,让它掌握特定领域的知识呢?
这篇文章主要聊的就是后面这条路,以及这条路上的一些关键技术和挑战。
三、从零开始:一条高投入高回报的路
在讨论如何改造现有模型之前,我们先简单看看从零开始是怎么回事。
这方面的一个典型代表就是BloombergGPT。
我从论文里看到,彭博社为了打造一个顶尖的金融大模型,首先整理了自己公司四十年来积累的海量金融数据,做成了一个名为FinPile的数据集。
然后,他们把这个专业数据集和大量的通用公开数据混合在一起,从头开始训练了一个拥有506亿参数的大模型。
BloombergGPT的训练数据集由两大部分组成:
金融领域数据(FinPile):约占总token数的51.97%,包括金融新闻、公司年报、新闻稿、Bloomberg自有内容等。
通用公开数据:约占总token数的48.03%,包括C4、The Pile、Wikipedia等主流公开语料。
具体各子集的token占比如下(单位见表头):
BLOOMBERGGPT完整训练集的数据来源拆解。统计项包括每个子集的文档数量(Docs 1e4)、每份文档的平均字符数(C/D)、总字符数(Chars 1e8)、每个token的平均字符数(C/T)、总token数(Toks 1e8),以及该子集占全部token的百分比(T%)。各项单位见表头。
Dataset | Docs 1e4 | C/D | Chars 1e8 | C/T | Toks 1e8 | T% |
FINPILE(金融领域总计) | 175,886 | 1,017 | 17,883 | 4.92 | 3,635 | 51.97% |
Web(金融网页) | 158,250 | 933 | 14,768 | 4.96 | 2,978 | 42.01% |
News(金融新闻) | 10,040 | 1,665 | 1,672 | 4.44 | 376 | 5.31% |
Filings(公司年报) | 3,335 | 2,340 | 780 | 5.30 | 145 | 2.04% |
Press(新闻稿) | 1,265 | 3,443 | 435 | 5.06 | 86 | 1.21% |
Bloomberg(自有内容) | 2,996 | 758 | 227 | 4.60 | 49 | 0.70% |
PUBLIC(公开数据总计) | 50,744 | 3,314 | 16,818 | 4.87 | 3,454 | 48.73% |
C4 | 34,832 | 2,206 | 7,683 | 5.56 | 1,381 | 19.48% |
Pile-CC | 5,255 | 4,401 | 2,312 | 5.42 | 427 | 6.02% |
GitHub | 1,428 | 5,364 | 766 | 3.38 | 227 | 3.20% |
Books3 | 19 | 552,398 | 1,064 | 4.97 | 214 | 3.02% |
PubMed Central | 294 | 32,181 | 947 | 4.51 | 210 | 2.96% |
ArXiv | 124 | 47,819 | 591 | 3.56 | 166 | 2.35% |
OpenWebText2 | 1,684 | 3,850 | 648 | 5.07 | 128 | 1.80% |
FreeLaw | 349 | 15,381 | 537 | 4.99 | 108 | 1.52% |
StackExchange | 1,538 | 2,201 | 339 | 4.17 | 81 | 1.15% |
DM Mathematics | 100 | 8,193 | 82 | 1.92 | 43 | 0.60% |
Wikipedia (en) | 590 | 2,988 | 176 | 4.65 | 38 | 0.53% |
USPTO Backgrounds | 517 | 4,339 | 224 | 6.18 | 36 | 0.51% |
PubMed Abstracts | 1,527 | 1,333 | 204 | 5.77 | 35 | 0.50% |
OpenSubtitles | 38 | 31,055 | 119 | 4.90 | 24 | 0.34% |
Gutenberg (PG-19) | 3 | 399,351 | 112 | 4.89 | 23 | 0.32% |
Ubuntu IRC | 1 | 539,222 | 56 | 3.16 | 18 | 0.25% |
EuroParl | 7 | 65,053 | 45 | 2.93 | 15 | 0.21% |
YouTubeSubtitles | 17 | 19,831 | 33 | 2.54 | 13 | 0.19% |
BookCorpus2 | 2 | 370,384 | 65 | 5.36 | 12 | 0.17% |
HackerNews | 82 | 5,009 | 41 | 4.87 | 8 | 0.12% |
PhilPapers | 3 | 74,827 | 23 | 4.21 | 6 | 0.08% |
NIH ExEPorter | 92 | 2,165 | 20 | 6.65 | 3 | 0.04% |
Enron Emails | 24 | 1,882 | 5 | 3.90 | 1 | 0.02% |
Wikipedia (7/1/22) | 2,218 | 3,271 | 726 | 3.06 | 237 | 3.35% |
TOTAL | 226,631 | 1,531 | 34,701 | 4.89 | 7,089 | 100.00% |
1)分词器(Tokenizer)与词表设计
他们没有采用像 BPE(Byte Pair Encoding)或 WordPiece 这种基于贪心策略的分词器,而是选择了 Unigram分词器。Unigram 的一个核心优势在于,它在分词时保留了概率信息,这意味着对于同一段文本,它可以有多种可能的分词方式。这种灵活性使得模型在处理不同语言和专业术语时能表现得更好。
在具体的实现上,BloombergGPT 首先将所有文本都看作是底层的字节序列(byte sequence),而不是我们通常所说的Unicode字符。这样做的好处是,词汇表天然就包含了所有256个基础字节,从根本上避免了模型遇到不认识的生僻字或符号(即“out-of-vocabulary”问题)。接着,在预分词阶段,他们通过一个正则表达式把文本初步切分成字母块、数字和符号。这里有一个设计:他们允许空格出现在字母块中,这样分词器就能学习到像“New York”这样的多词短语作为一个单独的token,这不仅提高了信息密度,也有效缩短了处理相同内容所需的上下文长度。
由于 Unigram 分词器直接处理像 The Pile 这样庞大的语料库效率很低,他们还独创了一套并行的分块训练与分层合并策略。简单来说,就是先把整个大数据集切成数千个小块,在每个小块上独立训练出一个小分词器,最后再像搭积木一样,通过加权平均token概率的方式,把这些小分词器层层合并成一个最终的大分词器。
最终的词汇表大小也经过了仔细考量。他们通过实验发现,一个大小为 (即131,072)的词汇表,能在编码信息密度和模型参数开销之间取得最佳平衡。这个词汇量比当时主流模型常用的5万左右要大得多。
如下面的表格所示,BloombergGPT的分词器在处理相同文本时,能比其他模型产生更少的token。这意味着在训练时,模型能用更短的序列长度装下更多的信息,从而显著提升了训练效率和上下文窗口的利用率。
BLOOM | /ours | NeoX | /ours | OPT | /ours | BloombergGPT | |
|---|---|---|---|---|---|---|---|
FinPile (旧) | 451 | 110% | 460 | 112% | 456 | 111% | 412 |
C4 | 166 | 121% | 170 | 123% | 170 | 123% | 138 |
The Pile | 203 | 110% | 214 | 116% | 239 | 130% | 184 |
Wikipedia | 21 | 88% | 23 | 99% | 24 | 103% | 24 |
Total | 390 | 113% | 408 | 118% | 434 | 126% | 345 |
(表源:BloombergGPT 论文) 不同分词器在各语料上的token数量对比(单位:十亿)。“/ours”列显示了其他分词器与BloombergGPT分词器产生的token数量比率。
2)训练配置(Training Configuration)
BloombergGPT的训练采用了标准的自回归语言建模目标,核心配置如下:
训练流程:所有训练序列长度统一为2048个token,提升GPU利用率。所有文档token化后用特殊分隔符连接,再分割为定长块。
优化器:AdamW, , ,权重衰减0.1。最大学习率 ,余弦退火调度,线性warmup(前1800步)。最终学习率为最大值的0.1倍。
批次大小:前7200步warmup阶段为1024(约210万token),之后提升到2048(约420万token)。
Dropout:初始为0,后期根据验证集表现动态调整。
参数初始化:均值为0,标准差 ,D为隐藏层维度。部分层采用特殊缩放。
数值稳定性:采用query_key_layer_scaling技术,提升BF16/FP16训练稳定性。
硬件环境:训练在AWS SageMaker云平台,使用64台p4d.24xlarge实例(每台8块A100 40GB GPU),总计512块A100。存储采用Amazon FSX for Lustre,支持高吞吐读写。
训练时长与规模:总训练步数约14万步,历时约53天,训练token总量5690亿。
四、持续预训练,更经济的再教育之路
既然从零开始代价太高,那么在现有模型上进行再教育就成了一个更受欢迎的方向。
这种再教育的过程,在技术上通常被称为持续预训练 (Continual Pre-training)。
《Don't Stop Pretraining》这篇论文系统地研究了这种方法。
研究中提到了两种主要的持续预训练策略:
领域自适应预训练 (Domain-Adaptive Pretraining, DAPT),指的是在一个通用模型的基础上,用特定领域的大量数据(比如生物医学领域的所有论文)继续进行训练。
这个过程能让模型学会这个领域的专业术语和表达习惯。
任务自适应预训练 (Task-Adaptive Pretraining, TAPT),指的是在DAPT之后,再用更具体、更聚焦的任务数据进行训练。
这个过程能让模型更好地对齐我们最终要解决的问题。
我从论文里看到,如果把这两种方法结合起来,先做DAPT再做TAPT,通常能获得最好的效果。
五、不同路线的资源投入对比
聊到从零开始和持续预训练,你可能会好奇,这两条路在实际投入上到底有多大差别?我从几篇论文里整理了一些关键数据,可以帮助我们建立一个直观的感受。
首先是从零开始的代表BloombergGPT,它的投入是大量的。 他们训练了一个506亿参数的模型,动用了512块NVIDIA A100 GPU (每块40GB显存),整个训练过程持续了大约53天。 在数据量上,他们使用了高达5690亿个token。
然后是持续预训练路线。在《Efficient Continual Pre-training》这篇论文里,研究者们在已有的Pythia模型上进行再训练。 他们实验了10亿和69亿两种参数规模的模型。硬件上,只用了一台p4d.24xlarge实例,这个实例配备了8块NVIDIA A100 GPU (每块也是40GB显存)。 在240亿个token的数据上,训练69亿参数的模型花了18天,训练10亿参数的模型则花了3天。
最后,《Don't Stop Pretraining》这篇论文更侧重于方法的验证,规模更小。 它使用的基础模型RoBERTa-base只有1.25亿左右的参数,硬件是一块v3-8 TPU。 训练时长不是按天计算,而是按步数或轮数。数据量上,领域自适应预训练用了20亿到80亿个token,而任务自适应预训练的数据量就更小了,只有几千个样本。
通过这个对比,我们能很清楚地看到,不同技术路线在硬件、时间、数据上的投入是数量级的差异。
六、一个亿的Token是什么概念?
我们上面提到了一个单位叫token,你可能会觉得有点抽象。一个亿的token到底是多少内容呢?
一个token不完全等于一个单词。在处理英文时,像“unbelievably”这样的词可能会被拆成“un”、“believe”、“ably”三个token。处理中文时,通常一个汉字就是一个token。
我们可以根据论文里的数据来做一个估算。在《Efficient Continual Pre-training》中,165亿个单词对应了239亿个token,平均每个单词大约是 1.45 个token。
基于这个比例,我们可以换算出“一个亿的token”大致相当于: 大约 6900万个单词。
如果按一句话平均20个单词来算,这相当于 350万个句子。
如果换算成我们更熟悉的东西: 一本普通的书大约是7万个单词,那么一个亿的token就差不多相当于 1000本书 的内容。
所以,当我们说一个模型用了几千亿token来训练时,你可以想象一下,它等于阅读了几十万甚至上百万本书,这个数据规模是非常庞大的。
七、训练中的一个大问题,灾难性遗忘
持续预训练这条路虽然经济高效,但它会面临一个非常棘手的问题,叫做灾难性遗忘 (Catastrophic Forgetting)。
这个问题指的是,当一个已经训练好的模型去学习新知识时,会严重损害甚至完全忘记它之前学到的旧知识。
比如,一个通用模型原本知道法国的首都是巴黎,但在我们用大量医疗数据对它进行微调后,它可能就回答不出这个常识问题了。
之所以会发生这种情况,是因为在学习新任务的过程中,模型网络中那些对旧知识至关重要的参数(权重),被为了适应新任务而改变了。
这个问题是持续学习领域一个核心的挑战。
八、给重要参数上保护锁
为了解决灾难性遗忘这个棘手的问题,研究人员的核心思路出奇地一致:在学习新知识时,我们不能对所有模型参数一视同仁,而是要识别出那些对旧知识至关重要的参数,并给它们上一种特殊的保护锁,限制它们在新任务的训练中发生较大的变化。
1. 弹性权重巩固 (EWC)
这方面经典,有开创性的方法之一,就是《Overcoming catastrophic forgetting in neural networks》这篇论文中提出的弹性权重巩固 (Elastic Weight Consolidation, EWC)。
EWC的思路非常巧妙,它把对旧任务知识的保护,看作是给模型参数增加了一个约束。你可以想象,当模型学完任务A后,它的参数到达了一个最优点 。现在我们要学习任务B,EWC会在每个参数上都拴上一根弹簧,这根弹簧的另一头就固定在 这个位置。
这样一来,在学习任务B的过程中,模型参数想要移动,就会受到这些弹簧的拉力,被往回拉向任务A的最优点。
当然,不是所有弹簧的弹性或硬度都一样。参数对任务A越重要,拴在它上面的弹簧就越硬,把它拉回去的力就越大,从而使得这个参数在新任务中更难被改变。反之,那些对任务A不怎么重要的参数,它们的弹簧就很软,可以自由地移动以适应新任务。
那么,如何衡量一个参数有多重要呢?EWC使用了一个叫做费雪信息矩阵 (Fisher Information Matrix, ) 的数学工具。简单来说,费雪信息矩阵可以衡量,如果一个参数发生微小的变化,模型的预测结果会产生多大的波动。波动越大,说明这个参数对模型的输出影响越大,也就越重要。
整个EWC方法可以用一个损失函数来表示。在训练任务B时,模型的总损失 不仅仅是任务B自身的损失 ,还额外增加了一个惩罚项:
公式来源:[2]
我们来拆解一下这个公式:
是我们在新任务B上的损失,驱动模型学习新知识。
后面那一长串就是EWC的惩罚项,也就是我们说的弹簧。
计算了当前参数 偏离任务A最优参数 的距离。
就是费雪信息矩阵算出的第 个参数的重要性,它决定了弹簧的硬度。
是一个超参数,用来调节我们对旧任务的重视程度, 越大,保护力度越强。
EWC为解决灾难性遗忘问题为我们提供了一个有效的参考思路。
2. 更高效的层级正则化
EWC虽然经典,但对于现在动辄几百上千亿参数的大型语言模型来说,有一个缺点,计算和存储完整的费雪信息矩阵,成本太高了。
因此,最近的研究,比如《How to Alleviate Catastrophic Forgetting in LLMs Finetuning》这篇论文,就在EWC思想的基础上,提出了更高效、更轻量级的解决方案。
这个新方法的核心,是找到一种替代费雪信息矩阵的、计算成本更低的重要性衡量方法。
它借鉴了另一种名为突触智能 (Synaptic Intelligence) 的思路,不再关注参数变动对输出的影响,而是关注参数自身在学习过程中的贡献。具体来说,它通过计算在学习通用知识(任务A)的过程中,每个参数的更新对整体损失函数下降的累计贡献度来判断这个参数有多重要。这个过程在论文里被称为路径积分 (path integral),它可以在正常的训练流程中顺带计算出来,不需要像费雪信息矩阵那样进行额外的复杂计算。
此外,这个方法还提出了一个重要的创新点,就是分层级的保护策略。
元素级 (Element-Wise):这和EWC一样,为网络中的每一个参数计算一个重要性得分,进行非常精细的保护。
层级 (Layer-Wise):作者认为,LLM的不同层对于通用知识的贡献是不同的,比如有些层可能更关注底层语法,有些层则更关注高层语义。因此,不能对所有层施加同样强度的保护。他们提出了一种动态调整每一层保护力度的方法,根据该层所有参数的整体重要性得分,来决定这一层的弹簧总体上应该有多硬。
这种新方法最大的优势就是效率。我从论文的实验结果里看到,与基于EWC的方法相比,他们在计算参数重要性时:
速度提升了近20倍。
存储空间只占原来的10%到15%。
3. 其他应对遗忘的思路
当然,给重要参数上保护锁,也叫正则化方法,只是应对灾难性遗忘的其中一种主流思路。
学术界还探索了其他几种非常有趣的路径,比如经验回放、调整模型架构等。
经验回放 (Experience Replay) 的想法最符合我们的直觉,也就是温故而知新。它在学习新任务的同时,会把一小部分旧任务的数据拿出来一起复习。
而调整模型架构 (Architecture-based) 的方法则更为直接,它会为新任务在模型中开辟一块专属的、独立的参数空间,比如增加新的网络模块,从而在物理上将新旧知识隔离开来。
关于这些方法的更详细讨论,你可以参考我们之前的文章让大模型持续学习,我们如何应对知识更新的挑战。
九、课程学习与数据筛选
除了直接应对遗忘,我们还可以通过更聪明地组织训练过程来提升效果。
这里就不得不提到一个基础性的理念,叫做课程学习 (Curriculum Learning)。
这个理念由图灵奖得主Yoshua Bengio等人在2009年的论文中提出,它的核心思想很简单:让模型像人一样,从简单的例子开始学,然后逐步增加难度。
我从论文中看到,这种先易后难的训练顺序,可以帮助模型更快地收敛,并找到一个更好的解。
这个思想可以很好地应用在我们的持续预训练过程中。
比如,先进行DAPT学习宽泛的领域知识,再进行TAPT学习具体的任务知识,这本身就是一种从易到难的课程安排。
《Efficient Continual Pre-training》这篇论文则把这个思想用在了数据筛选上。
他们发现,在进行持续预训练时,并不需要把所有领域数据都用上。
通过一些简单的策略,筛选出信息量最大、对模型来说最新颖或最多样的数据,只用大约10%的数据量,就能达到甚至超过使用全部数据进行训练的效果。
这无疑为我们提供了一种更加高效、也更加聪明的再教育方式。
十、一个具体的例子:FinPythia的训练过程
前面我们聊了很多方法和理念,现在我们来看一个具体的实践案例,就是《Efficient Continual Pre-training》这篇论文里,他们是如何为金融领域构建FinPythia模型的。
1. 数据集的构建与处理
高质量的数据是模型成功的基石。我从论文的附录中看到,他们的数据主要来自两个方面:
1)金融语料构建(Financial Corpus Curation)
在金融领域持续预训练中,数据集的构建尤为关键。FinPythia的金融语料主要包括两部分:
金融新闻 CommonCrawl:通过筛选公开的CommonCrawl新闻数据,提取出金融相关内容。具体做法包括:建立金融新闻网站域名列表,只保留这些网站的文章;对于综合性新闻网站,通过URL关键词(如 economy, market, finance, money, wealth, invest, business, industry 等)识别金融板块内容。
SEC公司年报(Filings):收集美国证监会EDGAR系统1993-2022年公开的10-K文件。为保证数据质量,剔除内容少于20个单词的报告章节。
所有数据都经过Pythia套件的去重流程,去除重复样本,提高训练效率和泛化能力。最终金融语料总规模为23.9亿token(约16.5亿词)。
下图展示了任务数据、任务相似领域数据和完整领域语料在特征空间中的分布关系:
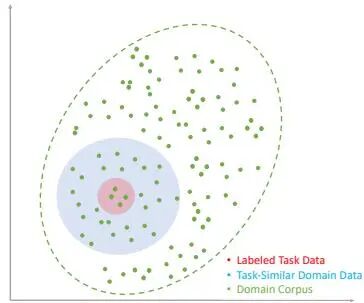

(图1:标注任务数据、任务相似领域数据和领域语料在特征空间中的分布)
(图源:FinPythia论文)
2)数据去重流程
为了保证训练数据的独特性和质量,FinPythia在数据集构建过程中进行了严格的去重处理。具体流程如下:
基于文本相似度的去重:计算文本之间的相似度,移除相似度过高的重复文本。
基于哈希的去重:对文本进行哈希处理,利用哈希值快速识别和移除重复文本。
人工审核:对去重后的数据进行抽样,人工检查数据质量,确保无误删重要信息。
通过上述流程,FinPythia确保了数据集的高质量和高多样性。
2. 硬件与训练技巧
在训练设置上,他们分享了一些具体的参数和技巧。
硬件条件:他们是在AWS SageMaker云服务上,使用一台p4d.24xlarge实例来完成持续预训练任务的。这个实例配备了8块NVIDIA A100 GPU,每块GPU拥有40GB的显存。
训练技巧:
学习率:他们为不同大小的模型设置了不同的学习率,比如为69亿参数的模型设置了 ,为10亿参数的模型设置了 。他们提到,使用较小的学习率有助于减轻灾难性遗忘。
计算精度:他们使用了
bf16混合精度进行训练。批次大小 (Batch Size):批次大小设置为512。
并行技术:为了能在单个实例上训练大模型,他们使用了DeepSpeed ZeRO Stage 2这种数据并行技术,并且启用了激活检查点 (activation checkpointing) 来优化显存使用。
3. 背后的一些关键公式
这篇论文为他们的数据筛选方法提供了一些理论支撑,其中有几个公式能帮助我们理解他们的思路。
首先,他们把数据筛选问题定义为一个优化问题。这个问题的最终目标是,从海量的领域数据 中,找到一个最优的数据子集 。用这个子集训练出来的模型,在最终要解决的目标任务 上表现最好(也就是任务损失 最小)。
公式来源:[3]
这里的 就是我们要找的最优训练数据子集。
是我们拥有的全部领域数据。
是我们最终要解决的目标任务。
是衡量模型在目标任务上表现的损失函数,值越小越好。
整个公式的意思是:找到一个数据子集,用它训练出的模型在最终任务上损失最小。
这个公式里的 指的是模型在数据子集 上训练好之后的参数。而这个训练过程本身,就是寻找能让预训练损失 最小的参数。
公式来源:[3]
然后,他们引用了一个理论来指导如何选择数据。这个理论指出,模型在目标任务上的误差 有一个上限,这个上限和我们选择的训练数据与目标任务数据之间的“分布差异” 正相关。
公式来源:[3]
是模型在最终任务上的真实误差,我们希望它尽可能小。
是模型在我们选择的训练数据上的误差。
是最关键的一项,它衡量了我们选的训练数据和最终任务数据有多不像,也就是分布差异。
这个公式的含义是,模型在最终任务上的表现,不仅取决于它在训练数据本身上学得好不好( ),还很大程度上取决于我们选的训练数据和最终任务的数据有多像。两者越像,分布差异越小,模型在最终任务上表现好的可能性就越大。
正是基于这个理论,他们提出了一种核心的数据筛选策略:从海量领域数据中,优先挑选出那些和目标任务数据最相似的数据来进行训练。
4. FinPythia模型评估结果
在金融任务评估中,FinPythia(持续预训练模型)与Pythia(原始通用模型)及其他主流开源模型进行了对比。评测采用FLARE框架,所有模型均为5-shot设置,任务包括金融短语分类(FPB)、金融情感分析(FiQA SA)、新闻标题分类(Headline)、金融实体识别(NER)。
下表为各模型在金融任务上的表现(F1为主要指标,*为BloombergGPT论文原始结果,仅供参考,因数据集划分和prompt不同,不能直接对比):
BloombergGPT | OPT 7B | BLOOM 7B | GPT-J-6B | Pythia 1B | Pythia 7B | FinPythia 1B | FinPythia 7B | ||
FPB | Acc | - | 57.22 | 52.68 | 50.21 | 42.85 | 54.64 | 47.14 | 59.90 |
F1 | 51.07* | 65.77 | 52.11 | 49.31 | 4.39 | 55.79 | 46.52 | 64.43 | |
FiQA SA | Acc | - | 40.43 | 70.21 | 60.42 | 54.51 | 60.85 | 46.13 | 52.34 |
F1 | 75.07* | 31.29 | 74.11 | 62.14 | 56.29 | 61.33 | 44.53 | 53.04 | |
Headline | F1 | 82.20* | 62.62 | 42.68 | 45.54 | 44.73 | 43.83 | 53.02 | 54.14 |
NER | F1 | 60.82* | 41.91 | 18.97 | 35.87 | 49.15 | 41.60 | 55.51 | 48.42 |
Average | F1 | 67.29* | 50.40 | 46.97 | 48.22 | 48.53 | 50.64 | 49.90 | 54.83 |
(表源:FinPythia论文)
结果显示,FinPythia-6.9B和FinPythia-1B在FPB、Headline和NER任务上均优于原始Pythia模型,平均F1提升显著,且在部分任务上超过同规模的OPT、BLOOM、GPT-J等主流模型。持续预训练能有效提升模型在金融领域的专业能力,同时保持通用能力。
训练损失曲线如图所示,FinPythia在金融测试集上的loss快速下降,说明模型在持续预训练过程中快速适应金融领域分布。
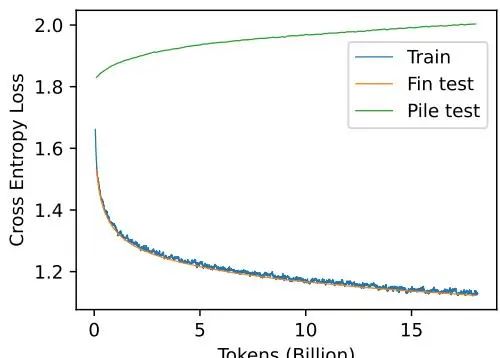 (图源:FinPythia论文)
(图源:FinPythia论文)
十一、总结
通过阅读这些材料,我们大概了解了如何在现有大模型的基础上,构建一个更专业的领域模型。
我们知道了,要实现这个目标,主要有两条路:一条是从零开始训练,成本很高,比如BloombergGPT;另一条是基于现有模型进行持续预训练,这条路更经济。
我们也看到了不同路线在硬件、时间、数据上的投入有着巨大的差异,并对token这个数据单位有了更直观的认识,知道了一个亿的token大概相当于1000本书的内容。
在持续预训练的过程中,我们会遇到一个叫做灾难性遗忘的大问题,也就是模型学了新的忘了旧的。
为了解决这个问题,我们可以使用像EWC或者一些更现代、更高效的方法,来保护那些对通用知识重要的模型参数。同时,我们也简单了解了经验回放、架构调整等其他思路。
最后,我们还了解到,可以借鉴课程学习的思想,通过合理安排训练顺序,或者智能地筛选训练数据,让整个模型的再教育过程变得更加高效。通过FinPythia这个具体的例子,我们也看到了这些理论和方法在实践中是如何应用的。
参考文献
1. Song, S., Xu, H., Ma, J., Li, S., Peng, L., Wan, Q., Liu, X., & Yu, J. (n.d.). How to Alleviate Catastrophic Forgetting in LLMs Finetuning? Hierarchical Layer-Wise and Element-Wise Regularization.
2. Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., & Hadsell, R. (n.d.). Overcoming catastrophic forgetting in neural networks.
3. Xie, Y., Aggarwal, K., & Ahmad, A. (n.d.). Efficient Continual Pre-training for Building Domain Specific Large Language Models.
4. Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., & Mann, G. (n.d.). BloombergGPT: A Large Language Model for Finance.
5. Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (n.s.). Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks.
6. Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (n.d.). Curriculum Learning.
7. Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (n.s.). Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks.
8. Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (n.d.). Curriculum Learning.

一起“点赞”三连↓

















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









