



Datawhale干货
教程作者:Mark,华南理工大学
本教程采用一套标准化的工作流,将复杂的绘图任务拆解为 “逻辑构建(The Architect)” 与 “视觉渲染(The Renderer)” 两个独立且互补的环节。通过利用 LLM 强大的逻辑推理能力来指导绘图模型的像素生成能力,我们能够产出符合 CVPR/NeurIPS 等顶刊标准的学术插图!
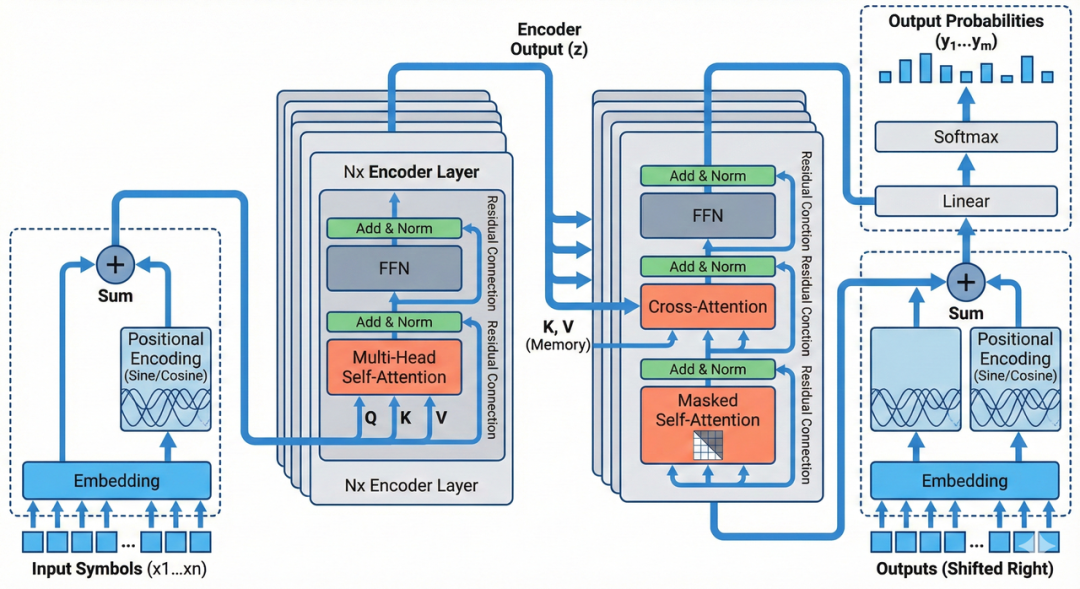
Attention Is All You Need
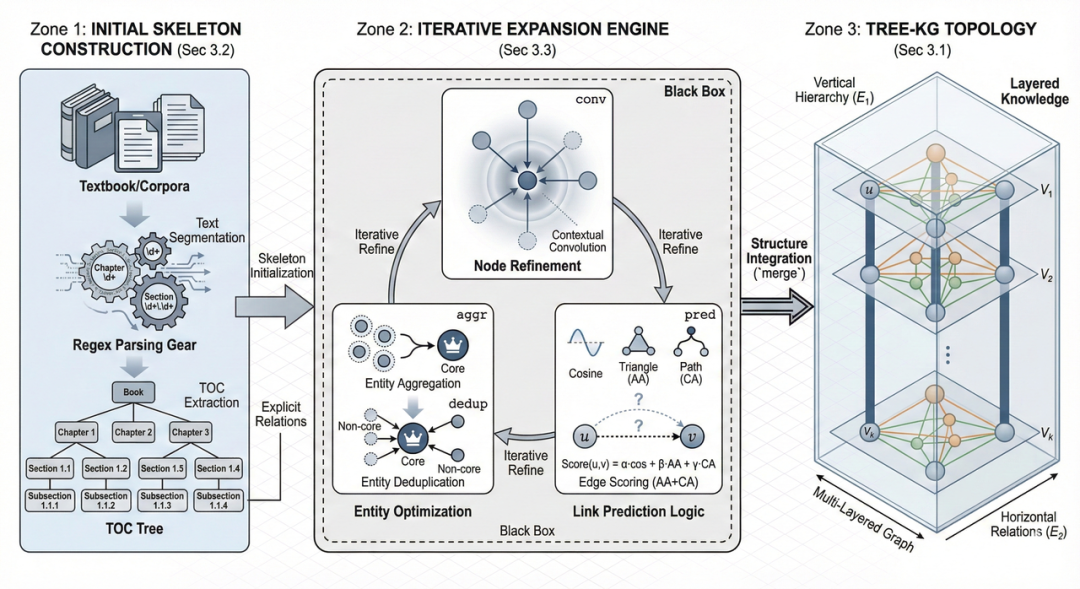
Tree-KG: An expandable knowledge graph construction framework for knowledge-intensive domains
步骤一:逻辑构建(The Architect)
目标:利用逻辑推理能力强的 LLM(如 Gemini 3 Pro, GPT-5, Claude 4.5)将你的论文内容转化为一份[VISUAL SCHEMA]。
操作指南:请复制下方的 Prompt,并将你的论文摘要或方法章节的内容附在最后。这一步的核心在于将抽象的算法逻辑转化为绘图模型能够理解的“强硬”物理描述。
Prompt 1
# Role
你是一位 CVPR/NeurIPS 顶刊的**视觉架构师**。你的核心能力是将抽象的论文逻辑转化为**具体的、结构化的、几何级的视觉指令**。
# Objective
阅读我提供的论文内容,输出一份 **[VISUAL SCHEMA]**。这份 Schema 将被直接发送给 AI 绘图模型,因此必须使用**强硬的物理描述**。
# Phase 1: Layout Strategy Selector (关键步骤:布局决策)
在生成 Schema 之前,请先分析论文逻辑,从以下**布局原型**中选择最合适的一个(或组合):
1. **Linear Pipeline**: 左→右流向 (适合 Data Processing, Encoding-Decoding)。
2. **Cyclic/Iterative**: 中心包含循环箭头 (适合 Optimization, RL, Feedback Loops)。
3. **Hierarchical Stack**: 上→下或下→上堆叠 (适合 Multiscale features, Tree structures)。
4. **Parallel/Dual-Stream**: 上下平行的双流结构 (适合 Multi-modal fusion, Contrastive Learning)。
5. **Central Hub**: 一个核心模块连接四周组件 (适合 Agent-Environment, Knowledge Graphs)。
# Phase 2: Schema Generation Rules
1. **Dynamic Zoning**: 根据选择的布局,定义 2-5 个物理区域 (Zones)。不要局限于 3 个。
2. **Internal Visualization**: 必须定义每个区域内部的“物体” (Icons, Grids, Trees),禁止使用抽象概念。
3. **Explicit Connections**: 如果是循环过程,必须明确描述 "Curved arrow looping back from Zone X to Zone Y"。
# Output Format (The Golden Schema)
请严格遵守以下 Markdown 结构输出:
---BEGIN PROMPT---
[Style & Meta-Instructions]
High-fidelity scientific schematic, technical vector illustration, clean white background, distinct boundaries, academic textbook style. High resolution 4k, strictly 2D flat design with subtle isometric elements.
[LAYOUT CONFIGURATION]
* **Selected Layout**: [例如:Cyclic Iterative Process with 3 Nodes]
* **Composition Logic**: [例如:A central triangular feedback loop surrounded by input/output panels]
* **Color Palette**: Professional Pastel (Azure Blue, Slate Grey, Coral Orange, Mint Green).
[ZONE 1: LOCATION - LABEL]
* **Container**: [形状描述, e.g., Top-Left Panel]
* **Visual Structure**: [具体描述, e.g., A stack of documents]
* **Key Text Labels**: "[Text 1]"
[ZONE 2: LOCATION - LABEL]
* **Container**: [形状描述, e.g., Central Circular Engine]
* **Visual Structure**: [具体描述, e.g., A clockwise loop connecting 3 internal modules: A (Gear), B (Graph), C (Filter)]
* **Key Text Labels**: "[Text 2]", "[Text 3]"
[ZONE 3: LOCATION - LABEL]
... (Add Zone 4/5 if necessary based on layout)
[CONNECTIONS]
1. [描述连接线, e.g., A curved dotted arrow looping from Zone 2 back to Zone 1 labeled "Feedback"]
2. [描述连接线, e.g., A wide flow arrow from Zone 2 to Zone 3]
---END PROMPT---
# Input Data
[在此处粘贴你的论文内容]步骤二:绘图渲染(The Renderer)
目标:利用 Nano-Banana Pro 的指令遵循能力,将蓝图转化为像素。
操作指南:请复制下面的通用模板。注意,你只需要将步骤一生成的 ---BEGIN PROMPT--- 到 ---END PROMPT--- 之间的内容(包含方括号内的英文)完整粘贴进去即可,无需做任何修改。
Prompt 2
**Style Reference & Execution Instructions:**
1. **Art Style (Visio/Illustrator Aesthetic):**
Generate a **professional academic architecture diagram** suitable for a top-tier computer science paper (CVPR/NeurIPS).
* **Visuals:** Flat vector graphics, distinct geometric shapes, clean thin outlines, and soft pastel fills (Azure Blue, Slate Grey, Coral Orange).
* **Layout:** Strictly follow the spatial arrangement defined below.
* **Vibe:** Technical, precise, clean white background. NOT hand-drawn, NOT photorealistic, NOT 3D render, NO shadows/shading.
2. **CRITICAL TEXT CONSTRAINTS (Read Carefully):**
* **DO NOT render meta-labels:** Do not write words like "ZONE 1", "LAYOUT CONFIGURATION", "Input", "Output", or "Container" inside the image. These are structural instructions for YOU, not text for the image.
* **ONLY render "Key Text Labels":** Only text inside double quotes (e.g., "[Text]") listed under "Key Text Labels" should appear in the diagram.
* **Font:** Use a clean, bold Sans-Serif font (like Roboto or Helvetica) for all labels.
3. **Visual Schema Execution:**
Translate the following structural blueprint into the final image:
[在此处直接粘贴 Step 1 生成的 ---BEGIN PROMPT--- ... ---END PROMPT--- 内容(包含方括号内的英文)]步骤三:交互式微调与迭代 (The Editor)
当你拿到步骤二生成的初稿后,发现并不满意后,可以根据实际情况选择不同的操作路径:
这一步的核心理念是利用 Nano-Banana Pro 卓越的自然语言编辑能力进行“微调”。Nano-Banana Pro的图编辑已经很强了,所以如果你对这个图能达到80分的满意,就不要轻易点击重新生成。
💡关于抽卡的有效性
通过测试发现,抽卡对整体的布局和风格改动不会特别大,不过可能会对某些线条的路径、某些元素的颜色、图形的细节有些改变。
你可以抽卡选择你最喜欢的一张;或者如果你本身有明确的配色方案的话,可以直接用自然语言去对这张原图进行修改。
你可以对比下面两张相同提示词生成的结果,其实差别并不是特别显著。因此更多情况下,对于大幅度的调整可以去优化步骤一的提示词;小幅度调整直接自然语言去命令修改即可。
情况 A:整体布局满意,但细节或风格有瑕疵
此时应采取“自然语言编辑”策略。你可以直接在对话框中输入修改指令,或者利用界面上的“选中区域编辑”功能。模型会在保持画面主体结构不变的前提下,精准修改你指定的元素。例如:
修改图标:你可以说 "Change the 'Gear' icon in the center to a 'Neural Network' icon"(把中间的齿轮换成神经网络图标),或者 "Replace the robot head with a simple document symbol"(把机器人头换成文档符号)。
调整颜色:例如 "Make the background of the left panel pure white instead of light blue"(把左边面板的背景改成纯白),或 "Change the orange arrows to dark grey"(把橙色箭头改成深灰色)。
风格统一:如果线条太粗,可以说 "Make all lines thinner and cleaner";如果阴影干扰了视觉,可以说 "Remove the shading effect, make it completely flat 2D"。
文字修正:如果出现拼写错误,可以说 "Correct the text 'ZONNE' to 'ZONE'"。当然,如果文字错误太严重,最稳妥的办法是直接让 AI 去掉文字 ("Remove the text labels"),后期自己在 PPT 中添加。
情况 B:整体布局错误 (Layout Failure)
如果你发现本该是循环结构的画成了直线,或者核心逻辑关系完全搞反了,这时候不要试图通过修补来挽救。这通常意味着步骤一生成的 [VISUAL SCHEMA] 本身描述不够清晰。
正确的做法是回到步骤一。检查并修改 Step 1 的 Prompt,确认是否选错了 [LAYOUT CONFIGURATION],或者 Internal Visualization 的描述不够具体。你可以直接和LLM对话,要求它按照你的要求修改 [VISUAL SCHEMA] 重新生成蓝图后,再次运行步骤二,往往能解决根本问题。
🚀进阶技巧:从“可用”到“完美”
为了进一步提升出图质量,我们可以结合人工介入和一些工具技巧:
1. 人工介入微调 (Human-in-the-loop)
LLM 生成的 [VISUAL SCHEMA](Step 1 的结果)本质上是完全可编辑的。
你不需要反复“抽卡”来碰运气,直接修改 [VISUAL SCHEMA] 往往更快。例如,如果你不想要某个图标,直接在蓝图文本里把 Top Visual: A robot 改成 Top Visual: A brain icon;如果觉得颜色太花哨,直接在 Color Palette 里删掉多余的颜色。
2. 提供参考图像
语言描述终究有其局限性,再精准的 Prompt 也难以完全复刻你脑海中特定的视觉张力或复杂的空间拓扑。因此,我们需要引入更直观的约束手段。
建立“科研审美库”与风格迁移:我强烈建议你在日常阅读顶刊论文时,建立一个私人的“科研审美库”,有意识地收集那些布局精妙、配色高级的插图。在实战中,如果你有一张目标风格的图片(甚至是你的手绘草稿),请直接上传给模型,并删除步骤二提示词中的通用 Art Style 描述,改为明确指令:“生成的 Figure 风格、布局特征和配色方案应严格参考我上传的图片”。这将迫使 AI 从“文生图”逻辑切换为更精准的“图生图”逻辑,从根本上解决布局失控的问题。
参数化控色:仅仅告诉 AI 使用 "Light Blue" 或 "Red" 是远远不够的,这往往会导致生成图带有廉价的“塑料感”。真正的专业级绘图需要“参数化控色”。 你可以利用取色工具从你的“审美库”中提取精准的 HEX 代码(如 #E1F5FE),并在 Prompt 中强制指定颜色。同时,建议建立一套经过学术界验证的配色方案储备,例如参考 顶刊高质量论文插图配色(含RGB值及16进制HEX码) 等资源。直接将这些经过验证的 RGB/HEX 数值喂给 AI,能让你的插图瞬间拥有 Nature/Science 级别的视觉质感。
3. 如何避免生成时携带的水印
通过 Google AI Studio 使用 Nano Banana 模型时,生成的图片右下角往往会带有一个 Gemini Logo 水印。这其实是前端页面叠加的效果,我们可以通过简单的技术手段去除。
最简单的方法是使用 Bookmarklet(书签脚本):
在浏览器书签栏新建一个书签,命名为 "Remove Gemini Watermark"。
在“网址(URL)”栏粘贴下面的用于阻止水印图片加载的 JavaScript 脚本。
保存后,在 Google AI Studio 页面点击该书签,弹出成功提示后,新生成的图片就不会带有水印了。
javascript:(function(){const o=XMLHttpRequest.prototype.open;XMLHttpRequest.prototype.open=function(m,u){if(u.includes("watermark"))return console.log("🚫 Blocked:",u);return o.apply(this,arguments)};const f=window.fetch;window.fetch=function(u,...a){if(typeof u==="string"&&u.includes("watermark"))return console.log("🚫 Blocked fetch:",u),new Promise(()=>{});return f.apply(this,arguments)};Object.defineProperty(Image.prototype,"src",{set(v){if(v.includes("watermark"))return console.log("🚫 Blocked IMG:",v);this.setAttribute("src",v)}});const n=document.createElement("div");n.textContent="✅ Watermark blocking active!";Object.assign(n.style,{position:"fixed",top:"20px",left:"50%",transform:"translateX(-50%)",background:"rgba(0,0,0,0.75)",color:"#fff",padding:"8px 14px",borderRadius:"6px",fontSize:"14px",zIndex:99999,transition:"opacity 0.3s"});document.body.appendChild(n);setTimeout(()=>{n.style.opacity="0";setTimeout(()=>n.remove(),300)},500);})();如果不想折腾技术,或者对于上述内容不适用的情况,还有一个“物理外挂”的方法:在步骤二的提示词末尾加上一句:
在图片底部插入一行占位文本,这行文本内容所在位置应该刚好能包含 Gemini 的水印。拿到图后,直接把底部包含文本和水印的区域裁剪掉即可。
添加这种提示词后生成的效果
4. 后期处理 (Post-Processing)
请将 AI 生成的图视为 90% 的完成品。为了达到出版要求,建议使用 Photoshop 或 Adobe illustrator(AI)进行最后的修整。比如,AI 生成的文字可能会有拼写错误或字体不统一的问题,最好的办法是用修图软件抹掉这些文字,然后换成符合论文格式(如 Times New Roman)的矢量文字。如果是超长流程图,可以分段生成(Zone 1+2 一次,Zone 3 一次),最后在 PPT 里拼接起来。
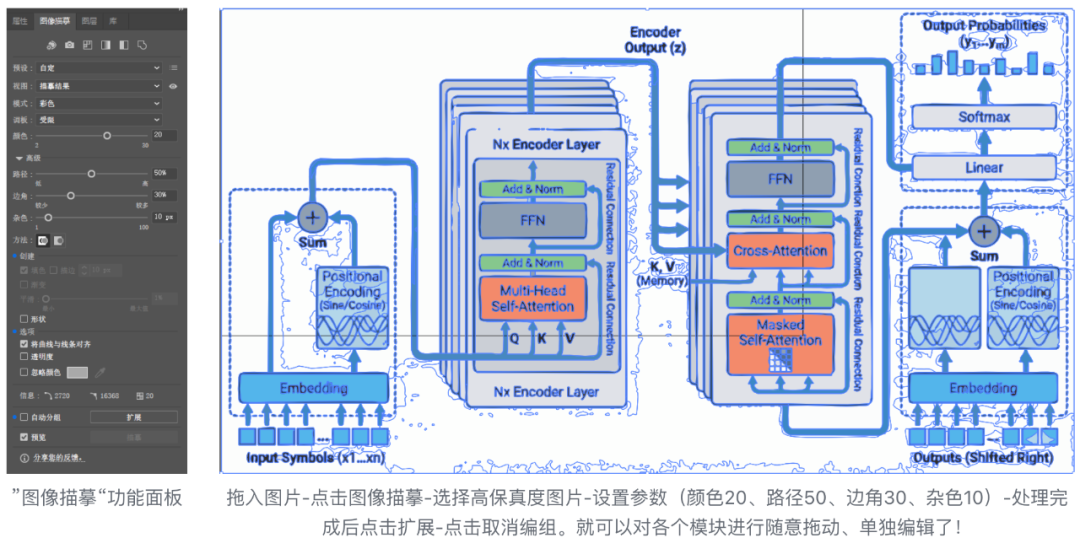
有xhs博主指出 Illustrator的“图像描摹”功能可以将 Nano banana Pro 生成的PNG图转为矢量图,具体参数和步骤如下:
不过在我实际测试时,效果并不是特别完美,精度有些低。可能这个参数更适用于生物学等领域的 biorender 风格。如果确实有将 PNG 矢量化的需求,可以去测试
颜色、路径、边角、杂色这几个参数的取值,提高精度。不过这个过程可能对硬件资源消耗较大,会耗费一些时间。
⚠️ 注意事项:认清 AI 局限
AI 仅是辅助,而非决策者。
Nano Banana Pro 在文本标注和结构化布局上的表现,目前确实远超同领域的其他模型。它极大地解放了我们的生产力——从结构设计、配色方案到最终的绘制,原本需要数小时的机械性工作被压缩到了几分钟。
但是,我们必须警惕“AI 幻觉”以及它对科研意图的理解偏差。 虽然我们用“懒人式”的方法依赖 AI 完成了绘图,但在审核环节,“过度懒惰”是万万不可的。请务必将节省下来的时间,全部投入到对图表内容的严谨审查中。以下是你在使用过程中必须时刻提防的几个具体的“陷阱”:
1. “视觉合理性” vs “科学真实性”的冲突
Nano Banana Pro 在生成图形时,有时会优先考虑“画面好不好看”或“布局是否平衡”,从而牺牲掉“科学是否正确”。
细节偏差:在涉及复杂的机制图时,它可能会将信号通路中的抑制箭头方向画反,或者把蛋白质之间的调控关系简化过头。
逻辑重组:它甚至可能为了构图方便,把实验步骤的顺序“自动优化”,导致与真实流程不一致。这些细微的错误往往隐藏得很好,需要你具备极高的警惕性才能发现。
2. 文本标注的“张冠李戴”
尽管该模型的文字能力很强,但在信息量较大的图表中,它偶尔会出现逻辑性错位。
它可能会为未提到的元素添加多余的说明。
它可能会把原本属于模块 A 的标签挪到模块 B 上。
切记:科研插图容不得半点错位或误解,每一个箭头、每一个框、每一行注释都必须逐一进行人工排查。
3. “过度艺术化”与领域适配
模型有时会添加渐变、阴影或非标准的配色来炫技,但这可能不符合学术期刊的规范。特别是生物医学领域,通常有特定的颜色语义(如上调红、下调蓝),这需要你在后期人工统一风格。
注:本文提供的 Prompt 主要基于工科/计算机领域的视觉风格。如果你从事生物、化学或人文社科研究,建议对提示词进行微调,并在步骤二中上传你所在领域的经典论文插图作为参考(Reference Image)。
4. 数据的真实性
严正声明:本文所介绍的 AI 辅助绘图流程,仅适用于生成“概念结构图”、“流程图”、“系统架构图”等不涉及具体实验数值的示意图。
绝对禁止:使用 AI 绘制、生成或修改任何与实验数据直接相关的统计图表(如散点图、柱状图、折线图等)。
后果:AI 无法理解数据的物理意义,它生成的每一个数据点都是基于概率的“瞎编”。使用 AI 生成数据图表严重涉嫌数据造假和学术不端!!!
总结: 工具就是工具,Nano Banana Pro 帮我们解决的是“画出来”的问题,而不是“画得对”的问题。 不要把它当作可以替你判断科学内容的系统,那样只会带来偏差和风险。把节省下来的时间用在严谨、严谨、再严谨的校对上,这样 AI 才会成为你的科研利器,而非学术隐患。
💡 对于禁止直接使用 AI 绘图的期刊
针对有些期刊明确禁止使用 AI 生成图像作为插图的情况,我们可以灵活应对,将 AI 作为“草图“。
你可以参考前文生成的图片,将其导入 Figma 或 Illustrator 中。在软件里将这张图的透明度调高,作为底层的“临摹范本”,然后重新手动绘制线条和形状。其中的图标可以手绘,也可以利用 iconfont-阿里巴巴矢量图标库 进行查询和替换;对于较规则的图形,或仅用于示意数据的图表,则建议利用 Python (matplotlib/seaborn) 等库生成(代码部分也可以让 AI 辅助编写)。
这种方法既规避了版权和学术伦理风险,又保留了 AI 在布局设计上的高效优势。
参考资料
[Nano-Banana Pro 完整指南:10 個製作實戰技巧](https://tenten.co/learning/nano-banana-pro-tutorials/)
[Gemini 3 Pro 影像模型发布:Nano Banana Pro 功能详解与应用教程 | Gemini 中文版](https://www.gemini-cn.com/blog/gemini-3-pro-image-model-nano-banana.html)
[实用指南!用Nano Banana Pro制作论文插图,附Prompt (aje.cn)](https://www.aje.cn/arc/graphic-design-for-academic-papers)
[Nano Banana 一键去水印 - 小红书](https://www.xiaohongshu.com/explore/68e88a590000000004007f5d?note_flow_source=wechat&xsec_token=CB8qUC0evJew9kTHL04pjUgbGo6X1AR-ep0u87BR_rE_I=)
[1分钟将图片转为矢量图,元素随意拖动! - 小红书](https://www.xiaohongshu.com/explore/693041cc000000001e033691?note_flow_source=wechat&xsec_token=CBxCBtmFky6B_YwXXIHbnvgSlb9RS24-rPJCpm0Hm3MYc=)
[顶刊高质量论文插图配色(含RGB值及16进制HEX码) - 知乎](https://zhuanlan.zhihu.com/p/670396774)


一起“点赞”三连↓

















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









